Service Manager では、データ ウェアハウスに存在するデータをさまざまなソースから統合できます。 これは、定義済みのカスタマイズされた Microsoft Online Analytical Processing (OLAP) データ キューブを使用して、Service Manager を通じて提示されます。 つまり、Service Manager の高度な分析は、キューブ データの発行、表示、操作で構成されます。通常は、Microsoft Excel または Microsoft SharePoint です。 Excel は、主にそれ自体を使用して、データを表示および操作します。 SharePoint は、主にキューブ データを公開および共有する手段として使用されます。
Service Manager には、System Center 全体のデータ ウェアハウスが含まれています。 そのため、Operations Manager、Configuration Manager、および Service Manager のデータをデータ ウェアハウスに統合できます。複数のデータ ビューを簡単に使用して、必要な情報を取得できます。 これは、SAP アプリケーションやサードパーティの人事アプリケーションなど、独自のカスタム ソースから同じデータ ウェアハウスにデータをまとめることができるインターフェイスでもあるのです。 この統合によって、共通のデータ モデルが作成され、強化された分析が可能になります。これは、すべてのビジネス インテリジェンスとレポートのニーズに応じられる、情報技術 (IT) 組織全体でのデータ ウェアハウスの構築に役立ちます。
データ が共通モデルであれば、情報を操作して、企業全体に共通する定義と分類法を持つことができます。 これは、OLAP データ キューブを展開し、Excel や SharePoint などの標準ツールを使用してキューブの情報にアクセスすることによって可能です。 これにより、ユーザーが既に知っているスキルを採用することも可能になります。 ビジネス ロジックの定義は、一元的な方法で管理します。 たとえば、インシデントの解決時間のしきい値とその評価 (緑、黄、赤) などの、主要業績評価指標を定義できます。 これらの選択を一元的な方法で管理し、ユーザーがデータを簡単に使用できるようにしながら、共通の定義が Excel レポートや SharePoint ダッシュボードに表示されるようにできます。
Service Manager OLAP キューブについて
オンライン分析処理 (OLAP) キューブは、既存のデータ ウェアハウス インフラストラクチャを使用してエンド ユーザーにセルフサービス ビジネス インテリジェンス機能を提供する Service Manager の機能です。
OLAP キューブは、高速なデータ分析を提供することで、リレーショナル データベースの制限を克服するデータ構造です。 キューブは、大量のデータの表示と集計を行う一方で、あらゆるデータ ポイントへの検索可能なアクセスをユーザーに提供します。 これにより、必要に応じてデータをロールアップ、スライス、およびダイシングして、ユーザーの関心領域に関連するさまざまな質問を処理できます。
OLAP キューブに関する実用的な知識を持つソフトウェア ベンダーまたは情報テクノロジ (IT) 開発者は、管理パックを作成して、データ ウェアハウス インフラストラクチャ上に構築された独自の拡張可能でカスタマイズ可能な OLAP キューブを定義できます。 これらのキューブは、SQL Server Analysis Services (SSAS) に保管されます。 Excel または SQL Server Reporting Services (SSRS) などのセルフサービス ビジネス インテリジェンス ツールは、SSAS 内のこれらのキューブをターゲットにすることが可能なため、キューブを使用して、複数のパースペクティブからデータを分析できます。
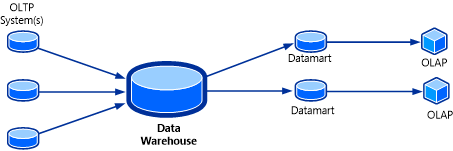
すべてのトランザクションとレコードの格納に企業が使用しているデータベースは、オンライン トランザクション処理 (OLTP) データベースと呼ばれます。 通常、これらのデータベースには、一度に 1 つずつ入力されたレコードが蓄積され、十分な情報に基づいて業務上の意思決定を下すための戦略に使用できる豊富な情報が保管されています。 ただし、データの格納に使用されるデータベースは、分析用に設計されていませんでした。 そのため、これらのデータベースから目的の情報を取得するには、時間と労力において高い負荷がかかります。 OLAP データベースは、データからビジネス インテリジェンス情報を抽出するために設計された、特殊化されたデータベースです。
OLAP キューブは、これまでのデータ ウェアハウス ソリューションに欠けていた機能であると言えます。 OLAP キューブは、多次元キューブ、ハイパーキューブなどとも呼ばれる SQL Server Analysis Services (SSAS) におけるデータ構造であり、ほぼ瞬時のデータ分析を可能にするために、OLAP データベースを使用して構築されます。 このシステムのトポロジーは、次の図に示してあります。
