R 스크립트 실행 구성 요소
이 문서에서는 R 스크립트 실행 구성 요소를 사용하여 Azure Machine Learning 디자이너 파이프라인에서 R 코드를 실행하는 방법을 설명합니다.
R을 사용하면 다음과 같이 기존 구성 요소에서 지원되지 않는 작업을 수행할 수 있습니다.
- 사용자 지정 데이터 변환 만들기
- 자체 메트릭을 사용하여 예측 평가
- 디자이너에서 독립 실행형 구성 요소로 구현되지 않는 알고리즘을 사용하여 모델 빌드
R 버전 지원
Azure Machine Learning 디자이너는 R의 CRAN(광범위한 R 보관 네트워크) 배포를 사용합니다. 현재 사용되는 버전은 CRAN 3.5.1입니다.
지원되는 R 패키지
R 환경은 100개 이상의 패키지와 함께 미리 설치되어 있습니다. 전체 목록은 사전 설치된 R 패키지 섹션을 참조하세요.
R 스크립트 실행 구성 요소에 다음 코드를 추가하여 설치된 패키지를 볼 수도 있습니다.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
참고
파이프라인에 사전 설치된 목록에 없는 패키지를 필요로 하는 R 스크립트 실행 구성 요소가 여러 개 있는 경우 각 구성 요소에 해당 패키지를 설치합니다.
R 패키지 설치
추가 R 패키지를 설치하려면 install.packages() 메서드를 사용합니다. 패키지는 각 R 스크립트 실행 구성 요소에 대해 설치됩니다. 다른 R 스크립트 실행 구성 요소에서 공유되지 않습니다.
참고
스크립트 번들에서 R 패키지를 설치하는 것은 권장하지 않습니다. 스크립트 편집기에서 직접 패키지를 설치하는 것이 좋습니다.
패키지를 설치할 때 CRAN 리포지토리를 지정 합니다(예: install.packages("zoo",repos = "https://cloud.r-project.org")).
경고
R 스크립트 실행 구성 요소는 JAVA를 필요로 하는 qdap 패키지와 C++를 필요로 하는 drc 패키지와 같이 네이티브 컴파일이 필요한 패키지 설치를 지원하지 않습니다. 이 구성 요소는 비관리자 권한으로 사전 설치된 환경에서 실행되기 때문입니다.
디자이너 구성 요소가 Ubuntu에서 실행되고 있으므로 Windows에 사전 빌드된 패키지를 설치하지 마세요. Windows에 패키지가 사전 빌드되었는지 확인하려면 CRAN으로 이동하여 패키지를 검색하고 OS에 따라 이진 파일 하나를 다운로드하고 DESCRIPTION 파일에서 Built: 부분을 확인합니다. 예를 들면 다음과 같습니다. 
이 샘플에서는 Zoo를 설치하는 방법을 보여 줍니다.
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
참고
패키지를 설치하기 전에 설치를 반복하지 않도록 이미 있는지 확인합니다. 설치를 반복하면 웹 서비스 요청 시간이 초과될 수 있습니다.
등록된 데이터 세트에 대한 액세스
다음 샘플 코드를 참조하여 작업 영역에서 등록된 데이터 세트에 액세스할 수 있습니다.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
R 스크립트 실행을 구성하는 방법
R 스크립트 실행 구성 요소에는 시작하는 데 도움이 되는 샘플 코드가 포함되어 있습니다.
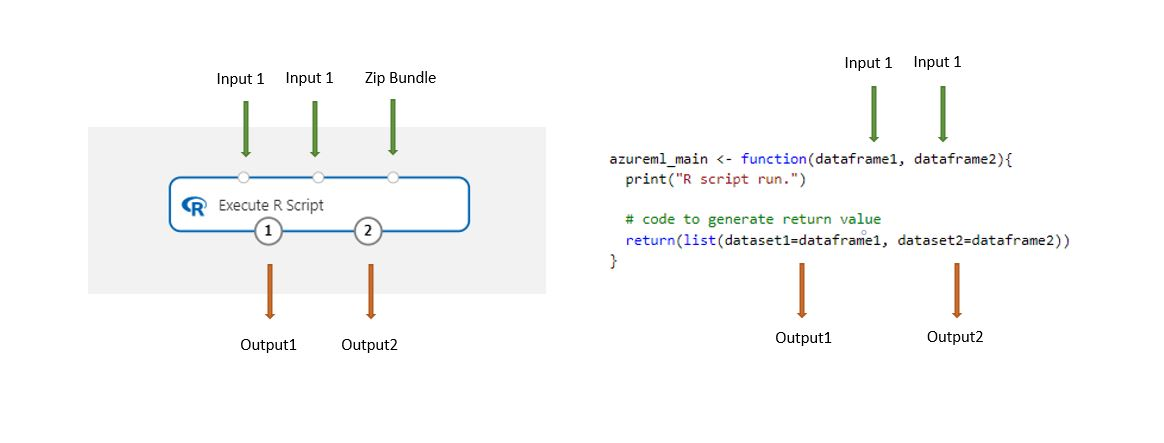
이 구성 요소를 사용하여 로드하면 디자이너에 저장된 데이터 세트가 자동으로 R 데이터 프레임으로 변환됩니다.
