자습서: HDInsight에서 Apache Kafka의 Apache Spark 구조적 스트림 사용
이 자습서에서는 Azure HDInsight에서 Apache Kafka를 사용하여 Apache Spark Structured Streaming을 통해 데이터를 읽고 쓰는 방법을 보여줍니다.
Spark Structured Streaming은 Spark SQL을 기반으로 하는 스트리밍 처리 엔진입니다. 정적 데이터에 대한 일괄 처리 계산과 동일하게 스트리밍 계산을 표현할 수 있습니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- Azure Resource Manager 템플릿을 사용하여 클러스터 만들기
- Kafka를 통한 Spark Structured Streaming 사용
이 문서의 단계를 완료하는 경우 과도한 요금이 청구되지 않도록 클러스터를 삭제해야 합니다.
필수 조건
간단한 jq 명령줄 JSON 프로세서. https://stedolan.github.io/jq/을(를) 참조하세요.
HDInsight의 Spark에서 Jupyter Notebook을 사용하는 방법 이해. 자세한 내용은 HDInsight의 Apache Spark로 데이터 로드 및 쿼리 실행 문서를 참조하세요.
Scala 프로그래밍 언어 숙지. 이 자습서에 사용되는 코드는 Scala로 작성됩니다.
Kafka 토픽 생성 방법 이해. 자세한 내용은 HDInsight의 Apache Kafka 빠른 시작 문서를 참조하세요.
Important
이 문서의 단계를 수행하려면 HDInsight의 Spark와 HDInsight의 Kafka 클러스터를 모두 포함하는 Azure 리소스 그룹이 필요합니다. 이러한 클러스터는 모두 Azure Virtual Network에 있으며, 여기서는 Spark 클러스터와 Kafka 클러스터 간에 직접 통신할 수 있습니다.
사용자의 편의를 위해, 이 문서는 필요한 모든 Azure 리소스를 만들 수 있는 템플릿에 연결되어 있습니다.
가상 네트워크에서 HDInsight 사용에 대한 자세한 내용은 HDInsight용 가상 네트워크 계획 문서를 참조하세요.
Apache Kafka를 사용하는 구조적 스트림
Spark Structured Streaming은 Spark SQL 엔진에서 작성된 스트림 처리 엔진입니다. 구조적 스트리밍을 사용할 때 일괄 처리 쿼리를 작성하는 경우와 동일한 방식으로 스트리밍 쿼리를 작성할 수 있습니다.
다음 코드 조각은 Kafka에서 읽고 파일에 저장하는 방법을 보여 줍니다. 첫 번째는 일괄 처리 작업이고, 두 번째는 스트리밍 작업입니다.
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
두 조각 모두에서 Kafka에서 데이터를 읽고 파일에 씁니다. 예제의 차이점은 다음과 같습니다.
| Batch | 스트리밍 |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
스트리밍 작업에서도 30,000밀리초 후에 스트림을 중지하는 awaitTermination(30000)을 사용합니다.
Kafka에서 구조적 스트리밍을 사용하려면 프로젝트가 org.apache.spark : spark-sql-kafka-0-10_2.11 패키지에 대해 종속성이 있어야 합니다. 이 패키지의 버전은 HDInsight의 Spark 버전과 일치해야 합니다. Spark 2.4(HDInsight 4.0에서 사용 가능)의 경우, https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar에서 다른 프로젝트 형식에 대한 종속성 정보를 찾을 수 있습니다.
이 자습서에서 사용되는 Jupyter Notebook의 경우 다음 셀에서 이 패키지 종속성을 로드합니다.
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
클러스터 만들기
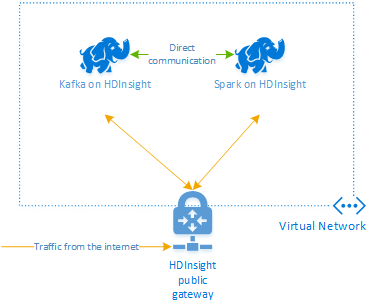
HDInsight의 Apache Kafka는 공용 인터넷을 통한 액세스를 Kafka broker에 제공하지 않습니다. Kafka를 사용하는 경우 동일한 Azure 가상 네트워크에 있어야 합니다. 이 자습서에서는 Kafka 클러스터와 Spark 클러스터가 동일한 Azure 가상 네트워크에 있습니다.
