Dataverse データを Azure SQL へコピーする
Azure Synapse Link を使用して自分の Microsoft Dataverse データを Azure Synapse Analytics に接続し、データを探索したり分析情報の取得時間の短縮したりできます。 この記事では、Azure Synapse Link で有効になった増分更新機能を使用して、Azure Data Lake Storage Gen2 から Azure SQL データベースにデータをコピーするために Azure Synapse パイプラインまたは Azure Data Factory を実行する方法を示します。
注意
Azure Synapse Link for Microsoft Dataverse は以前は、Data Lake へのエクスポートと呼ばれていました。 このサービスは、2021 年 5 月より名称が変更され、Azure Synapse Analytics だけでなく、Azure Data Lake へのデータのエクスポートも継続されます。 このテンプレートはコード サンプルです。 このテンプレートをガイダンスとして使用し、提供されたパイプラインで Azure Data Lake Storage Gen2 から Azure SQL Database にデータを取得する機能をテストすることをお勧めします。
前提条件
- Azure Synapse Link for Dataverse。 このガイドは、Azure Data Lake を使用して Azure Synapse Link を作成するための前提条件をすでに満たしていることを前提としています。 詳細: Azure Data Lake の Azure Synapse Link for Dataverse の前提条件
- Power Apps テナントと同じ Microsoft Entra テナントで、Azure Synapse Workspace または Azure Data Factory を作成します。
- 増分フォルダー更新が有効 を使用して Azure Synapse Link for Dataverse を作成し、時間間隔を設定します。 詳細: 増分更新のクエリと分析
- トリガーには Microsoft.EventGrid プロバイダーを登録する必要があります。 詳細情報については、Azure portal を参照してください。 注意: Azure Synapse Analytics でこの機能を使用する場合、サブスクリプションがデータ ファクトリーのリソース プロバイダにも登録されていることを確認してください。そうでない場合、「イベント サブスクリプション」の作成が失敗したというエラーが表示されます。
- Azure サービスおよびリソースがこのサーバーにアクセスすることを許可するプロパティを有効にして Azure SQL データベースを作成します。 詳細情報: Azure SQLデータベース (PaaS) をセットアップする際に知っておくべきことは何ですか?
