Power Query コネクタ (プレビュー - 廃止)
重要
Power Query コネクタのサポートは、Microsoft Azure プレビューの追加使用条件下で限定的なパブリック プレビューとして導入されましたが、現在は廃止されています。 Power Query コネクタを使用する検索ソリューションがある場合は、別のソリューションに移行してください。
2022 年 11 月 28 日までに移行する
Power Query コネクタのプレビューは 2021 年 5 月に発表され、一般提供に進む予定はありません。 Snowflake と PostgreSQL には、次の移行ガイダンスを使用できます。 別のコネクタを使用していて、移行手順が必要な場合は、プレビュー サインアップで提供されているメール連絡先情報を使用して、ヘルプを要求するか、Azure サポートでチケットを開いてください。
前提条件
- Azure Storage のアカウント ストレージ アカウントがない場合は、作成します。
- Azure Data Factory。 Data Factory がない場合は、作成します。 実装前に Data Factory パイプラインの価格に関するページを参照して、関連コストを理解してください。 例からの Data Factory の価格に関するページも確認してください。
Snowflake データ パイプラインを移行する
このセクションでは、Snowflake データベースから Azure Cognitive Search インデックスにデータをコピーする方法について説明します。 Snowflake から Azure Cognitive Search に直接インデックスを作成するプロセスはないため、このセクションには、データベース コンテンツを Azure Storage BLOB コンテナーにコピーするステージング フェーズが含まれています。 次に、Data Factory パイプラインを使用して、そのステージング コンテナーからインデックスを作成します。
手順 1: Snowflake データベース情報を取得する
Snowflake に移動し、Snowflake アカウントにサインインします。 Snowflake アカウントは 、https://< account_name>.snowflakecomputing.com のようになります。
サインインしたら、左側のウィンドウから次の情報を収集します。 この情報は、次の手順で必要になります。
- [データ] から [データベース] を選択し、データベース ソースの名前をコピーします。
- 管理から、[ユーザー] & [ロール] を選択し、ユーザーの名前をコピーします。 ユーザーが読み取りアクセス許可を持っていることを確認します。
- [管理者] で、[アカウント] を選択し、アカウントの LOCATOR 値をコピーします。
https://app.snowflake.com/<region_name>/xy12345/organization)のような Snowflake URL から、 リージョン名をコピーします。 たとえば、https://app.snowflake.com/south-central-us.azure/xy12345/organizationでリージョン名はsouth-central-us.azureです。- [管理者] から [ウェアハウス] を選択し、ソースとして使用するデータベースに関連付けられているウェアハウスの名前をコピーします。
手順 2: Snowflake のリンク サービスを構成する
Azure アカウントを使用して Azure Data Factory Studio にサインインします。
データ ファクトリを選択し、[続行] を選択します。
左側のメニューから、[管理] アイコンを選択します。
![Azure Data Factory の [管理] アイコンを選択して Snowflake Linked Service を構成する方法を示すスクリーンショット。](media/search-power-query-connectors/azure-data-factory-manage-icon.png)
[リンク サービス] で [新規] を選択します。
![Azure Data Factory で [新しいリンク サービス] を選択する方法を示すスクリーンショット。](media/search-power-query-connectors/new-linked-service.png)
右側のウィンドウで、データ ストアの検索に「snowflake」と入力します。 [Snowflake] タイルを選択し、[続行] を選択します。
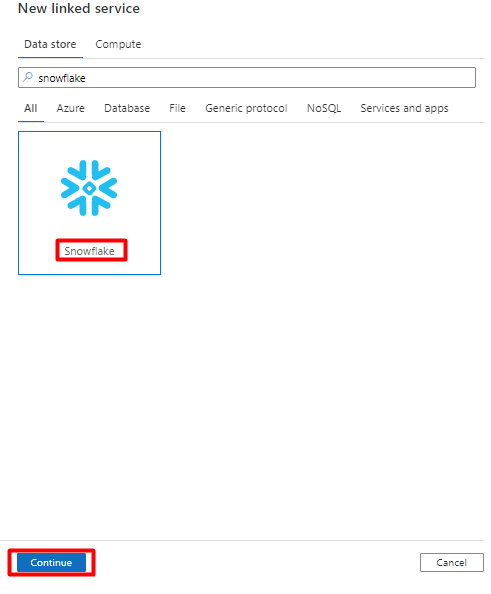
