ヒープ (クラスター化インデックスなしのテーブル)
適用対象:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
ヒープとはクラスター化インデックスを使用しないテーブルのことです。 1 つまたは複数の非クラスター化インデックスを、ヒープとして格納されているテーブルに作成することができます。 ヒープには、順序を指定せずにデータが格納されます。 通常、最初にデータが格納される順序はテーブルに行が挿入された順序と同じですが、データベース エンジンでは行を効率的に格納できるようにヒープ内でデータが移動される場合があるため、データの順序は予測できません。 ヒープから返される行の順序を保証するには、ORDER BY 句を使用する必要があります。 行を格納するための永久的な論理的順序を指定するには、テーブルにクラスター化インデックスを作成し、テーブルがヒープにならないようにします。
注意
クラスター化インデックスを作成する代わりにテーブルをヒープのままにしておくとよい場合もありますが、ヒープを効果的に使用するには高度なスキルが必要です。 テーブルをヒープのままにしておく妥当な理由がない限り、ほとんどのテーブルには、慎重に選択されたクラスター化インデックスが必要です。
ヒープを使用する場合
テーブルをヒープとして格納する場合、個々の行は、ファイル番号、データ ページ番号、ページのスロット (FileID:PageID:SlotID) で構成される 8 バイトの行識別子 (RID) への参照で識別されます。 行 ID は、小さい効率的な構造です。
ヒープは、順序指定されていな大規模な挿入操作のステージング テーブルとして使用できます。 厳密な順序を適用せずにデータが挿入されるため、通常この挿入操作は、クラスター化インデックスへの同等の挿入より高速です。 ヒープのデータが読み取られて最終的な宛先へ処理される場合は、読み取りクエリで使用される検索述語を対象とする、狭い非クラスター化インデックスを作成すると便利な場合があります。
注意
データはデータページの順にヒープから取得されますが、必ずしもデータが挿入された順序ではありません。
データが常に非クラスター化インデックスを介してアクセスされ、RID がクラスター化インデックス キーより小さい場合も、データ担当者はヒープを使用することがあります。
テーブルがヒープで、非クラスター化インデックスがない場合、行を検索するには、テーブル全体を読み取る (テーブル スキャンする) 必要があります。 SQL Server は、ヒープで直接 RID をシークできません。 テーブルが小さい場合は、この方法で対応できます。
ヒープを使用しない場合
データが、並べ替えた順序で頻繁に取得される場合は、ヒープを使用しないでください。 並べ替え用の列にクラスター化インデックスが存在すると、並べ替え操作が実行されない場合があります。
データが頻繁にグループ化される場合は、ヒープを使用しないでください。 データの並べ替えはグループ化よりも前に行う必要がありますが、並べ替え用の列にクラスター化インデックスが存在すると、並べ替え操作が実行されない場合があります。
広範囲のデータがテーブルから頻繁に照会される場合は、ヒープを使用しないでください。 範囲列にクラスター化インデックスが存在すると、ヒープ全体の並べ替えが実行されなくなります。
指定した順序でテーブル全体のコンテンツを返す必要がない場合を除いて、非クラスター化インデックスがなく、テーブルが大きい場合はヒープを使用しないでください。 ヒープでは、特定の行を探すためにヒープのすべての行を読み取る必要があります。
データが頻繁に更新される場合は、ヒープを使用しないでください。 レコードを更新し、その更新によって、使用されるデータ ページ内の領域が現在よりも増える場合、十分な空き領域があるデータ ページにレコードを移動する必要があります。 これにより、データの新しい場所を指す転送レコードが作成され、以前にそのデータを保持していたページに、新しい物理的な場所を示す転送ポインターを書き込む必要があります。 これは、ヒープの断片化を招きます。 ヒープをスキャンするときは、これらのポインターをたどる必要があります。このため、先読みパフォーマンスが制限され、追加の I/O 発生して、スキャンのパフォーマンスが低下するおそれがあります。
ヒープの管理
ヒープを作成するには、クラスター化インデックスのないテーブルを作成します。 既にテーブルにクラスター化インデックスが含まれている場合は、クラスター化インデックスを削除して、テーブルをヒープに戻します。
