성능을 위해 Azure Data Lake Storage Gen1 조정
Data Lake Storage Gen1은 I/O 집약적 분석 및 데이터 이동에 대해 높은 처리량을 지원합니다. Data Lake Storage Gen1에서는 사용 가능한 모든 처리량(초당 읽거나 쓸 수 있는 데이터 양)을 이용하여 최상의 성능을 얻는 것이 중요합니다. 이를 위해 최대한 많은 읽기와 쓰기를 병렬로 수행합니다.
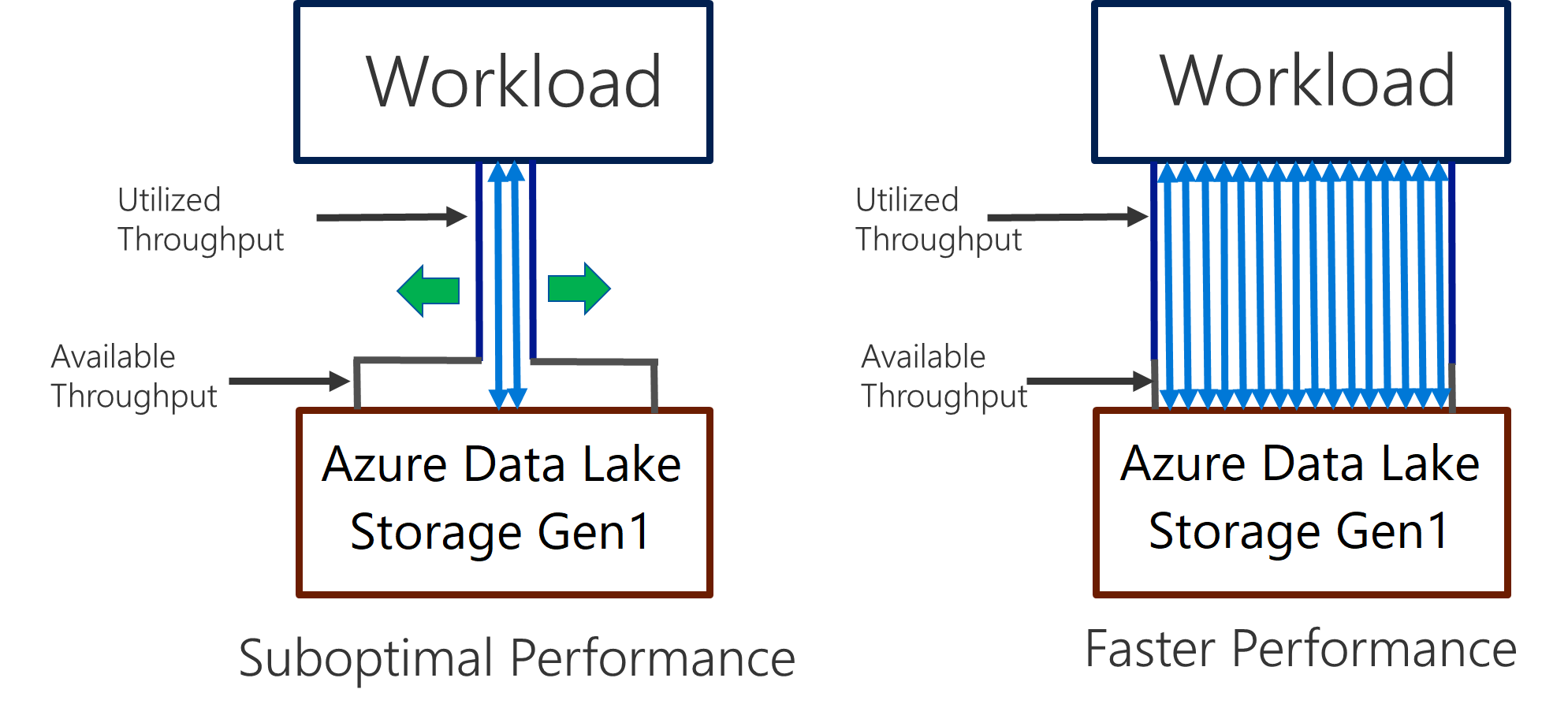
Data Lake Storage Gen1은 모든 분석 시나리오에 필요한 처리량을 제공하도록 크기가 조정될 수 있습니다. 기본적으로 Data Lake Storage Gen1 계정은 다양한 사용 사례 범주의 요구를 충족하기에 충분한 처리량을 자동으로 제공합니다. 고객이 기본 제한에 걸리는 경우 Microsoft 지원에 문의하여 더 많은 처리량을 제공하도록 Data Lake Storage Gen1 계정을 구성할 수 있습니다.