[新しいリンク サービス] フォームに、前の手順で収集したデータを入力します。 [アカウント名] には LOCATOR 値とリージョン (例:
xy56789south-central-us.azure) が含まれます。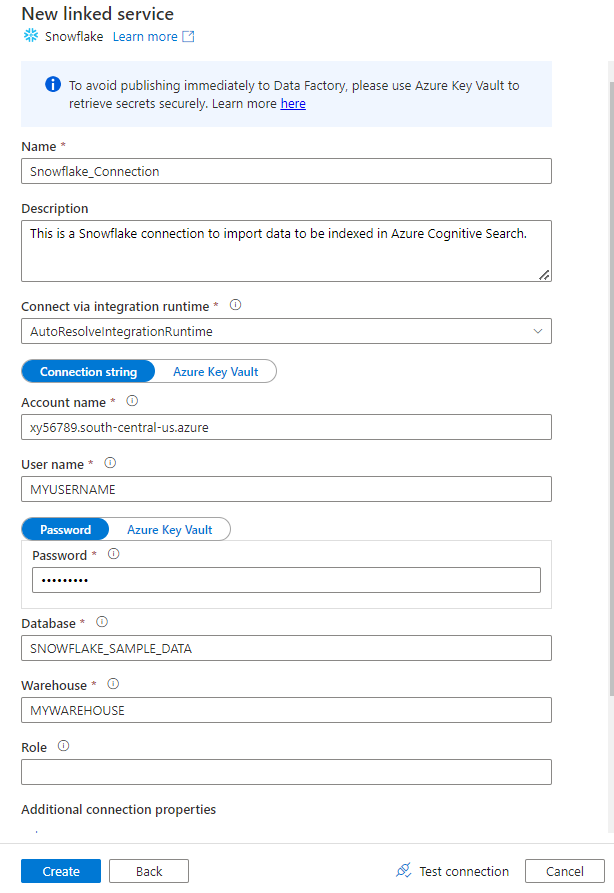
フォームが完成したら、[接続のテスト] を選択します。
テストが成功した場合は、[作成] を選択します。
手順 3: Snowflake データセットを構成する
左側のメニューから、[作成者] アイコンを選択します。
[データセット] を選択し、[データセット アクション] の省略記号メニュー (
...) を選択します。![[作成者] アイコンと [データセット] オプションを選択する方法を示すスクリーンショット。](media/search-power-query-connectors/author-datasets.png)
新しいデータセットを選択します。
右側のウィンドウで、データ ストアの検索に「snowflake」と入力します。 [Snowflake] タイルを選択し、[続行] を選択します。
[プロパティの設定] で:
- 手順 2 で作成したリンク サービスを選択します。
- インポートするテーブルを選択し、[OK] を選択します。
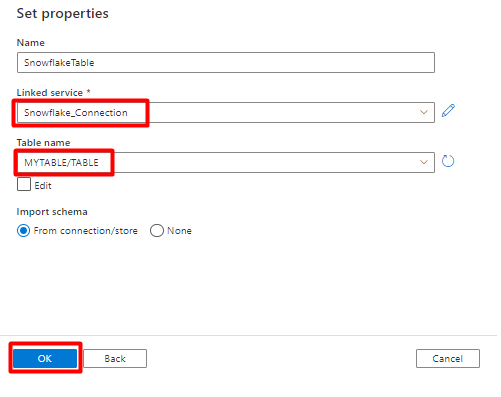
[保存] を選択します。
手順 4: Azure Cognitive Search で新しいインデックスを作成する
現在 Snowflake データ用に構成したスキーマと同じスキーマを使用して、Azure Cognitive Search サービスに新しいインデックスを作成します。
Snowflake Power Connector に現在使用しているインデックスを再利用できます。 Azure portal で、インデックスを見つけて、[インデックス定義 (JSON)] を選択します。 定義を選択し、新しいインデックス要求の本文にコピーします。
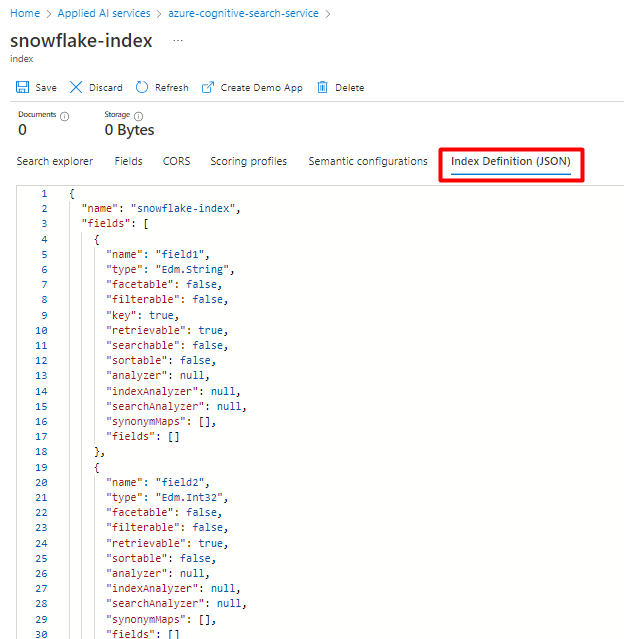
手順 5: Azure Cognitive Search リンク サービスを構成する
左側のメニューから、[管理] アイコンを選択します。
[リンク サービス] で [新規] を選択します。
右側のウィンドウで、データ ストアの検索に「search」と入力します。 [Azure Search] タイルを選択し、[続行] を選択します。
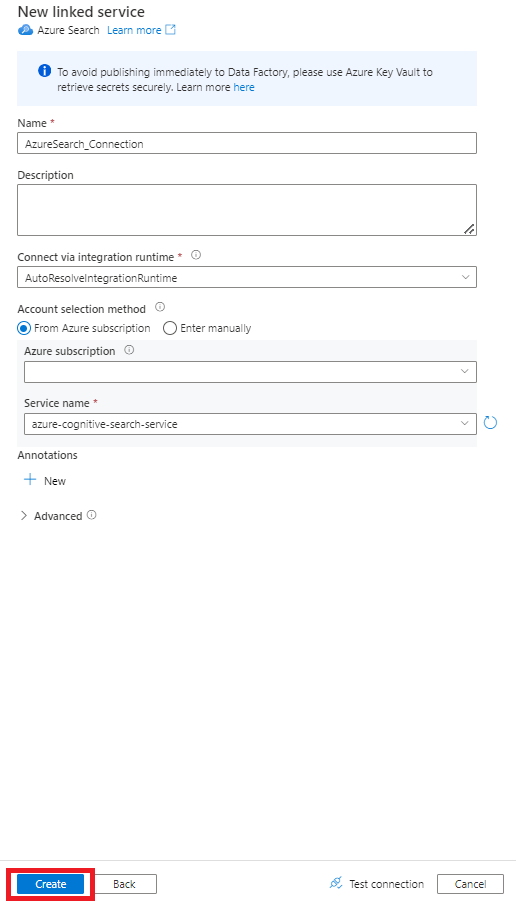
[新しいリンク サービス] の値を入力します。
- Azure Cognitive Search サービスが存在する Azure サブスクリプションを選択します。
- Power Query コネクタ インデクサーがある Azure Cognitive Search サービスを選択します。
- [作成] を選択します
手順 6: Azure Cognitive Search データセットを構成する
左側のメニューから、[作成者] アイコンを選択します。
[データセット] を選択し、[データセット アクション] の省略記号メニュー (
...) を選択します。
新しいデータセットを選択します。
右側のウィンドウで、データ ストアの検索に「search」と入力します。 [Azure Search] タイルを選択し、[続行] を選択します。
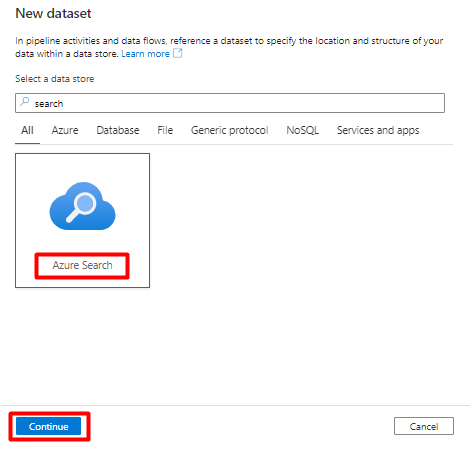
[プロパティの設定] で:
[保存] を選択します。
手順 7: Azure Blob Storage リンク サービスを構成する
左側のメニューから、[管理] アイコンを選択します。
[リンク サービス] で [新規] を選択します。
右側のウィンドウで、データ ストアの検索に「storage」と入力します。 [Azure Blob Storage] タイルを選択し、[続行] を選択します。
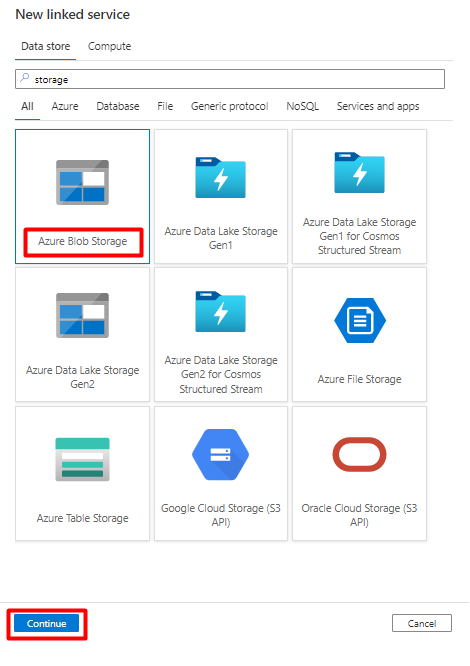
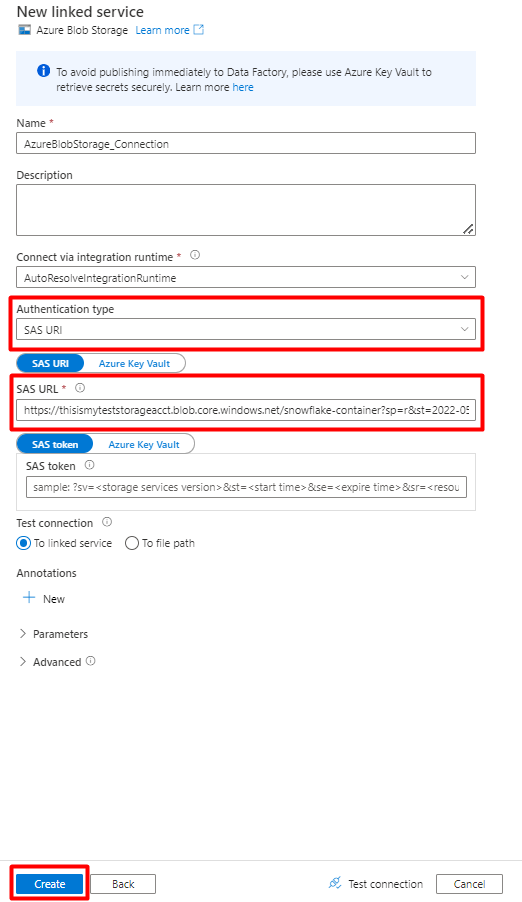
[新しいリンク サービス] の値を入力します。
[認証の種類] の [SAS URI] を選択します。 Snowflake から Azure Blob Storage にデータをインポートするために使用できるのは、この認証の種類だけです。
ステージングに使用するストレージ アカウントの SAS URL を生成します。 [SAS URL] フィールドに BLOB SAS URL を貼り付けます。
[作成] を選択します
