이미지 분석이란?
Azure AI Vision 이미지 분석 서비스는 이미지에서 다양한 시각적 특징을 추출할 수 있습니다. 예를 들어 이 서비스를 통해 이미지에 성인 콘텐츠가 포함되어 있는지, 특정 브랜드 또는 개체가 있는지, 사람 얼굴이 있는지 확인할 수 있습니다.
현재 일반 공급으로 제공되는 최신 버전의 이미지 분석 4.0에는 동기 OCR 및 인물 감지와 같은 새로운 기능이 있습니다. 앞으로 이 버전을 사용하는 것이 좋습니다.
클라이언트 라이브러리 SDK를 통해 또는 REST API를 직접 호출하여 이미지 분석을 사용할 수 있습니다. 빠른 시작을 따라 시작하세요.
또는 Vision Studio를 사용하여 브라우저에서 빠르고 쉽게 이미지 분석 기능을 사용해 볼 수 있습니다.
이 설명서에는 다음과 같은 유형의 문서가 포함되어 있습니다.
- 빠른 시작은 서비스를 호출하고 짧은 시간 내에 결과를 얻을 수 있는 단계별 지침입니다.
- 방법 가이드에는 보다 구체적이거나 사용자 지정된 방식으로 서비스를 사용하기 위한 지침이 포함되어 있습니다.
- 개념 문서에서는 서비스의 기능 및 기능에 대한 자세한 설명을 제공합니다.
- 자습서는 보다 광범위한 비즈니스 솔루션에서 이 서비스를 구성 요소로 사용하는 방법을 보여주는 긴 가이드입니다.
보다 구조화된 방식을 위해 이미지 분석을 위한 학습 모듈을 따릅니다.
이미지 분석 버전
Important
요구 사항에 가장 적합한 이미지 분석 API 버전을 선택합니다.
| 버전 | 사용 가능한 기능 | 권장 |
|---|---|---|
| version 4.0 | 텍스트 읽기, 캡션, 촘촘한 캡션, 태그, 개체 감지, 사용자 지정 이미지 분류/개체 감지, 사람, 스마트 자르기 | 더 나은 모델; 사용 사례를 지원하는 경우 버전 4.0을 사용합니다. |
| 버전 3.2 | 태그, 개체, 설명, 브랜드, 얼굴, 이미지 형식, 색 구성표, 랜드마크, 유명인사, 성인용 콘텐츠, 스마트 자르기 | 더 넓은 범위의 기능; 사용 사례가 버전 4.0에서 아직 지원되지 않는 경우 버전 3.2를 사용합니다. |
사용 사례를 지원하는 경우 이미지 분석 4.0 API를 사용하는 것이 좋습니다. 사용 사례가 4.0에서 아직 지원되지 않는 경우 버전 3.2를 사용합니다.
이미지 캡션을 작성하고 Vision 리소스가 미국 동부, 프랑스 중부, 한국 중부, 북유럽, 동남 아시아, 서유럽 및 미국 서부, 아시아 태평양과 같은 Azure 지역 외부에 있는 경우에도 버전 3.2를 사용해야 합니다. 이미지 분석 4.0의 이미지 캡션 기능은 이러한 Azure 지역에서만 지원됩니다. 버전 3.2의 이미지 캡션은 모든 Azure AI Vision 지역에서 사용할 수 있습니다.
이미지 분석
이미지를 분석하여 이미지의 시각적 기능 및 특성에 대한 인사이트를 제공할 수 있습니다. 이 목록의 모든 기능은 Analyze Image API에서 제공됩니다. 빠른 시작을 따라 시작하세요.