OLAP キューブの便利な機能の 1 つは、キューブ内のデータを集計済み形式で格納できる点です。 キューブでは、各種の値が事前計算済みであるため、ユーザーには、答えが事前に用意されているかのように見えます。 ソース OLAP データベースにクエリを実行する必要がないため、キューブは広範な質問に対する答えをほぼ瞬時に返すことができます。
Service Manager OLAP キューブの主な目的は、ソフトウェア ベンダーまたは情報テクノロジ (IT) 開発者が、履歴分析とトレンド分析の両方の目的でデータをほぼ瞬時に分析できることです。 サービス マネージャーは、次の方法でこれを行います。
- 管理パックの展開時に SSAS で自動的に作成される OLAP キューブを管理パックで定義することができます。
- 処理、パーティション分割、翻訳とローカライズ、スキーマ変更などのタスクを実行することで、ユーザーの介入なしにキューブを自動的に管理します。
- ユーザーは、Excel などのセルフサービス ビジネス インテリジェンス ツールを使用して、複数のパースペクティブからデータを分析できます。
- 生成された Excel レポートを保存し、将来参考として利用できます。
Service Manager コンソールでデータ ウェアハウス キューブがどのように表されるかを確認するには、 Data Warehouse ワークスペースに移動し、 Cubes を選択します。
サービス マネージャー OLAP キューブ
次の図は、オンライン分析処理 (OLAP) キューブに必要な主要部分を表す SQL Server Business Intelligence Development Studio (BIDS) からのイメージです。 これらの部分には、データ ソース、データ ソース ビュー、キューブとディメンションがあります。 次のセクションでは、OLAP キューブ部分と、ユーザーがキューブを使って実行することができるアクションについて説明します。
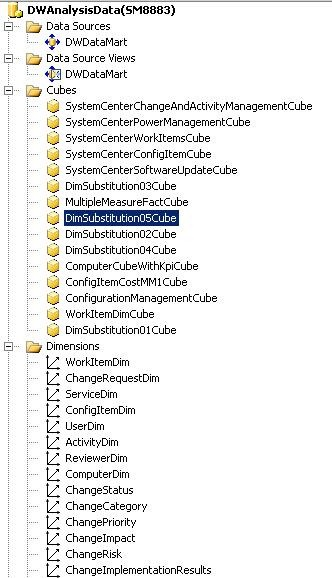
データ ソース
データ ソースは、OLAP キューブ内に含まれるすべてのデータの源泉です。 OLAP キューブがデータ ソースに接続して、生データの読み込みと処理を行い、関連付けられたメジャーに関する集計と計算を実行します。 すべての Service Manager OLAP キューブのデータ ソースは、Operations Manager と Configuration Manager の両方のデータ マートを含むデータ マートです。 正しいレベルのアクセス許可を確立するためには、データ ソースについての認証情報が SQL Server Analysis Services (SSAS) に保存されている必要があります。
データ ソース ビュー
データ ソース ビュー (DSV) は、Service Manager データ マートなどのデータ ソースのディメンション、ファクト、アウトリガー テーブルを表すビューのコレクションです。 DSV には、プライマリ キーや外部キーなど、テーブル間のすべてのリレーションシップが含まれます。 言い換えると、DSV は SSAS データベースがリレーショナル スキーマをどのようにマップするか指定し、リレーショナル データベースの上に抽象レイヤーを提供します。 この抽象レイヤーを使用すると、ソース リレーショナル データベース内にリレーションシップが存在しなくても、ファクト テーブルとディメンション テーブルの間にリレーションシップを定義できます。 データ ウェアハウス ディメンション スキーマにはもともと存在しない名前付き計算、カスタム メジャー、新しい属性も、DSV で定義できます。 たとえば、 Incidents Resolved のブール値を定義する名前付き計算では インシデントの状態が解決または閉じられた場合に true として値が計算されます。 名前付き計算を使用して、Service Manager は、解決されたインシデントの割合、解決されたインシデントの合計数、解決されていないインシデントの合計数などの有用な情報を表示するメジャーを定義できます。
名前付き計算のもう 1 つのわかりやすい例は、 ReleasesImplementedOnScheduleです。 この名前付き計算は、実績終了日が予定終了日と同じか、それよりも前のリリース レコードの数を確認する、すばやいヘルス状態チェックを提供します。
「OLAP Cubes
OLAP キューブは、迅速にデータを分析することで、リレーショナル データベースの限界を克服するデータ構造です。 OLAP キューブでは、大量のデータを表示および合計できるだけでなく、任意のデータ ポイントへの検索可能なアクセスをユーザーに提供できるため、必要に応じてデータをロールアップ、スライス、およびダイシングして、ユーザーの関心領域に関連するさまざまな質問を処理できます。
次元