- Azure Integration Runtime を作成して構成します。 詳細情報: Azure Integration Runtime の作成 - Azure Data Factory & Azure Synapse
重要
このテンプレートを使用すると、追加費用が発生する場合があります。 これらのコストは、Azure Data Factory または Synapse ワークスペース パイプラインの使用に関連し、月単位で請求されます。 パイプラインを使用するコストは、主に増分更新の時間間隔とデータ量によって異なります。 この機能の使用にともなうコストの計画と管理を行う場合は、コスト分析を使用してパイプライン レベルでコストを監視する に移動します
これらの追加費用はオプションではなく、この機能を引き続き使用する場合に支払う必要があるため、このテンプレートの利用を決定する際は、これらの追加費用を考慮することが重要です。
ソリューションのテンプレートを使用する
- Azure ポータル に移動して Azure Synapse workspace を開きます。
- 統合 > ギャラリーを参照 を選択します。
- 統合ギャラリーからSynapse Link を使用して Dataverse データを Azure SQL にコピーを選択します。
ソリューション テンプレートを構成する
適切な認証タイプを使用して Dataverse に接続される、Azure Data Lake Storage Gen2 へのリンクされたサービスを作成します。 これを行うには、接続をテストして接続を検証するを選択し、作成を選択します。
前の手順と同様に、Dataverse データが同期される Azure SQL Database へのリンクされたサービスを作成します。
入力を構成したら、このテンプレートを使用を選択します。
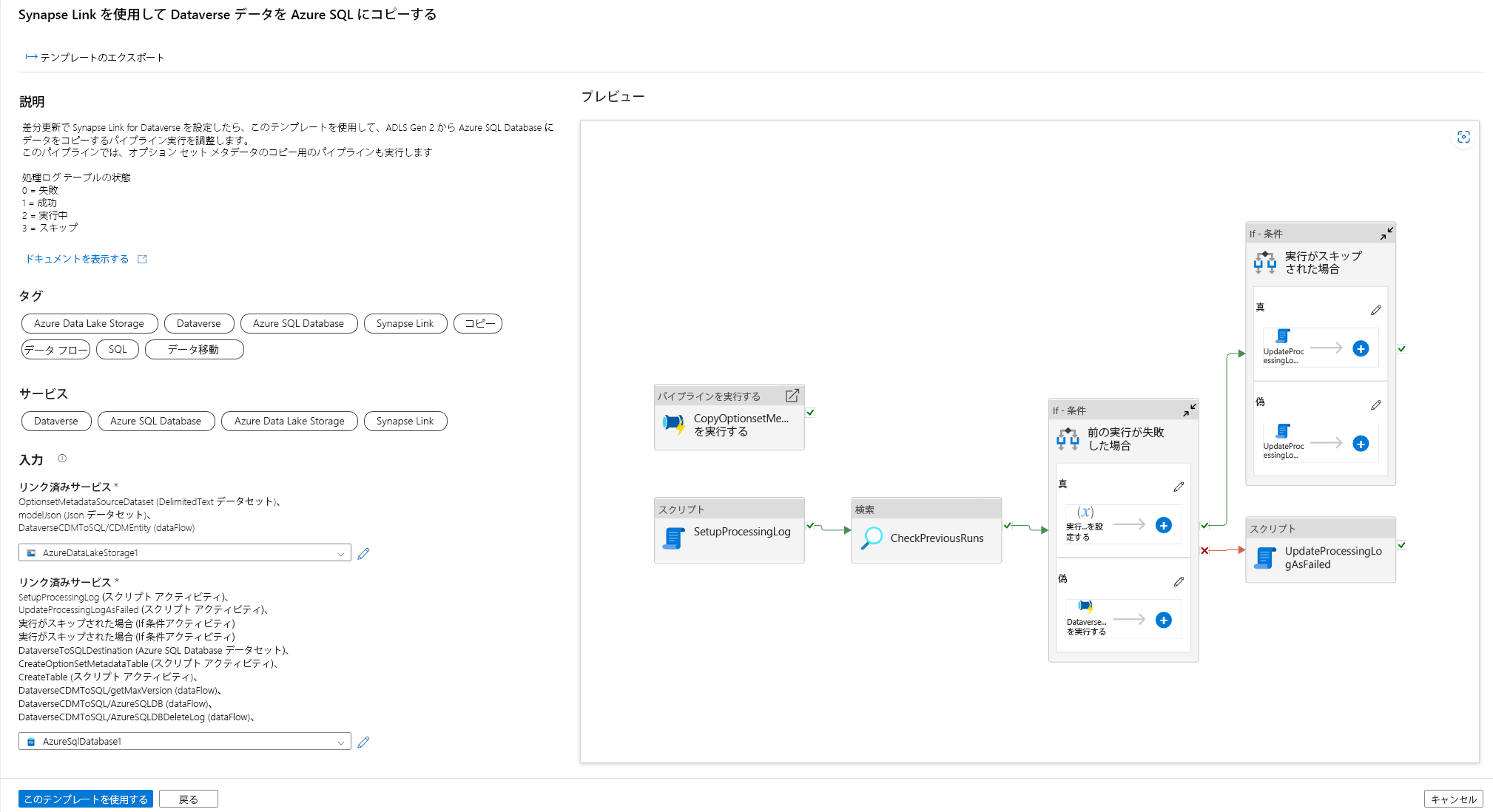
このパイプラインを自動化するためのトリガーを追加できるようになりました。これにより、増分更新が定期的に完了したとき、パイプラインが常にファイルを処理できるようになります。 管理 > トリガーに移動し、次のプロパティを使用してトリガーを作成します。
- 名前: triggerModelJson など、トリガーの名前を入力します。
- 種類: ストレージ アイベント。
- Azure サブスクリプション: Azure Data Lake Storage Gen2 を持つサブスクリプションを選択します。
- ストレージ アカウント名: Dataverse データを持つストレージを選択します。
- コンテナ名: Azure Synapse Link によって作成されたコンテナーを選択します。
- BLOB パスの末尾: /model.json
- イベント: 作成された Blob。
- 空の Blob を無視: はい。
