仮想マシン スケール セットを構成する
スケーリングするとき、仮想マシン スケール セットにインスタンスを追加します。 運送会社のシナリオで、スケーリングは、時間と共に変動する要求数の処理に適した方法です。 スケーリングでは、Web アプリケーションが実行される仮想マシン数が、ユーザー数の変化に合わせて調整されます。 この方法では、現在の負荷に関係なく、システムで一定の応答時間が保たれます。
このユニットでは、仮想マシン スケール セットをスケーリングする方法を学習します。 スケール セット内の仮想マシン インスタンスの数を明示的に設定して手動でスケーリングしたり、仮想マシンの割り当てと割り当て解除をトリガーするスケール ルールを定義して自動スケールを構成したりすることができます。 これらのスケール ルールでは、さまざまなパフォーマンス メトリックを監視することで、システムをスケーリングするタイミングが決定されます。
仮想マシン スケール セットを手動でスケーリングする
仮想マシン スケール セットを手動でスケーリングするには、インスタンス数を増減させます。 このタスクは、プログラムまたは Azure portal で行うことができます。
次のコードでは、Azure CLI を使用して、仮想マシン スケール セット内のインスタンスのを変更しています。
az vmss scale \
--name MyVMScaleSet \
--resource-group MyResourceGroup \
--new-capacity 6
仮想マシン スケール セットを自動スケーリングする
手動スケーリングは、状況によっては役に立ちます。 しかし、多くの場合は、自動スケーリングの方が適しています。 これにより、スケール セット内のインスタンスの数をシステムで制御できるようになります。
以下を基にして自動スケーリングを行うことができます。
- スケジュール: 特定の日付/時刻の期間にワークロードが増加することがわかっている場合は、この方法を使用します。
- メトリック: スケール セットに関連付けられているパフォーマンス メトリックを監視することによって、スケーリングを調整します。 これらのメトリックが指定したしきい値を超えたら、スケール セットで新しい仮想マシン インスタンスを自動的に開始できます。 追加リソースが不要になったことがメトリックで示されたら、スケール セットの余分なインスタンスを停止できます。
自動スケーリングの条件、ルール、制限を定義する
自動スケールは、一連のスケール条件、ルール、および制限に基づいています。 スケーリング条件は、時刻と一連のスケール ルールを組み合わせたものです。 現在の時刻がスケーリング条件で定義されている期間内にある場合、条件のスケール ルールが評価されます。 この評価の結果で、スケール セット内のインスタンスを追加するか削除するかが判断されます。 スケーリング条件では、インスタンスの最大数と最小数に対するスケーリングの制限も定義します。
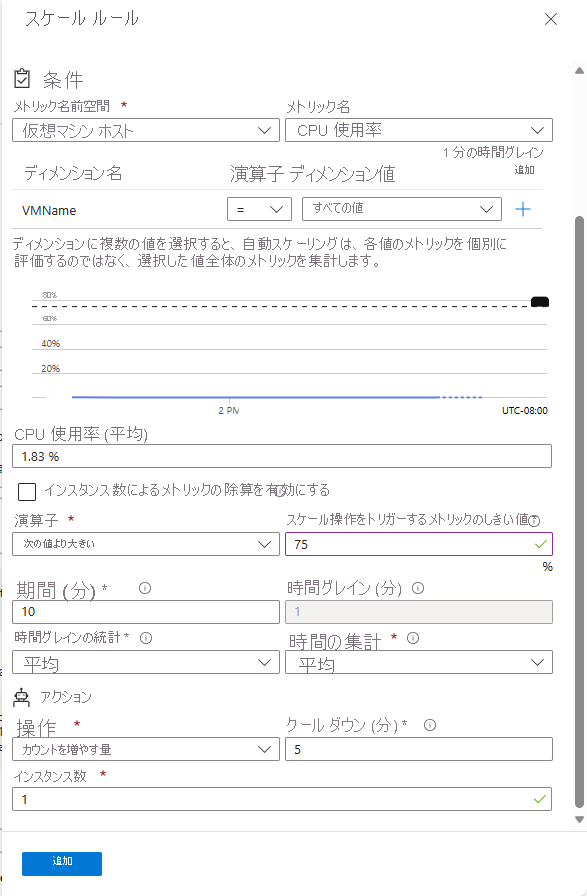
運送会社のシナリオでは、スケール セット全体の CPU 使用率を監視するスケール ルールを追加できます。 CPU 使用率が 75% のしきい値を超えた場合、スケール ルールで仮想マシン インスタンスの数を増やすことができます。 CPU 使用率を監視するスケール ルールをもう 1 つ作成し、使用率が 50% 未満になったら仮想マシン インスタンスの数を減らすこともできます。 アプリケーションは世界中で使用されるため、これらのルールは、特定の時間だけでなく、常にアクティブにしておく必要があります。
