번잡한 I/O 안티패턴
많은 수의 I/O 요청의 누적 효과는 성능 및 응답성에 상당한 영향을 미칠 수 있습니다.
문제 설명
네트워크 호출 및 기타 I/O 작업은 컴퓨팅 작업에 비해 본질적으로 느립니다. 일반적으로 각 I/O 요청에는 상당한 오버헤드가 있으며 수많은 I/O 작업의 누적 효과로 인해 시스템 속도가 느려질 수 있습니다. 다음은 수다스러운 I/O의 몇 가지 일반적인 원인입니다.
개별 레코드를 별도의 요청으로 데이터베이스에 읽고 쓰기
다음 예제에서는 제품 데이터베이스에서 읽습니다. 세 개의 테이블, Product및 ProductSubcategoryProductPriceListHistory. 이 코드는 일련의 쿼리를 실행하여 가격 책정 정보와 함께 하위 범주의 모든 제품을 검색합니다.
- 테이블에서 하위 범주를 쿼리합니다
ProductSubcategory. Product테이블을 쿼리하여 해당 하위 범주의 모든 제품을 찾습니다.- 각 제품에 대해 테이블의 가격 책정 데이터를 쿼리합니다
ProductPriceListHistory.
애플리케이션은 Entity Framework를 사용하여 데이터베이스를 쿼리합니다. 전체 샘플은 여기에서 찾을 수 있습니다.
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}
이 예제에서는 문제를 명시적으로 보여 주지만 O/RM이 자식 레코드를 한 번에 하나씩 암시적으로 가져오는 경우 문제를 마스킹할 수 있습니다. 이를 "N+1 문제"라고 합니다.
단일 논리 연산을 일련의 HTTP 요청으로 구현
개발자가 개체 지향 패러다임을 따르고 원격 개체를 메모리의 로컬 개체인 것처럼 처리하려고 할 때 종종 발생합니다. 이로 인해 네트워크 왕복이 너무 많을 수 있습니다. 예를 들어 다음 웹 API는 개별 HTTP GET 메서드를 통해 개체의 User 개별 속성을 노출합니다.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}
이 접근 방식에는 기술적으로 문제가 없지만 대부분의 클라이언트는 각각 User에 대해 여러 속성을 가져와야 하므로 다음과 같은 클라이언트 코드가 생성됩니다.
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();
디스크의 파일 읽기 및 쓰기
파일 I/O에는 데이터를 읽거나 쓰기 전에 파일을 열고 적절한 지점으로 이동하는 작업이 포함됩니다. 작업이 완료되면 운영 체제 리소스를 절약하기 위해 파일을 닫을 수 있습니다. 파일에 소량의 정보를 지속적으로 읽고 쓰는 애플리케이션은 상당한 I/O 오버헤드를 생성합니다. 쓰기 요청이 작으면 파일 조각화가 발생할 수 있으므로 후속 I/O 작업이 더 느려질 수 있습니다.
다음 예제에서는 개체를 파일에 쓰는 Customer 데 사용합니다FileStream. 파일을 FileStream 만들면 파일이 열리고 삭제하면 파일이 닫힙니다. (문은 using 개체를 FileStream 자동으로 삭제합니다.) 새 고객이 추가되면 애플리케이션에서 이 메서드를 반복적으로 호출하면 I/O 오버헤드가 빠르게 누적됩니다.
private async Task SaveCustomerToFileAsync(Customer customer)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
문제를 해결하는 방법
데이터를 더 크고 적은 수의 요청으로 패키징하여 I/O 요청 수를 줄입니다.
데이터베이스에서 데이터를 여러 개의 작은 쿼리 대신 단일 쿼리로 가져옵니다. 다음은 제품 정보를 검색하는 수정된 코드 버전입니다.
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}
웹 API에 대한 REST 디자인 원칙을 따릅니다. 다음은 이전 예제에서 수정된 웹 API 버전입니다. 각 속성에 대해 별도의 GET 메서드 대신 해당 메서드를 반환 User하는 단일 GET 메서드가 있습니다. 이로 인해 요청당 응답 본문이 더 커지지만 각 클라이언트는 더 적은 수의 API 호출을 수행할 수 있습니다.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();
파일 I/O의 경우 메모리의 데이터를 버퍼링한 다음 버퍼링된 데이터를 단일 작업으로 파일에 쓰는 것이 좋습니다. 이 방법을 사용하면 반복적으로 파일을 열고 닫는 오버헤드를 줄이고 디스크에서 파일의 조각화를 줄이는 데 도움이 됩니다.
// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var customer in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var customer = new Customer(...);
customers.Add(customer);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);
고려 사항
처음 두 예제에서는 I/O 호출을 줄이지만 각각 더 많은 정보를 검색합니다. 이 두 가지 요소 간의 절충을 고려해야 합니다. 정답은 실제 사용 패턴에 따라 달라집니다. 예를 들어 웹 API 예제에서는 클라이언트에 사용자 이름만 필요한 경우가 많을 수 있습니다. 이 경우 별도의 API 호출로 노출하는 것이 합리적일 수 있습니다. 자세한 내용은 불필요한 페치 안티패턴을 참조하세요.
데이터를 읽을 때 I/O 요청을 너무 크게 만들지 마세요. 애플리케이션이 사용할만한 정보만 검색해야 합니다.
경우에 따라 개체에 대한 정보를 두 개의 청크, 대부분의 요청을 고려하는 자주 액세스하는 데이터 및 드물게 사용되는 덜 자주 액세스되는 데이터 로 분할하는 데 도움이 됩니다. 가장 자주 액세스되는 데이터는 개체에 대한 총 데이터의 상대적으로 작은 부분이기 때문에 해당 부분만 반환하면 상당한 I/O 오버헤드를 절약할 수 있습니다.
데이터를 작성할 때 긴 작업 중 경합 가능성을 줄이려면 필요한 것보다 오랫동안 리소스를 잠그지 마세요. 쓰기 작업이 여러 데이터 저장소, 파일 또는 서비스에 걸쳐 있는 경우 최종적으로 일관된 접근 방식을 채택합니다. 데이터 일관성 지침을 참조하세요.
데이터를 쓰기 전에 메모리의 데이터를 버퍼링하는 경우 프로세스가 충돌하면 데이터가 취약합니다. 일반적으로 데이터 속도에 버스트가 있거나 상대적으로 스파스가 있는 경우 Event Hubs와 같은 외부 지속성 큐에서 데이터를 버퍼링하는 것이 더 안전할 수 있습니다.
서비스 또는 데이터베이스에서 검색하는 데이터를 캐시하는 것이 좋습니다. 이렇게 하면 동일한 데이터에 대한 반복된 요청을 방지하여 I/O 볼륨을 줄일 수 있습니다. 자세한 내용은 캐싱 모범 사례를 참조하세요.
문제를 감지하는 방법
수다스러운 I/O의 증상에는 대기 시간이 높고 처리량이 낮습니다. 최종 사용자는 I/O 리소스에 대한 경합 증가로 인해 서비스 시간 초과로 인한 확장된 응답 시간 또는 실패를 보고할 가능성이 높습니다.
다음 단계를 수행하여 문제의 원인을 식별할 수 있습니다.
- 프로덕션 시스템의 프로세스 모니터링을 수행하여 응답 시간이 부족한 작업을 식별합니다.
- 이전 단계에서 식별된 각 작업의 부하 테스트를 수행합니다.
- 부하 테스트 중에 각 작업에서 수행한 데이터 액세스 요청에 대한 원격 분석 데이터를 수집합니다.
- 데이터 저장소로 전송되는 각 요청에 대한 자세한 통계를 수집합니다.
- 테스트 환경에서 애플리케이션을 프로파일링하여 가능한 I/O 병목 현상이 발생할 수 있는 위치를 설정합니다.
다음과 같은 증상을 찾습니다.
- 동일한 파일에 대해 많은 수의 작은 I/O 요청이 있습니다.
- 애플리케이션 인스턴스가 동일한 서비스에 대해 수행하는 다수의 작은 네트워크 요청.
- 애플리케이션 인스턴스가 동일한 데이터 저장소에 대해 수행한 많은 수의 작은 요청입니다.
- I/O 바인딩되는 애플리케이션 및 서비스입니다.
예제 진단
다음 섹션에서는 이러한 단계를 데이터베이스를 쿼리하는 앞에서 설명한 예제에 적용합니다.