- トリガーの開始: 作成時にトリガーを開始を有効にします。
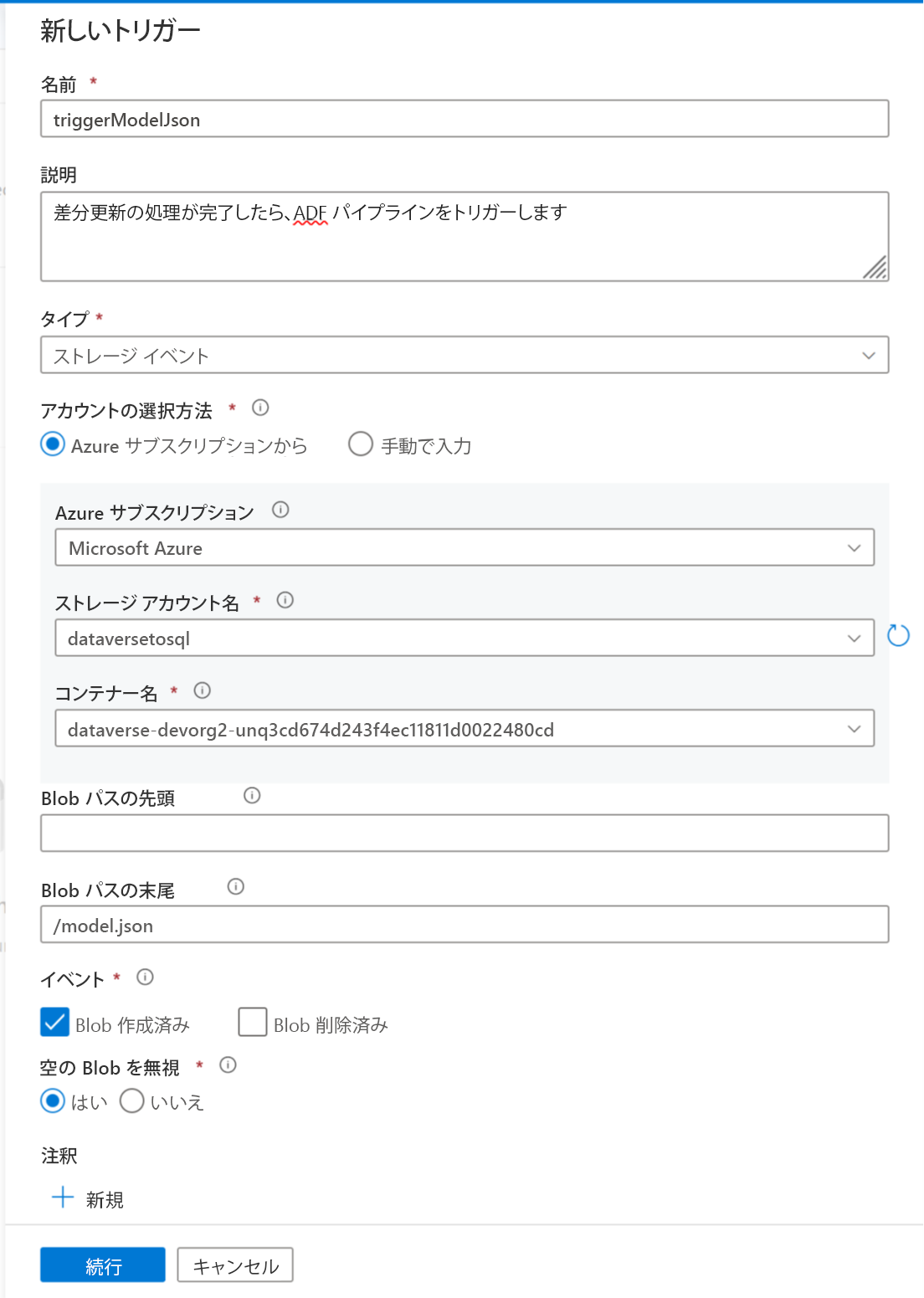
続行を選択して、次の画面に進みます。
次の画面で、トリガーは一致するファイルを検証します。 OK を選択して、トリガーを作成します。
トリガーをパイプラインに関連付けます。 先ほどインポートしたパイプラインに移動し、トリガーを追加 > 新規作成/編集を選択します。
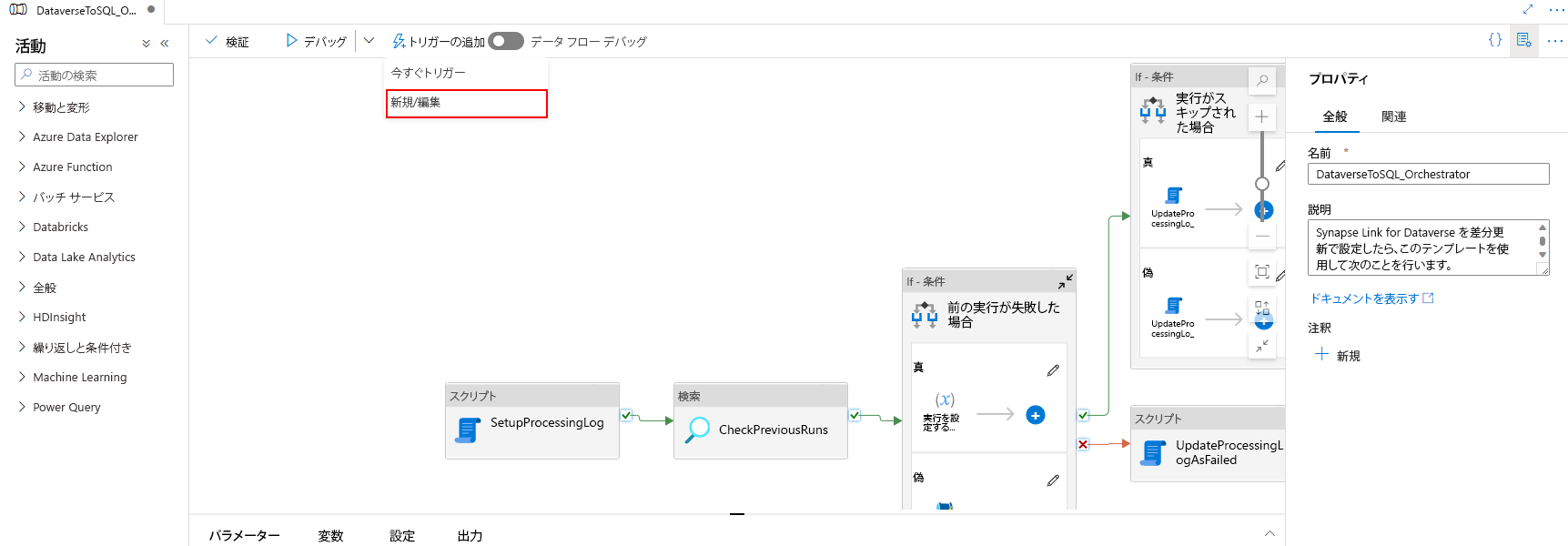
前の手順でトリガーを選択してから、続行を選択し、トリガーが一致するファイルを検証する次の画面に進みます。
続行を選択して、次の画面に進みます。
実行パラメーターのトリガーセクションで、以下のパラメーターを入力してから、OK を選択します。
- コンテナ:
@split(triggerBody().folderPath,'/')[0] - フォルダー:
@split(triggerBody().folderPath,'/')[1]
- コンテナ:
トリガーをパイプラインに関連付けた後、すべて検証を選択します。
検証が成功したら、すべて公開を選択します。
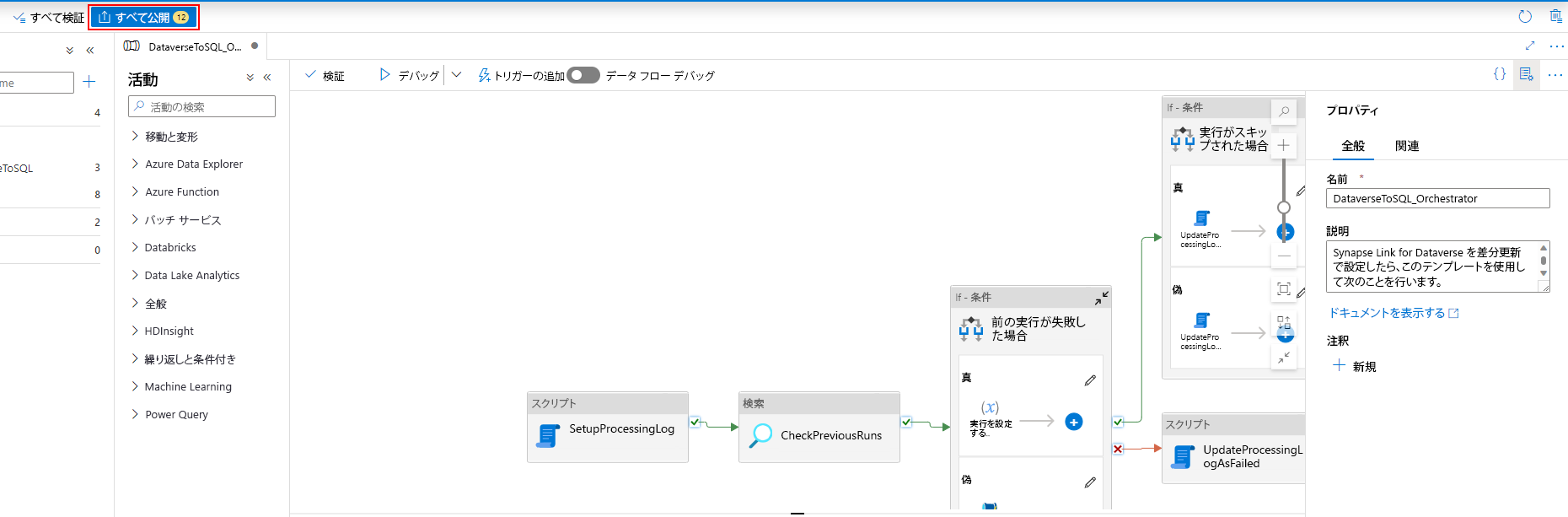
公開を選択し、すべての変更を公開します。



イベント サブスクリプション フィルターを追加する
