AutoML と Python (SDK v1) を使用して回帰モデルをトレーニングする

この記事では、Azure Machine Learning の自動 ML を使用して Azure Machine Learning Python SDK で回帰モデルをトレーニングする方法について説明します。 この回帰モデルでは、NYC タクシーの料金を予測します。
このプロセスは、トレーニング データと構成設定を受け取り、さまざまなフィーチャーの正規化/標準化の方法、モデル、およびハイパーパラメーター設定の組み合わせを自動的に反復処理し、最適なモデルに到達します。
この記事では、Python SDK を使用してコードを記述します。 次のタスクについて説明します。
- Azure Open Datasets を使用してデータのダウンロード、変換、クリーニングを行う
- 自動機械学習回帰モデルをトレーニングする
- モデルの精度を計算する
コードなしの AutoML の場合は、次のチュートリアルを試してください。
前提条件
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning を今すぐお試しください。
- まだ Azure Machine Learning ワークスペースまたはコンピューティング インスタンスがない場合は、Azure Machine Learning の利用開始に関するクイックスタートを完了します。
- ウィザードの完了後:
- スタジオで [Notebooks] を選択します。
- [サンプル] タブを選択します。
- SDK v1/tutorials/regression-automl-nyc-taxi-data/regression-automated-ml.ipynb ノートブックを開きます。
- チュートリアルで各セルを実行するには、 [このノートブックを複製する] を選択します
独自の ローカル環境で実行したい場合は、この記事を GitHub で入手することもできます。 必要なパッケージを取得するには、
- 完全な
automlクライアントをインストールします。 pip install azureml-opendatasets azureml-widgetsを実行して必要なパッケージを取得してください。
データのダウンロードと準備
必要なパッケージをインポートします。 オープン データセット パッケージには各データ ソースを表すクラス (たとえば NycTlcGreen) が含まれており、ダウンロードする前に簡単に日付パラメーターをフィルター処理できます。
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
まず、タクシーのデータを保持するデータフレームを作成します。 Spark 以外の環境で作業する場合、Open Datasets では、大きなデータセットによる MemoryErrorを回避するために、特定のクラスの 1 か月分のデータしか一度にダウンロードできません。
タクシー データをダウンロードするには、一度に 1 か月分をフェッチすることを繰り返してから green_taxi_df に付加し、各月の 2,000 レコードをランダムにサンプリングして、データフレームが大きくならないようにします。 次に、データをプレビューします。
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | extra | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 131969 | 2 | 2015-01-11 05:34:44 | 2015-01-11 05:45:03 | 3 | 4.84 | なし | なし | -73.88 | 40.84 | -73.94 | ... | 2 | 15.00 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 16.30 |
| 1129817 | 2 | 2015-01-20 16:26:29 | 2015-01-20 16:30:26 | 1 | 0.69 | なし | なし | -73.96 | 40.81 | -73.96 | ... | 2 | 4.50 | 1.00 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 6.30 |
