이 문서에서는 Azure Databricks 클러스터 또는 Azure Databricks SQL 웨어하우스와 함께 Spotfire Analyst를 사용하는 방법을 설명합니다.
요구 사항
Azure Databricks 작업 영역의 클러스터 또는 SQL 웨어하우스
클러스터 또는 SQL 웨어하우스, 특히 서버 호스트 이름, 포트및 HTTP 경로 값에 대한 연결 세부 정보입니다.
- Azure Databricks 컴퓨팅 리소스대한 연결 세부 정보를 가져옵니다.
Azure Databricks 개인용 액세스 토큰 또는 Microsoft Entra ID(이전 Azure Active Directory) 토큰. 개인 액세스 토큰을 만들려면 작업 영역 사용자를 위한 Azure Databricks 개인용 액세스 토큰의 단계를 따릅니다.
참고 항목
보안 모범 사례로, 자동화된 도구, 시스템, 스크립트, 앱을 사용하여 인증할 때 Databricks는 작업 영역 사용자 대신 서비스 주체에 속한 개인용 액세스 토큰을 사용하는 것을 권장합니다. 서비스 주체에 대한 토큰을 만들려면 서비스 주체에 대한 토큰 관리를 참조하세요.
연결 단계
- Spotfire Analyst의 탐색 모음에서 더하기(파일 및 데이터) 아이콘을 클릭하고 연결 대상을 클릭합니다.
- Databricks을 선택한 후 새 연결을 클릭합니다.
Apache Spark SQL 대화 상자의일반 탭에서Server 서버 호스트 이름 입력하고 1단계의 포트 필드 값을 콜론으로 구분하여. - 인증 방법을 위해 사용자 이름 및 암호을 선택합니다.
-
사용자 이름에
token단어를 입력합니다. - 암호에 1단계의 개인용 액세스 토큰을 입력합니다.
- 고급 탭에서 Thrift 전송 모드에 대해 HTTP를 선택합니다.
- HTTP 경로에 1단계의 HTTP 경로 필드 값을 입력합니다.
- 일반 탭에서 연결을 클릭합니다.
- 연결이 성공하면 데이터베이스 목록에서 사용할 데이터베이스를 선택한 다음 확인클릭합니다.
분석할 Azure Databricks 데이터 선택
연결 대화 상자의
사용 가능한 테이블
- Azure Databricks에서 사용 가능한 테이블을 찾습니다.
- 뷰로 원하는 테이블을 추가합니다. 이 테이블은 Spotfire에서 분석하는 데이터 테이블입니다.
- 각 보기에 대해 포함할 열을 결정할 수 있습니다. 매우 구체적이고 유연한 데이터 선택 항목을 만들려는 경우 이 대화 상자에서 다음과 같은 강력한 도구 범위에 액세스할 수 있습니다.
- 사용자 지정 쿼리. 사용자 지정 쿼리를 사용하면 사용자 지정 SQL 쿼리를 입력하여 분석할 데이터를 선택할 수 있습니다.
- 프롬프트 표시. 데이터 선택은 분석 파일의 사용자에게 맡기세요. 선택한 열을 기반으로 프롬프트를 구성합니다. 그런 다음 분석을 여는 최종 사용자가 관련 값에 대해서만 데이터를 제한하고 볼 수 있도록 선택할 수 있습니다. 예를 들어 사용자는 특정 시간 범위 내 또는 특정 지역에 대한 데이터를 선택할 수 있습니다.
- 확인을 클릭합니다.
Azure Databricks에 대한 푸시다운 쿼리 또는 데이터 가져오기
분석할 데이터를 선택했으면 마지막 단계는 Azure Databricks에서 데이터를 검색할 방법을 선택하는 것입니다. 분석에 추가하는 데이터 테이블의 요약이 표시되며 각 테이블을 클릭하여 데이터 로드 방법을 변경할 수 있습니다.