手順 8: Storage データセットを構成する
左側のメニューから、[作成者] アイコンを選択します。
[データセット] を選択し、[データセット アクション] の省略記号メニュー (
...) を選択します。
新しいデータセットを選択します。
右側のウィンドウで、データ ストアの検索に「storage」と入力します。 [Azure Blob Storage] タイルを選択し、[続行] を選択します。
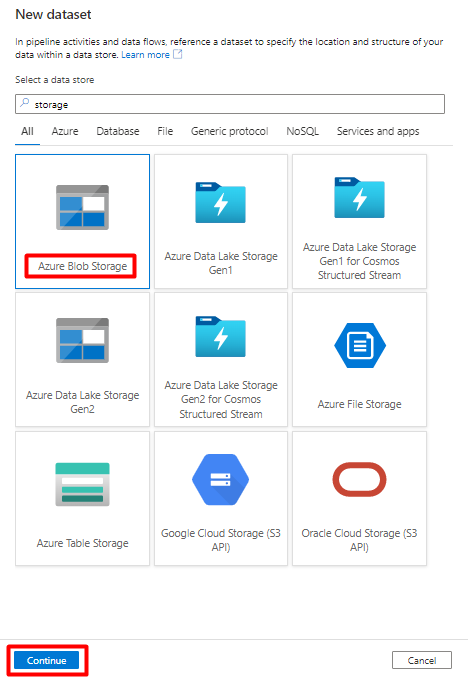
[DelimitedText] 形式を選択し、[続行] を選択します。
[プロパティの設定] で:
[リンク サービス]で、手順 7 で作成したリンク サービスを選択します。
[ファイル パス] で、ステージング プロセスのシンクとなるコンテナーを選択し、[OK] を選択します。
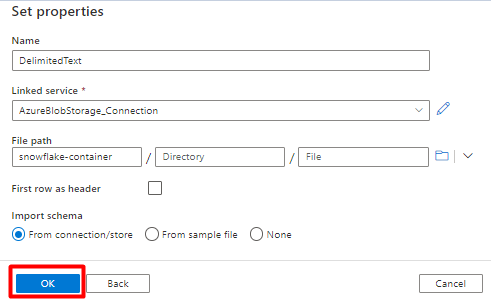
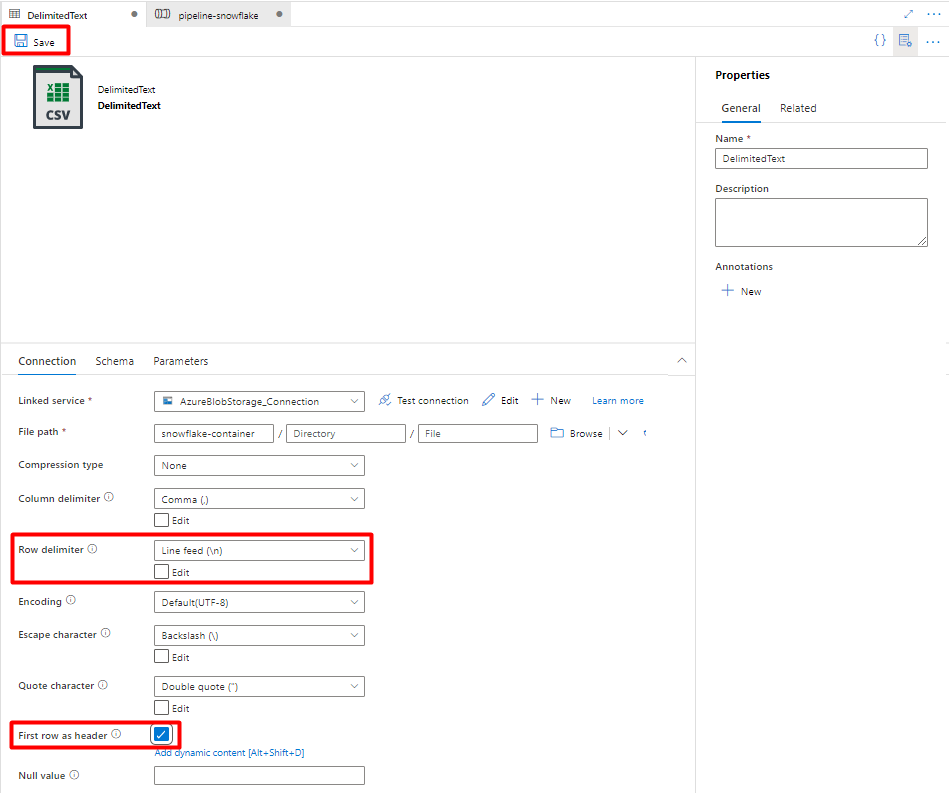
[行区切り記号] で [改行 (\n)] を選択します。
[先頭の行を見出しとして使用] ボックスをオンにします。
[保存] を選択します。
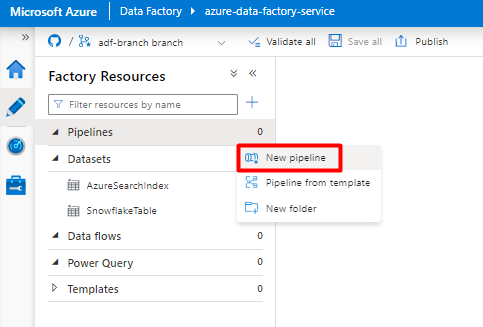
手順 9 : パイプラインを構成する
左側のメニューから、[作成者] アイコンを選択します。
[Pipelines] を選択し、[Pipelines アクション] の省略記号メニュー (
...) を選択します。![[作成者] アイコンと [パイプライン] オプションを選択して、Pipeline for Snowflake データ変換を構成する方法を示すスクリーンショット。](media/search-power-query-connectors/author-pipelines.png)
[新しいパイプライン] を選択します。
Snowflake から Azure Storage コンテナーにコピーする Data Factory アクティビティを作成して構成します。
[ Move & transform ] セクションを展開し、[ Copy Data]\(データのコピー \) アクティビティを空のパイプライン エディター キャンバスにドラッグ アンド ドロップします。
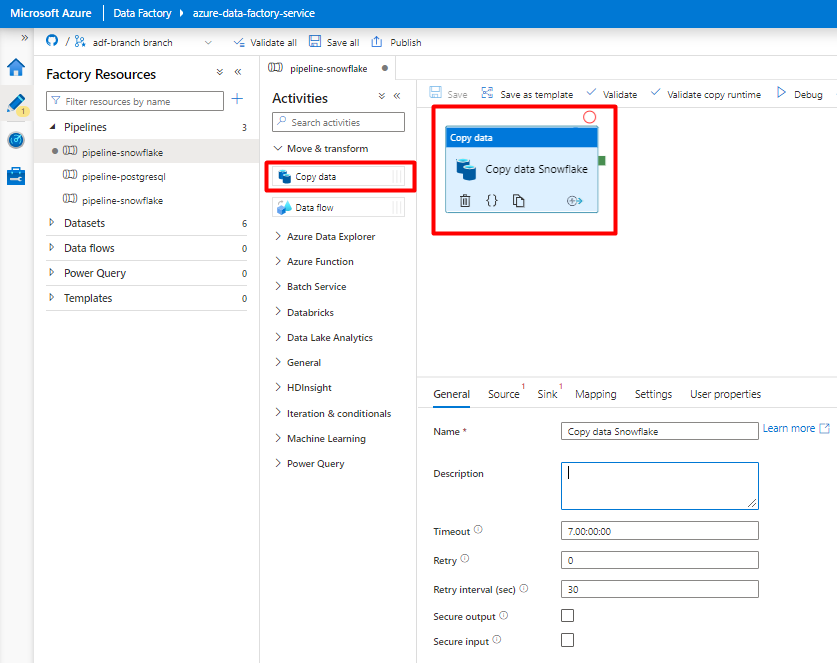
[全般] タブを開きます。実行をカスタマイズする必要がない限り、既定値をそのまま使用します。
[ソース] タブで、Snowflake テーブルを選択します。 残りのオプションは既定値のままにします。
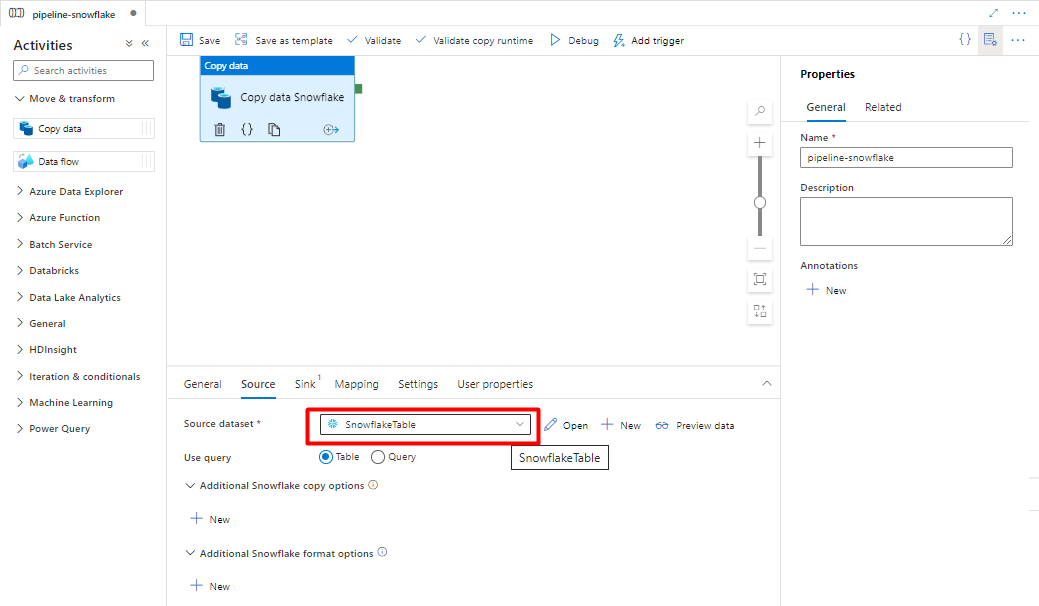
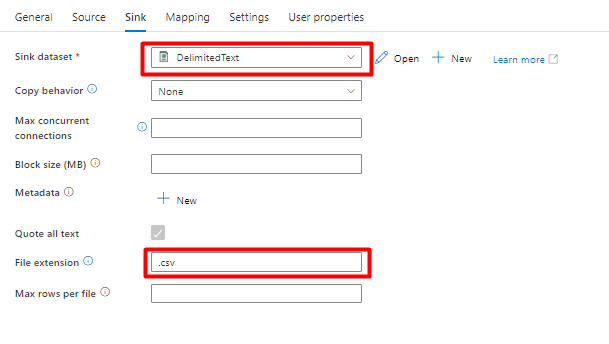
[シンク] タブで:
手順 8 で作成した Storage DelimitedText を選択します。
[ファイル拡張子] で [.csv] を追加します。
残りのオプションは既定値のままにします。
[保存] を選択します。
Azure Storage Blob から検索インデックスにコピーするアクティビティを構成します。
[ Move & transform ] セクションを展開し、[ Copy Data]\(データのコピー \) アクティビティを空のパイプライン エディター キャンバスにドラッグ アンド ドロップします。
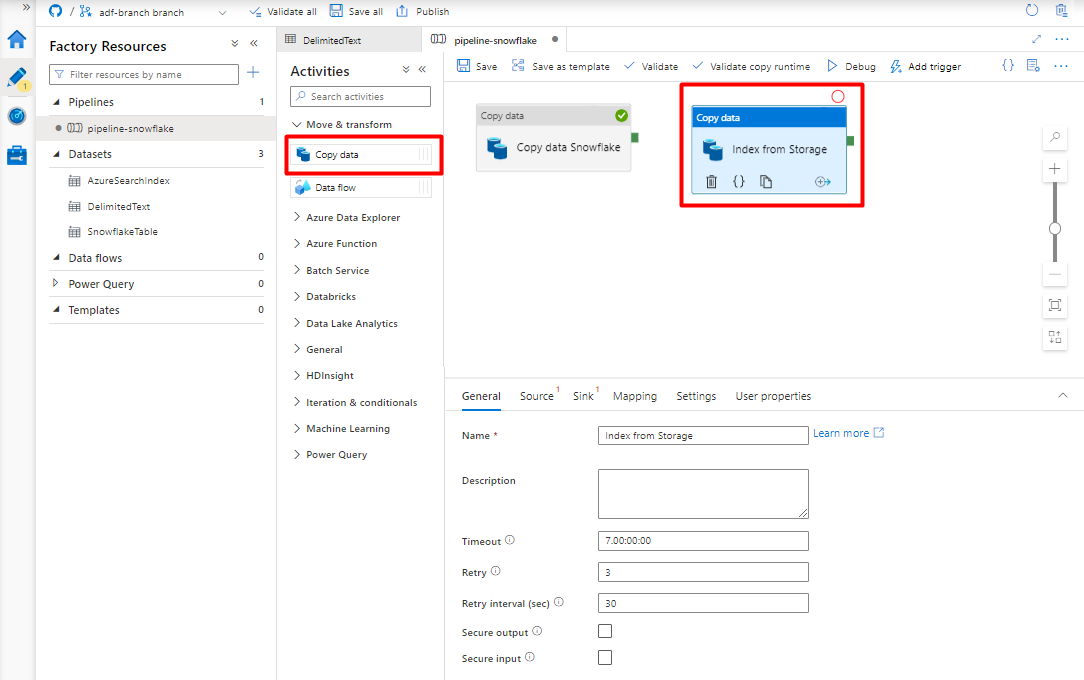
[全般] タブで、実行をカスタマイズする必要がない限り、既定値をそのまま使用します。
[ソース] タブで:
- 手順 8 で作成した Storage DelimitedText を選択します。
- [ファイル パスの種類] で、[ワイルドカード ファイル パス] を選択します。
- 残りのフィールドはすべて既定値のままにします。
[シンク] タブで、Azure Cognitive Search インデックスを選択します。 残りのオプションは既定値のままにします。
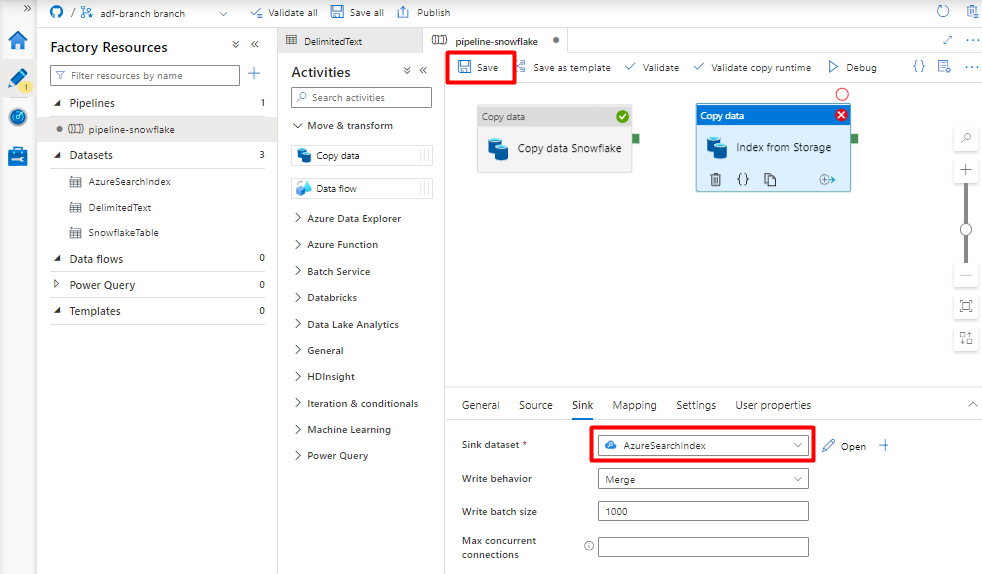
[保存] を選択します。
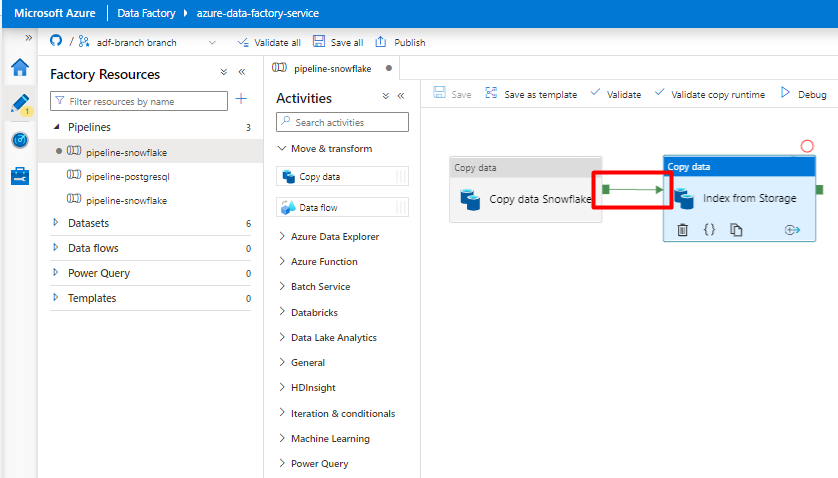
手順 10: アクティビティの順序を構成する
パイプライン キャンバス エディターで、パイプライン アクティビティ タイルの端にある小さな緑の四角形を選択します。 "Storage アカウントから Azure Cognitive Search へのインデックス" アクティビティにドラッグして、実行順序を設定します。
[保存] を選択します。
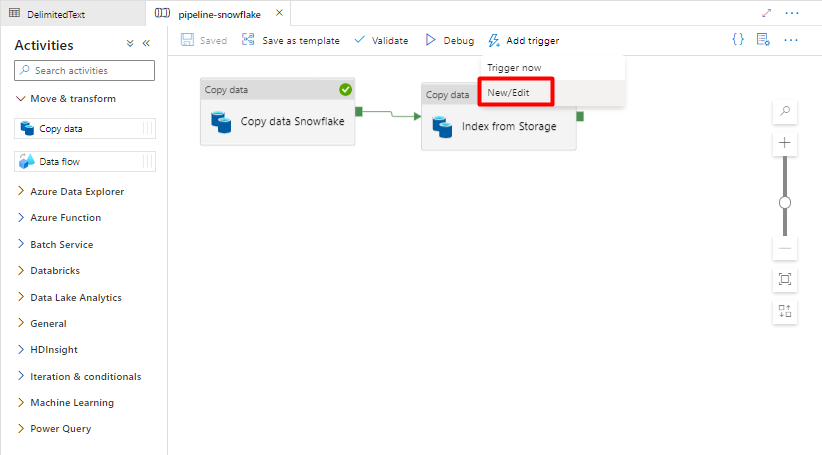