| 1278620 | 2 | 2015-01-01 05:58:10 | 2015-01-01 06:00:55 | 1 | 0.45 | なし | なし | -73.92 | 40.76 | -73.91 | ... | 2 | 4.00 | 0.00 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 4.80 |
| 348430 | 2 | 2015-01-17 02:20:50 | 2015-01-17 02:41:38 | 1 | 0.00 | なし | なし | -73.81 | 40.70 | -73.82 | ... | 2 | 12.50 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 13.80 |
| 1269627 | 1 | 2015-01-01 05:04:10 | 2015-01-01 05:06:23 | 1 | 0.50 | なし | なし | -73.92 | 40.76 | -73.92 | ... | 2 | 4.00 | 0.50 | 0.50 | 0 | 0.00 | 0.00 | nan | 5.00 |
| 811755 | 1 | 2015-01-04 19:57:51 | 2015-01-04 20:05:45 | 2 | 1.10 | なし | なし | -73.96 | 40.72 | -73.95 | ... | 2 | 6.50 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 7.80 |
| 737281 | 1 | 2015-01-03 12:27:31 | 2015-01-03 12:33:52 | 1 | 0.90 | なし | なし | -73.88 | 40.76 | -73.87 | ... | 2 | 6.00 | 0.00 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 6.80 |
| 113951 | 1 | 2015-01-09 23:25:51 | 2015-01-09 23:39:52 | 1 | 3.30 | なし | なし | -73.96 | 40.72 | -73.91 | ... | 2 | 12.50 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 13.80 |
| 150436 | 2 | 2015-01-11 17:15:14 | 2015-01-11 17:22:57 | 1 | 1.19 | なし | なし | -73.94 | 40.71 | -73.95 | ... | 1 | 7.00 | 0.00 | 0.50 | 0.3 | 1.75 | 0.00 | nan | 9.55 |
| 432136 | 2 | 2015-01-22 23:16:33 2015-01-22 23:20:13 1 0.65 | なし | なし | -73.94 | 40.71 | -73.94 | ... | 2 | 5.00 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 6.30 |
トレーニングまたはその他の特徴の構築で必要としない列を削除します。 自動機械学習では、lpepPickupDatetime などの時間ベースの機能が自動的に処理されます。
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
データをクレンジングする
新しいデータフレームに対して describe() 関数を実行して、各フィールドの概要の統計を確認します。
green_taxi_df.describe()
| vendorID | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | month_num day_of_month | day_of_week | hour_of_day |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 |
| mean | 1.78 | 1.37 | 2.87 | -73.83 | 40.69 | -73.84 | 40.70 | 14.75 | 6.50 | 15.13 |
