Azure Databricks 워크플로 소개
Azure Databricks 워크플로는 Databricks Data Intelligence Platform에서 데이터 처리, 기계 학습 및 분석 파이프라인을 오케스트레이션합니다. 워크플로에는 Azure Databricks 작업 영역에서 비대화형 코드를 실행하는 Azure Databricks 작업 및 델타 라이브 테이블을 포함하여 Databricks 플랫폼과 통합된 완전히 관리되는 오케스트레이션 서비스를 통해 안정적이고 기본 달성 가능한 ETL 파이프라인을 빌드합니다.
Databricks 플랫폼을 사용하여 워크플로를 오케스트레이션하는 이점에 대해 자세히 알아보려면 Databricks 워크플로를 참조 하세요.
Azure Databricks 워크플로 예제
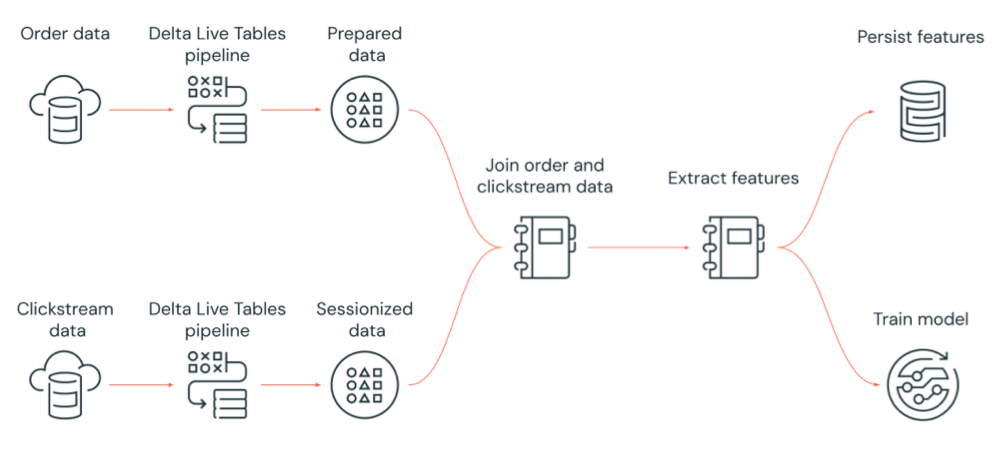
다음 다이어그램은 Azure Databricks 작업에서 다음과 같이 오케스트레이션되는 워크플로를 보여 줍니다.
- 클라우드 스토리지에서 원시 클릭스트림 데이터를 수집하고, 데이터를 클린 및 준비하고, 데이터를 세션화하고, 최종 세션화된 데이터 집합을 Delta Lake로 유지하는 Delta Live Tables 파이프라인을 실행합니다.
- 클라우드 스토리지에서 주문 데이터를 수집하고, 처리할 데이터를 클린 변환하고, 최종 데이터 집합을 Delta Lake로 유지하는 Delta Live Tables 파이프라인을 실행합니다.
- 주문 및 세션화된 클릭스트림 데이터를 조인하여 분석을 위한 새 데이터 집합을 만듭니다.
- 준비된 데이터에서 기능을 추출합니다.
- 병렬로 작업을 수행하여 기능을 유지하며 기계 학습 모델을 학습시킵니다.
Azure Databricks 작업란?
Azure Databricks 작업은 Azure Databricks 작업 영역에서 데이터 처리 및 분석 애플리케이션을 실행하는 방법입니다. 작업은 단일 태스크로 구성되거나 복잡한 종속성이 있는 대규모 다중 태스크 워크플로로 구성될 수 있습니다. Azure Databricks는 모든 작업에 대한 작업 오케스트레이션, 클러스터 관리, 모니터링 및 오류 보고를 관리합니다. 새 파일이 외부 위치에 도착할 때마다 사용하기 쉬운 일정 시스템을 통해 정기적으로 작업을 즉시 실행하거나 작업 인스턴스가 항상 실행되도록 지속적으로 수행할 수 있습니다. 또한 Notebook UI에서 작업을 대화형으로 실행할 수 있습니다.
작업 UI, Databricks CLI를 사용하거나 작업 API를 호출하여 작업을 만들고 실행할 수 있습니다. UI 또는 API를 사용하여 실패하거나 취소된 작업을 복구하고 다시 실행할 수 있습니다. UI, CLI, API 및 알림(예: 이메일, 웹후크 대상 또는 Slack 알림)을 사용하여 작업 실행 결과를 모니터링할 수 있습니다.
Databricks CLI 사용에 대한 자세한 내용은 Databricks CLI란?을 참조하세요. 작업 API 사용에 대한 자세한 내용은 작업 API를 참조하세요.
다음 섹션에서는 Azure Databricks Jobs의 중요한 기능에 대해 설명합니다.