手順 11: パイプライン トリガーを追加する
[トリガーの追加] を選択してパイプラインの実行をスケジュールし、[新規/編集] を選択します。
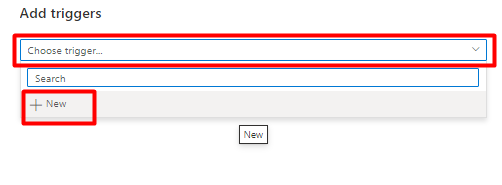
[トリガーの選択] ドロップダウンから、[新規] を選択します。
トリガー オプションを確認してパイプラインを実行し、[OK] を選択します。
[保存] を選択します。
[発行] を選択します。
PostgreSQL データ パイプラインを移行する
このセクションでは、PostgreSQL データベースから Azure Cognitive Search インデックスにデータをコピーする方法について説明します。 PostgreSQL から Azure Cognitive Search に直接インデックスを作成するプロセスはありません。そのため、このセクションには、データベース コンテンツを Azure Storage BLOB コンテナーにコピーするステージング フェーズが含まれています。 次に、Data Factory パイプラインを使用して、そのステージング コンテナーからインデックスを作成します。
手順 1: PostgreSQL リンク サービスを構成する
Azure アカウントを使用して Azure Data Factory Studio にサインインします。
データ ファクトリを選択し、[続行] を選択します。
左側のメニューから、[管理] アイコンを選択します。
[リンク サービス] で [新規] を選択します。
右側のウィンドウで、データ ストアの検索に「postgresql」と入力します。 PostgreSQL データベースが配置されている場所 (Azure またはその他) を表す PostgreSQL タイルを選択し、[続行] を選択します。 この例では、PostgreSQL データベースは Azure にあります。

[新しいリンク サービス] の値を入力します。
[アカウントの選択方法] で、[手動で入力] を選択します。
Azure portal の Azure Database for PostgreSQL の概要ページから、それぞれのフィールドに次の値を貼り付けます。
- [完全修飾ドメイン名] に "サーバー名" を追加します。
- [ユーザー名] に "管理者ユーザー名" を追加します。
- [データベース名] に "データベース名" を追加します。
- [ユーザー名パスワード] に管理者ユーザー名パスワードを入力します。
- [作成] を選択します
![Azure Data Factory の [管理] アイコンを選択する](media/search-power-query-connectors/new-linked-service-postgresql.png)
手順 2: PostgreSQL データセットを構成する
左側のメニューから、[作成者] アイコンを選択します。
[データセット] を選択し、[データセット アクション] の省略記号メニュー (
...) を選択します。
新しいデータセットを選択します。
右側のウィンドウで、データ ストアの検索に「postgresql」と入力します。 [Azure PostgreSQL] タイルを選択します。 [続行] をクリックします。

[プロパティの設定] の値を入力します。
手順 1 で作成した PostgreSQL リンク サービスを選択します。
インポートまたはインデックスを付けるテーブルを選択します。
[OK] を選択します。

[保存] を選択します。
手順 3: Azure Cognitive Search で新しいインデックスを作成する
PostgreSQL データに使用されるスキーマと同じスキーマを使用して、Azure Cognitive Search サービスに新しいインデックスを作成します。
PostgreSQL Power Connector に現在使用しているインデックスを再利用できます。 Azure portal で、インデックスを見つけて、[インデックス定義 (JSON)] を選択します。 定義を選択し、新しいインデックス要求の本文にコピーします。
手順 4: Azure Cognitive Search リンク サービスを構成する
左側のメニューから、[管理] アイコンを選択します。
[リンク サービス] で [新規] を選択します。
右側のウィンドウで、データ ストアの検索に「search」と入力します。 [Azure Search] タイルを選択し、[続行] を選択します。
[新しいリンク サービス] の値を入力します。
- Azure Cognitive Search サービスが存在する Azure サブスクリプションを選択します。