| 이름 | 설명 | 개념 페이지 |
|---|---|---|
| 모델 사용자 지정(v4.0 미리 보기에만 해당) | 이미지 분류 또는 개체 감지를 수행하도록 사용자 지정 모델을 만들고 학습할 수 있습니다. 자신의 이미지를 가져와서 사용자 지정 태그로 레이블을 지정하면 이미지 분석이 사용 사례에 맞게 사용자 지정된 모델을 학습합니다. | 모델 사용자 지정 |
| 이미지에서 텍스트 읽기(v4.0만 해당) | 이미지 분석의 버전 4.0 미리 보기는 이미지에서 읽을 수 있는 텍스트를 추출하는 기능을 제공합니다. 비동기 Computer Vision 3.2 읽기 API와 비교할 때 새 버전은 성능이 향상된 통합 동기식 API에서 친숙한 읽기 OCR 엔진을 제공하므로 단일 API 호출에서 다른 인사이트와 함께 OCR을 쉽게 가져올 수 있습니다. | 이미지용 OCR |
| 이미지에서 사람 검색(v4.0에만 해당) | 이미지 분석 버전 4.0은 이미지에 나타나는 사람을 검색하는 기능을 제공합니다. 검색된 각 사람의 경계 상자 좌표가 신뢰도 점수와 함께 반환됩니다. | 인물 검색 |
| 이미지 캡션 생성 | 완전한 문장을 사용하여 인간이 읽을 수 있는 언어로 이미지 캡션을 생성합니다. Computer Vision의 알고리즘은 이미지에서 식별된 개체를 기반으로 캡션을 생성합니다. 버전 4.0 이미지 캡션 모델은 고급 구현이며 더 넓은 범위의 입력 이미지에서 작동합니다. 미국 동부, 프랑스 중부, 한국 중부, 북유럽, 동남 아시아, 서유럽, 미국 서부에서만 사용할 수 있습니다. 버전 4.0에서는 또한 이미지에서 발견되는 개별 개체에 대한 자세한 캡션을 생성하는 조밀한 캡션을 사용할 수 있습니다. API는 이미지에서 발견된 각 개체의 경계 상자 좌표(픽셀)와 캡션을 반환합니다. 이 기능을 사용하여 이미지의 개별 파트에 대한 설명을 생성할 수 있습니다. 
|
이미지 캡션 생성(v3.2) (v4.0) |
| 개체 감지 | 개체 검색은 태그 지정과 유사하지만, API는 적용된 각 태그의 경계 상자 좌표를 반환합니다. 예를 들어, 이미지에 개, 고양이, 사람이 포함된 경우 감지 작업은 해당 개체를 이미지의 좌표와 함께 나열합니다. 이 기능을 사용하여 이미지의 개체 간 관계를 추가로 처리할 수 있습니다. 또한 이 기능을 통해 이미지에 동일한 태그의 여러 인스턴스가 있는 경우 이를 알 수 있습니다. 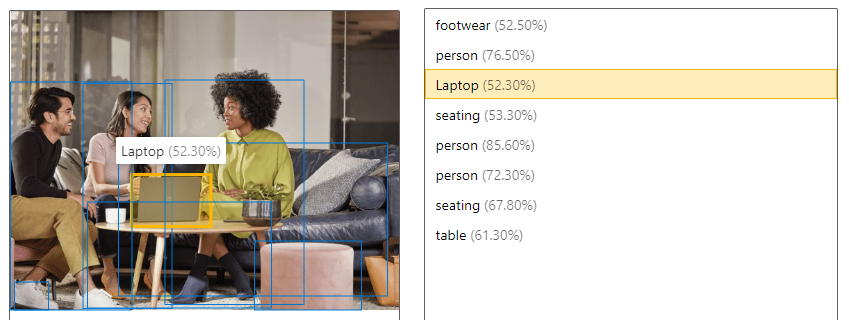
|
개체 감지(v3.2) (v4.0) |
| 시각적 기능 태그 지정 | 수천 개의 인식 가능한 사물, 생물, 풍경 및 동작 세트를 기반으로 하여 이미지의 시각적 기능을 식별하고 태그를 지정합니다. 태그가 모호하거나 누구나 알 수 있는 것이 아닌 경우 API 응답은 태그의 컨텍스트를 명확히 설명하는 ‘힌트’를 제공합니다. 태그 지정은 주요 대상(예: 전경에 있는 인물)으로 제한되지 않으며 설정(실내 또는 옥외), 가구, 도구, 식물, 동물, 액세서리, 장치 등도 포함합니다.