데이터 수집
원본 시스템의 데이터를 Data Lake Storage Gen1에 수집하는 경우 원본 하드웨어, 원본 네트워크 하드웨어 및 Data Lake Storage Gen1에 대한 네트워크 연결에서 병목 상태가 발생할 수 있다는 점을 고려해야 합니다.
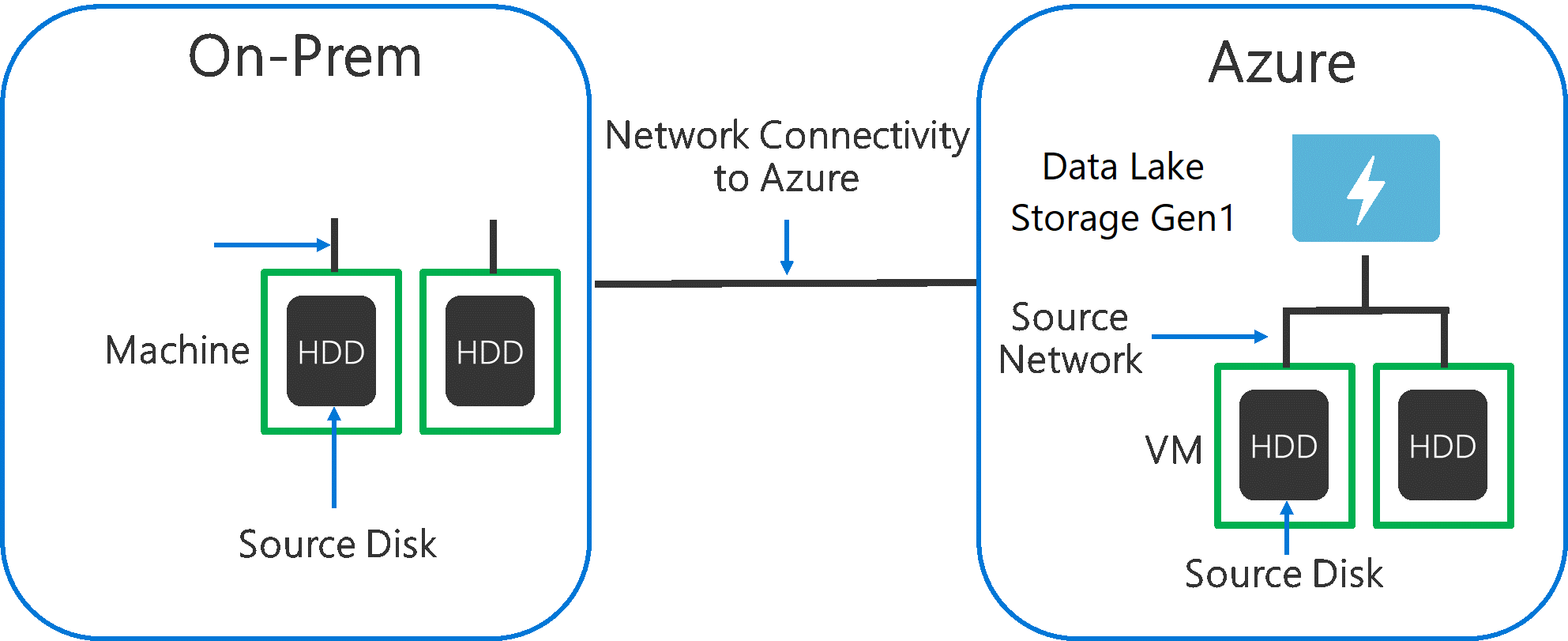
데이터 이동이 이러한 요인에 의해 영향을 받지 않도록 하는 것이 중요합니다.
원본 하드웨어
Azure의 VM 또는 온-프레미스 머신을 사용하는 경우 적절한 하드웨어를 신중하게 선택해야 합니다. 원본 디스크 하드웨어의 경우 HDD보다 SSD를 사용하고, 스핀들이 더 빠른 디스크 하드웨어를 선택합니다. 원본 네트워크 하드웨어의 경우 가능한 가장 빠른 NIC를 사용합니다. Azure에서는 강력한 디스크 및 네트워킹 하드웨어를 갖춘 Azure D14 VM을 사용하는 것이 좋습니다.