- Power Query コネクタ インデクサーがある Azure Cognitive Search サービスを選択します。
- [作成] を選択します
手順 5: Azure Cognitive Search データセットを構成する
左側のメニューから、[作成者] アイコンを選択します。
[データセット] を選択し、[データセット アクション] の省略記号メニュー (
...) を選択します。
新しいデータセットを選択します。
右側のウィンドウで、データ ストアの検索に「search」と入力します。 [Azure Search] タイルを選択し、[続行] を選択します。
[プロパティの設定] で:
[保存] を選択します。
![検索データセットの [プロパティの設定] に入力する方法を示すスクリーンショット。](media/search-power-query-connectors/set-search-postgresql-properties.png)
手順 6: Azure Blob Storage リンク サービスを構成する
左側のメニューから、[管理] アイコンを選択します。
[リンク サービス] で [新規] を選択します。
右側のウィンドウで、データ ストアの検索に「storage」と入力します。 [Azure Blob Storage] タイルを選択し、[続行] を選択します。
[新しいリンク サービス] の値を入力します。
[認証の種類] で [SAS URI] を選択します。 PostgreSQL から Azure Blob Storage にデータをインポートするために使用できる方法は、これだけです。
ステージングに使用するストレージ アカウントの SAS URL を生成して、BLOB SAS URL を SAS URL フィールドにコピーします。
[作成] を選択します
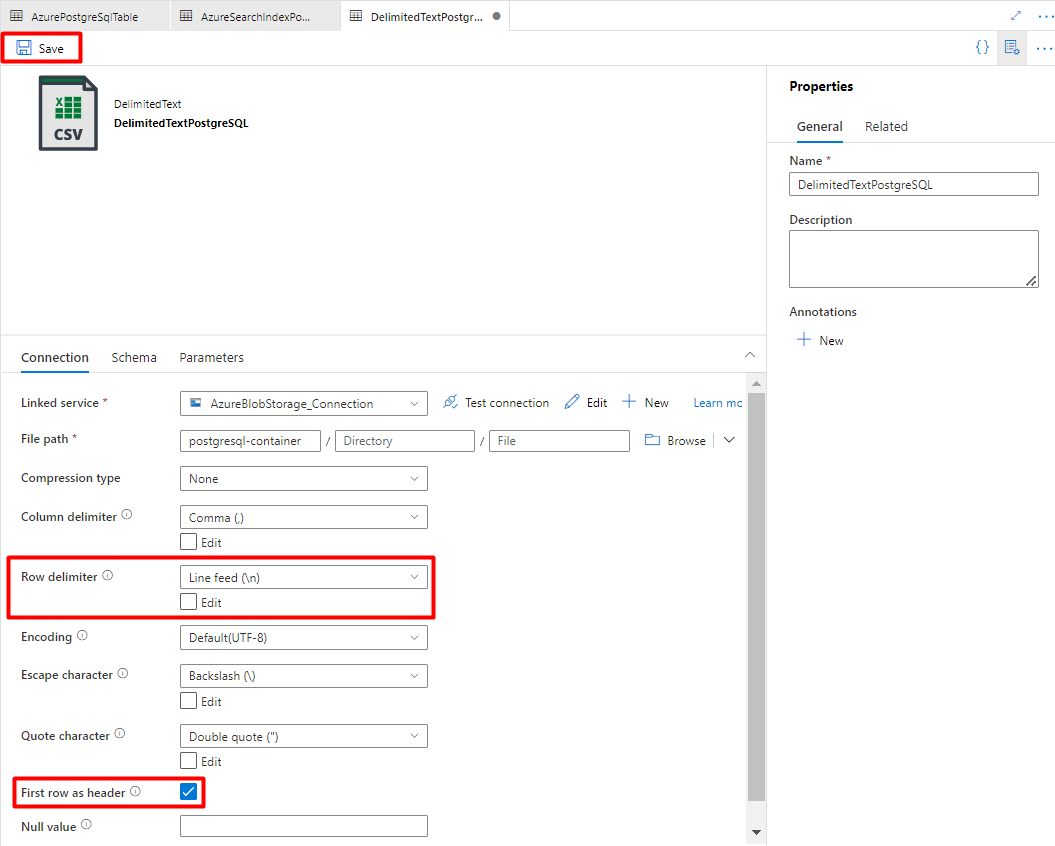
手順 7: Storage データセットを構成する
左側のメニューから、[作成者] アイコンを選択します。
[データセット] を選択し、[データセット アクション] の省略記号メニュー (
...) を選択します。
新しいデータセットを選択します。
右側のウィンドウで、データ ストアの検索に「storage」と入力します。 [Azure Blob Storage] タイルを選択し、[続行] を選択します。
[DelimitedText] 形式を選択し、[続行] を選択します。
[行区切り記号] で [改行 (\n)] を選択します。
[先頭の行を見出しとして使用] ボックスをオンにします。
[保存] を選択します。
手順 8 : パイプラインを構成する
左側のメニューから、[作成者] アイコンを選択します。
[Pipelines] を選択し、[Pipelines アクション] の省略記号メニュー (
...) を選択します。
[新しいパイプライン] を選択します。
PostgreSQL から Azure Storage コンテナーにコピーする Data Factory アクティビティを作成して構成します。
[ Move & transform ] セクションを展開し、[ Copy Data]\(データのコピー \) アクティビティを空のパイプライン エディター キャンバスにドラッグ アンド ドロップします。
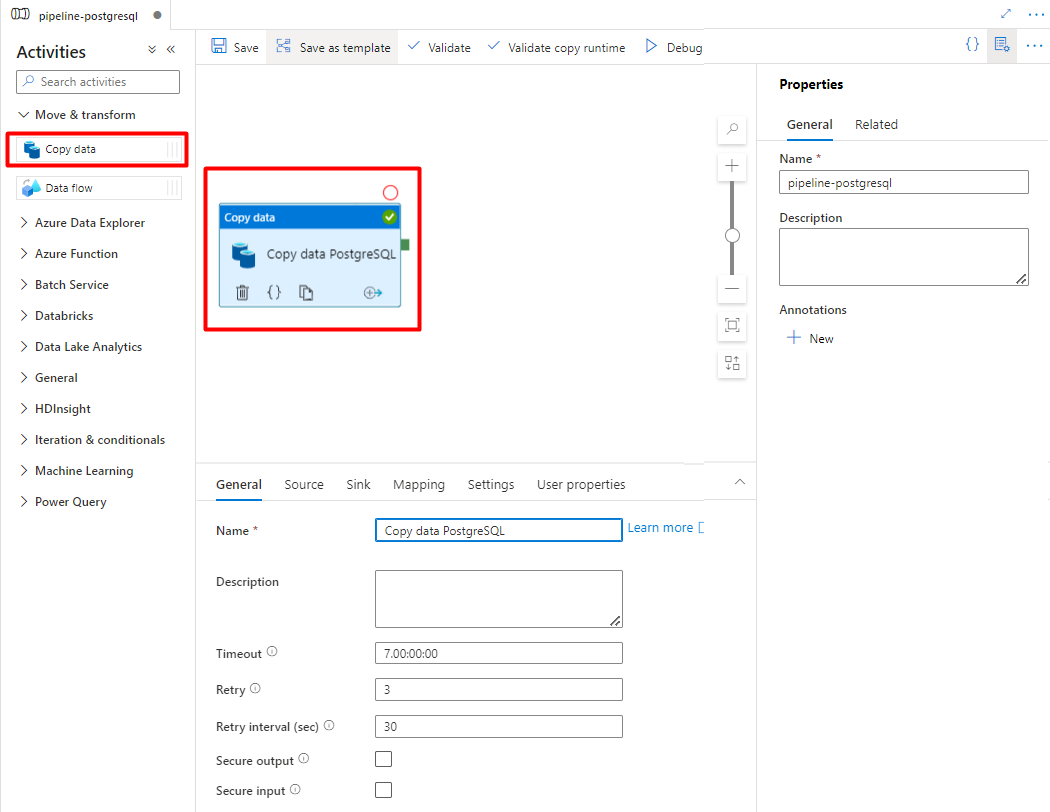
[全般] タブを開きます。実行をカスタマイズする必要がない限り、既定値をそのまま使用します。
[ソース] タブで、PostgreSQL テーブルを選択します。 残りのオプションは既定値のままにします。
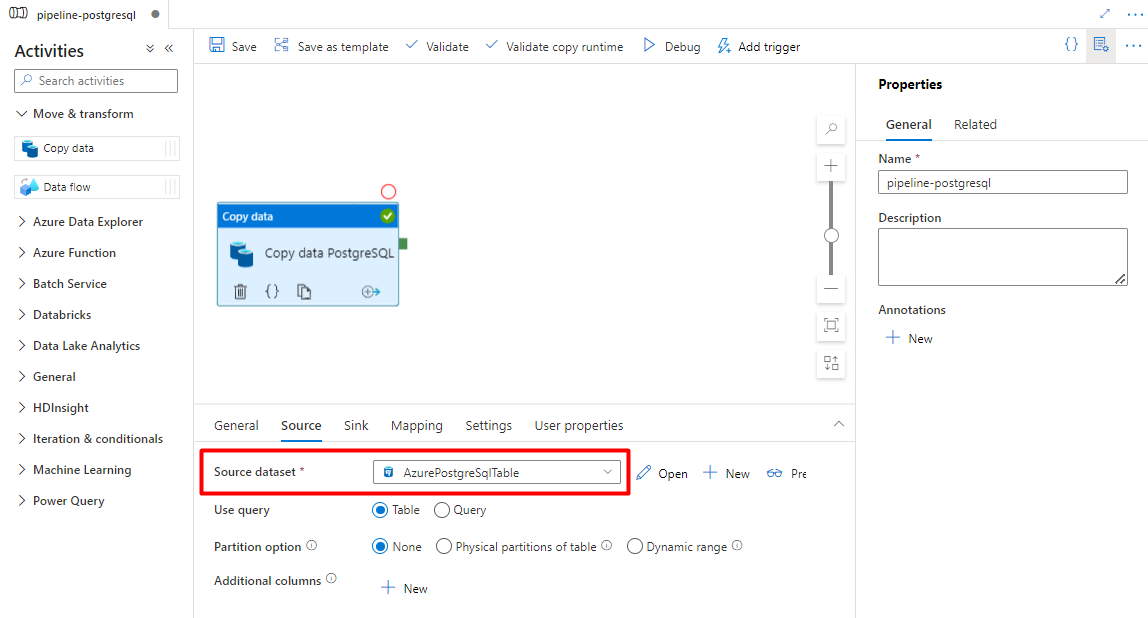
[シンク] タブで:
手順 7 で構成した Storage DelimitedText PostgreSQL データセットを選択します。
[ファイル拡張子] で [.csv] を追加します
残りのオプションは既定値のままにします。
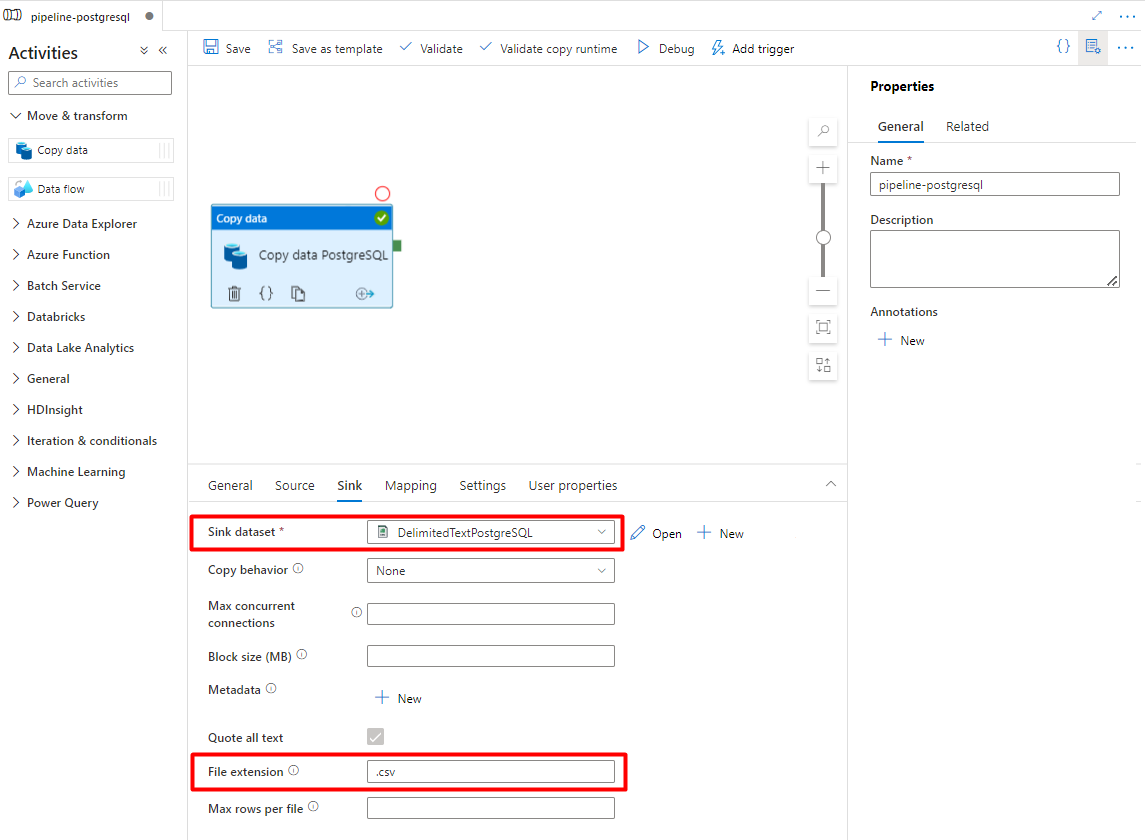
[保存] を選択します。
Azure Storage から検索インデックスにコピーするアクティビティを構成します。
[ Move & transform ] セクションを展開し、[ Copy Data]\(データのコピー \) アクティビティを空のパイプライン エディター キャンバスにドラッグ アンド ドロップします。
[全般] タブで、実行をカスタマイズする必要がない限り、既定値をそのまま使用します。
[ソース] タブで:
- 手順 7 で構成した Storage ソース データセットを選択します。