|
태그 시각적 기능(v3.2) (v4.0) |
| 관심 영역 가져오기/스마트 자르기 | 이미지의 내용을 분석하여 지정된 가로 세로 비율과 일치하는 관심 영역의 좌표를 반환합니다. Computer Vision은 영역의 경계 상자 좌표를 반환하므로 호출 애플리케이션이 원하는 대로 원본 이미지를 수정할 수 있습니다. 버전 4.0 스마트 자르기 모델은 더 발전된 구현이며 더 넓은 범위의 입력 이미지와 함께 작동합니다. 미국 동부, 프랑스 중부, 한국 중부, 북유럽, 동남 아시아, 서유럽, 미국 서부에서만 사용할 수 있습니다. |
썸네일 생성(v3.2) (v4.0 미리 보기) |
| 브랜드 감지(v3.2만 해당) | 수천 개의 글로벌 로고 데이터베이스에서 이미지 또는 비디오에 있는 상업용 브랜드를 식별합니다. 예를 들어 이 기능을 사용하여 소셜 미디어에서 가장 인기 있거나 미디어 제품 배치에서 가장 일반적인 브랜드를 검색할 수 있습니다. | 브랜드 감지 |
| 이미지 분류(v3.2만 해당) | 부모/자식 유전적 계층 구조가 있는 범주 분류를 사용하여 전체 이미지를 식별하고 분류합니다. 범주는 단독으로 사용하거나 새 태그 지정 모델을 통해 사용할 수 있습니다. 현재 영어는 이미지에 대한 태그 지정 및 분류에 지원되는 유일한 언어입니다. |
이미지 분류 |
| 얼굴 감지(v3.2만 해당) | 이미지에서 얼굴을 감지하고, 감지된 얼굴 각각에 대한 정보를 제공합니다. Azure AI Vision은 감지된 각 얼굴의 좌표, 직사각형, 성별 및 나이를 반환합니다. 이러한 용도로 전용 Face API를 사용할 수도 있습니다. 얼굴 식별 및 포즈 검색과 같은 보다 자세한 분석을 제공합니다. |
얼굴 감지 |
| 이미지 유형 감지(v3.2만 해당) | 이미지가 선 그리기인지, 아니면 이미지가 클립 아트인지 여부와 같은 이미지에 대한 특성을 감지합니다. | 이미지 유형 감지 |
| 도메인별 콘텐츠 감지(v3.2만 해당) | 도메인 모델을 사용하여 유명인 및 랜드마크와 같은 이미지의 도메인 관련 콘텐츠를 감지하고 식별합니다. 예를 들어 이미지에 사람이 포함된 경우 Azure AI Vision은 유명인에 대한 도메인 모델을 사용하여 이미지에서 감지된 사람이 알려진 유명인인지 확인할 수 있습니다. | 도메인 특정 콘텐츠 검색 |
| 색 구성표 감지(v3.2만 해당) | 이미지 내의 색 사용을 분석합니다. Azure AI Vision은 이미지가 흑백인지 컬러인지 확인하고, 컬러 이미지의 경우 주요 색상과 강조 색상을 식별할 수 있습니다. | 색 구성표 감지 |
| 이미지 콘텐츠 조정(v3.2만 해당) | Azure AI Vision을 사용하여 이미지에서 성인 콘텐츠를 감지하고 다양한 분류에 대한 신뢰도 점수를 반환할 수 있습니다. 콘텐츠 플래그 지정 임계값은 기본 설정에 맞게 슬라이딩 배율로 설정할 수 있습니다. | 성인 콘텐츠 검색 |
팁
Azure OpenAI Service를 통해 이미지 분석의 읽기 텍스트 및 개체 검색 기능을 사용할 수 있습니다. GPT-4 Turbo with Vision 모델을 사용하면 공유하는 이미지를 분석할 수 있는 AI 도우미와 채팅할 수 있으며, 비전 향상 옵션은 이미지 분석을 사용하여 AI 지원에 이미지에 대한 자세한 세부 정보(읽기 가능한 텍스트 및 개체 위치)를 제공합니다. 자세한 내용은 GPT-4 Turbo with Vision 빠른 시작을 참조하세요.