SSAS のディメンションは、Service Manager データ ウェアハウスのディメンションを参照します。 Service Manager では、ディメンションは管理パック クラスとほぼ同じです。 各管理パックのクラスにはプロパティの一覧があり、各ディメンションには属性の一覧があります。各属性は、クラスの 1 つのプロパティにマップされます。 ディメンションにより、データのフィルター処理、グループ化、ラベル作成が可能です。 たとえば、コンピューターをインストールされているオペレーティング システムでフィルター処理したり、人々を性別や年齢の分類でグループ分けできます。 その後、データをこれらの階層とカテゴリに自然に分類して、より詳細な分析を可能にする形式でデータを表示できます。 ディメンションには、ユーザーがより詳細なレベルに "ドリルダウン" できるように、自然階層が含まれる場合もあります。 たとえば、日付ディメンションは、年、四半期、月、週、そして日にドリル ダウンできる階層を持ちます。
次の図は、日付、地域、製品のディメンションを含む OLAP キューブを示したものです。
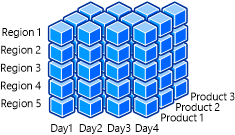
たとえば、Microsoft チーム メンバーは、該当するバージョンの Xbox One ゲーム コンソールの売上の概要をすばやく簡単に確認できます。 掘り下げていくと、より特定の期間に絞った売上数値を得ることができます。 ビジネス アナリストは、新しい本体設計の立ち上げと Xbox One 用 Kinect によって Xbox One 本体の販売がどのように影響を受けたかを調べたい場合があります。 これは、売上の傾向がどうであるか、どのようなビジネス戦略の見直しが必要かを判断するのに役立ちます。 日付ディメンションをフィルター処理すると、この情報を迅速に配布して、使用できます。 このようにデータのスライス アンド ダイスが可能なのは、ユーザーが簡単にフィルター処理やグループ化できる属性とデータでディメンションが設計されているためです。
Service Manager では、すべての OLAP キューブが共通のディメンション セットを共有します。 データ マートが複数あるシナリオでも、すべてのディメンションがプライマリ データ ウェアハウスをデータ ソースとして使用します。 データ マートが複数あるシナリオでは、このために、キューブの処理中にディメンション キー エラーが発生する可能性があります。
[メジャー グループ]
メジャー グループは、データ ウェアハウスの用語のファクトと同じ概念です。 データ ウェアハウスでファクトに数値による評価が含まれるのと同じように、メジャー グーループには OLAP キューブに関するメジャーが含まれます。 データ ソース ビューの単一ファクト テーブルから派生する OLAP キューブのすべてのメジャーもまた、メジャー グループであると見なすことができます。 ただし、OLAP キューブのメジャーが複数のファクト テーブルから派生するインスタンスもあります。 同じ詳細レベルのメジャーは、1 つのメジャー グループにまとめられます。 メジャー グループでは、システムに読み込まれるデータ、データの読み込み方法、およびデータの多次元キューブへのバインド方法が定義されます。
各メジャー グループには、実際のデータを重複しない別々のセクションに保持するパーティションの一覧も含まれます。 メジャー グループには、ユーザーのパフォーマンスを向上するために、各メジャー グループごとに計算し、事前に集計するデータ セットを定義する集計デザインも含まれます。
対策
メジャーとは、ユーザーがスライス、ダイス、集計および分析する数値のことです。メジャーは、データ ウェアハウスのインフラストラクチャを使用して OLAP キューブを構築する基本的な利点の 1 つです。 SSAS を使用して、ビジネス ルールと計算を適用する OLAP キューブをビルドして、カスタマイズ可能な形式でメジャーの書式設定と表示を行うことができます。 OLAP キューブの開発時間の多くは、表示するメジャーとその計算方法の決定と定義に費やされます。
メジャーは、通常、データ ウェアハウスのファクト テーブルの数値列にマップする値ですが、ディメンションの属性と逆ディメンションの属性に作成されることもあります。 これらのメジャーは、OLAP キューブで分析される最も重要な値であり、OLAP キューブを参照するエンド ユーザーが一番関心を持つものです。 データウェアハウスにある測定値の一例に、ActivityTotalTimeMeasure があります。 ActivityTotalTimeMeasure は、ActivityStatusDurationFact 内のメジャーであり、各活動が特定の状態にある時間を表します。 メジャーの詳細レベルは、参照されるすべてのディメンションで構成されます。 たとえば、 ComputerHostsOperatingSystem リレーションシップ ファクトの詳細レベルは、Computer ディメンションと Operating System ディメンションで構成されます。
集計関数は測定値に対して計算され、さらなるデータ分析を可能にします。 最も一般的な集計関数は Sum です。 たとえば、一般的な OLAP キューブ クエリに In Progressであるすべての活動の合計時間を計算があります。 その他の一般的な集計関数には、Min、Max、Count が含まれます。