- [ファイル パスの種類] フィールドで、[ワイルドカード ファイル パス] を選択します。
- 残りのフィールドはすべて既定値のままにします。
[シンク] タブで、Azure Cognitive Search インデックスを選択します。 残りのオプションは既定値のままにします。
[保存] を選択します。
手順 9: アクティビティの順序を構成する
パイプライン キャンバス エディターで、パイプライン アクティビティの端にある小さな緑の四角形を選択します。 "Storage アカウントから Azure Cognitive Search へのインデックス" アクティビティにドラッグして、実行順序を設定します。
[保存] を選択します。
手順 10: パイプライン トリガーを追加する
[トリガーの追加] を選択してパイプラインの実行をスケジュールし、[新規/編集] を選択します。
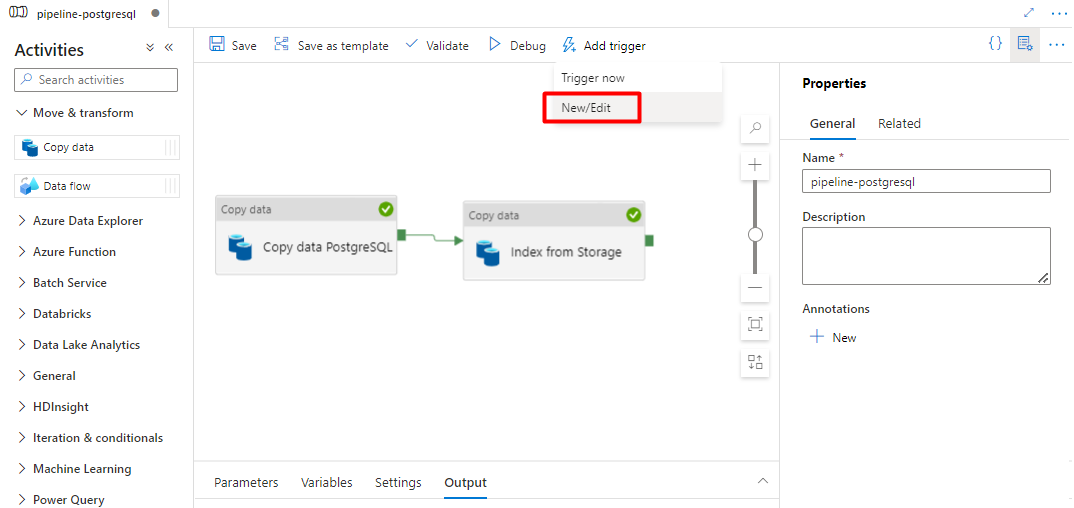
[トリガーの選択] ドロップダウンから、[新規] を選択します。
トリガー オプションを確認してパイプラインを実行し、[OK] を選択します。
[保存] を選択します。
[発行] を選択します。
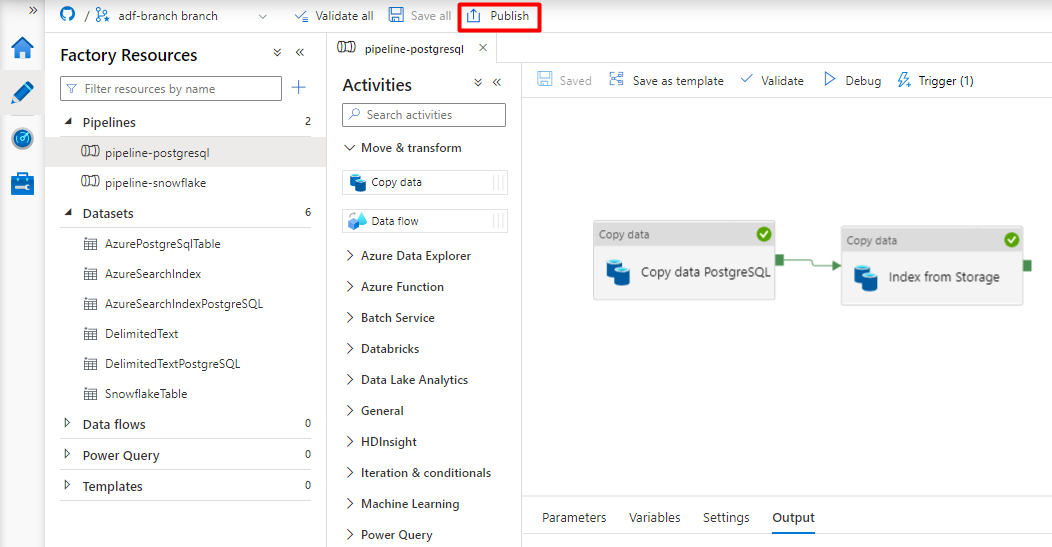
Power Query コネクタ プレビューのレガシ コンテンツ
Power Query コネクタは、検索インデクサーと共に使用され、他のクラウド プロバイダーのデータ ソースを含むさまざまなデータ ソースからのデータ インジェストを自動化します。 それにより、Power Query を使用してデータが取得されます。
プレビューでサポートされている新しいデータ ソースは次のとおりです。
- Amazon Redshift
- Elasticsearch
- PostgreSQL
- Salesforce オブジェクト
- Salesforce レポート
- Smartsheet
- Snowflake
サポートされる機能
Power Query コネクタは、インデクサーで使用されます。 Azure Cognitive Search のインデクサーは、検索可能なデータとメタデータを外部データ ソースから抽出し、インデックスとデータ ソース間のフィールド対フィールドのマッピングに基づいてインデックスを作成するクローラーです。 この方法は、インデックスにデータを追加するコードを記述することなく、サービスがデータをプルするため、「プル モデル」と呼ばれることもあります。 インデクサーは、ユーザーが独自のクローラーまたはプッシュ モデルを記述することなく、データ ソースからコンテンツのインデックスを付けるための便利な方法を提供します。
Power Query データ ソースを参照するインデクサーは、他のインデクサーでサポートされるスキルセット、スケジュール、高基準値変更検出ロジック、およびほとんどのパラメーターに対して同じレベルのサポートを提供します。
前提条件
この機能は使用できなくなりましたが、プレビュー段階では次の要件がありました。
サポートされているリージョンの Azure Cognitive Search サービス。
プレビュー登録。 バックエンドでこの機能を有効にする必要があります。
データの仲介役として使用される Azure Blob Storage アカウント。 データはデータ ソースから Blob Storage へ、その後インデックスに流れます。 この要件は、初期の限定的なプレビューにのみ存在します。
リージョン別の提供状況
プレビューは、次のリージョンの検索サービスでのみ使用できます。
- 米国中部
- 米国東部
- 米国東部 2
- 米国中北部
- 北ヨーロッパ
- 米国中南部
- 米国中西部
- 西ヨーロッパ
- 米国西部
- 米国西部 2
プレビューの制限事項
このセクションでは、プレビューの現在のバージョンに固有の制限事項について説明します。
データ ソースからバイナリ データをプルする機能はサポートされていません。
デバッグ セッションはサポートされていません。
Azure portal を使用して作業を開始する
Azure portal は、Power Query コネクタのサポートを提供しています。 コンテナー内のデータをサンプリングしてメタデータを解析することにより、Azure Cognitive Search のデータのインポートウィザードでは、既定のインデックスを作成し、ソース フィールドをターゲット インデックス フィールドにマップし、1 回の操作でインデックスを読み込むことができます。 ソース データのサイズと複雑さによっては、数分で運用可能なフルテキスト検索インデックスを作成できます。
次のビデオでは、Azure Cognitive Search で Power Query コネクタを設定する方法を紹介します。