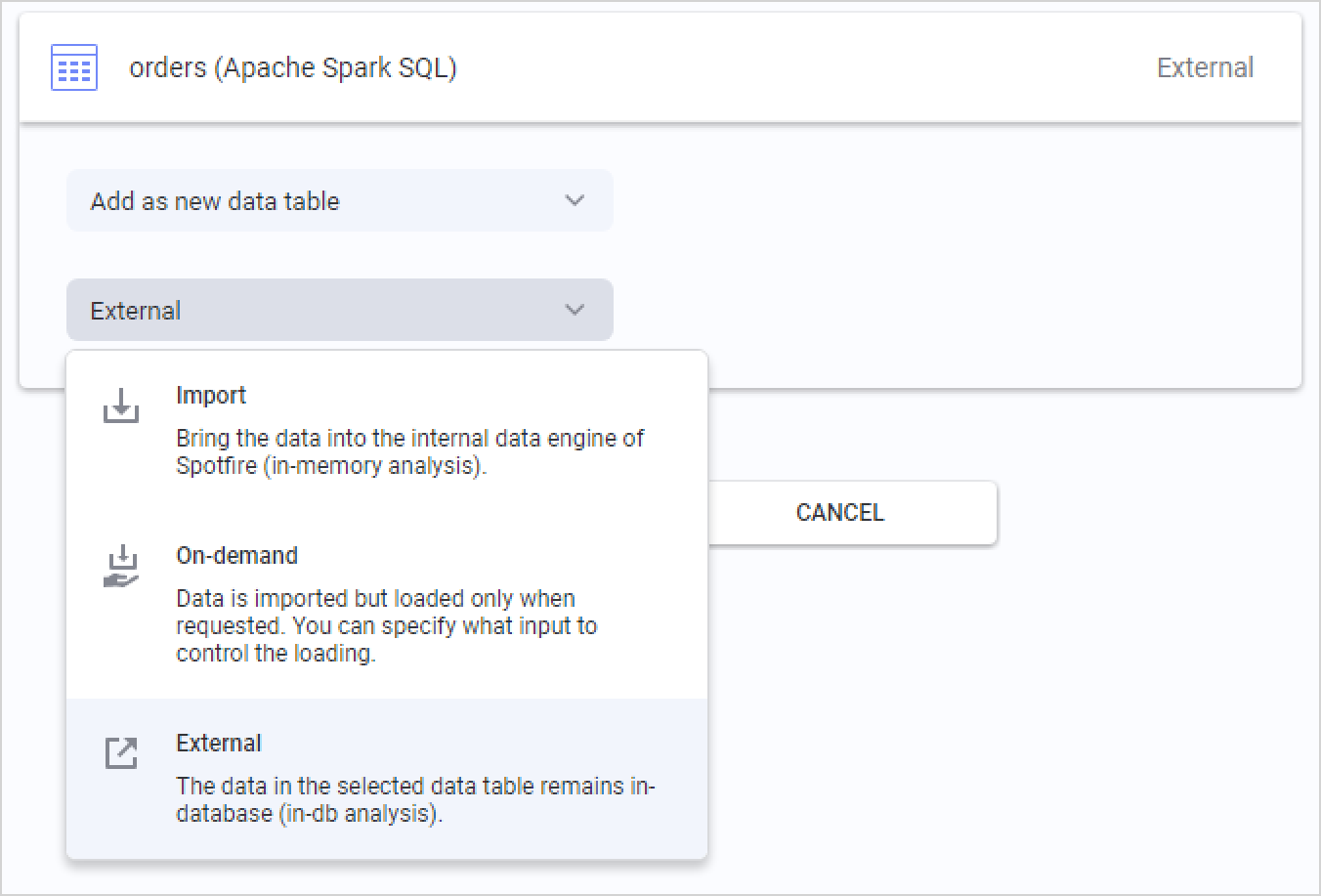
Azure Databricks의 기본 옵션은 외부입니다. 즉, 데이터 테이블은 Azure Databricks의 데이터베이스에 유지되고 Spotfire는 분석의 작업에 따라 관련 데이터 조각에 대해 데이터베이스에 다른 쿼리를 푸시합니다.
가져온을 선택할 수도 있으며, Spotfire는 전체 데이터 테이블을 처음부터 추출하여 로컬 메모리에서의 분석을 가능하게 합니다. 데이터 테이블을 가져올 때 TIBCO Spotfire의 포함된 메모리 내 데이터 엔진에서도 분석 함수를 사용합니다.
세 번째 옵션은 주문형(동적 WHERE 절에 해당)입니다. 즉, 분석에서 사용자 작업을 기반으로 데이터 조각이 추출됩니다. 데이터 표시 또는 필터링, 문서 속성 변경과 같은 작업이 될 수 있는 기준을 정의할 수 있습니다. 주문형 데이터 로드를 외부 데이터 테이블과 결합할 수도 있습니다.