OLAP キューブで生データが処理されると、独自のメジャー式や計算されるメンバーを定義する多次元式 (MDX) を使用して、ユーザーはより複雑な計算とクエリを実行できます。 MDX は OLAP システムに保存されているデータに照会とアクセスをするための業界標準です。 SQL Server は、多次元データベースがサポートするデータ モデルを操作するようには設計されていませんでした。
ドリルダウン
ユーザーが OLAP キューブのデータをドリルダウンすると、データがさまざまな概要レベルで分析されます。 データの詳細レベルは、ユーザーが、データを階層のさまざまなレベルで調べながらドリルダウンするにつれて変わります。 ユーザーがドリルダウンすると、概要情報からデータに移動し、フォーカスが狭くなります。 次に挙げるのは、ドリルダウンの例です。
- 米国の人口統計情報を見て、ワシントン州、シアトル都市圏、レッドモンド市の順番にデータをドリルダウンし、最後にはマイクロソフトの従業員数にまで絞り込みます。
- 2015 暦年、その年の第 4 四半期、12 月、クリスマスの前の週、最後にクリスマス イブの Xbox One 本体の売上数値をドリルダウンします。
ドリルスルー
ユーザーがデータ ドリルスルー すると、OLAP キューブの集計データに貢献したすべての個々のトランザクションが表示されます。 言い換えると、ユーザーは特定のメジャー値に関する最も詳細なレベルのデータを取得できます。 たとえば、特定の月と製品カテゴリの売上データが与えられた場合、そのデータをドリルスルーして、そのデータのセルに含まれる各テーブル行の一覧を表示できます。
「ドリルダウン」と「ドリルスルー」という用語を混同することは一般的です。 これらの主な違いは、ドリルダウンは、たとえば、米国、ワシントン、OLAP キューブ内のシアトルなど、定義済みのデータ階層で動作することです。 ドリルスルーは、データの最も詳細なレベルに直接アクセスし、単一のセルに集計されているデータ ソースから行のセットを抽出します。
主要業績評価指標
組織は、主要業績評価指標 (KPI) を使用して目標を目指す進捗状況を測定することにより、企業のヘルスとパフォーマンスを評価できます。 KPI は、事前に定義された特定の目的と目標に向けての進捗状況を監視するために定義されるビジネス メトリックです。 KPI には目標値と実際の値があり、これは組織の成功に不可欠な定量的な目標を表します。 KPI はスコアカードのグループに表示され、ビジネスの全体的な正常性が 1 つのクイック スナップショットに表示されます。
KPI の一例を挙げると、すべての変更要求を 48 時間以内に完了することなどです。 KPI は、タイム フレーム内の変更要求の解決率の測定に使用できます。 KPI をグラフィックで表示するダッシュボードを作成できます。 たとえば、すべての変更要求を 48 時間に完了するという KPI の目標値を 75 パーセントに定義することができます。
メジャー グループ
パーティションは、メジャー グループにあるデータの一部あるいはすべてを保持するデータ構造です。 すべてのメジャー グループはパーティションに分かれます。 パーティションは、ファクト データの中からメジャー グループに読み込まれるデータのサブセットを定義します。 SSAS Standard Edition では 1 つのメジャー グループに 1 つのパーティションしか許可されませんが、SSAS Enterprise Edition では 1 つのメジャー グループに複数のパーティションを含むことができます。 パーティションはエンドユーザーにとって透過的な機能ですが、OLAP キューブのパフォーマンスとスケーラビリティの両方に大きな影響を与えます。 メジャー グループのすべてのパーティションは、同じ物理データベースに存在します。
パーティションを使用すると、管理者は OLAP キューブをより適切に管理し、OLAP キューブのパフォーマンスを向上させることができます。 たとえば、メジャー グループ全体に影響を与えることなく、その 1 つのパーティション内のデータを削除または再処理することができます。 ファクト テーブルに新しいデータを読み込むとき、新しいデータの保管場所となるパーティションだけが影響を受けます。
パーティション分割は、OLAP キューブの処理とクエリのパフォーマンスの向上ももたらします。 SSAS では、複数のパーティションを並行して処理することが可能なため、サーバー上の CPU とメモリ リソースの利用効率を大きく向上させることが可能です。 クエリの実行中、SSAS は複数のパーティションからデータをフェッチ、処理、集計しますが、クエリに関連するデータを含むパーティションのみがスキャンされ、入力と出力の全体的な量が減少します。
パーティション分割の 1 例として、各月のファクト データを月別のパーティションに配置することができます。 月末になると、すべての新規データは新しいパーティションに保管されるため、値が重複することなく自然にデータが分散されます。
集計