手順 1 - ソース データを準備する
データ ソースにデータが含まれていることを確認します。 [データのインポート] ウィザードでは、メタデータが読み取られ、インデックス スキーマを推論するためにデータのサンプリングが実行されますが、データ ソースからデータの読み込みも行われます。 データがない場合は、ウィザードが停止し、エラーが返されます。
手順 2 - [データのインポート] ウィザードを開始する
お客様がプレビューに関して承認された後、Azure Cognitive Search チームは、機能フラグを使用する Azure portal リンクをお客様に提供します。これにより、Power Query コネクタにアクセスできます。 このページを開き、Azure Cognitive Search サービス ページのコマンド バーから [データのインポート] を選択して、ウィザードを開始します。
手順 3 – データ ソースを選択する
このプレビューを使用してデータをプルできるデータ ソースがいくつかあります。 Power Query を使用するすべてのデータ ソースには、そのタイルに "Powered By Power Query" と記載されています。 データ ソースを選択します。
![[データ ソースの選択] ページのスクリーンショット。](media/search-power-query-connectors/power-query-import-data.png)
データ ソースを選択したら、[次へ: データの構成] を選択して、次のセクションに移動します。
手順 4 – データを構成する
この手順では、接続を構成します。 各データ ソースには、異なる情報が必要です。 いくつかのデータ ソースについては、Power Query ドキュメントに、データに接続する方法に関する追加の詳細が記載されています。
接続の資格情報を指定したら、[次へ] を選択します。
手順 5 – データを選択する
インポート ウィザードでは、データ ソースで使用できるさまざまなテーブルがプレビューされます。 この手順では、インデックスにインポートするデータを含む 1 つのテーブルを確認します。
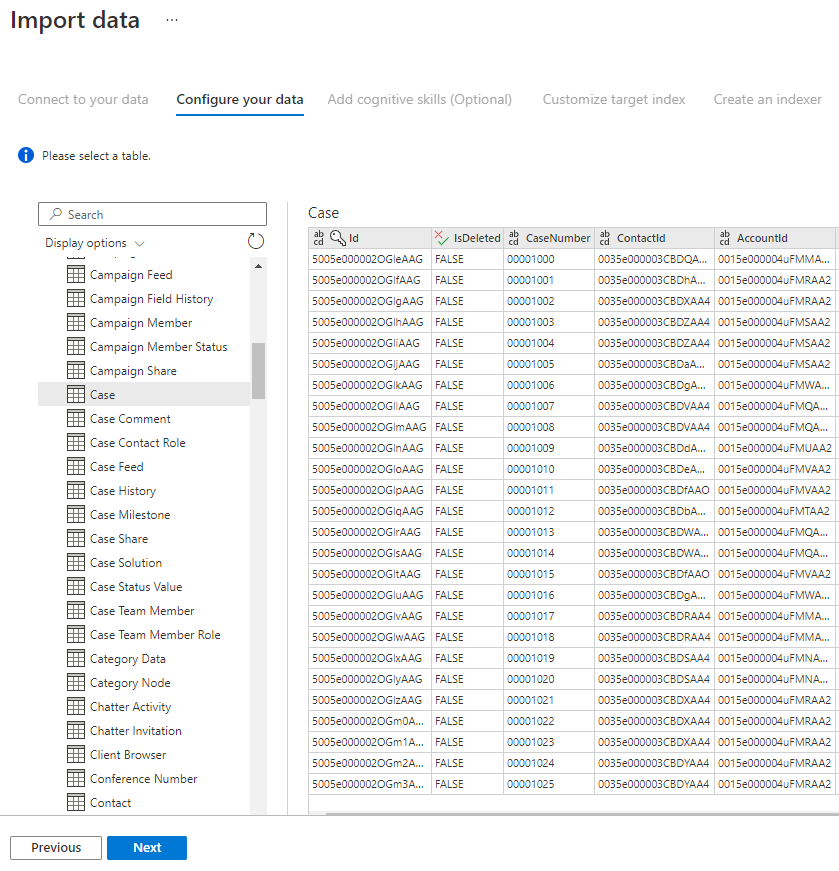
テーブルを選択したら、 [次へ] を選択します。
手順 6 – データを変換する (省略可能)
Power Query コネクタには、データを操作できる充実した UI エクスペリエンスが用意されているため、インデックスに適切なデータを送信できます。 列の削除や、行のフィルター処理などを実行できます。
データを Azure Cognitive Search にインポートする前に変換する必要はありません。
![[データの変換] ページのスクリーンショット。](media/search-power-query-connectors/power-query-transform-your-data.png)
Power Query を使用したデータ変換の詳細については、Power BI Desktop での Power Query の使用に関するページを参照してください。
データが変換されたら、[次へ] を選択します。
手順 7 – Azure Blob Storage を追加する
Power Query コネクタ プレビューでは現在、BLOB ストレージ アカウントを指定する必要があります。 この手順は、初期の限定的なプレビューにのみ存在します。 この BLOB ストレージ アカウントは、データ ソースから Azure Cognitive Search インデックスに移動するデータの一時ストレージとして機能します。
フル アクセス ストレージ アカウントの接続文字列を指定することをお勧めします。
{ "connectionString" : "DefaultEndpointsProtocol=https;AccountName=<your storage account>;AccountKey=<your account key>;" }
Azure portal でこの接続文字列を取得するには、ストレージ アカウント ブレードに移動し > [設定] > [キー] を選ぶ (クラシック ストレージ アカウントの場合) か、[設定] > [アクセス キー] を選びます (Azure Resource Manager ストレージ アカウントの場合)。
データ ソース名と接続文字列を指定した後、[Next: Add cognitive skills (Optional)](次へ: コグニティブ スキルの追加 (省略可能)) を選択します。
手順 8 – コグニティブ スキルを追加する (省略可能)