Important
- 작업 영역은 1000개의 동시 작업 실행으로 제한됩니다. 즉시 시작할 수 없는 실행을 요청하면
429 Too Many Requests응답이 반환됩니다. - 작업 영역에서 한 시간 내에 만들 수 있는 작업 수는 10000개로 제한됩니다("실행 제출" 포함). 이 제한은 REST API 및 Notebook 워크플로에 의해 만들어진 작업에도 영향을 줍니다.
작업 태스크를 사용하여 데이터 처리 및 분석 구현
작업을 사용하여 데이터 처리 및 분석 워크플로를 구현합니다. 작업은 하나 이상의 작업으로 구성됩니다. Notebook, JARS, Delta Live Tables 파이프라인 또는 Python, Scala, Spark 제출 및 Java 애플리케이션을 실행하는 작업 작업을 만들 수 있습니다. 작업 태스크는 Databricks SQL 쿼리, 경고 및 대시보드를 오케스트레이션하여 분석 및 시각화를 만들 수도 있고, dbt 작업을 사용하여 워크플로에서 dbt 변환을 실행할 수도 있습니다. 레거시 Spark 제출 애플리케이션도 지원됩니다.
다른 작업을 실행하는 작업에 작업을 추가할 수도 있습니다. 이 기능을 사용하면 큰 프로세스를 여러 개의 작은 작업으로 분할하거나 여러 작업에서 다시 사용할 수 있는 일반화된 모듈을 만들 수 있습니다.
태스크 간의 종속성을 지정하여 태스크의 실행 순서를 제어합니다. 태스크를 순서대로 또는 병렬로 실행하도록 구성할 수 있습니다.
작업 트리거를 대화형으로, 지속적으로 또는 사용하여 작업 실행
작업 UI, API 또는 CLI에서 대화형으로 작업을 실행하거나 연속 작업을 실행할 수 있습니다. Amazon S3, Azure Storage 또는 Google Cloud Storage와 같은 외부 위치에 새 파일이 도착하면 작업을 주기적으로 실행하거나 작업을 실행하는 일정을 만들 수 있습니다.
알림을 사용하여 작업 진행률 모니터링
작업 또는 작업이 시작, 완료 또는 실패할 때 알림을 받을 수 있습니다. 하나 이상의 이메일 주소 또는 시스템 대상(예: 웹후크 대상 또는 Slack)에 알림을 보낼 수 있습니다. 작업 이벤트에 대한 이메일 및 시스템 알림 추가를 참조하세요.
Azure Databricks 컴퓨팅 리소스를 사용하여 작업 실행
Databricks 클러스터 및 SQL 웨어하우스는 작업에 대한 계산 리소스를 제공합니다. 작업 클러스터, 다목적 클러스터 또는 SQL 웨어하우스를 사용하여 작업을 실행할 수 있습니다.
- 작업 클러스터는 작업 또는 개별 작업 작업에 대한 전용 클러스터입니다. 작업은 모든 태스크에서 공유하는 작업 클러스터를 사용하거나 작업을 만들거나 편집할 때 개별 작업에 대한 클러스터를 구성할 수 있습니다. 작업 클러스터는 작업 또는 태스크가 시작되고 작업 또는 작업이 종료될 때 종료될 때 만들어집니다.
- 다목적 클러스터는 수동으로 시작 및 종료되며 여러 사용자 및 작업에서 공유할 수 있는 공유 클러스터입니다.
리소스 사용량을 최적화하기 위해 Databricks는 작업에 작업 클러스터를 사용하는 것이 좋습니다. 클러스터 시작 대기 시간을 줄이려면 다목적 클러스터를 사용하는 것이 좋습니다. 작업과 함께 Azure Databricks 컴퓨팅 사용을 참조하세요.
SQL 웨어하우스를 사용하여 쿼리, 대시보드 또는 경고와 같은 Databricks SQL 작업을 실행합니다. SQL 웨어하우스를 사용하여 dbt 작업으로 dbt 변환을 실행할 수도 있습니다.
다음 단계
Azure Databricks 작업을 시작하려면 다음을 수행합니다.
- 빠른 시작을 사용하여 첫 번째 Azure Databricks 작업 워크플로를 만듭니다.
- Azure Databricks 작업 사용자 인터페이스를 사용하여 워크플로를 만들고 실행하는 방법을 알아봅니다.
- Azure Databricks 작업 사용자 인터페이스에서 작업 실행을 모니터링하는 방법을 알아봅니다.
- 작업에 대한 구성 옵션에 대해 알아봅니다.
Azure Databricks 작업을 사용하여 워크플로 빌드, 관리 및 문제 해결에 대해 자세히 알아봅니다.
- 태스크 값을 사용하여 Azure Databricks 작업의 태스크 간에 정보를 전달하는 방법을 알아봅니다.
- 작업 매개 변수 변수를 사용하여 작업 실행에 대한 컨텍스트를 작업 태스크에 전달하는 방법을 알아봅니다.
- 작업 종속성의 상태 따라 조건부로 실행되도록 작업 태스크를 구성하는 방법을 알아봅니다.