| std | 0.41 | 1.04 | 2.93 | 2.76 | 1.52 | 2.61 | 1.44 | 12.08 | 3.45 | 8.45 |
| min | 1.00 | 0.00 | 0.00 | -74.66 | 0.00 | -74.66 | 0.00 | -300.00 | 1.00 | 1.00 |
| 25% | 2.00 | 1.00 | 1.06 | -73.96 | 40.70 | -73.97 | 40.70 | 7.80 | 3.75 | 8.00 |
| 50% | 2.00 | 1.00 | 1.90 | -73.94 | 40.75 | -73.94 | 40.75 | 11.30 | 6.50 | 15.00 |
| 75% | 2.00 | 1.00 | 3.60 | -73.92 | 40.80 | -73.91 | 40.79 | 17.80 | 9.25 | 22.00 |
| max | 2.00 | 9.00 | 97.57 | 0.00 | 41.93 | 0.00 | 41.94 | 450.00 | 12.00 | 30.00 |
概要の統計では、外れ値すなわちモデルの精度を低下させる値を含むフィールドがいくつか見つかります。 まず、マンハッタン エリアの境界内に収まるように緯度と経度のフィールドをフィルター処理します。 これにより、その距離範囲を超えるタクシー乗車や、他の特徴との関係の点で外れ値となっているタクシー乗車が除外されます。
加えて、tripDistance フィールドが 0 より大きく 31 マイル (2 つの緯度経度ペア間の半正矢距離) 未満となるようにフィルター処理します。 これにより、移動距離が長く、矛盾した運賃となっている外れ値の乗車が除外されます。
最後に、タクシー料金の totalAmount フィールドに負の値が含まれていますが、これは、ここで扱うモデルのコンテキストでは意味を成しません。また、passengerCount フィールドにも、最小値が 0 である無効なデータがあります。
これらの異常値をフィルターで除外してから、最終的にトレーニングのために不必要ないくつかの列を削除します。
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
再びデータに対して describe() を呼び出して、クレンジングが予期したとおりに動作したことを確認します。 これで、機械学習モデルのトレーニングに使用するためのタクシー、休日、気象のデータセットの準備とクレンジングが終了しました。
final_df.describe()
ワークスペースの構成
既存のワークスペースからワークスペース オブジェクトを作成します。 ワークスペースは、お客様の Azure サブスクリプションとリソースの情報を受け取るクラスです。 また、これにより、お客様のモデル実行を監視して追跡するためのクラウド リソースが作成されます。 Workspace.from_config() により、config.json ファイルが読み取られ、認証の詳細情報が ws という名前のオブジェクトに読み込まれます。 ws は、この記事の残りのコード全体で使用されています。
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
データをトレーニング セットとテスト セットに分割する
scikit-learn ライブラリの train_test_split 関数を使用して、トレーニング セットとテスト セットにデータを分割します。 この関数は、モデル トレーニング用の x (特徴) データ セットとテスト用の y (予測する値) データ セットに、データを分割します。
test_size パラメーターでは、テストに割り当てるデータの割合を決定します。 random_state パラメーターでは、お客様のトレーニングとテストの分割が決定論的になるように、乱数ジェネレーターにシードを設定します。
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
この手順の目的は、正しい精度を測定するために、モデルのトレーニングに使用されたことのないデータ ポイントで完成モデルをテストすることです。
つまり、適切にトレーニングされたモデルは、まだ見たことのないデータから正確な予測ができるはずです。 機械学習モデルの自動トレーニングに使用するデータの準備が整いました。