OLAP キューブでは、集計は事前に集計されたデータセットです。 これは、GROUP BY 句を含む SQL SELECT ステートメントに似ています。 SSAS は、クエリに応答するときにこれらの集合体を使用して、必要な計算量を減らし、ユーザーに迅速に答えを返すことができます。 OLAP キューブに組み込まれた集計機能により、SSAS でクエリを行うときに実行しなければならない集計量が削減されます。 集計を正しく構築することで、クエリのパフォーマンスを劇的に向上させることが可能です。 多くの場合、このプロセスはクエリと使用量の変動に応じて、OLAP キューブのライフタイムを通して継続的に進化します。
集計の基本セットが通常作成され、OLAP キューブに対するほとんどのクエリでこのセットを使用できます。 集計は、メジャー グループ内の OLAP キューブのパーティションごとに構築されます。 集計の構築時に、ディメンションの特定の属性が事前集計済みのデータ セットに組み込まれます。 ユーザーが OLAP キューブを参照するとき、これらの集計に基づいてすばやくデータをクエリすることができます。 構築可能な集計の数は夥しいため、すべてを構築するには膨大な時間と記憶域スペースを必要とするため、集計は慎重に設計しなければなりません。
Service Manager は、Service Manager OLAP キューブで集計を構築および設計するときに、次の 2 つのオプションを使用します。
- パフォーマンスの到達率
- 使用法に基づく最適化
"パフォーマンスの到達率" オプションでは、集計を構築するパーセンテージを定義します。 たとえば、このオプションを既定の推奨値 30% に設定する場合は、OLAP キューブのパフォーマンスの予測到達率が 30% になるように集計が構築されます。 ただし、これは、考えられる集計の 30% が構築されることを意味するわけではありません。
"使用法に基づく最適化" を利用すると、クエリの実行時に情報が集計設計プロセスにフィードされるように、SSAS でデータの要求がログに記録されるようになります。 その後、SSAS がデータをレビューして、最高のパフォーマンス予測到達率を実現するのに適した集計を提案します。
Service Manager キューブのパーティション分割
キューブ内の各メジャーグループはパーティションに分けられ、パーティションはメジャーグループに読み込まれるファクトデータの一部を定義します。 SQL Server Standard Edition の SQL Server Analysis Services (SSAS) では、メジャー グループごとに 1 つのパーティションのみが許可されますが、Enterprise Edition では複数のパーティションが許可されます。 パーティションは、エンド ユーザーがまったくその存在を意識しないものですが、パフォーマンスとスケーラビリティに重要な影響を与えます。 たとえば、パーティションは、独立して並列に処理できます。 異なる集計デザインを持つことができます。 メジャー グループ内の他のすべてのパーティションに影響を与えずに、パーティションを再処理できます。 また、SSAS は、クエリに必要なデータを含むパーティションのみを自動的にスキャンするため、クエリのパフォーマンスを大きく改善することが可能です。
キューブのパーティションは、データ ウェアハウスのメンテナンス ジョブが実行されるたびに分割されますが、そのタイミングは、既定では 1 時間ごとです。 実行する実際のプロセス モジュールの名前は、ManageCubePartitions です。 これは、常に CreateMartPartitions 手順の後に実行されます。 この依存データは、infra.moduletriggercondition テーブルに保存されます。
パーティション分割を処理する主なダイナミック リンク ライブラリ (DLL) は、PartitionUtil クラスのウェアハウス ユーティリティ DLL (Microsoft.EnterpriseManagement.Warehouse.Utility) です。 具体的には、すべてのパーティションメンテナンスを処理する ManagePartitions() メソッドがクラス内にあります。 データ ウェアハウス メンテナンス DLL (Microsoft.EnterpriseManagement.Warehouse.Maintenance) とデータ ウェアハウス オンライン処理 (OLAP) DLL (Microsoft.EnterpriseManagement.Warehouse.Olap) の両方が、メンテナンスとキューブの展開中にウェアハウス ユーティリティ DLL (Microsoft.EnterpriseManagement.Warehouse.Utility) を呼び出して、パーティションを処理します。 このため、共通のウェアハウス ユーティリティ DLL に実際のパーティション処理が含まれ、ロジックまたはコードの重複が回避されます。
キューブ パーティション分割メンテナンスは、次のタスクを実行します。
- パーティションの作成
- パーティションの削除
- パーティション境界の更新