model.json の作成が完了したときにのみトリガーが起動されるようにするには、トリガーのイベント サブスクリプションの高度なフィルターを更新する必要があります。 トリガーが初めて実行されたときに、ストレージ アカウントに対してイベントが登録されます。
トリガーの実行が完了したら、ストレージ アカウント > イベント > イベント サブスクリプションに移動します。
model.json トリガーに登録されたイベントを選択します。
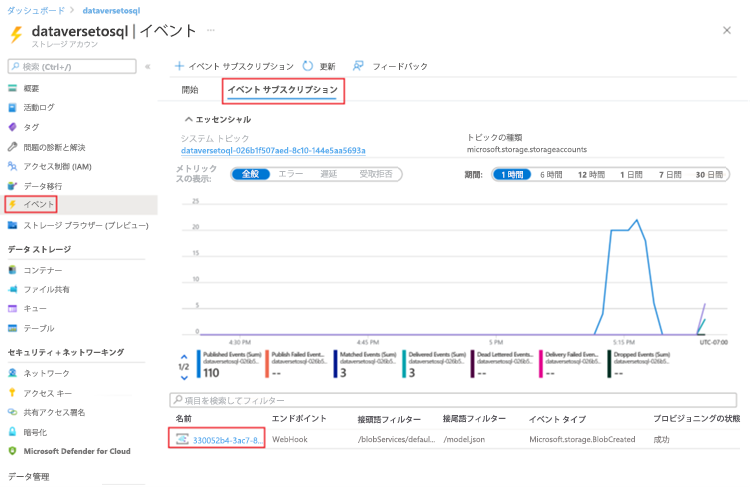
フィルター タブを選択し、+ 新しいフィルターの追加を選択します。
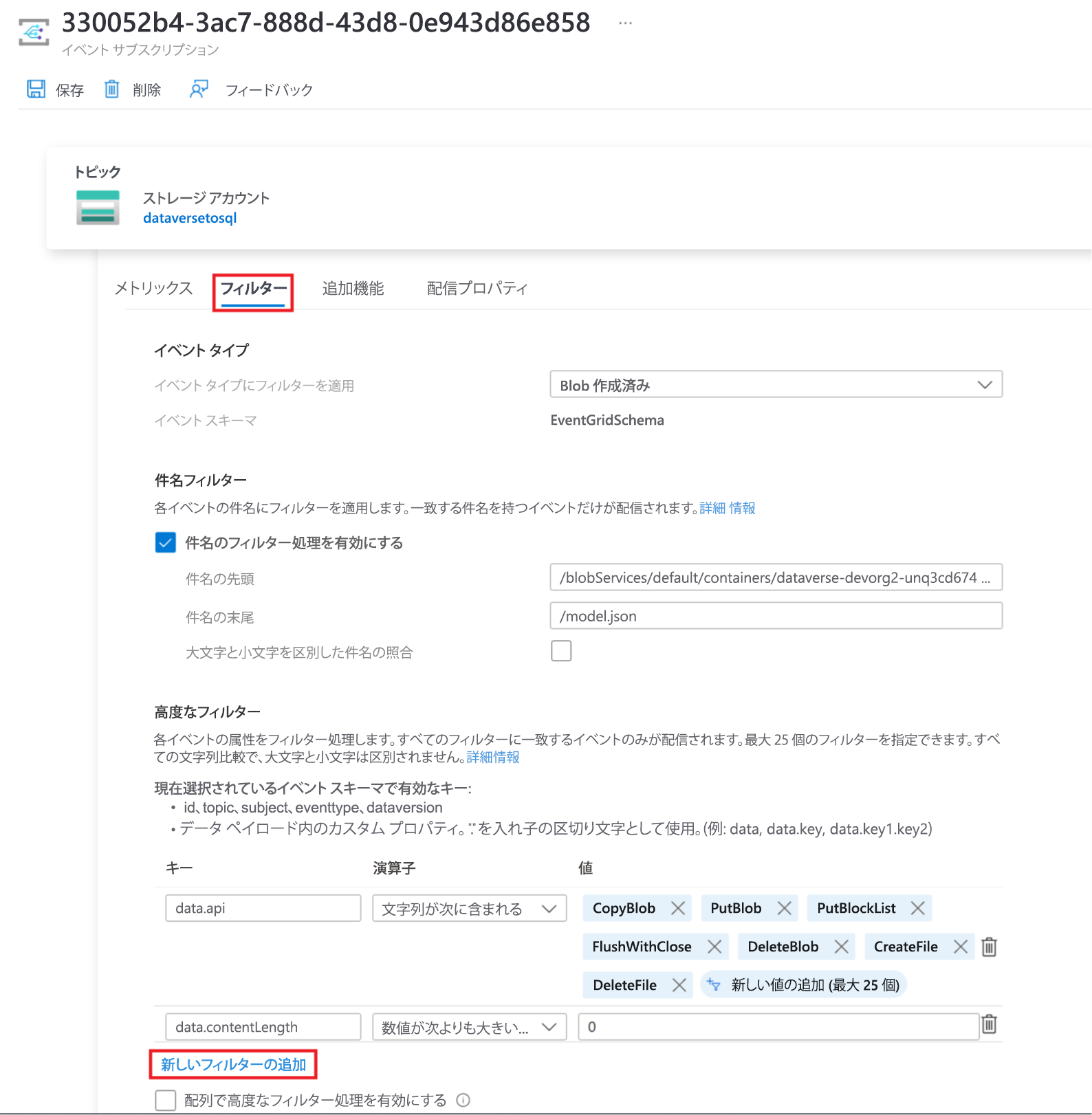
フィルターを作成します。
- キー: サブジェクト
- 演算子: 文字列の末尾は次以外
- 値: /blob/model.json
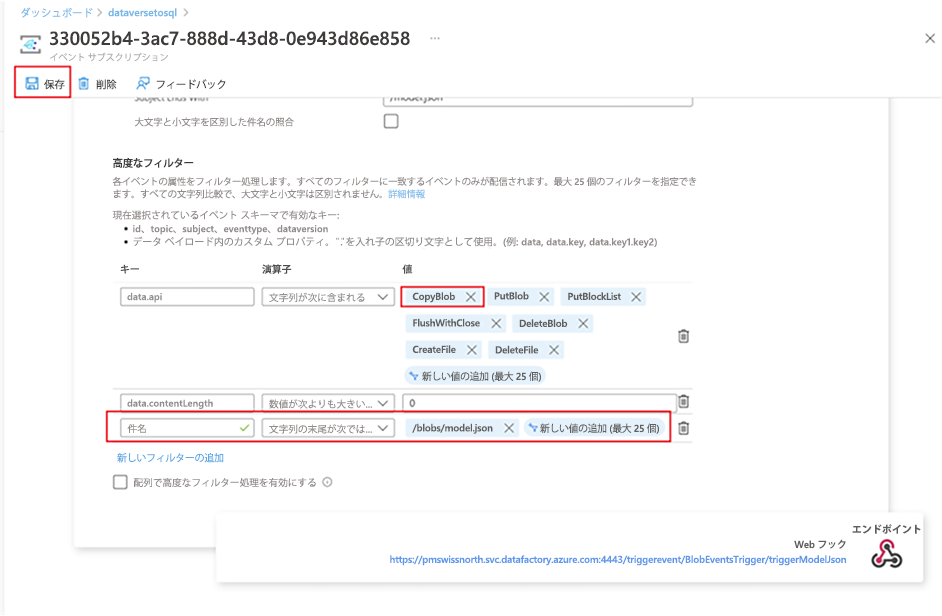
data.api 値配列から CopyBlob パラメーターを削除します。
保存を選択し、追加のフィルターを展開します。
参照
ブログ: Azure Synapse Link for Dataverse に関するお知らせ
注意
ドキュメントの言語設定についてお聞かせください。 簡単な調査を行います。 (この調査は英語です)
この調査には約 7 分かかります。 個人データは収集されません (プライバシー ステートメント)。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示