- 실패한 작업을 해결하고 수정하는 방법을 알아봅니다.
- 작업 실행 알림으로 작업이 시작, 완료 또는 실패 할 때 알림을 받습니다.
- 사용자 지정 일정에 따라 작업을 트리거하거나 연속 작업을 실행합니다.
- 파일 도착 트리거를 사용하여 새 데이터가 도착할 때 Azure Databricks 작업을 실행하는 방법을 알아봅니다.
- Databricks 컴퓨팅 리소스를 사용하여 작업을 실행하는 방법을 알아봅니다 .
- Azure Databricks 작업으로 워크플로 만들기 및 관리를 지원하기 위한 작업 API 업데이트에 대해 알아봅니다.
- 방법 가이드 및 자습서를 사용하여 Azure Databricks 작업을 사용하여 데이터 워크플로를 구현하는 방법에 대해 자세히 알아보세요.
델타 라이브 테이블이란?
참고 항목
Delta Live Tables에는 프리미엄 플랜이 필요합니다. 자세한 내용은 Databricks 계정 팀에 문의하세요.
Delta Live Tables는 ETL 및 스트리밍 데이터 처리를 간소화하는 프레임워크입니다. Delta Live Tables는 데이터 변환의 선언적 구현을 지원하는 자동 로더, SQL 및 Python 인터페이스를 기본적으로 지원하고 변환된 데이터를 Delta Lake에 쓰기 위한 지원을 통해 효율적인 데이터 수집을 제공합니다. 사용자는 데이터에 대해 수행할 변환을 정의하고, Delta Live Tables는 작업 오케스트레이션, 클러스터 관리, 모니터링, 데이터 품질 및 오류 처리를 관리합니다.
시작하려면 델타 라이브 테이블이란?을 참조하세요.
Azure Databricks 작업 및 델타 라이브 테이블
Azure Databricks 작업 및 델타 라이브 테이블은 엔드 투 엔드 데이터 처리 및 분석 워크플로를 빌드하고 배포하기 위한 포괄적인 프레임워크를 제공합니다.
모든 데이터 수집 및 변환에 델타 라이브 테이블을 사용합니다. Azure Databricks 작업을 사용하여 델타 라이브 테이블 수집 및 변환을 포함하여 Databricks 플랫폼에서 단일 작업 또는 여러 데이터 처리 및 분석 작업으로 구성된 워크로드를 오케스트레이션합니다.
워크플로 오케스트레이션 시스템인 Azure Databricks Jobs도 다음을 지원합니다.
- 트리거된 기준으로 작업 실행(예: 일정에 따라 워크플로 실행).
- SQL 쿼리를 통한 데이터 분석, Notebook, 스크립트 또는 외부 라이브러리 등을 사용한 기계 학습 및 데이터 분석
- 단일 작업으로 구성된 작업 실행(예: JAR에 패키지된 Apache Spark 작업 실행).
Apache AirFlow를 사용하는 워크플로 오케스트레이션
Databricks는 Azure Databricks 작업을 사용하여 데이터 워크플로를 오케스트레이션하는 것이 권장되지만 Apache Airflow를 사용하여 데이터 워크플로를 관리하고 예약할 수도 있습니다. Airflow를 사용하면 Python 파일에서 워크플로를 정의하고 Airflow는 워크플로 예약 및 실행을 관리합니다. Apache Airflow를 사용하여 Azure Databricks 작업 오케스트레이션을 참조하세요.
Azure Data Factory를 사용하는 워크플로 오케스트레이션
ADF(Azure Data Factory) 는 데이터 스토리지, 이동 및 처리 서비스를 자동화된 데이터 파이프라인으로 작성할 수 있는 클라우드 데이터 통합 서비스입니다. ADF를 사용하여 ADF 파이프라인의 일부로 Azure Databricks 작업을 오케스트레이션할 수 있습니다.
ADF에서 Azure Databricks에 인증하는 방법을 포함하여 ADF 웹 작업을 사용하여 작업을 실행하는 방법을 알아보려면 Azure Data Factory에서 Azure Databricks 작업 오케스트레이션 활용을 참조하세요.
또한 ADF는 ADF 파이프라인에서 JAR로 패키지된 Databricks Notebook, Python 스크립트 또는 코드를 실행하는 기본 제공 지원을 제공합니다.
ADF 파이프라인 에서 Databricks Notebook을 실행하는 방법을 알아보려면 Azure Data Factory에서 Databricks Notebook 작업을 사용하여 Databricks Notebook 실행, Databricks Notebook을 실행하여 데이터 변환을 참조하세요.
ADF 파이프라인에서 Python 스크립트를 실행하는 방법을 알아보려면 Azure Databricks에서 Python 작업을 실행하여 데이터 변환을 참조 하세요.
ADF 파이프라인의 JAR에 패키지된 코드를 실행하는 방법을 알아보려면 Azure Databricks에서 Jar 작업을 실행하여 데이터 변환을 참조 하세요.