제품 인식(v4.0 미리 보기에만 해당)
제품 인식 API를 사용하면 소매점의 선반 사진을 분석할 수 있습니다. 제품의 유무를 감지하고 경계 상자 좌표를 얻을 수 있습니다. 모델 사용자 지정과 함께 사용하여 특정 제품을 식별하도록 모델을 학습합니다. 제품 인식 결과를 매장의 플래노그램 문서와 비교할 수도 있습니다.
다중 모달 포함(v4.0에만 해당)
다중 모달 포함 API를 사용하면 이미지 및 텍스트 쿼리를 벡터화할 수 있습니다. 이미지를 다차원 벡터 공간의 좌표로 변환합니다. 그런 다음 들어오는 텍스트 쿼리도 벡터로 변환할 수 있으며 의미 체계 근접성을 기반으로 이미지를 텍스트와 일치시킬 수 있습니다. 이를 통해 사용자는 이미지 태그나 기타 메타데이터를 사용할 필요 없이 텍스트를 사용하여 이미지 집합을 검색할 수 있습니다. 의미 체계 근접성은 검색에서 더 나은 결과를 생성하기도 합니다.
2024-02-01 API에는 102개 언어로 텍스트 검색을 지원하는 다국어 모델이 포함되어 있습니다. 원래의 영어 전용 모델도 여전히 사용할 수 있지만 동일한 검색 인덱스의 새 모델과 결합할 수는 없습니다. 영어 전용 모델을 사용하여 텍스트 및 이미지를 벡터화한 경우 이러한 벡터는 다국어 텍스트 및 이미지 벡터와 호환되지 않습니다.
이러한 API는 미국 동부, 프랑스 중부, 한국 중부, 북유럽, 동남 아시아, 서유럽, 미국 서부 지역에서만 사용할 수 있습니다.
백그라운드 제거(v4.0 미리 보기만 해당)
이미지 분석 4.0(미리 보기)은 이미지의 백그라운드를 제거하는 기능을 제공합니다. 이 기능은 투명한 백그라운드를 가진 검색된 포그라운드 개체의 이미지를 출력하거나 검색된 포그라운드 개체의 불투명도를 보여 주는 회색조 알파 매트 이미지를 출력할 수 있습니다.
| 원본 이미지 | 백그라운드를 제거한 상태에서 | 알파 매트 |
|---|---|---|

|

|

|
이미지 요구 사항
이미지 분석은 다음 요구 사항을 충족하는 이미지에서 작동합니다.
- 이미지는 JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF 또는 MPO 형식으로 표시해야 합니다.
- 이미지의 파일 크기가 20MB보다 작아야 합니다.
- 이미지의 크기가 50x50픽셀보다 크고 16,000x16,000픽셀보다 작아야 합니다.
팁
다중 모달 포함에 대한 입력 요구 사항은 다르며 다중 모달 포함에 나열되어 있습니다.
데이터 개인 정보 보호 및 보안
모든 Azure AI 서비스와 마찬가지로 Azure AI Vision 서비스를 사용하는 개발자는 고객 데이터에 대한 Microsoft의 정책을 알고 있어야 합니다. 자세한 내용은 Microsoft 보안 센터의 Azure AI 서비스 페이지를 참조하세요.
다음 단계
선호하는 개발 언어로 된 빠른 시작 가이드에 따라 이미지 분석을 시작하세요.