これを行うには、構造化照会言語 (SQL) テーブルである etl.TablePartition を読み込んで、メジャー グループに作成されたすべてのファクト パーティションを特定します。 次のアクションが発生します。
- キューブ内の各メジャー グループごとにキューブ処理を開始する
- メジャー グループに関するすべてのパーティションを etl.TablePartition テーブルから取得する
- etl.TablePartition テーブルに存在しないメジャー グループのパーティションをすべて削除する
- 新規に作成されていて、etl.TablePartition テーブルのみに存在するパーティションを追加する
- etl.TablePartition テーブルの RangeStartDate と RangeEndDate を照会し、変更された可能性があるすべてのパーティションを更新する
キューブ処理について、次の点に注意してください。
- SQL Server Standard Edition では、ファクトを対象としたメジャー グループだけが、複数のパーティションを含むことができます。 既定では、すべてのメジャー グループとディメンションには、1 つのパーティションしか含まれません。 そのため、パーティションには境界条件はありません。
- パーティション境界は、etl.TablePartition テーブルの対応ファクト パーティションの日付キーに合致するデータキーを基準にしたクエリ バインドによって定義されます。
Service Manager OLAP キューブの展開
オンライン分析処理 (OLAP) キューブ展開では、Service Manager 展開インフラストラクチャを使用して、SQL Server Analysis Services (SSAS) データベースに OLAP キューブを作成します。
要約すると、展開可能な要素は、シリアル化された、SSAS データベースでの OLAP キューブの作成に使用されるリソースのコレクションと共に、展開プログラムを返します。 OLAP キューブについて展開可能なオブジェクトの名前は、SystemCenterCube 要素では CubeDeployable、CubeExtension 要素では CubeExtensionDeployable です。 両要素の展開プログラムは CubeDeployer です。
DWStagingAndConfig データベースの dbo.Selector テーブルには、SystemCenterCube 管理パック要素と CubeExtension 管理パック要素の両方に関するエントリが含まれます。 展開エンジンは、MPSync ジョブを使用してデータ ウェアハウスに管理パックがインポートされる際に、追加展開処理が管理パック要素に必要であれば、このメタデータを使用します。
展開では、分析管理オブジェクト (AMO) アプリケーション プログラミング インターフェイス (API) を使用して、SSAS データベースのすべてのキューブ コンポーネントを作成および変更します。 具体的には、CubeDeployable 要素に SSAS データベースへの接続がないため、切断モードの AMO が使用されます。 非接続モードの AMO で作業することで、サーバーとの接続を確立せずに、AMO オブジェトのツリー全体を作成できます。 その後、Service Manager は、オブジェクトの階層をストリーム リソースとしてシリアル化し、展開インフラストラクチャに渡される配置者オブジェクトにアタッチします。 それから、展開プログラム オブジェクトのシリアル化が解除されて、SSAD データベースとの接続を確立し、サーバーに適切な要求を送信することによって、オブジェクトを作成します。
シリアル化できるのはメジャー オブジェクトだけです。 AMO では、主要なオブジェクトは、他のオブジェクトの一部ではなく完全なエンティティとして、完全なオブジェクトを表すクラスであると見なされます。 たとえば、メジャー オブジェクトには、サーバー、キューブ、およびディメンションが含まれます。これらはすべてスタンドアロン エンティティです。 ただし、DimensionAttribute は、Dimension の親メジャー オブジェクトの一部としてのみ作成できるため、メジャー オブジェクトではありません。 そのため DimensionAttribute はマイナー オブジェトです。 OLAP キューブ デザインは、キューブに必要なすべての主要なオブジェクトを、任意の依存マイナー オブジェクトと共に作成することに焦点を当てます。 これらのメジャー オブジェクトは、SSAS データベースにオブジェクトが作成される前にシリアル化され、最終的には逆シリアル化されるオブジェクトです。
主要なオブジェクトをラップするリソースは、展開を正常に完了し OLAP キューブ要素の依存要件を満たすために、特定の順序で作成される必要があります。 次の 2 つの一覧は、SystemCenterCube 要素と CubeExtension 要素の展開シーケンスをそれぞれ説明します。
- DataSourceView 要素
- ディメンション要素