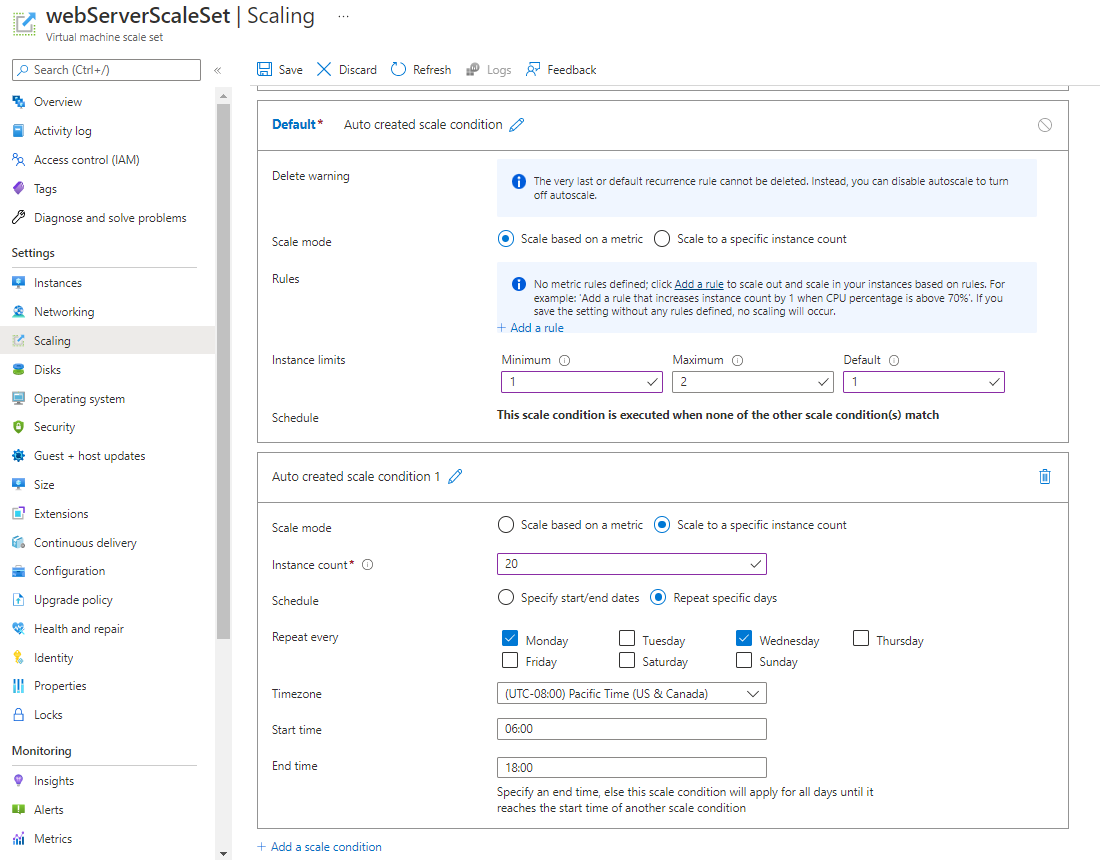
仮想マシン スケール セットには、多くのスケーリング条件を含めることができます。 一致する各スケーリング条件が処理されます。 スケール セットには、現在の時刻とパフォーマンス メトリックに一致する他のスケーリング条件がない場合に使用される、既定のスケーリング条件を含めることもできます。 既定のスケーリング条件は、常にアクティブです。 スケール ルールは含まれず、スケールインもスケールアウトもしない "無効" なスケール条件のように動作しますが、既定のスケール条件を変更して既定のインスタンス数を設定したり、スケールアウト後に再びスケールインするスケール ルールのペアを追加したりすることができます。
スケジュール ベースの自動スケーリングを使用する
スケジュール ベースのスケーリングでは、開始時刻と終了時刻、およびスケール セットに追加するインスタンスの数を指定します。 Azure portal の次のスクリーンショットは一例です。 インスタンスの数は、毎週月曜日と水曜日の午前 6 時から午後 6 時までの間、20 個にスケールアウトされます。 これらの時間以外は、他にスケーリング条件がない場合、既定のスケーリング条件が適用されます。
この場合、既定のルールによってシステムは 2 個のインスタンスにスケールダウンされます。 この値は、この既定のスケーリング条件での [最大値] です。
メトリック ベースの自動スケーリングを使用する
メトリック ベースのスケール ルールでは、監視するリソース (CPU 使用率、応答時間など) を指定します。 このスケール ルールでは、これらのメトリックの値に応じて、スケール セットのインスタンスを追加または削除します。 インスタンスの数に制限を指定すると、スケール セットが過度にスケールインまたはスケールアウトされないようにすることができます。
この例のシナリオでは、平均 CPU 使用率が 75% を超えた場合に、インスタンス数を 1 つ増やします。 また、スケールアウト操作を 50 インスタンスに制限します。 この制限は、攻撃によって発生する、コストのかかる暴走スケーリングを防ぐのに役立ちます。 同様に、平均 CPU 使用率が 50% を下回ったらスケールインします。
仮想マシン スケール セットの監視によく使用されるメトリックは次のとおりです。
- CPU 使用率: このメトリックでは、すべてのインスタンスの CPU 使用率が示されます。 この値が高い場合、インスタンスが CPU バインドになっていることを示し、クライアント要求の処理が遅れる可能性があります。
- 受信フローと送信フロー: これらのメトリックでは、スケール セット内の仮想マシンに出入りするネットワーク トラフィックの速度が示されます。
- ディスク読み取り操作数/秒とディスク書き込み操作数/秒: これらのメトリックでは、スケール セット全体のディスク I/O の量が示されます。
- データ ディスクのキューの深さ: このメトリックでは、仮想マシン上のデータ ディスクのみに対する I/O 要求のうち、処理待機中のものの数が示されます。