파이프라인에 R 스크립트 실행 구성 요소를 추가합니다.
스크립트에 필요한 모든 입력을 연결합니다. 입력은 선택 사항이며 데이터 및 추가 R 코드를 포함할 수 있습니다.
데이터 세트1: 첫 번째 입력을
dataframe1로 참조합니다. 입력 데이터 세트는 CSV, TSV 또는 ARFF 파일 형식으로 지정해야 합니다. 또는 Azure Machine Learning 데이터 세트를 연결할 수 있습니다.데이터 세트2: 두 번째 입력을
dataframe2로 참조합니다. 이 데이터 세트 또한 CSV, TSV 또는 ARFF 파일이나 Azure Machine Learning 데이터 세트로 형식이 지정되어야 합니다.스크립트 번들: 세 번째 입력은 .zip 파일을 허용합니다. 압축된 파일은 여러 파일 및 여러 파일 형식을 포함할 수 있습니다.
R 스크립트 텍스트 상자에 유효한 R 스크립트를 입력하거나 붙여넣습니다.
참고
스크립트를 작성할 때는 주의해야 합니다. 선언되지 않은 변수 또는 가져오지 않은 구성 요소나 함수를 사용하는 것과 같은 구문 오류가 없는지 확인합니다. 이 문서의 끝에 있는 사전 설치된 패키지 목록에 특히 주의해야 합니다. 목록에 없는 패키지를 사용하려면 스크립트에 설치합니다. 예제는
install.packages("zoo",repos = "https://cloud.r-project.org")입니다.시작하는 데 도움이 되도록 R 스크립트 텍스트 상자는 편집하거나 바꿀 수 있는 샘플 코드로 미리 채워져 있습니다.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }진입점 함수는 입력 인수
Param<dataframe1>및Param<dataframe2>를 포함해야 하며 함수에 이러한 인수가 사용되지 않은 경우에도 마찬가지입니다.참고
R 스크립트 실행 구성 요소에 전달되는 데이터는
dataframe1및dataframe2로 참조되며 Azure Machine Learning 디자이너(dataset1,dataset2로 디자이너 참조)와는 다릅니다. 입력 데이터가 스크립트에서 올바르게 참조되는지 확인합니다.참고
기존 R 코드를 디자이너 파이프라인에서 실행 하려면 약간 변경해야 할 수 있습니다. 예를 들어 CSV 형식으로 제공하는 입력 데이터를 코드에서 사용하려면 데이터 세트로 명시적으로 변환해야 합니다. R 언어에서 사용되는 데이터 및 열 유형도 어떤 측면에서는 디자이너에서 사용되는 데이터 및 열 유형과 다릅니다.
스크립트가 16KB보다 큰 경우 스크립트 번들 포트를 사용하여 명령줄에서 16597자 제한 초과 같은 오류를 방지합니다.
- 스크립트 및 기타 사용자 지정 리소스를 Zip 파일로 묶습니다.
- 이 Zip 파일을 File Dataset로 스튜디오에 업로드하세요.
- 디자이너 제작 페이지의 왼쪽 구성 요소 창에 있는 데이터 세트 목록에서 데이터 세트 구성 요소를 끌어옵니다.
- 데이터 세트 구성 요소를 R 스크립트 실행 구성 요소의 스크립트 번들 포트에 연결합니다.
다음은 스크립트 번들에서 스크립트를 사용하는 샘플 코드입니다.
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }임의 시드의 경우 R 환경에서 임의 시드 값으로 사용할 값을 입력합니다. 이 매개 변수는 R 코드에서
set.seed(value)를 호출하는 경우와 동일합니다.파이프라인을 제출합니다.
결과
R 스크립트 실행 구성 요소는 여러 출력을 반환할 수 있지만 R 데이터 프레임으로 제공되어야 합니다. 디자이너는 다른 구성 요소와의 호환성을 위해 데이터 프레임을 자동으로 데이터 세트로 변환합니다.
R의 표준 메시지 및 오류는 구성 요소의 로그로 반환됩니다.
R 스크립트에서 결과를 출력해야 하는 경우 구성 요소의 오른쪽 패널에 있는 출력+로그 탭의 70_driver_log에서 출력 결과를 찾을 수 있습니다.
샘플 스크립트
사용자 지정 R 스크립트를 사용하여 파이프라인을 확장하는 방법에는 여러 가지가 있습니다. 이 섹션에서는 일반적인 작업에 대한 샘플 코드를 제공합니다.
R 스크립트를 입력으로 추가
R 스크립트 실행 구성 요소는 임의의 R 스크립트 파일을 입력으로 지원합니다. 이를 사용하려면 .zip 파일의 일부로 작업 영역에 업로드해야 합니다.