- 日付ディメンション要素
- キューブ要素
- DataSourceView 要素
- キューブ要素
サービス マネージャー OLAP キューブ処理
オンライン分析処理 (OLAP) キューブがデプロイされ、そのすべてのパーティションが作成されると、表示できるように処理する準備が整います。 キューブの処理は、抽出、変換、読み込み (ETL) が実行された後の最後の手順です。 これらの手順は、次のように行われます。
- 抽出:ソース システムからデータを抽出します
- 変換:データに機能を適用して、標準ディメンション スキーマに適合させます
- 読み込み:データをデータ マートに読み込んで、使用できるようにします
- プロセス:データ マートから OLAP キューブにデータを読み込んで、参照できるようにします
OLAP キューブの処理は、キューブに関する集計がすべて計算され、それらの集計とデータがキューブに読み込まれる際に行われます。 ディメンション テーブルとファクト テーブルが読み込まれ、データが計算されて、キューブに読み込まれます。 OLAP キューブを設計する際には、処理について注意深く検討してください。なぜなら、何百万ものレコードが存在する運用環境では、処理に大きな影響が出る可能性があるからです。 このような環境内のすべてのパーティションの完全なプロセスには、数日から数週間かかる場合があります。これにより、Service Manager インフラストラクチャとキューブがエンド ユーザーに使用できなくなる可能性があります。 1 つの推奨事項は、システムのオーバーヘッドを減らすために使用されていないキューブの処理スケジュールを無効にすることです。
OLAP キューブ処理は、2 つの独立した作業から構成されます。
- ディメンションの処理
- パーティションの処理
各 OLAP キューブには、Service Manager コンソールに対応する処理ジョブがあり、ユーザーが構成可能なスケジュールで実行されます。 それぞれの種類の処理作業について、次のセクションで説明します。
ディメンションの処理
新しいディメンションが SQL Server Analysis Server (SSAS) データベースに追加されるたびに、そのディメンションに対してすべてのプロセスが実行され、完全に処理された状態にする必要があります。 ただし、ディメンションが処理された後、同じディメンションを対象とする別のキューブが処理されるときに、ディメンションが再び処理される保証はありません。 ディメンションを自動的に再処理しないことで、Service Manager がすべてのキューブのすべてのディメンションを再処理できなくなります。 これは、ディメンションが最近処理された場合に特に当てはまります。これは、まだ処理されていない新しいデータが存在する可能性は低いためです。 処理効率を最適化するために、Microsoft.SystemCenter.Datawarehouse.OLAP.Base 管理パックで定義されているシングルトン クラス (Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval という名前) があります。 このクラスの例を次に挙げます。
<!-- This singleton class defines the minimum interval of time in minutes that must elapse before a shared dimension is reprocessed. -->
<ClassType ID="Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval" Accessibility="Public" Abstract="false" Base="AdminItem!System.AdminItem" Singleton="true">
<Property ID="IntervalInMinutes" Type="int" Required="true" DefaultValue="60"/>
</ClassType>
このシングルトン クラスには、ディメンションを処理する頻度を記述する IntervalInMinutesプロパティがあります。 既定では、このプロパティは 60 分に設定されています。 たとえば、ディメンションが午後 3 時 5 分に処理され、同じディメンションをターゲットとする別のキューブが午後 3 時 45 分に処理された場合、ディメンションは再処理されません。 この方法の欠点は、ディメンション キー エラーが発生する可能性が高くなることです。 再試行メカニズムは、ディメンションを再処理してからキューブ パーティションを再処理することでディメンション キー エラーに対処します。 エラーの処理の詳細については、「デバッグとトラブルシューティングに関する一般的な問題」セクションを参照してください。