スケール ルールでは、すべてのインスタンスのメトリックに対して取得された値が集計されます。 "時間グレイン" と呼ばれる期間について、値が集計されます。 各メトリックには固有の時間グレインがありますが、通常この期間は 1 分です。 集計値は、"時間集計" と呼ばれます。 使用できる時間集計オプションは、"平均"、"最小"、"最大"、"合計"、"最終"、"カウント" です。
1 分間隔では、メトリックの変化が自動スケーリングを行う価値のある十分に長期的なものかどうかを判断するには短すぎます。 スケール ルールでは第 2 のステップが実行され、より長いユーザー指定の期間について、時間集計の値がさらに集計されます。 この時間の長さは "期間" と呼ばれます。 最小の期間は 5 分です。 たとえば、期間が 10 分に設定されている場合、スケール ルールでは、時間グレインに対して計算された 10 個の値が集計されます。
期間の集計計算は、時間グレインの集計計算と異なる場合があります。 たとえば、時間集計が "平均" で、収集される統計が 1 分の時間グレインに対する "CPU 使用率" であるとします。 1 分ごとに、その 1 分間におけるすべてのインスタンスでの平均 CPU 使用率が計算されます。 時間グレインの統計が "最大" に設定されていて、ルールの期間が 10 分に設定されている場合は、CPU 使用率の 10 個の平均値の最大値によって、ルールのしきい値を超えたかどうかが判断されます。
スケール ルールでは、メトリックがしきい値を超えたことが検出されると、スケーリング アクションが実行されます。 スケーリング アクションは、"スケールアウト" または "スケールイン" です。 スケールアウト アクションでは、インスタンスの数が増やされます。 スケールイン アクションでは、インスタンスの数が減らされます。
スケーリング アクションでは、"より小さい"、"より大きい"、"等しい" などの演算子を使用して、しきい値に対する対応方法が決定されます。 スケールアウト アクションでは、通常、"より大きい" 演算子を使用して、メトリックの値としきい値が比較されます。 スケールイン アクションでは、"より小さい" 演算子を使用して、メトリックの値としきい値が比較される傾向があります。 また、スケーリング アクションでは、使用可能な数が増やされたり減らされたりするのではなく、インスタンスの数が特定のレベルに設定されます。
スケーリング アクションには "クールダウン" 期間があり、分単位で指定します。 この期間中は、スケール ルールが再度トリガーされることはありません。 クールダウンにより、スケール イベントとイベントの合間にシステムを安定させることができます。 インスタンスの起動またはシャットダウンには時間がかかるため、数分間は収集されるメトリックに大きな変化が見られない場合があります。 最小のクールダウン期間は 5 分です。
最後に、ワークロードが減少したときのスケールインを計画する必要があります。 同じスケーリング条件でスケール ルールをペアにして定義することを検討してください。 一方のスケール ルールで、メトリックが上限のしきい値を超えたときにシステムをスケールアウトする方法を示す必要があります。 もう一方のルールで、同じメトリックが下限のしきい値を下回ったときにシステムをスケールインして元に戻す方法を定義する必要があります。 両方のしきい値を同じにしないでください。 これを行わないと、スケールアウトして再びスケールインするという一連の不安定なイベントが発生する可能性があります。
次の図に、Azure portal で定義されているスケール ルールを示します。