R 코드가 포함된 .zip 파일을 작업 영역에 업로드하려면 데이터 세트 자산 페이지로 이동합니다. 데이터 세트 만들기를 선택한 다음 로컬 파일에서를 선택하고 파일 데이터 세트 유형 옵션을 선택합니다.
압축된 파일이 왼쪽 구성 요소 트리의 데이터 세트 범주의 내 데이터 세트에 표시되는지 확인합니다.
데이터 세트를 스크립트 번들 입력 포트에 연결합니다.
.zip 파일의 모든 파일은 파이프라인 실행 시간 동안 사용할 수 있습니다.
스크립트 번들 파일에 디렉터리 구조가 포함 되어 있는 경우 그 구조가 유지됩니다. 그러나 ./Script Bundle 디렉터리를 경로 앞에 추가하도록 코드를 변경해야 합니다.
데이터 처리
다음 샘플에서는 입력 데이터의 크기를 조정하고 정규화하는 방법을 보여 줍니다.
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
.zip 파일을 입력으로 읽기
이 샘플에서는 .zip 파일의 데이터 세트를 R 스크립트 실행 구성 요소에 대한 입력으로 사용하는 방법을 보여 줍니다.
- CSV 형식의 데이터 파일을 만들고 이름을 mydatafile.csv로 지정합니다.
- .zip 파일을 만들고 보관함에 CSV 파일을 추가합니다.
- 압축 파일을 Azure Machine Learning 작업 영역에 업로드합니다.
- 결과 데이터 세트를 R 스크립트 실행 구성 요소의 ScriptBundle 입력에 연결합니다.
- 압축 파일에서 CSV 데이터를 읽으려면 다음 코드를 사용합니다.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
행 복제
이 샘플에서는 데이터 세트의 양수 레코드를 복제하여 샘플의 균형을 유지하는 방법을 보여 줍니다.
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
R 스크립트 실행 구성 요소 간에 R 개체 전달
내부 serialization 메커니즘을 사용하면 R 스크립트 실행 구성 요소 인스턴스 간에 R 개체를 전달할 수 있습니다. 이 예에서는 두 개의 R 스크립트 실행 구성 요소 간에 A로 명명된 R 개체를 이동하려 한다고 가정합니다.
파이프라인에 첫 번째 R 스크립트 실행 구성 요소를 추가합니다. 그런 다음 R 스크립트 텍스트 상자에 다음 코드를 입력하여 직렬화된 개체
A를 구성 요소의 출력 데이터 테이블의 열로 만듭니다.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }직렬화 함수가 디자이너가 지원하지 않는 R
Raw형식으로 데이터를 출력하기 때문에 정수 유형으로 명시적 변환을 수행합니다.R 스크립트 실행 구성 요소의 두 번째 인스턴스를 추가하고 이를 이전 구성 요소의 출력 포트에 연결합니다.
R 스크립트 텍스트 상자에 다음 코드를 입력하여 입력 데이터 테이블에서 개체
A를 추출합니다.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
사전 설치된 R 패키지
현재 다음과 같은 사전 설치된 R 패키지를 사용할 수 있습니다.
| 패키지 | 버전 |
|---|---|
| askpass | 1.1 |
| assertthat | 0.2.1 |
| backports | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| boot | 1.3-22 |
| broom | 0.5.2 |
| callr | 3.2.0 |
| 캐럿 | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| class | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| cluster | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| compiler | 3.5.1 |
| crayon | 1.3.4 |
| curl | 3.3 |
| data.table | 1.12.2 |
| datasets | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| evaluate | 0.14 |
| fansi | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| foreign | 0.8-71 |
| fs | 1.3.1 |
| gdata | 2.18.0 |
| 제네릭(generics) | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| glue | 1.3.1 |
| gower | 0.2.1 |
| gplots | 3.0.1.1 |
| graphics | 3.5.1 |
| grDevices | 3.5.1 |
| 그리드 | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| highr | 0.8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| iterators | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| knitr | 1.23 |
| labeling | 0.3 |
| lattice | 0.20-38 |
| lava | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| markdown | 1 |
| MASS | 7.3-51.4 |
| 행렬 | 1.2-17 |
| methods | 3.5.1 |
| mgcv | 1.8-28 |
| mime | 0.7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| pillar | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| progress | 1.2.2 |
| ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quantmod | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| recipes | 0.1.5 |
| rematch | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| reticulate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0.1 |
| rvest | 0.3.4 |
| scales | 1.0.0 |
| selectr | 0.4-1 |
| spatial | 7.3-11 |
| splines | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| stats4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| survival | 2.44-1.1 |
| sys | 3.2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| timeDate | 3043.102 |
| tinytex | 0.13 |
| 도구 | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| utils | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| whisker | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0.8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoo | 1.8-6 |
다음 단계
Azure Machine Learning에서 사용 가능한 구성 요소 집합을 참조하세요.