Data Lake Storage Gen1에 대한 네트워크 연결
원본 데이터와 Data Lake Storage Gen1 간의 네트워크 연결에서 병목 상태가 발생하는 경우도 있습니다. 원본 데이터가 온-프레미스인 경우 Azure ExpressRoute와 함께 전용 링크를 사용하는 것이 좋습니다. 원본 데이터가 Azure에 있는 경우 데이터가 Data Lake Storage Gen1 계정과 동일한 Azure 지역에 있을 때 성능이 가장 좋습니다.
최대 병렬 처리를 위한 데이터 수집 도구 구성
원본 하드웨어 및 네트워크 연결 병목 현상을 해결했으면 수집 도구를 구성할 준비가 된 것입니다. 다음 표에는 몇 가지 일반적인 수집 도구에 대한 주요 설정이 요약되어 있으며, 각 도구에 대한 심층 분석 성능 튜닝 문서가 제공됩니다. 시나리오에 사용할 도구에 대한 자세한 내용은 이 문서를 참조하세요.
| 도구 | 설정 | 자세한 정보 |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | 링크 |
| AdlCopy | Azure Data Lake Analytics 단위 | 링크 |
| DistCp | -m(mapper) | 링크 |
| Azure Data Factory | parallelCopies | 링크 |
| Sqoop | fs.azure.block.size, -m(mapper) | 링크 |
데이터 집합 구성
데이터가 Data Lake Storage Gen1에 저장되면 파일 크기, 파일 수 및 폴더 구조가 성능에 영향을 미칩니다. 다음 섹션에서는 이러한 영역의 모범 사례에 대해 설명합니다.
파일 크기
일반적으로 HDInsight, Azure Data Lake Analytics 등의 분석 엔진에서는 파일당 오버헤드가 발생합니다. 데이터를 많은 작은 파일로 저장하는 경우 성능이 저하될 수 있습니다.
일반적으로 성능을 향상하려면 데이터를 더 큰 파일로 구성합니다. 일반적으로 데이터 세트를 256MB 이상의 파일로 구성합니다. 이미지, 이진 데이터 등과 같이 병렬로 처리할 수 없는 경우도 있습니다. 이러한 경우 개별 파일을 2GB 미만으로 유지하는 것이 좋습니다.
때로는 다수의 작은 파일로 이루어진 원시 데이터에 대한 데이터 파이프라인의 제어가 제한됩니다. 다운스트림 애플리케이션에 사용할 더 큰 파일을 생성하는 "처리" 프로세스를 포함하는 것이 좋습니다.
폴더에 시계열 데이터 구성
Hive 및 ADLA 워크로드의 경우 시계열 데이터의 파티션 정리를 통해 일부 쿼리에서 데이터의 하위 집합만 읽도록 지원하여 성능을 개선할 수 있습니다.
시계열 데이터를 수집하는 이러한 파이프라인은 파일 및 폴더에 대해 구조적 명명을 사용하여 파일을 배치하는 경우가 많습니다. \DataSet\YYYY\MM\DD\datafile_YYYY_MM_DD.tsv는 날짜별로 구조화된 데이터의 일반적인 예입니다.
datetime 정보가 폴더 및 파일 이름 둘 다에 나타납니다.
날짜 및 시간에 대한 일반적인 패턴은 \DataSet\YYYY\MM\DD\HH\mm\datafile_YYYY_MM_DD_HH_mm.tsv입니다.
앞에서 설명했듯이, 더 큰 파일 크기와 각 폴더에 포함된 적절한 파일 수의 요건에 맞는 폴더 및 파일 구성을 선택해야 합니다.
HDInsight의 Hadoop 및 Spark 워크로드에 대한 I/O 집약적 작업 최적화
작업은 다음 세 가지 범주 중 하나에 속합니다.
- CPU 집약적. 이러한 작업은 최소한의 I/O 시간으로 계산 시간이 깁니다. 기계 학습 및 자연어 처리 작업을 예로 들 수 있습니다.
- 메모리 집약적. 이러한 작업은 메모리를 많이 사용합니다. PageRank 및 실시간 분석 작업을 예로 들 수 있습니다.
