自律インテリジェンス テクノロジの概要
まずは、自律インテリジェンスに含まれる 2 種類の AI 手法 (機械学習と深層強化学習) について分析します。
機械学習モデルは、データを使用して推定 (知識に基づいた推測) を行うコンピューター アルゴリズムです。 機械学習モデルは、設計方法が従来のアルゴリズムとは異なります。 このモデルは、人の脳のニューロンを生理学的に模倣した、相互接続された"ノード" (人工ニューロン) のシステムです。 これらは、各ノードの重みがネットワーク全体の出力に与える影響に基づいて、さまざまな重み (重要性の値) を受け取ります。、きます。 機械学習アルゴリズムは、データを使用して特定のタスクを改善します。 スパム フィルターは、機械学習モデルの例です。 機械学習モデルは、時間の経過に従ってデータから学習します。 機械学習モデルには、教師あり学習と教師なし学習の 2 つの主要なカテゴリがあります。 教師あり学習を使用して、特定の入力にラベルを適用するようにコンピューターをトレーニングします。 たとえば、分類子をトレーニングするには、それを猫や犬のラベル付き画像に公開します。 トレーニングが完了すると、モデルは、猫や犬のラベルなしの新しい画像を分類するようになります。
教師なし学習は、分類またはラベル付けされていないデータセット内のパターンまたは隠された構造を見つけるために使用されます。
ディープ ラーニングは、複数のレイヤーを使用して生の入力から上位レベルの特徴を段階的に抽出する機械学習アルゴリズムです。 ネットワークは、各ノードの重みの進化に応じて、ネットワークの入力と出力の間の複雑な関係を表す方法を学習します。 そのため、ディープ ラーニング アルゴリズムでは、タスクの成功を特定の条件に関連付け、関連するノードにより多くの重みを割り当てることで、生物の脳の神経経路に似た関係を強化します。
機械学習では、特徴を手動で指定する必要があります。 たとえば、住宅価格を予測する必要がある場合は、住宅の価格に影響を与える特徴を指定する必要があります (例: 寝室の数、良い学校への近さなど)。 ただし、ディープ ラーニング アルゴリズムは、特徴を自動的に検出するように設計されています。 また、非構造化データを操作することもできます。 ディープ ラーニングのこの機能は表現学習と呼ばれます。これは、分類子やその他の予測子を構築するときに役立つ情報を簡単に抽出できるようにするデータ表現を学習する機能です。 この機能により、ディープ ラーニング アルゴリズムはより強力になりますが、データの必要性 (何百万ものデータ ポイントが必要) とコンピューティング リソースの観点から、アルゴリズムの複雑さも増します。
機械学習のもう 1 つの種類が、強化学習 (RL) です。 静的データセットを使用して動作する教師あり学習や教師なし学習とは異なり、RL は動的環境からのデータを処理します。 この場合の目標は、データをクラスター化したり、データにラベルを付けたりするのではなく、最適な結果を生成する行動の最適な順序を見つけることです。 強化学習では、ソフトウェア エージェントが環境と対話し、そこから学習できるようにすることで、最適な行動の順序を見つけるという問題を解決します。 エージェントは関数であると考えることができます。 環境との相互作用から状態の観察を受け取り (入力)、エージェントが各ステップで実行する必要がある行動にマップします (出力)。 この関数はポリシーと呼ばれます。 一連の観察値 (状態) を指定すると、ポリシーによって実行する行動が決定されます。 ポリシーは、環境から実行された行動と収集された報酬に基づいて動的に変化します。 エージェントの目標は、各ステップの報酬だけでなく、長期的な報酬を最大化することです。