ディメンションが完全に処理された後は、 ProcessUpdate による増分処理が実行されます。 それ以外に ProcessFull が実行されるのは、ディメンション スキーマが変更されたときだけです。なぜなら、変更の結果、ディメンションが未処理状態に戻るからです。 ディメンションに対して ProcessFull が実行された場合、影響を受けるすべてのキューブとそのパーティションは未処理の状態になり、次回のスケジュールされた実行で完全に処理される必要があります。
パーティションの処理
大きなパーティションの再処理が遅く、SSAS をホストするサーバー上の多くの CPU リソースが消費されるため、パーティション処理は慎重に検討する必要があります。 パーティションの処理には、一般に、ディメンションの処理よりも長い時間がかかります。 ディメンションの処理とは異なり、パーティションの処理は、他のオブジェクトへの副作用はありません。 System Center - Service Manager OLAP キューブで実行される処理の種類は、ProcessFull と ProcessAdd の 2 種類のみです。
ディメンションと同様、OLAP キューブに新しいパーティションを作成するには、そのパーティションの ProcessFull タスクが、照会可能な状態であることが必要です。 ProcessFull タスクはコストがかかる操作なので、パーティションを作成する場合や行が更新された場合など、必要なときのみ実行してください。 行が追加され、行が更新されていないシナリオでは、Service Manager は ProcessAdd タスクを実行できます。 これを行うため、Service Manager は透かしや他のメタデータを使用します。 具体的には、実行する処理の種類を特定するために、etl.cubepartition テーブルと etl.tablepartition テーブルを照会します。
次の図は、Service Manager がウォーターマーク データに基づいて実行する処理の種類を決定する方法を示しています。
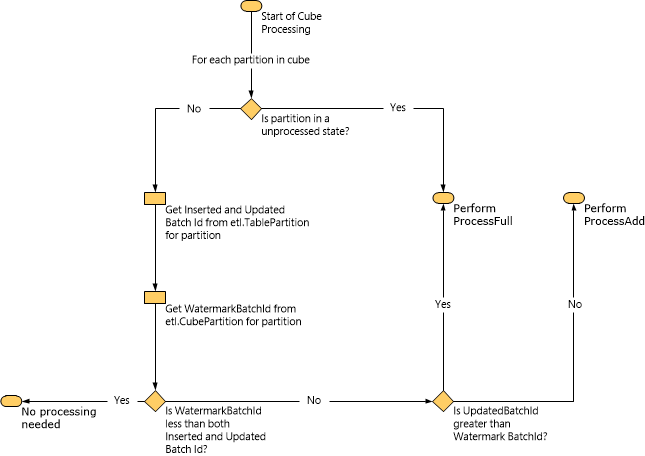
ProcessAdd タスクが実行されると、Service Manager は透かしを使用してクエリのスコープを制限します。 たとえば、InsertedBatchId の値が 100 で WatermarkBatchId の値が 50 である場合、そのクエリは、InsertedBatchId の値が 50 より大きく 100 未満のデータ マートからのみ、データを読み込みます。
最後に、Service Manager は、SSAS または Business Intelligence Development Studio を使用した OLAP キューブの手動処理をサポートしていない点に注意してください。 System Center - Service Manager で提供されているメソッドの外部でキューブを処理しても、Service Manager コンソールと Service Manager コマンドレットを含め、ウォーターマーク テーブルは更新されません。 そのため、データ整合性の問題が発生する可能性があります。 キューブを誤って手動で再処理した場合、考えられる回避策の 1 つは、OLAP キューブを同じ方法で手動で処理し直す方法です。 その後、次に Service Manager がキューブを処理すると、パーティションが未処理の状態になるため、ProcessFull タスクが自動的に実行されます。 これで、すべてのウオーターマークとメタデータが正常に更新され、発生した可能性があるデータ整合性の問題は解決されます。
Service Manager OLAP キューブの維持
ここでは、Online Analytical Processing (OLAP) キューブのメンテナンスのベスト プラクティスについて説明します。
Analysis Services ディメンションを定期的に再処理する
SQL Server Analysis Services (SSAS) のベスト プラクティスでは、SSAS ディメンションを完全に定期的に再処理することが推奨されています。 ディメンションを完全に再処理することで、インデックスの再構築と多次元データのデータ記憶域の最適化が行われるため、時間の経過とともに低下しがちなクエリおよびキューブのパフォーマンスを向上することができます。 これは、コンピューターのハードディスクを定期的にデフラグするのに似ています。
ただし、SSAS ディメンションの完全な再処理の欠点は、影響を受ける OLAP キューブがすべて未処理の状態になり、クエリ可能な状態に戻すためには、これらも完全に再処理する必要があることです。 Service Manager は、SSAS ディメンションで明示的に完全に処理しません。 そのため、このメンテナンス タスクをいつ実行するかを慎重に決定する必要があります。
メモリの考慮事項
データ ウェアハウスの抽出、変換、読み込み (ETL) 操作と OLAP キューブ機能をすべて 1 つのサーバー上で実行する場合は、同時に実行されるデータ集約型の操作すべてにサーバーが確実に対応できるように、オペレーティング システム、データ ウェアハウス、および SSAS のメモリ要件を慎重に考慮してください。 特に、OLAP キューブの処理には多くのメモリが使用されるため注意が必要です。