프로덕션 환경에서 모델용 데이터 수집
적용 대상: Python SDK azureml v1
Python SDK azureml v1
이 문서에서는 AKS(Azure Kubernetes Service) 클러스터에 배포된 Azure Machine Learning 모델에서 데이터를 수집하는 방법을 보여 줍니다. 수집된 데이터는 Azure Blob Storage에 저장됩니다.
수집을 사용하도록 설정하면 수집되는 데이터를 활용하여 다음 작업을 수행할 수 있습니다.
수집한 프로덕션 데이터의 데이터 드리프트를 모니터링.
Power BI 또는 Azure Databricks 를 사용하여 수집된 데이터를 분석
모델을 다시 학습시키거나 최적화할 시기를 더 효율적으로 결정
수집한 데이터로 모델 다시 학습
제한 사항
- 모델 데이터 수집 기능은 Ubuntu 18.04 이미지에서만 작동할 수 있습니다.
Important
2023년 3월 10일 현재 Ubuntu 18.04 이미지는 더 이상 사용되지 않습니다. Ubuntu 18.04 이미지에 대한 지원은 2023년 4월 30일에 EOL에 도달하면 2023년 1월부터 삭제됩니다.
MDC 기능은 Ubuntu 18.04 이외의 다른 이미지와 호환되지 않습니다. Ubuntu 18.04 이미지가 더 이상 사용되지 않는 후에는 사용할 수 없습니다.
참조할 수 있는 추가 정보:
참고 항목
데이터 수집 기능은 현재 미리 보기 상태이며 프로덕션 워크로드에는 미리 보기 기능이 권장되지 않습니다.
수집되는 데이터 및 데이터가 이동하는 위치 파악
다음 데이터를 수집할 수 있습니다.
AKS 클러스터에 배포된 웹 서비스의 모델 입력 데이터. 음성 오디오, 이미지, 비디오는 수집되지 ‘않습니다’.
프로덕션 입력 데이터를 사용하는 모델 예측
참고 항목
이 데이터에 대한 사전 집계 및 사전 계산은 현재 수집 서비스에서 지원하지 않습니다.
출력은 Blob 스토리지에 저장됩니다. 데이터가 Blob 스토리지에 추가되기 때문에 원하는 도구를 선택하여 분석을 실행할 수 있습니다.
Blob에서 출력 데이터의 경로 형식은 다음 구문을 따릅니다.
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
참고 항목
0.1.0a16 이전 버전의 Python용 Azure Machine Learning SDK 버전에서는 designation 인수의 이름이 identifier로 지정됩니다. 이전 버전을 사용하여 코드를 개발한 경우 이에 맞게 업데이트해야 합니다.
필수 조건
Azure 구독이 없는 경우 시작하기 전에 체험 계정을 만듭니다.
Azure Machine Learning 작업 영역, 스크립트가 포함된 로컬 디렉터리 및 Python용 Azure Machine Learning SDK가 설치되어 있어야 합니다. 해당 항목을 설치하는 방법을 알아보려면 개발 환경 구성 방법을 참조하세요.
AKS에 배포할 학습된 기계 학습 모델이 필요합니다. 해당 모델이 없으면 이미지 분류 모델 학습 자습서를 참조하세요.
AKS 클러스터가 필요합니다. 모델을 만들고 배포하는 방법에 대한 자세한 정보는 Azure에 기계 학습 모델 배포를 참조하세요.
환경을 설정하고 Azure Machine Learning 모니터링 SDK를 설치합니다.
modeldatacollector의 필수 종속성인
libssl 1.0.0과 함께 제공되는 Ubuntu 18.04 기반 docker 이미지를 사용합니다. 미리 빌드된 이미지를 참조할 수 있습니다.
데이터 수집 사용
Azure Machine Learning 또는 기타 도구를 통해 배포하는 모델과 관계없이 데이터 수집을 사용하도록 설정할 수 있습니다.
데이터 수집을 사용하도록 설정하려면 다음을 수행해야 합니다.
점수 매기기 파일을 엽니다.
파일 맨 위에 다음 코드를 추가합니다.
from azureml.monitoring import ModelDataCollectorinit함수에서 데이터 수집 변수를 선언합니다.global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId는 선택적 매개 변수입니다. 모델에 필요하지 않은 경우 사용할 필요가 없습니다. CorrelationId를 사용하면 LoanNumber나 CustomerId와 같은 다른 데이터와 함께 보다 쉽게 매핑할 수 있습니다.
Identifier 매개 변수는 나중에 Blob에서 폴더 구조를 빌드하는 데 사용됩니다. 이를 사용하여 원시 데이터와 처리된 데이터를 구분할 수 있습니다.
run(input_df)함수에 다음 코드 줄을 추가합니다.data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure Blob데이터 수집은 AKS에서 서비스를 배포할 때 true로 자동 설정되지 ‘않습니다’. 다음 예제와 같이 구성 파일을 업데이트합니다.
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)이 구성을 변경하여 서비스 모니터링용 Application Insights도 사용 설정할 수 있습니다.
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)새 이미지를 만들고 기계 학습 모델을 배포하려면 Azure에 기계 학습 모델 배포를 참조하세요.
웹 서비스 환경의 Conda 종속성에 ‘Azure 모니터링’ pip 패키지를 추가합니다.
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
데이터 수집 비활성화
데이터 수집은 언제든지 중지할 수 있습니다. 데이터 수집을 사용하지 않도록 설정하려면 Python 코드를 사용합니다.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
데이터 유효성 검사 및 분석
선호하는 도구를 선택하여 Blob 스토리지에 수집된 데이터를 분석할 수 있습니다.
Blob 데이터에 빠르게 액세스
Azure 포털에 로그인합니다.
작업 영역을 엽니다.
스토리지를 선택합니다.