強化学習は元々、Richard Sutton らが 1960 年代に制御理論を発展させたものです。 彼らは関数からの学習をテーブルに格納しました。 テーブルには、膨大な数の行が必要となるため、RL のスケーラビリティに制限があります。 ディープ ニューラル ネットワークによる表現学習機能と強化学習を組み合わせると、深層強化学習 (DRL) が実現します。 DRL は、RL の課題を 2 つの方法で克服します。 1 つ目として、状態空間と行動空間が大きくなりすぎて、テーブルを使用してこれらの表現を格納できない場合、DRL はこれらの学習をニューラル ネットワークに格納するのに役立ちます。 その後、ニューラル ネットワークが複雑な非線形リレーションシップを構築して応答できます。 2 つ目として、ニューラル ネットワークはどんな関数にも、その関数を近似できるネットワークが存在するという普遍性定理に従います。 つまり、理論上、DRL は大きな状態空間を処理でき、どんなシステムでも制御できます。 DRL (深層強化学習) は、Go のようなゲームをプレイする上で人間のような能力を発揮し、さらにはそうしたゲームで最高の人間のプレーヤーを上回っています。
強化学習では、エージェントは機械学習アルゴリズムによって制御されます。 各ステップで、エージェントは状態を観察し、環境と対話し、試行錯誤を通じて行動の結果を学習します。 エージェントは、行動によって受け取った報酬に応じて、その動作を変更することを学習します。
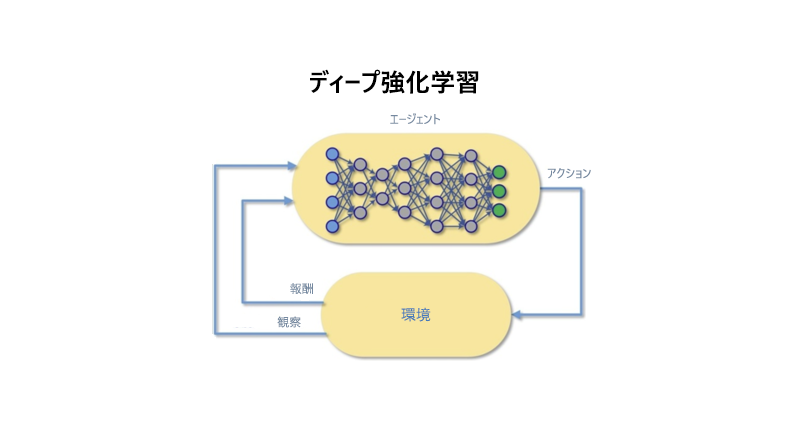
前の図では、DRL エージェントが環境を観察します。 これが、環境で実行されるアクションを決定し、そのアクションが目標にとって好ましい場合は肯定的な報酬を受け取ります。 それ以外の場合は、否定的な報酬を受け取ります。
深層強化学習には、次のような固有の特性がいくつかあります。
- 条件の変化に応じて動作を変更する: モデル化されるプロセスの変化に応じて、DRL は多くのシナリオを実践することで、その動作を学習し、変更できます。
- あいまいな非線形の相関関係を通じて制御する。 DRL は、ニューラル ネットワークに基づいているため、複雑な非線形関係を学習できます。 このような関係は、あいまいで非線形の相関関係全体で決定を行う必要がありますが、これは問題のエキスパートでさえ困難あるいは不可能です。
- 複雑な認識に基づいて行動する。 DRL は、視覚による認識、音声による認識、カテゴリや分類の理解などの、複雑な認識に基づいてシステムを適切に制御できます。
- 直接測定されない環境の変化に対応する。 主要なシステム変数がすべて測定されることはめったにありませんが、人間のオペレーターはシステムを適切に制御します。 自動システムでは、システム入力やシステム自体が不明な方法で変化してもシステムやプロセスは制御されませんが、現実世界のシステムではこのような条件下での制御が必要になることがよくあります。 DRL アルゴリズムは、システムの変化を測定できないこのような状況に対処できます。
- 戦略について学習する。 人間のオペレーターは、どの制御行動を追求するかを決定して教示するために、戦略を頻繁に使用します。 深層強化学習では、戦略を自動的に学習できます。
産業用の機械またはプロセスで、これらの条件のいずれか、またはすべてが特定された場合、機械教示のコンポーネントとして自律インテリジェンス テクノロジを使用すると、産業システムの制御に使用されている現在の方法よりも優れた性能を発揮できるということを示しています。