自動的にモデルをトレーニングする
モデルを自動的にトレーニングするには、次の手順を実行します。
- 実験の実行用の設定を定義する。 トレーニング データを構成にアタッチし、トレーニング プロセスを制御する設定を変更します。
- モデル調整用の実験を送信する。 実験を送信した後、プロセスは定義された制約に従って、他の機械学習アルゴリズムとハイパー パラメーター設定を反復処理します。 精度メトリックを最適化することによって、最適なモデルが選択されます。
トレーニングの設定を定義する
トレーニング用の実験パラメーターとモデルの設定を定義します。 設定の完全な一覧を表示します。 これらの既定の設定で実験を送信するには約 5 分から 20 分かかりますが、実行時間を短くしたい場合は experiment_timeout_hours パラメーターを減らしてください。
| プロパティ | この記事の値 | 説明 |
|---|---|---|
| iteration_timeout_minutes | 10 | 各イテレーションの分単位での時間制限。 各イテレーションにより多くの時間を必要とする大規模なデータセットの場合は、この値を大きくします。 |
| experiment_timeout_hours | 0.3 | すべてのイテレーションを組み合わせて、実験が終了するまでにかかる最大時間 (時間単位)。 |
| enable_early_stopping | True | 短期間でスコアが向上していない場合に、早期終了を有効にするフラグ。 |
| primary_metric | spearman_correlation | 最適化したいメトリック。 このメトリックに基づいて、最適なモデルが選択されます。 |
| featurization | 自動 | auto を使用すると、実験の入力データを前処理できます (欠損データの処理、テキストから数値への変換など)。 |
| verbosity | logging.INFO | ログ記録のレベルを制御します。 |
| n_cross_validations | 5 | 検証データが指定されていない場合に実行される、クロス検証の分割の数。 |
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
定義済みのトレーニング設定を AutoMLConfig オブジェクトへの **kwargs パラメーターとして使用します。 さらに、トレーニング データとモデルの種類を指定します。モデルの種類は、ここでは regression です。
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Note
自動化された機械学習の前処理手順 (機能の正規化、欠損データの処理、テキストから数値への変換など) は、基になるモデルの一部になります。 モデルを予測に使用する場合、トレーニング中に適用されたのと同じ前処理手順が入力データに自動的に適用されます。
自動回帰モデルをトレーニングする
自分のワークスペース内に実験オブジェクトを作成します。 実験は、個々のジョブのコンテナーとして機能します。 定義済みの automl_config オブジェクトを実験に渡し、出力を True に設定してジョブ中の進行状況を表示します。
実験の開始後、その実行に伴い、表示される出力が随時更新されます。 各イテレーションでは、モデルの種類、実行継続時間、およびトレーニングの精度が表示されます。 BEST フィールドでは、メトリックの種類に基づいて、最高の実行トレーニング スコアが追跡されます。
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
結果を検索する
Jupyter ウィジェットを使用して、自動トレーニングの結果を探索します。 このウィジェットを使用すると、トレーニング精度のメトリックとメタデータと共に、各ジョブのすべてのイテレーションのグラフと表を確認できます。 さらに、ドロップダウン セレクターを使用して、主なメトリック以外にも、さまざまな精度メトリックを条件としてフィルター処理することができます。
from azureml.widgets import RunDetails
RunDetails(local_run).show()