애플리케이션 부하 테스트
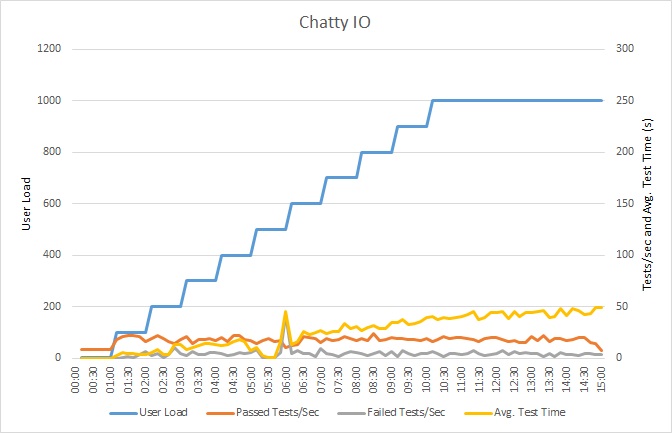
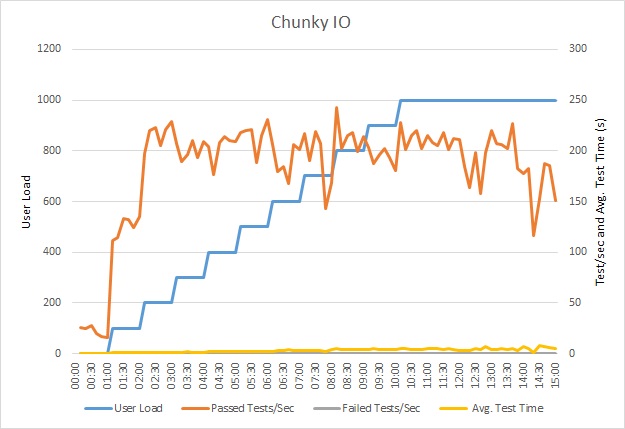
이 그래프는 부하 테스트의 결과를 보여줍니다. 중간 응답 시간은 요청당 10초 단위로 측정됩니다. 그래프는 매우 높은 대기 시간을 보여줍니다. 사용자가 1,000명인 경우 사용자는 쿼리 결과를 확인하기 위해 거의 1분 동안 기다려야 할 수 있습니다.
참고 항목
애플리케이션은 Azure SQL Database를 사용하여 Azure 앱 Service 웹앱으로 배포되었습니다. 부하 테스트는 최대 1,000명의 동시 사용자로 구성된 시뮬레이션된 단계 워크로드를 사용했습니다. 최대 1,000개의 동시 연결을 지원하는 연결 풀을 사용하여 데이터베이스를 구성하여 연결 경합이 결과에 영향을 줄 수 있는 가능성을 줄였습니다.
애플리케이션 모니터링
APM(애플리케이션 성능 모니터링) 패키지를 사용하여 수다스러운 I/O를 식별할 수 있는 주요 메트릭을 캡처하고 분석할 수 있습니다. 중요한 메트릭은 I/O 워크로드에 따라 달라집니다. 이 예제의 경우 흥미로운 I/O 요청은 데이터베이스 쿼리입니다.
