Azure Data Factory を使用したデータ インジェスト
この記事では、Azure Data Factory を使用したデータ インジェスト パイプラインの作成に使用できるオプションについて説明します。 この Azure Data Factory パイプラインは、Azure Machine Learning で使用するデータを取り込むために使用されます。 Data Factory を使用すると、データの抽出、変換、読み込み (ETL) を簡単に実行できます。 変換されてストレージに読み込まれたデータは、Azure Machine Learning での機械学習モデルのトレーニングに使用できます。
単純なデータ変換は、データ フローなどのネイティブ Data Factory アクティビティとインストルメントを使用して処理できます。 より複雑なシナリオについては、何らかのカスタム コードを使用してデータを処理できます。 たとえば、Python や R コードです。
Azure Data Factory データ インジェスト パイプラインを比較する
インジェスト中にデータを変換するために Data Factory を使用する一般的な手法がいくつかあります。 各手法には、特定のユース ケースに適しているかどうかを判断するのに役立つ長所と短所があります。
| 手法 | 長所 | 短所 |
|---|---|---|
| Data Factory + Azure Functions | 実行時間の短い処理にのみ適している | |
| Data Factory + カスタム コンポーネント | ||
| Data Factory + Azure Databricks ノートブック |
Azure Data Factory と Azure Functions
Azure Functions を使用すると、アプリケーションのインフラストラクチャについて気にすることなく、小規模なコード (関数) を実行できます。 このオプションでは、Azure 関数にラップされたカスタム Python コードを使用してデータが処理されます。
関数は、Azure Data Factory の Azure Functions アクティビティを使用して呼び出されます。 この方法は、軽量なデータ変換に適したオプションです。
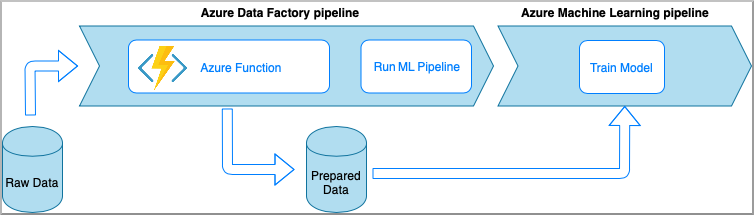
- 長所:
- データは、比較的短い待機時間でサーバーレス コンピューティングで処理されます
- Data Factory パイプラインから、高度なデータ変換フローを実装できる Durable Azure Functions を呼び出すことができます
- データ変換の詳細は、Azure Functions によって抽象化され、他の場所から再利用して呼び出すことができます
- 短所:
- Azure Functions を ADF で使用する前に作成しておく必要があります
- Azure Functions は、実行時間の短いデータ処理にのみ適しています
Azure Data Factory とカスタム コンポーネント アクティビティ
このオプションでは、実行可能ファイルにラップされたカスタム Python コードを使用してデータが処理されます。 これは、Azure Data Factory カスタム コンポーネント アクティビティを使用して呼び出されます。 この方法は、前の手法に比べて大規模なデータにより適しています。
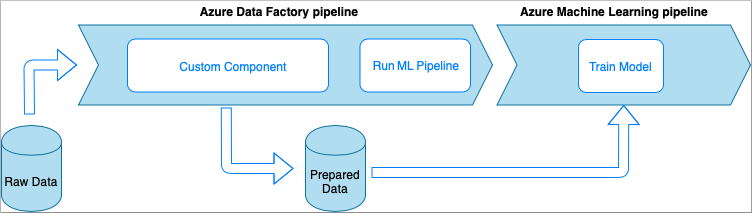
- 長所:
- データは Azure Batch プールで処理されます。これにより、大規模な並列かつハイパフォーマンス コンピューティングが実現されます
- 大量のアルゴリズムの実行や大量のデータの処理に使用できます
- 短所:
- Azure Batch プールを Data Factory で使用する前に作成しておく必要があります
- Python コードを実行可能ファイルにラップすることに関連した過度なエンジニアリング。 依存関係と入出力パラメーターの処理が複雑です
Azure Data Factory と Azure Databricks Python ノートブック
Azure Databricks は、Microsoft クラウドの Apache Spark ベースの分析プラットフォームです。
この手法では、Azure Databricks クラスターで実行されている Python ノートブックによってデータ変換が実行されます。 これはおそらく、Azure Databricks サービスの能力を最大限に利用する最も一般的な方法です。 これは、大規模な分散データ処理向けに設計されています。
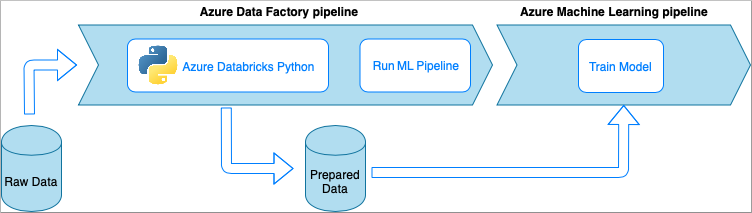
- 長所:
- データは、Apache Spark 環境によってバックアップされる、最も強力なデータ処理 Azure サービスで変換されます
- Python に加え、データ サイエンス フレームワークとライブラリ (TensorFlow、PyTorch、scikit-learn など) のネイティブ サポート
- Python コードを関数または実行可能モジュールにラップする必要はありません。 コードはそのままで動作します。
- 短所:
- Azure Databricks インフラストラクチャを Data Factory で使用する前に作成しておく必要があります
- Azure Databricks 構成によってはコストが高くなる可能性があります
- コンピューティング クラスターを "コールド" モードから起動するにはしばらく時間がかかり、ソリューションで長い待機時間が発生します
Azure Machine Learning でデータを使用する
Data Factory パイプラインを使用して、準備されたデータをクラウド ストレージ (Azure BLOB や Azure Data Lake など) に保存します。
準備されたデータを Azure Machine Learning で次のようにして使用します。
- Data Factory パイプラインから Azure Machine Learning パイプラインを呼び出します。
OR - Azure Machine Learning データストアを作成します。
Data Factory から Azure Machine Learning パイプラインを呼び出す