다음 다이어그램은 Spark와 Kafka 사이의 통신 흐름을 보여줍니다.
참고 항목
Kafka 서비스는 가상 네트워크 내에서 통신으로 제한됩니다. SSH 및 Ambari와 같은 클러스터의 다른 서비스는 인터넷을 통해 액세스할 수 있습니다. HDInsight에서 사용할 수 있는 공용 포트에 대한 자세한 내용은 HDInsight에서 사용하는 포트 및 URI를 참조하세요.
Azure Virtual Network를 만든 후 그 안에 Kafka 및 Spark 클러스터를 만들려면 다음 단계를 사용합니다.
Azure에 로그인하고 Azure Portal에서 템플릿을 열려면 다음 단추를 사용합니다.

Azure Resource Manager 템플릿의 위치는 https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json입니다.
이 템플릿은 다음과 같은 리소스를 만듭니다.
HDInsight 4.0 또는 5.0 클러스터의 Kafka
HDInsight 4.0 또는 5.0 클러스터의 Spark 2.4 또는 3.1.
HDInsight 클러스터를 포함하는 Azure Virtual Network
Important
이 자습서에서 사용된 구조적 스트림 Notebook에는 HDInsight 4.0 또는 5.0의 Spark 2.4 또는 3.1가 필요합니다. HDInsight에서 이전 버전의 Spark를 사용하면 Notebook을 사용하는 경우 발생하는 오류가 발생합니다.
다음 정보를 사용하여 사용자 지정된 템플릿 섹션의 항목을 채웁니다.
설정 값 Subscription Azure 구독 Resource group 리소스를 포함하는 리소스 그룹입니다. 위치 리소스가 만들어지는 Azure 지역입니다. Spark 클러스터 이름 Spark 클러스터의 이름입니다. 처음 여섯 자는 Kafka 클러스터 이름과 달라야 합니다. Kafka 클러스터 이름 Kafka 클러스터의 이름입니다. 처음 여섯 자는 Spark 클러스터 이름과 달라야 합니다. 클러스터 로그인 사용자 이름 클러스터의 관리 사용자 이름입니다. 클러스터 로그인 암호 클러스터의 관리 사용자 암호입니다. SSH 사용자 이름 클러스터용으로 만들 SSH 사용자입니다. SSH 암호 SSH 사용자에 대한 암호입니다. 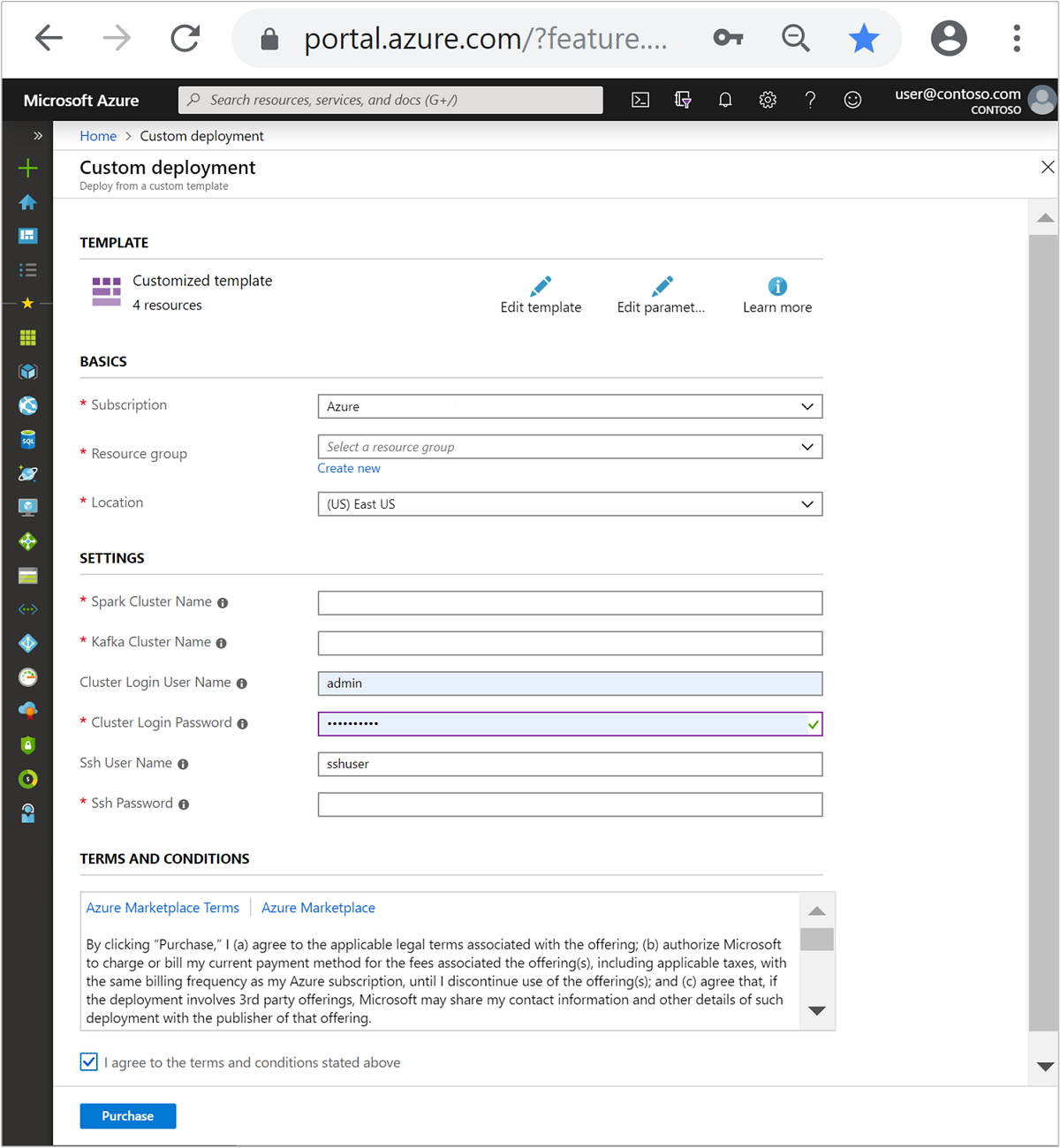