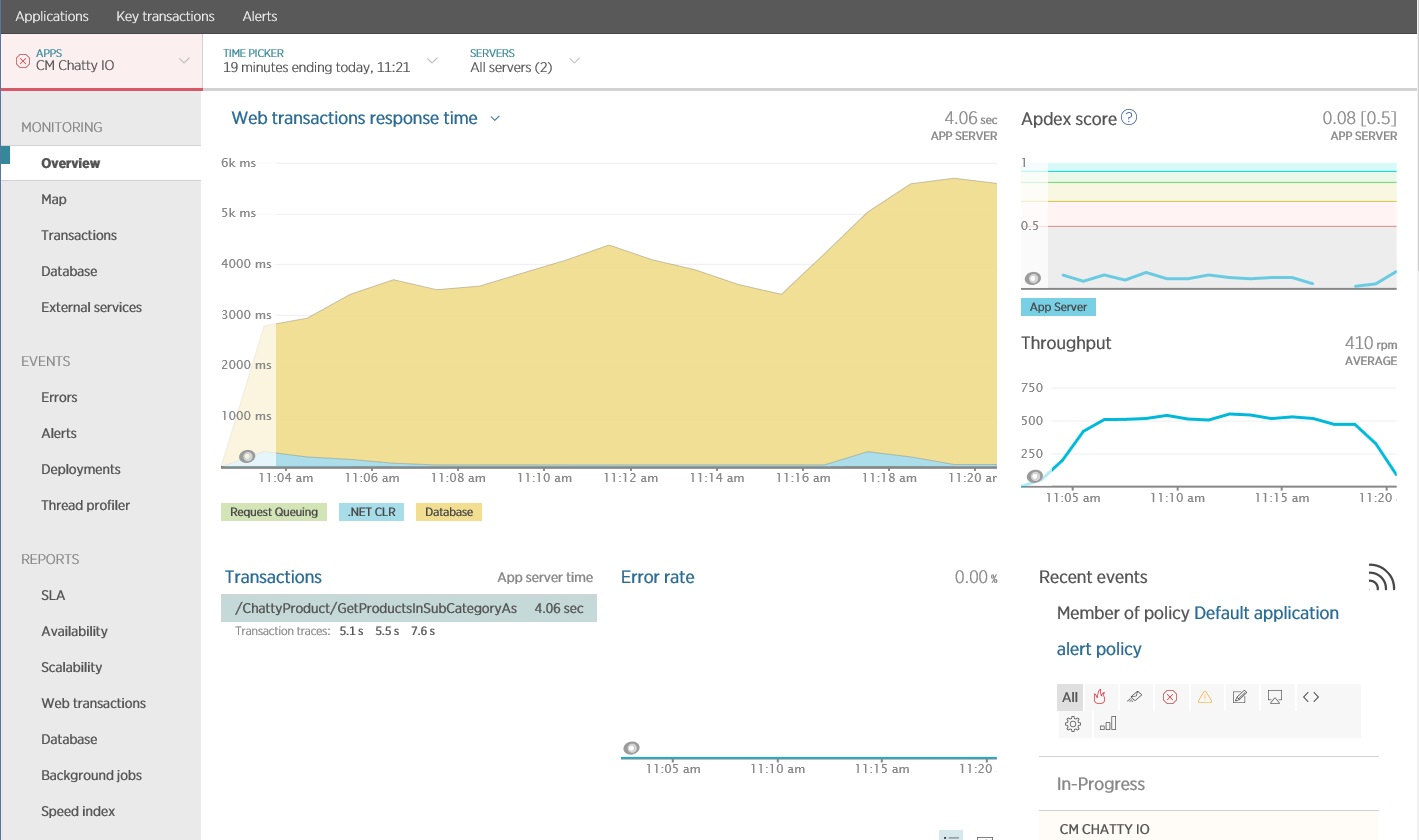
다음 이미지는 New Relic APM을 사용하여 생성된 결과를 보여줍니다. 최대 워크로드 기간 동안 평균 데이터베이스 응답 시간은 요청당 약 5.6초에 최고점에 도달했습니다. 테스트 기간 동안 시스템은 분당 평균 410건의 요청을 지원할 수 있었습니다.
자세한 데이터 액세스 정보 수집
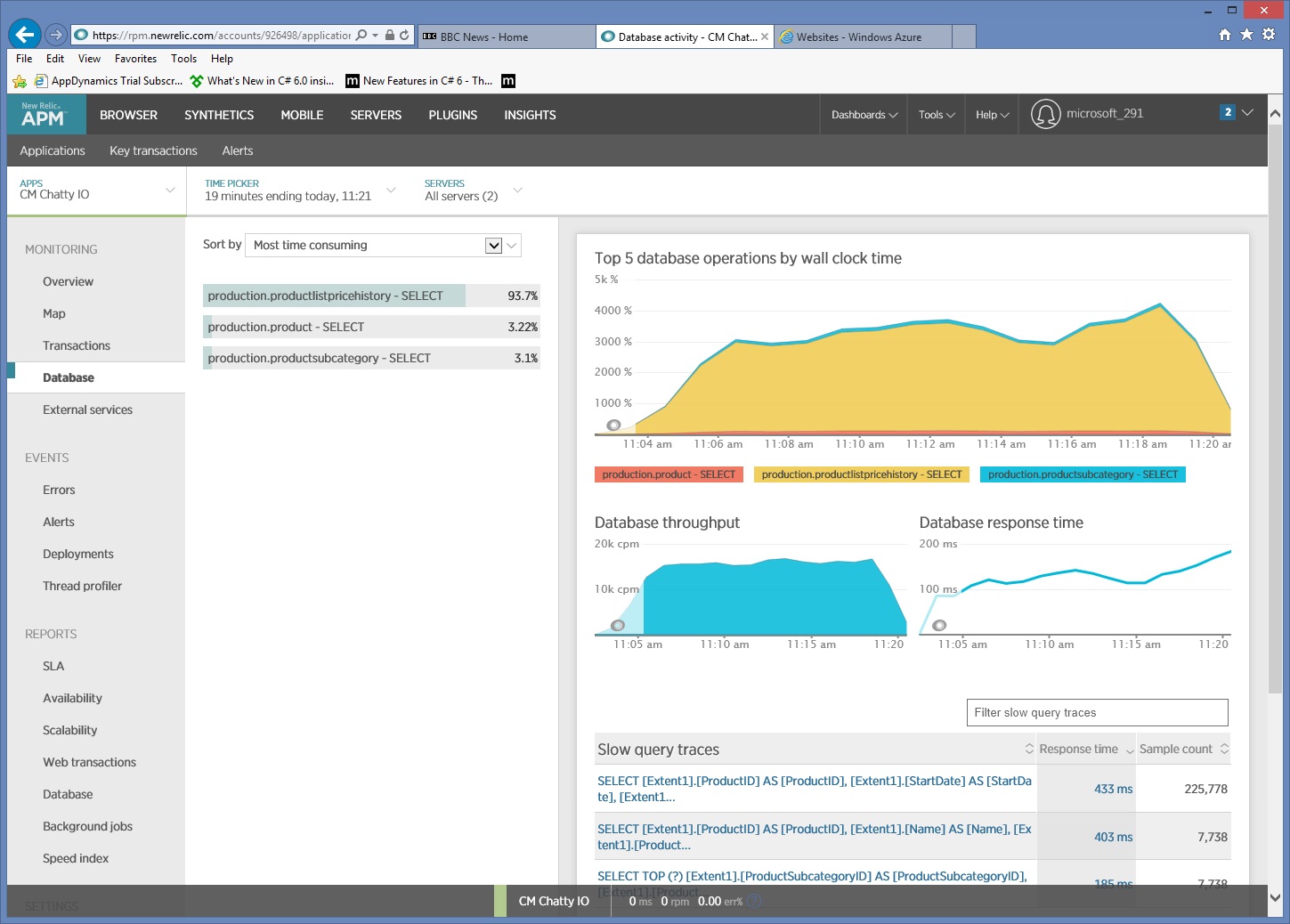
모니터링 데이터를 자세히 살펴보면 애플리케이션이 세 가지 SQL SELECT 문을 실행합니다. 이러한 요청은 Entity Framework에서 생성된 요청에 해당하여 , Product및 ProductSubcategory 테이블에서 데이터를 ProductListPriceHistory가져옵니다. 또한 테이블에서 데이터를 ProductListPriceHistory 검색하는 쿼리는 크기 순으로 가장 자주 실행되는 SELECT 문입니다.