- I/O 집약적. 이러한 작업은 I/O를 수행하는 데 대부분의 시간을 사용합니다. 일반적인 예로는 읽기 및 쓰기 작업만 수행하는 복사 작업이 있습니다. 다른 예로는 수많은 데이터를 읽고 일부 데이터 변환을 수행한 다음, 데이터를 저장소에 다시 쓰는 데이터 준비 작업이 있습니다.
다음 지침은 I/O 집약적 작업에만 적용됩니다.
HDInsight 클러스터에 대한 일반적인 고려 사항
- HDInsight 버전. 최상의 성능을 얻으려면 HDInsight의 최신 릴리스를 사용합니다.
- 지역. HDInsight 클러스터와 동일한 지역에 Data Lake Storage Gen1 계정을 배치합니다.
HDInsight 클러스터는 헤드 노드 두 개와 일부 작업자 노드로 구성됩니다. 각 작업자 노드는 VM 유형에 의해 결정되는 특정 개수의 코어와 메모리를 제공합니다. 작업을 실행할 때 YARN은 사용 가능한 메모리와 코어를 할당하여 컨테이너를 만드는 리소스 협상자입니다. 각 컨테이너는 작업을 완료하는 데 필요한 태스크를 실행합니다. 태스크를 신속하게 처리하기 위해 컨테이너가 병렬로 실행됩니다. 따라서 최대한 많은 병렬 컨테이너를 실행하여 성능을 향상합니다.
HDInsight 클러스터 내에 있는 3개의 계층을 튜닝하여 컨테이너 수를 늘리고 사용 가능한 모든 처리량을 이용할 수 있습니다.
- 물리적 계층
- YARN 계층
- 워크로드 계층
물리적 계층
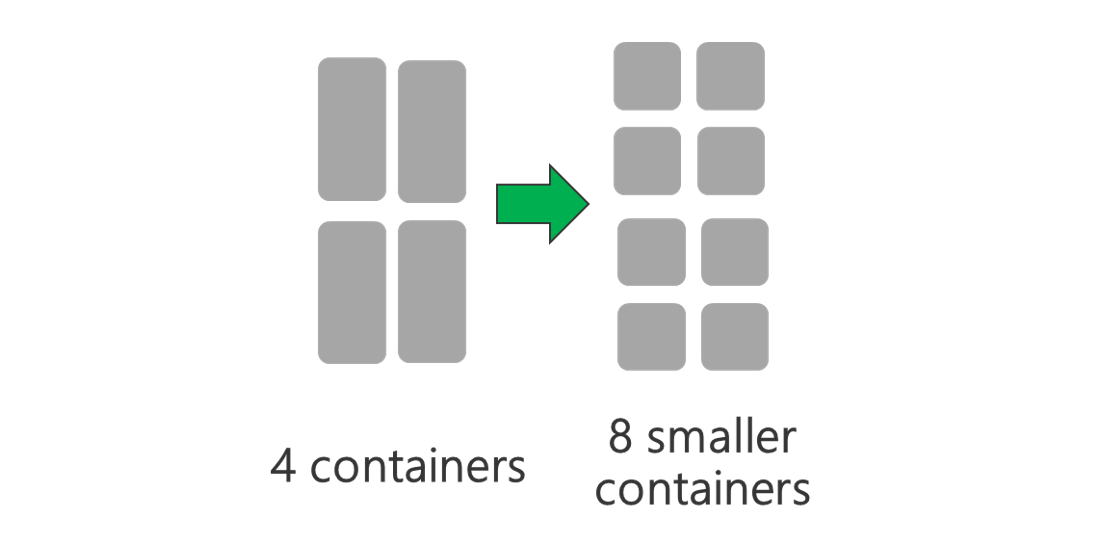
더 많은 노드 및/또는 더 큰 VM으로 클러스터를 실행합니다. 더 큰 클러스터를 사용하면 아래 그림과 같이 더 많은 YARN 컨테이너를 실행할 수 있습니다.

더 많은 네트워크 대역폭을 가진 VM을 사용합니다. 네트워크 대역폭이 Data Lake Storage Gen1 처리량보다 작을 경우 네트워크 대역폭 크기로 인해 병목 상태가 발생할 수 있습니다. VM마다 각기 다른 네트워크 대역폭 크기를 갖게 됩니다. 가능한 가장 큰 네트워크 대역폭을 가진 VM 유형을 선택합니다.