この方法は、機械学習の運用 (MLOps) のワークフロー用にお勧めします。 Azure Machine Learning パイプラインを設定しない場合は、「ストレージからデータを直接読み取る」を参照してください。
Data Factory パイプラインを実行するたびに、次のようになります。
- データは、ストレージ内の別の場所に保存されます。
- この場所を Azure Machine Learning に渡すために、Data Factory パイプラインから Azure Machine Learning パイプラインが呼び出されます。 ML パイプラインを呼び出すと、データの場所とジョブ ID がパラメーターとして送信されます。
- その後、ML パイプラインでデータの場所を使用して Azure Machine Learning のデータストアとデータセットを作成できます。 詳細については、「Azure Machine Learning パイプラインを Data Factory で実行する」を参照してください。
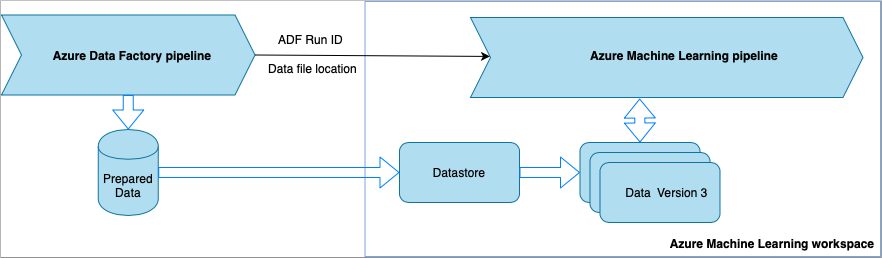
ヒント
データセットはバージョン管理をサポートしているため、ML パイプラインは ADF パイプラインからの最新のデータを指すデータセットの新しいバージョンを登録できます。
データストアまたはデータセットを使用してデータにアクセスできるようになったら、それを使用して ML モデルをトレーニングできます。 トレーニング プロセスは、ADF から呼び出されるものと同じ ML パイプラインの一部である場合があります。 または、Jupyter ノートブックでの実験など、別のプロセスである場合もあります。
データセットはバージョン管理をサポートし、パイプラインからのジョブごとに新しいバージョンが作成されるため、モデルのトレーニングに使用されたデータのバージョンを簡単に把握できます。
ストレージからデータを直接読み取る
ML パイプラインを作成しない場合は、Azure Machine Learning のデータストアとデータセットを使用して、準備されたデータが保存されているストレージ アカウントから直接データにアクセスできます。
次の Python コードは、Azure DataLake Generation 2 ストレージに接続するデータストアを作成する方法を示しています。 データストアと、サービス プリンシパルのアクセス許可を検索する場所について、詳細を確認してください。

ws = Workspace.from_config()
adlsgen2_datastore_name = '<ADLS gen2 storage account alias>' #set ADLS Gen2 storage account alias in Azure Machine Learning
subscription_id=os.getenv("ADL_SUBSCRIPTION", "<ADLS account subscription ID>") # subscription id of ADLS account
resource_group=os.getenv("ADL_RESOURCE_GROUP", "<ADLS account resource group>") # resource group of ADLS account
account_name=os.getenv("ADLSGEN2_ACCOUNTNAME", "<ADLS account name>") # ADLS Gen2 account name
tenant_id=os.getenv("ADLSGEN2_TENANT", "<tenant id of service principal>") # tenant id of service principal
client_id=os.getenv("ADLSGEN2_CLIENTID", "<client id of service principal>") # client id of service principal
client_secret=os.getenv("ADLSGEN2_CLIENT_SECRET", "<secret of service principal>") # the secret of service principal
adlsgen2_datastore = Datastore.register_azure_data_lake_gen2(
workspace=ws,
datastore_name=adlsgen2_datastore_name,
account_name=account_name, # ADLS Gen2 account name
filesystem='<filesystem name>', # ADLS Gen2 filesystem
tenant_id=tenant_id, # tenant id of service principal
client_id=client_id, # client id of service principal
次に、機械学習タスクで使用するファイルを参照するデータセットを作成します。
次のコードにより、csv ファイル prepared-data.csv から TabularDataset が作成されます。 データセットの種類と使用できるファイル形式の詳細を確認してください。
from azureml.core import Workspace, Datastore, Dataset
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
# retrieve data via Azure Machine Learning datastore
datastore = Datastore.get(ws, adlsgen2_datastore)
datastore_path = [(datastore, '/data/prepared-data.csv')]
prepared_dataset = Dataset.Tabular.from_delimited_files(path=datastore_path)
ここから、prepared_dataset を使用して、トレーニング スクリプトなどの準備されたデータを参照します。 Azure Machine Learning データセットを使用してモデルをトレーニングする方法を確認してください。