データ ウェアハウスのアーキテクチャについて説明する
大規模データ分析アーキテクチャはさまざまであり、その実装に使われる具体的なテクノロジもさまざまです。ただし、一般に次の要素が含まれています。
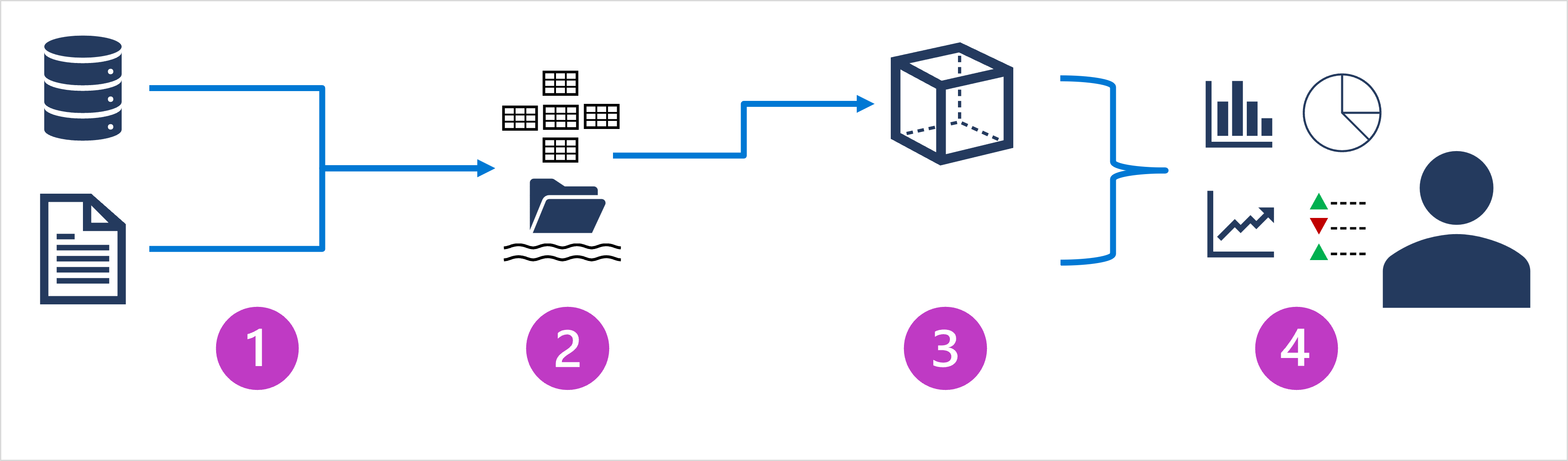
- データ インジェストと処理 – 1 つ以上のトランザクション対応のデータ ストア、ファイル、リアルタイム ストリーム、その他のソースからのデータが、データ レイクまたはリレーショナル データ ウェアハウスに読み込まれます。 読み込み操作には、通常、"抽出、変換、読み込み" (ETL) または "抽出、読み込み、変換" (ELT) のプロセスが含まれ、それによってデータは分析用にクリーンアップ、フィルター処理、再構築されます。 ETL プロセスでは、データは分析ストアに読み込まれる前に変換されますが、ELT プロセスでは、データはストアにコピーされてから変換されます。 どちらの方法でも、結果のデータ構造は分析クエリ用に最適化されます。 データ処理は、多くの場合、マルチノード クラスターを使用して大量のデータを並列処理できる分散システムによって実行されます。 データ インジェストには、静的データのバッチ処理と、ストリーミング データのリアルタイム処理の両方が含まれます。
- 分析データ ストア – 大規模な分析用のデータ ストアには、リレーショナル "データ ウェアハウス"、ファイル システム ベースの "データ レイク"、データ ウェアハウスとデータ レイクの機能を組み合わせたハイブリッド アーキテクチャ ("データ レイクハウス" または "レイク データベース" と呼ばれることもあります) が含まれます。 これらについては、後で詳しく説明します。
- 分析データ モデル – データ アナリストやデータ科学者は、分析データ ストア内のデータを直接操作できますが、普通は、レポート、ダッシュボード、対話型視覚エフェクトを簡単に生成できるように、データを事前に集計する 1 つ以上のデータ モデルを作成します。 多くの場合、これらのデータ モデルは "キューブ" として記述されており、数値データ値は 1 つ以上のディメンションにわたって集計されます (たとえば、製品別と地域別に総売上を調べるため)。 このモデルには、"ドリルアップ/ドリルダウン" 分析をサポートするために、データ値とディメンション エンティティの間のリレーションシップがカプセル化されています。
- データの視覚化 – データ アナリストは、分析モデルのデータと、直接分析ストアからのデータを使用して、レポート、ダッシュボード、その他の視覚エフェクトを作成します。 さらに、テクノロジ プロフェッショナルではない組織内のユーザーは、セルフサービス データ分析やレポート作成を実行することがあります。 データからの視覚化では、ビジネスや他の組織のために、傾向、比較、主要業績評価指標 (KPI) が示されます。また、ドキュメントや PowerPoint プレゼンテーション、Web ベースのダッシュボード、およびユーザーがデータを視覚的に調査できる対話型の環境で、印刷されたレポート、グラフ、チャートを使用することもできます。