YARN 계층
더 작은 YARN 컨테이너를 사용합니다. 각 YARN 컨테이너의 크기를 줄여 동일한 리소스 양으로 더 많은 컨테이너를 만듭니다.
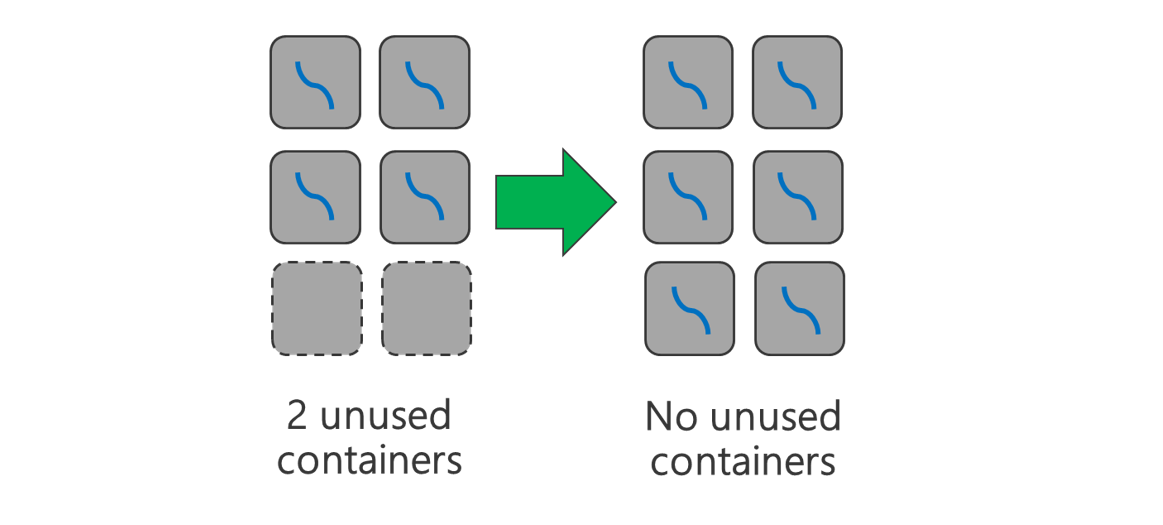
워크로드에 따라 항상 필요한 최소 YARN 컨테이너 크기가 있습니다. 너무 작은 컨테이너를 선택하면 작업에서 메모리 부족 문제가 발생합니다. 일반적으로 YARN 컨테이너는 1GB 이상이어야 합니다. 3GB YARN 컨테이너도 흔히 볼 수 있습니다. 일부 워크로드의 경우 더 큰 YARN 컨테이너가 필요할 수도 있습니다.
YARN 컨테이너당 코어 수를 늘립니다. 각 컨테이너에 할당된 코어 수를 늘려 각 컨테이너에서 실행되는 병렬 태스크 수를 늘립니다. 이는 컨테이너당 여러 태스크를 실행하는 Spark와 같은 애플리케이션에 적합합니다. 각 컨테이너에서 단일 스레드를 실행하는 Hive와 같은 애플리케이션에서는 컨테이너당 코어 수보다 컨테이너 수를 늘리는 것이 좋습니다.
워크로드 계층
사용 가능한 모든 컨테이너를 이용합니다. 모든 리소스가 사용되도록 태스크 수를 사용 가능한 컨테이너 수보다 크거나 같도록 설정합니다.
실패한 태스크는 비용이 많이 듭니다. 각 태스크에서 많은 양의 데이터를 처리하는 경우 태스크 실패 시 다시 시도하는 데 많은 비용이 듭니다. 따라서 각각 적은 양의 데이터를 처리하는 태스크를 더 많이 만드는 것이 좋습니다.
위의 일반적인 지침 외에도 각 애플리케이션마다 특정 애플리케이션에 대해 튜닝할 수 있는 다른 매개 변수가 있습니다. 아래 표에는 각 애플리케이션에 대한 성능 튜닝을 시작하기 위한 몇 가지 매개 변수 및 링크가 나와 있습니다.
| 작업 | 작업을 설정하는 매개 변수 |
|---|---|
| HDInsight의 Spark |
|
| HDInsight의 Hive |
|
| HDInsight의 MapReduce |
|
| HDInsight의 Storm |
|