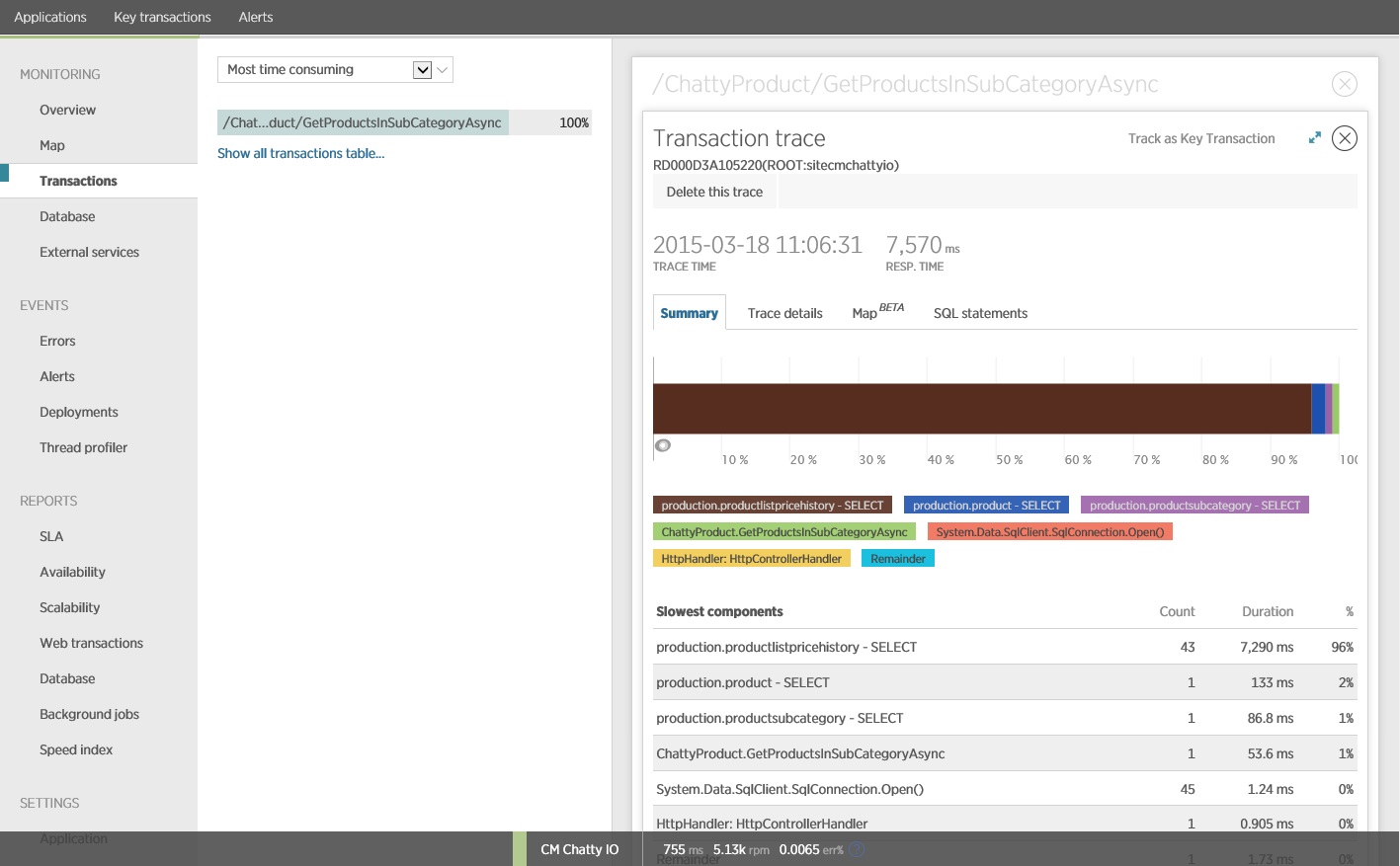
앞에서 보여 준 메서드가 GetProductsInSubCategoryAsync 45개의 SELECT 쿼리를 수행하는 것으로 나타났습니다. 각 쿼리를 사용하면 애플리케이션이 새 SQL 연결을 엽니다.