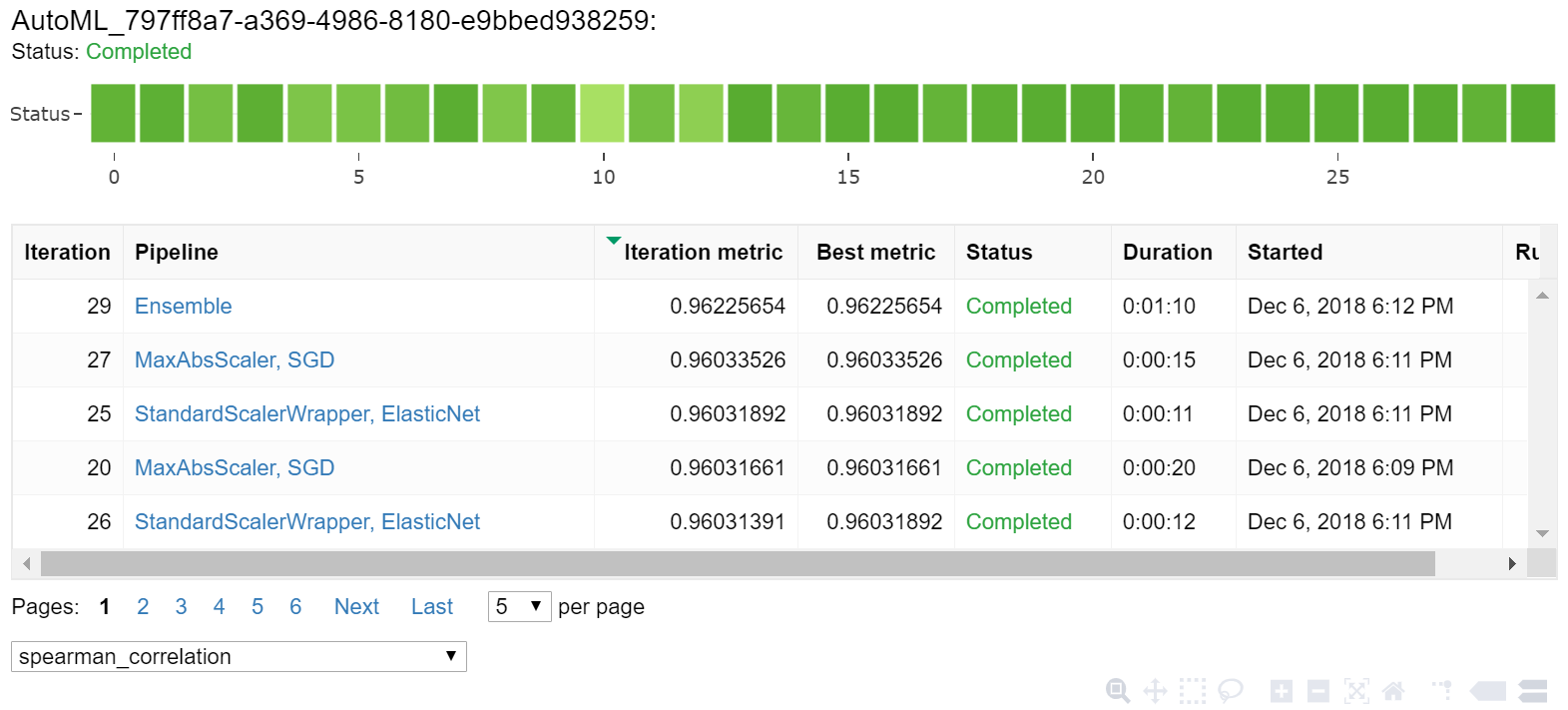
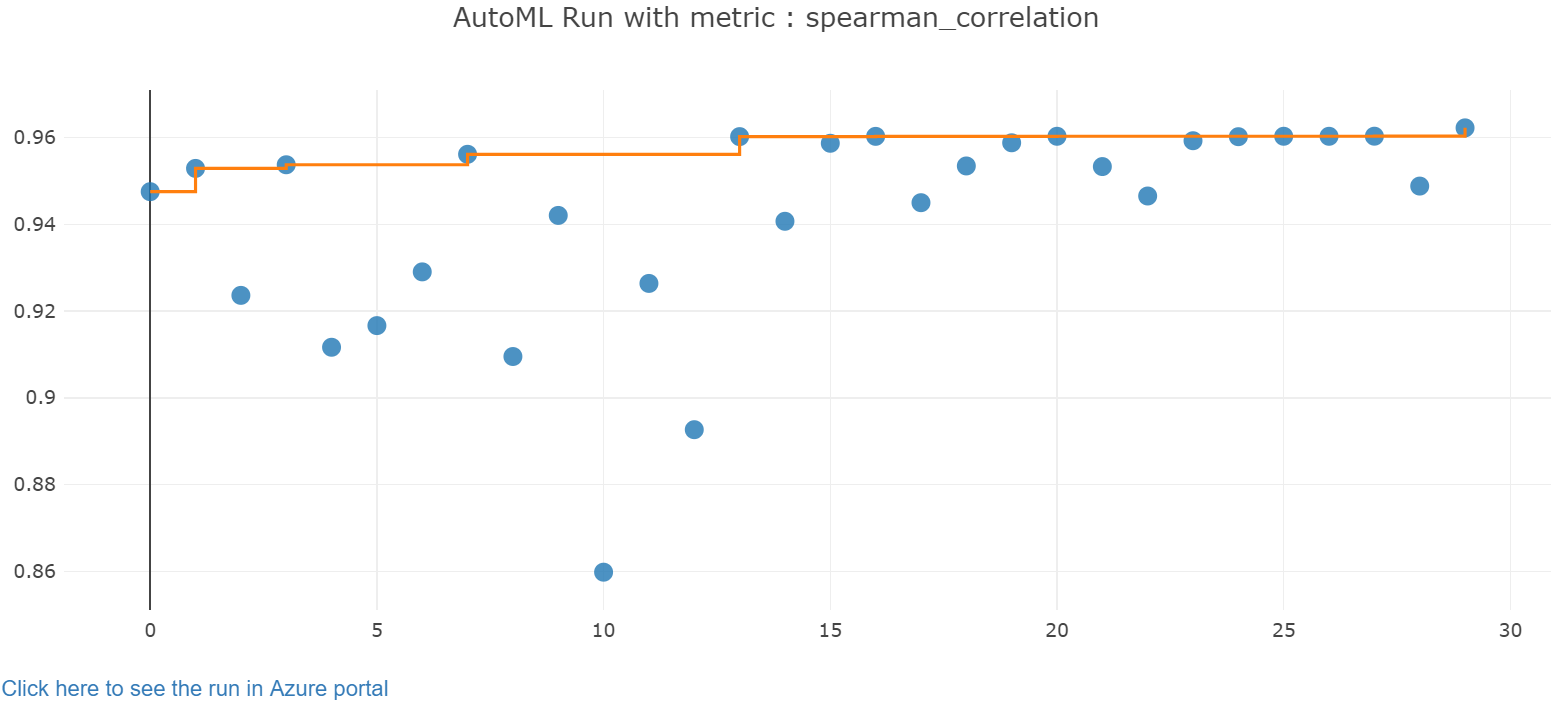
最高のモデルを取得する
イテレーションから最適なモデルを選択します。 get_output 関数は、最適な実行と、最後の fit の呼び出しで適合したモデルを返します。 get_output 上のオーバーロードを使用して、ログ記録された任意のメトリックや特定のイテレーションに対する最適な実行と適合モデルを取得できます。
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
最高のモデルの正確性をテストする
最高のモデルを使用して、テスト データ セット上で予測を実行し、タクシー料金を予測します。 関数 predict は最高のモデルを使用して、x_test データ セットから y (交通費) の値を予測します。 y_predict から最初の 10 個の予測コスト値をプリントします。
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
結果の root mean squared error を計算します。 予測値と比較するために、y_test データフレームをリストに変換します。 関数 mean_squared_error によって 2 つの配列の値が受け取られ、それらの間の平均二乗誤差が計算されます。 結果の平方根を取ると、y 変数 (コスト) と同じ単位で誤差が得られます。 これは、タクシー料金の予測が実際の料金からどの程度離れているかを大まかに示します。
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
次のコードを実行し、完全な y_actual と y_predict データ セットを使用して平均絶対誤差率 (MAPE) を計算します。 このメトリックでは、予測される各値と実際の値の間の絶対誤差が計算され、すべての差分が合計されます。 そしてその合計が、実際の値の合計に対する割合として表されます。
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
最終的な予測精度メトリックから、モデルでのデータ セットの特徴によるタクシー料金の予測はかなり良好で、誤差は ± 4 ドル (約 15%) 以内であることがわかります。
従来の機械学習モデルの開発プロセスでは、リソースが大量に消費され、数十個のモデルを実行して結果を比較するために、その領域に関する膨大な知識と時間の投資が必要とされます。 自動化された機械学習の使用は、シナリオに合わせてさまざまなモデルを迅速にテストするための優れた方法です。
リソースをクリーンアップする
Azure Machine Learning の他のチュートリアルを実行する予定の場合、このセクションを実行しないでください。
コンピューティング インスタンスの停止
コンピューティング インスタンスを使用していた場合は、使用していない VM を停止してコストを削減します。
お使いのワークスペースで、 [コンピューティング] を選択します。
一覧から、コンピューティング インスタンスの名前を選択します。
[停止] を選択します。
サーバーを再び使用する準備が整ったら、 [開始] を選択します。
すべてを削除する
作成したリソースを今後使用する予定がない場合は、課金が発生しないように削除します。
- Azure Portal で、左端にある [リソース グループ] を選択します。
- 作成したリソース グループを一覧から選択します。
- [リソース グループの削除] を選択します。
- リソース グループ名を入力します。 次に、 [削除] を選択します。
リソース グループは保持しつつ、いずれかのワークスペースを削除することもできます。 ワークスペースのプロパティを表示し、 [削除] を選択します。
次のステップ
自動化された機械学習に関するこの記事では、以下のタスクを学習しました。
- 実験用のワークスペースと準備されたデータを構成しました。
- カスタム パラメーターを使って、自動化された回帰モデルをローカルで使用してトレーニングしました。
- トレーニング結果を調べて確認しました。
Python を使用して Computer Vision モデルをトレーニングするために AutoML を設定する (v1)