Blob의 출력 데이터 경로는 다음 구문을 따릅니다.
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Power BI를 사용하여 모델 데이터 분석
Power BI Desktop을 다운로드하고 엽니다.
데이터 가져오기를 선택하고 Azure Blob Storage를 선택합니다.
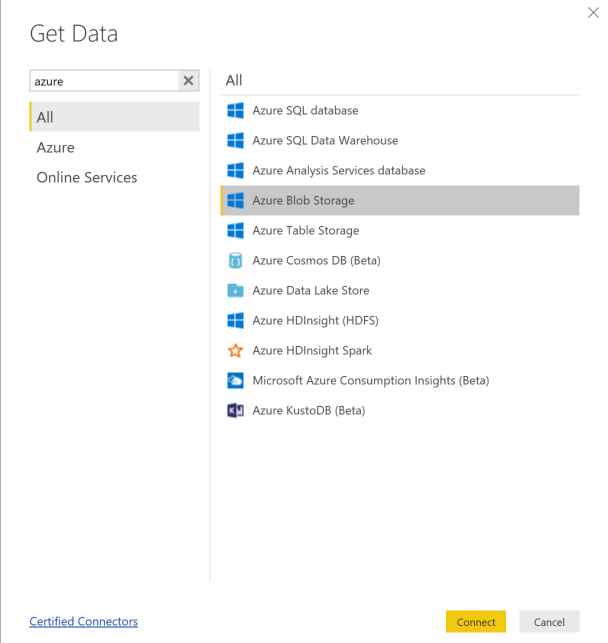
스토리지 계정 이름을 추가하고 스토리지 키를 입력합니다. Blob의 설정>액세스 키를 선택하여 이 정보를 찾을 수 있습니다.
모델 데이터 컨테이너를 선택하고 편집을 선택합니다.

쿼리 편집기에서 이름 열 아래를 클릭하고 스토리지 계정을 추가합니다.
필터에 모델 경로를 입력합니다. 특정 연도 또는 특정 월의 파일만 보려면 필터 경로를 확장하기만 하면 됩니다. 예를 들어 3월 데이터만 보려면 다음 필터 경로를 사용합니다.
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
이름 값을 기준으로 관련된 데이터를 필터링합니다. 예측 및 입력을 저장한 경우 각각에 대해 쿼리를 만들어야 합니다.
콘텐츠 열 제목 옆에 있는 하향 이중 화살표를 선택하여 파일을 결합합니다.

확인을 선택합니다. 데이터가 미리 로드됩니다.

닫기 및 적용을 선택합니다.
입력 및 예측을 추가한 경우 자동으로 RequestId 값에 따라 테이블 상관관계 순서가 설정됩니다.
모델 데이터에 대한 사용자 지정 보고서 빌드를 시작합니다.




Azure Databricks를 사용하여 모델 데이터 분석
Databricks 작업 영역으로 이동합니다.
Databricks 작업 영역에서 데이터 업로드를 선택합니다.