ヒープを削除するには、ヒープにクラスター化インデックスを作成します。
ヒープを再構築して無駄な領域を解放するには、次の操作を行います。
- ヒープにクラスター化インデックスを作成し、そのクラスター化インデックスを削除します。
ALTER TABLE ... REBUILDコマンドを使用して、ヒープを再構築します。
警告
クラスター化インデックスを作成または削除するには、テーブル全体を再作成する必要があります。 テーブルに非クラスター化インデックスがある場合は、クラスター化インデックスが変更されるたびに、すべての非クラスター化インデックスを再作成する必要があります。 このため、ヒープからクラスター化インデックス構造への変更、またはその逆の変更には時間がかかり、tempdb でデータの順序を並べ替えるためのディスク領域が必要になります。
ヒープ構造
ヒープとはクラスター化インデックスを使用しないテーブルのことです。 ヒープは、 sys.partitionsに 1 行を持っており、ヒープに使われる各パーティションは index_id = 0 になります。 既定では、ヒープのパーティションは 1 つです。 ヒープにパーティションが複数ある場合、各パーティションは、そのパーティションのデータを保持するヒープ構造になります。 たとえば、ヒープに 4 つのパーティションがある場合、4 つのヒープを持つ構造になります。この場合、パーティションごとに 1 つのヒープがあります。
ヒープ内のデータ型によっては、各ヒープ構造に 1 つ以上のアロケーション ユニットが含まれ、そこに特定のパーティションのデータが格納され、管理されます。 各ヒープには、パーティションごとに、少なくとも 1 つの IN_ROW_DATA アロケーション ユニットがあります。 また、ヒープにラージ オブジェクト (LOB) 列が含まれている場合は、パーティションごとに 1 つの LOB_DATA アロケーション ユニットもあります。 さらに、行サイズの上限である 8,060 バイトを超える可変長列が含まれている場合は、パーティションごとに 1 つの ROW_OVERFLOW_DATA アロケーション ユニットがあります。
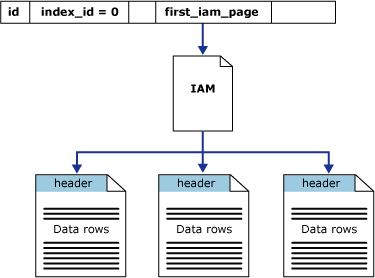
first_iam_page システム ビュー内の列 sys.system_internals_allocation_units は、特定のパーティション内のヒープに割り当てられた領域を管理する IAM ページのチェーン内の最初の IAM ページをポイントします。 SQL Server は、IAM ページを使用してヒープ内を移動します。 データ ページとその中にある行は特定の順序になっておらず、リンクもされていません。 データ ページ間の論理接続は、IAM ページ内に記録されている情報だけです。
重要
sys.system_internals_allocation_units システム ビューは SQL Server の内部使用専用に予約されています。 将来の互換性は保証されません。
IAM をスキャンしてヒープのページを保持しているエクステントを見つけることによって、ヒープのテーブル スキャンまたはシリアル読み取りが行われます。 IAM ではエクステントがデータ ファイルに入っている順序で表されています。したがって、シリアル ヒープ スキャンでは各ファイルが順に読み取られて進行します。 スキャン シーケンスの設定に IAM ページを使用すると、ヒープの行が挿入順どおりに戻されるとは限らないことになります。
次の図に、IAM ページを使用して単一パーティションのヒープ内のデータ行が SQL Server データベース エンジンで取得されるしくみを示します。
関連コンテンツ
CREATE INDEX (Transact-SQL)
DROP INDEX (Transact-SQL)
クラスター化インデックスと非クラスター化インデックスの概念
フィードバック
近日公開予定: 2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub イシューを段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、以下を参照してください: https://aka.ms/ContentUserFeedback。
フィードバックの送信と表示