참고 항목
이 이미지는 부하 테스트에서 작업의 가장 느린 인스턴스에 GetProductsInSubCategoryAsync 대한 추적 정보를 보여 줍니다. 프로덕션 환경에서는 가장 느린 인스턴스의 추적을 검사하여 문제를 암시하는 패턴이 있는지 확인하는 것이 유용합니다. 평균 값을 살펴보면 부하가 크게 악화되는 문제를 간과할 수 있습니다.
다음 이미지는 발급된 실제 SQL 문을 보여 줍니다. 가격 정보를 가져 오는 쿼리는 제품 하위 범주의 개별 제품에 대해 실행됩니다. 조인을 사용하면 데이터베이스 호출 수가 상당히 줄어듭니다.
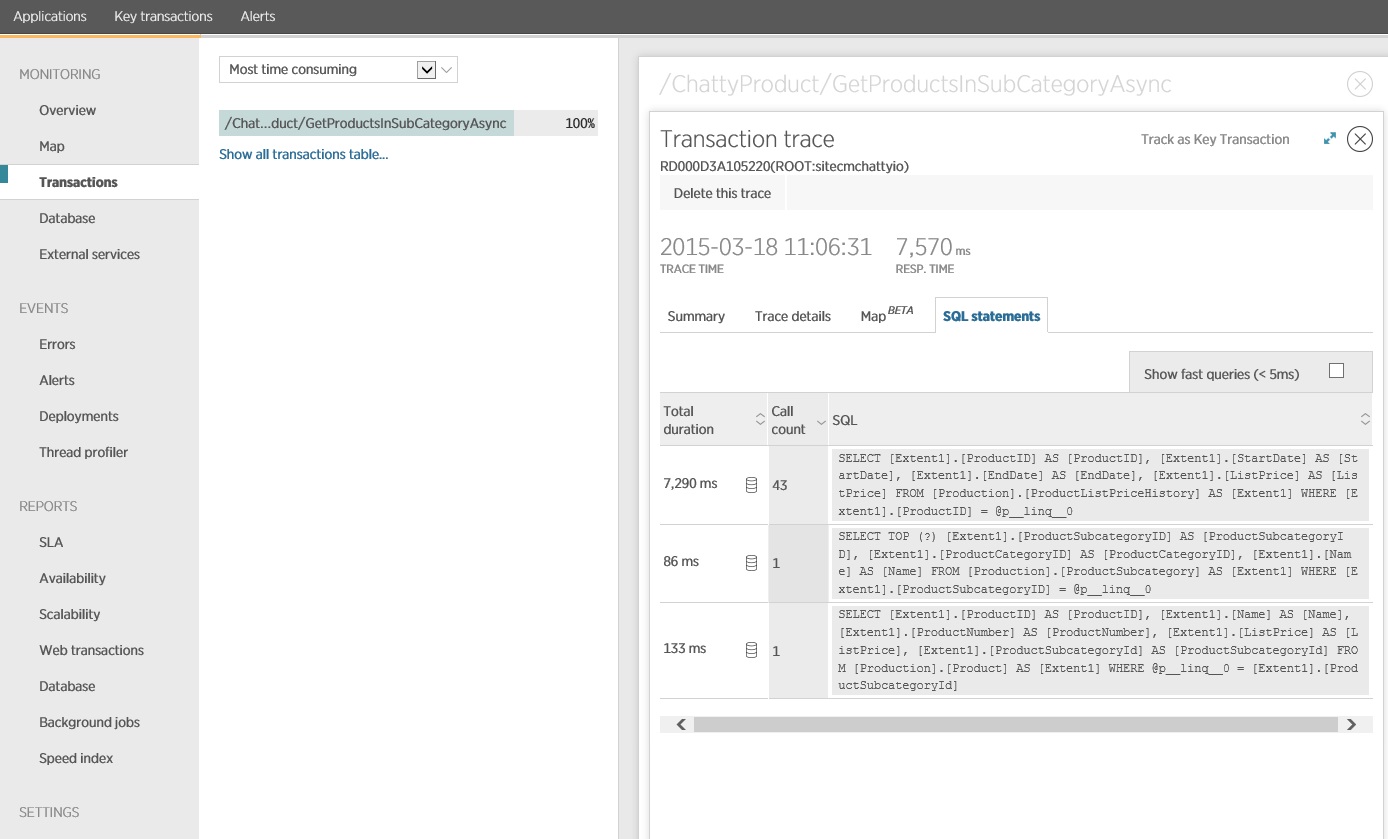
Entity Framework와 같은 O/RM을 사용하는 경우, SQL 쿼리를 추적하면 O/RM이 프로그래밍 방식 호출을 SQL 문으로 변환하는 방식에 대한 통찰력을 얻을 수 있고 데이터 액세스가 최적화될 수 있는 영역을 알아낼 수 있습니다.