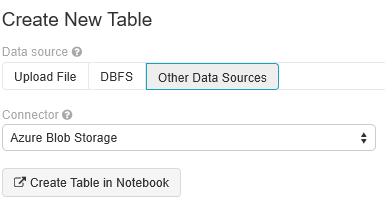
새 테이블 만들기를 선택하고 기타 데이터 원본>Azure Blob Storage>Notebook에서 테이블 만들기를 선택합니다.
데이터 위치를 업데이트합니다. 예를 들어 다음과 같습니다.
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/*/*/data.csv" file_type = "csv"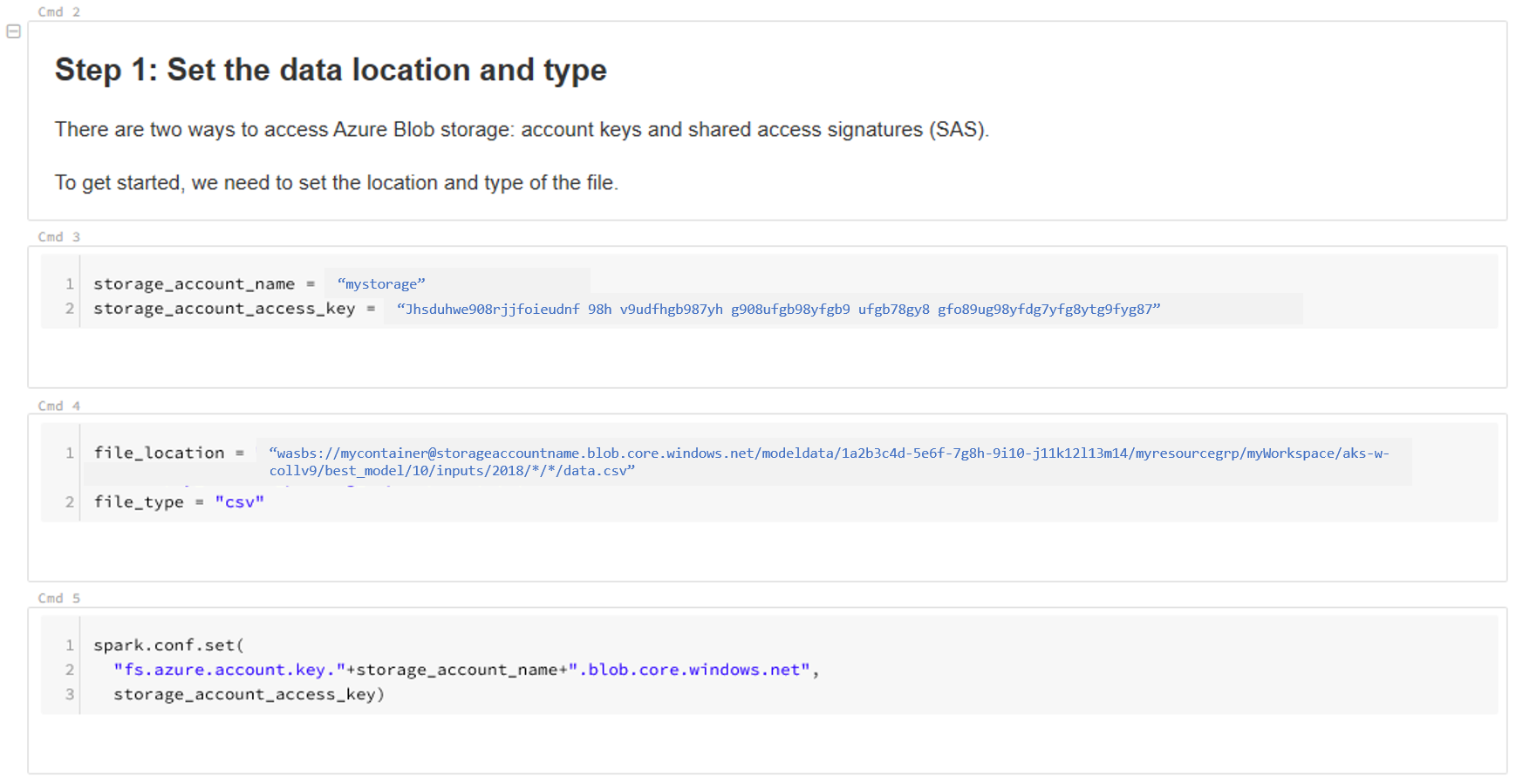
데이터를 보고 분석하려면 템플릿의 단계를 따릅니다.



다음 단계
수집한 데이터에 대한 데이터 드리프트를 검색합니다.