사용 약관을 읽은 다음, 위에 명시된 사용 약관에 동의함을 선택합니다.
구매를 선택합니다.
참고 항목
클러스터를 만드는 데 최대 20분이 걸릴 수 있습니다.
Spark Structured Streaming 사용
다음 예제에서는 Kafka on HDInsight에서 Spark Structured Streaming을 사용하는 방법을 보여 줍니다. 뉴욕시에서 제공하는 택시 여행 데이터를 사용합니다. 이 Notebook에 사용되는 데이터 세트의 출처는 2016 Green Taxi Trip Data(2016 그린 택시 여행 데이터)입니다.
호스트 정보를 수집합니다. 아래의 curl 및 jq 명령을 사용하여 Kafka ZooKeeper 및 broker 호스트 정보를 가져옵니다. 이러한 명령은 Windows 명령 프롬프트에 맞게 설계되었으며, 다른 환경에서는 약간 변경해야 합니다.
KafkaCluster는 Kafka 클러스터의 이름으로 바꾸고,KafkaPassword는 클러스터 로그인 암호로 바꿉니다. 또한C:\HDI\jq-win64.exe도 jq 설치의 실제 경로로 바꿉니다. Windows 명령 프롬프트에서 명령을 입력하고, 이후 단계에서 사용할 수 있도록 출력을 저장합니다.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"웹 브라우저에서
https://CLUSTERNAME.azurehdinsight.net/jupyter로 이동합니다. 여기서CLUSTERNAME은 클러스터의 이름입니다. 메시지가 표시되면 클러스터를 만들 때 사용한 클러스터 로그인(관리자) 이름과 암호를 입력합니다.새로 만들기 > Spark를 선택하여 Notebook을 만듭니다.
Spark 스트리밍에는 마이크로 일괄 처리가 있습니다. 즉, 데이터가 일괄 처리로 제공되고 실행기가 데이터 일괄 처리에서 실행됩니다. 실행기가 일괄 처리를 처리하는 데 걸리는 시간보다 유휴 시간 제한이 적은 경우 실행기는 지속적으로 추가 및 제거됩니다. 실행기 유휴 시간 제한이 일괄 처리 지속 시간 보다 크면 실행기는 제거되지 않습니다. 따라서 스트리밍 애플리케이션을 실행할 때 spark.dynamicAllocation.enabled를 false로 설정하여 동적 할당을 비활성화하는 것이 좋습니다.