솔루션 구현 및 결과 확인
Entity Framework에 대한 호출을 다시 작성하면 다음과 같은 결과가 생성되었습니다.
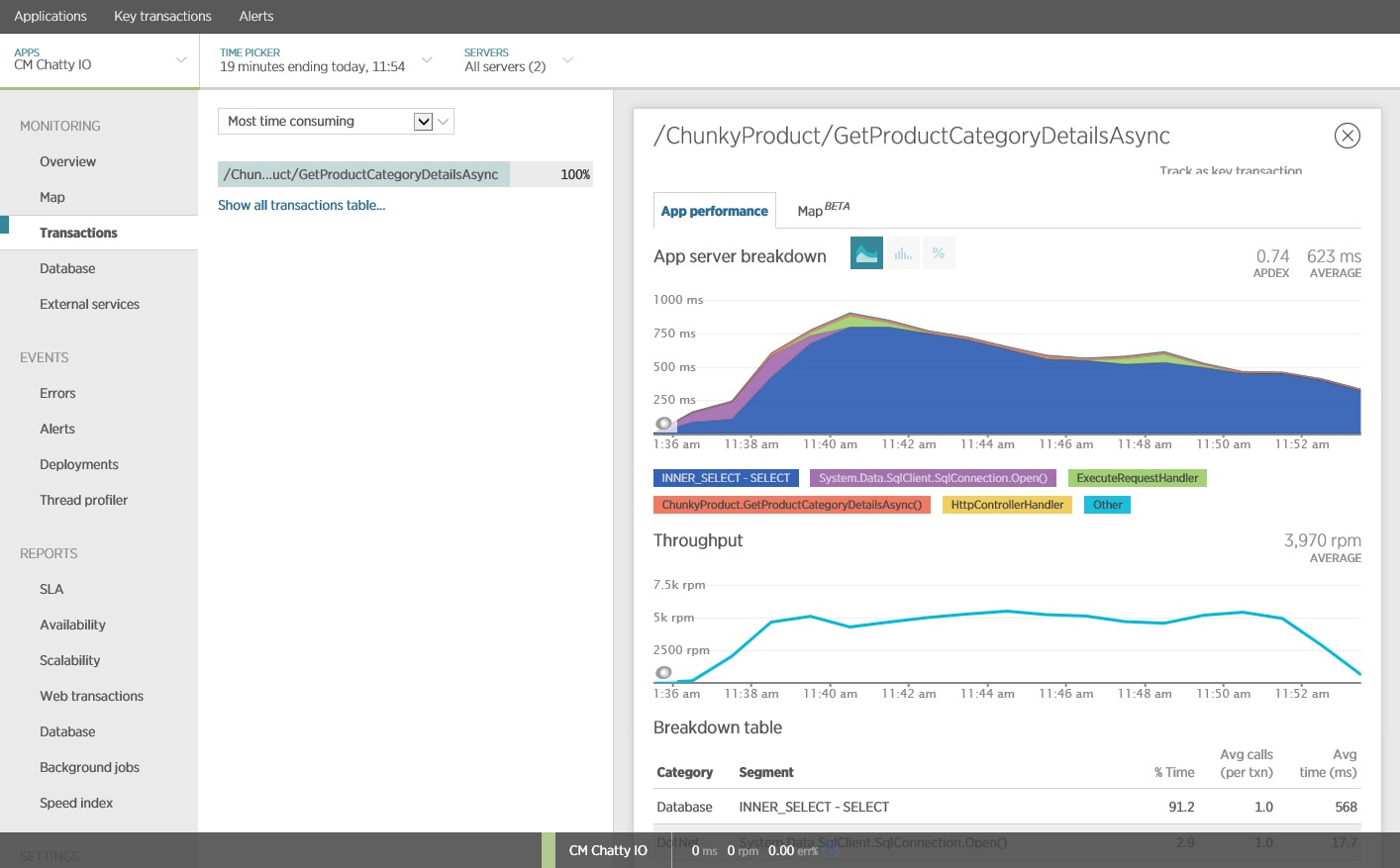
이 부하 테스트는 동일한 부하 프로필을 사용하여 동일한 배포에서 수행되었습니다. 이번에는 그래프에 훨씬 더 낮은 대기 시간이 표시됩니다. 1000명의 사용자에 대한 평균 요청 시간은 5~6초 사이이며, 거의 1분에서 줄어 들었습니다.