AI エンリッチメントはインデクサーの拡張機能であり、コンテンツをより検索しやすくするために使用できます。
シナリオに利点を追加するエンリッチメントを追加できます。 完了したら、 [Next: Customize target index](次へ: ターゲット インデックスのカスタマイズ) を選択します。
手順 9 – ターゲット インデックスをカスタマイズする
インデックス ページには、フィールドが、データ型とインデックスの属性を設定するための一連のチェック ボックスと共に一覧表示されます。 このウィザードで、メタデータに基づいてソース データをサンプリングすることで、フィールドの一覧を生成できます。
属性列の上部にあるチェック ボックスを選択することで、属性を一括選択できます。 クライアント アプリに返してフル検索処理の対象にする必要があるすべてのフィールドで、 [取得可能] と [検索可能] を選択します。 整数はフルテキスト検索もあいまい検索もできないことに注意してください (数値は逐語的に評価され、多くの場合フィルターで役立ちます)。
詳細については、インデックス属性と言語アナライザーの説明を参照してください。
時間をかけて選択内容を確認します。 ウィザードを実行すると、物理データ構造が作成されるため、すべてのオブジェクトを削除して再作成しない限り、これらのフィールドのほとんどのプロパティは編集できなくなります。
![[インデックスの作成] ページのスクリーンショット。](media/search-power-query-connectors/power-query-index.png)
完了したら、 [Next: Create an Indexer](次へ: インデクサーの作成) を選択します。
手順 10 - インデクサーを作成する
最後の手順では、インデクサーを作成します。 インデクサーに名前を付けると、インデクサーはスタンドアロン リソースとして存在することができ、同じウィザードのシーケンスで作成されるインデックス オブジェクトやデータ ソース オブジェクトとは独立して、スケジュールを設定したり管理したりできます。
[データのインポート] ウィザードで出力されるインデクサーにより、データ ソースがクロールされ、選択したデータが Azure Cognitive Search のインデックスにインポートされます。
インデクサーを作成するときに、必要に応じて、スケジュールに基づいたインデクサーの実行と、変更検出の追加を選択することができます。 変更検出を追加するには、'高基準値' 列を指定します。
![[インデクサーの作成] ページのスクリーンショット。](media/search-power-query-connectors/power-query-indexer-configuration.png)
このページの入力が完了したら、[送信] を選択します。
高基準値変更検出ポリシー
この変更検出ポリシーは、行が最後に更新されたときのバージョンまたは時刻を取得する "高基準" 列に依存します。
必要条件
- すべての挿入は列の値を指定します。
- 項目を更新すると、列の値も変更されます。
- この列の値は挿入または更新のたびに増加します。
サポートされていない列名
Azure Cognitive Search インデックス内のフィールド名は、特定の要件を満たす必要があります。 これらの要件の 1 つは、"/" などの一部の文字が使用できないということです。 データベース内の列名がこれらの要件を満たしていない場合、インデックス スキーマ検出で列が有効なフィールド名として認識されず、その列がインデックス用に提案されるフィールドとして一覧表示されません。 通常、フィールド マッピングを使用すると、この問題が解決しますが、フィールド マッピングはポータルでサポートされていません。
サポートされていないフィールド名を持つテーブル内の列からのコンテンツにインデックスを付けるには、データのインポート プロセスの "データを変換する" フェーズ中に列の名前を変更します。 たとえば、"Billing code/Zip code" という列の名前を "zipcode" に変更できます。 列の名前を変更すると、インデックス スキーマ検出によってそれが有効なフィールド名として認識され、インデックス定義に提案として追加されます。
次のステップ
この記事では、Power Query コネクタを使用してデータをプルする方法について説明しました。 このプレビュー機能は廃止されているため、既存のソリューションを、サポートされているシナリオに移行する方法についても説明しています。
インデクサーの詳細については、「Azure Cognitive Search のインデクサー」を参照してください。