Notebook 셀에 다음 정보를 입력하여 Notebook에서 사용하는 패키지를 로드합니다. Ctrl + Enter를 사용하여 명령을 실행합니다.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Kafka 항목을 만듭니다. 아래 명령을 편집하여
YOUR_ZOOKEEPER_HOSTS를 첫 번째 단계에서 추출한 Zookeeper 호스트 정보로 바꿉니다. Jupyter Notebook에서 편집된 명령을 입력하여tripdata항목을 만듭니다.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepers택시 여행에 대한 데이터를 검색합니다. 뉴욕시 택시 여행에 대한 데이터를 로드하는 명령을 다음 셀에 입력합니다. 데이터가 데이터 프레임에 로드된 다음, 데이터 프레임이 셀 출력으로 표시됩니다.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Kafka broker 호스트 정보를 설정합니다.
YOUR_KAFKA_BROKER_HOSTS를 1단계에서 추출한 broker 호스트 정보로 바꿉니다. 편집된 명령을 다음 Jupyter Notebook 셀에 입력합니다.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")데이터를 Kafka에 보냅니다. 다음 명령에서
vendorid필드는 Kafka 메시지에 대한 키 값으로 사용됩니다. 이 키는 데이터를 분할할 때 Kafka에서 사용됩니다. 모든 필드가 JSON 문자열 값으로 Kafka 메시지에 저장됩니다. Jupyter에서 다음 명령을 입력하여 일괄 처리 쿼리를 통해 데이터를 Kafka에 저장합니다.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")스키마를 선언합니다. 다음 명령에서는 Kafka에서 JSON 데이터를 읽을 때 스키마를 사용하는 방법을 보여 줍니다. 이 명령을 다음 Jupyter 셀에 입력합니다.
// Import bits useed for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")데이터를 선택하고 스트리밍을 시작합니다. 다음 명령에서는 일괄 처리 쿼리를 사용하여 Kafka에서 데이터를 검색하는 방법을 보여줍니다. 그런 다음, 결과를 Spark 클러스터의 HDFS에 기록합니다. 이 예제에서는
select가 Kafka에서 메시지(value 필드)를 검색하고 스키마를 적용합니다. 그런 다음, 데이터를 Parquet 형식으로 HDFS(WASB 또는 ADL)에 씁니다. 이 명령을 다음 Jupyter 셀에 입력합니다.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")이 명령을 다음 Jupyter 셀에 입력하여 파일이 만들어졌는지 확인할 수 있습니다.
/example/batchtripdata디렉터리의 파일이 나열됩니다.%%bash hdfs dfs -ls /example/batchtripdata이전 예제에서는 일괄 처리 쿼리를 사용했지만, 다음 명령에서는 스트리밍 쿼리를 사용하여 동일한 작업을 수행하는 방법을 보여 줍니다. 이 명령을 다음 Jupyter 셀에 입력합니다.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")다음 셀을 실행하여 스트리밍 쿼리에서 파일이 기록되었는지 확인합니다.
%%bash hdfs dfs -ls /example/streamingtripdata
리소스 정리
이 자습서에서 만든 리소스를 정리하려면 리소스 그룹을 삭제합니다. 리소스 그룹을 삭제하면 연결된 HDInsight 클러스터도 삭제됩니다. 그리고 리소스 그룹과 연결된 다른 모든 리소스도 삭제됩니다.
Azure Portal을 사용하여 리소스 그룹을 제거하려면:
- Azure Portal에서 왼쪽의 메뉴를 확장하여 서비스 메뉴를 연 다음, 리소스 그룹을 선택하여 리소스 그룹 목록을 표시합니다.
- 삭제할 리소스 그룹을 찾은 다음 목록 오른쪽에 있는 자세히 단추(...)를 마우스 오른쪽 단추로 클릭합니다.
- 리소스 그룹 삭제 를 선택한 다음 확인합니다.
Warning
클러스터가 만들어지면 HDInsight 클러스터 청구가 시작되고 클러스터가 삭제되면 중지됩니다. 분 단위로 청구되므로 더 이상 사용하지 않으면 항상 클러스터를 삭제해야 합니다.
HDInsight 클러스터의 Kafka를 삭제하면 Kafka에 저장된 데이터가 모두 삭제됩니다.