이번에는 시스템이 분당 평균 3,970개의 요청을 지원했으며, 이전 테스트의 경우 410개와 비교했습니다.
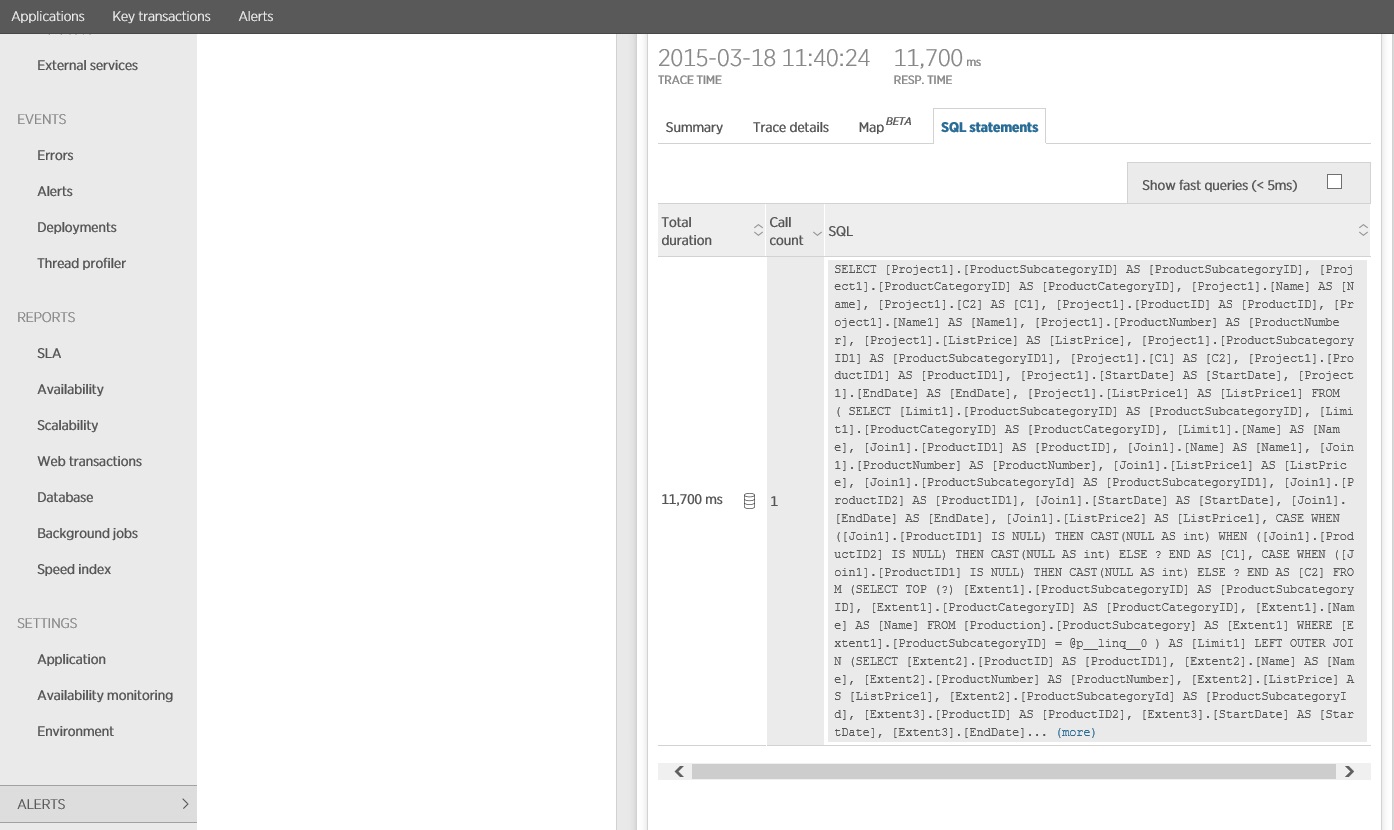
SQL 문을 추적하면 모든 데이터가 단일 SELECT 문에서 페치됨이 표시됩니다. 이 쿼리는 훨씬 더 복잡하지만 작업당 한 번만 수행됩니다. 복잡한 조인은 비용이 많이 들 수 있지만 관계형 데이터베이스 시스템은 이러한 유형의 쿼리에 최적화됩니다.
관련 참고 자료
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기