텍스트 구성 요소 참조에서 N-Gram 기능 추출
이 문서에서는 Azure Machine Learning 디자이너의 구성 요소에 대해 설명합니다. 텍스트에서 N-Gram 기능 추출 구성 요소를 사용하여 구조화되지 않은 텍스트 데이터를 기능화합니다.
텍스트 모듈에서 N-Gram 기능 추출 구성 요소 구성
이 구성 요소는 n-gram 사전을 사용하는 다음 시나리오를 지원합니다.
자유 텍스트 열에서 새 n-gram 사전을 생성합니다.
기존 텍스트 기능 집합을 사용하여 자유 텍스트 열을 기능화합니다.
n-gram을 사용하는 모델을 채점하거나 배포합니다.
새 n-gram 사전 만들기
텍스트에서 N-Gram 기능 추출 구성 요소를 파이프라인에 추가하고 처리하려는 텍스트가 있는 데이터 세트를 연결합니다.
텍스트 열을 사용하여 추출할 텍스트가 포함된 문자열 형식의 열을 선택합니다. 결과가 자세한 정보를 표시하기 때문에 한 번에 하나의 열만 처리할 수 있습니다.
어휘 모드를 만들기로 설정하여 n-gram 기능의 새 목록을 만들고 있음을 나타냅니다.
N-Gram 크기를 설정하여 추출하고 저장할 n-gram의 ‘최대’ 크기를 나타냅니다.
예를 들어 3을 입력하면 유니그램, 바이그램, 트라이그램이 만들어집니다.
가중치 함수는 문서 기능 벡터를 빌드하는 방법과 문서에서 어휘를 추출하는 방법을 지정합니다.
이진 가중치: 추출된 n-gram에 이진 현재 상태 값을 할당합니다. 각 n-gram의 값은 문서에 있으면 1이고, 그렇지 않으면 0입니다.
TF 가중치: 추출된 n-그램에 TF(용어 빈도) 점수를 할당합니다. 각 n-gram의 값은 문서에서 발생하는 빈도입니다.
IDF 가중치: 추출된 n-gram에 IDF(역 문서 빈도) 점수를 할당합니다. 각 n-gram의 값은 전체 모음의 발생 빈도로 나눈 모음 크기의 로그입니다.
IDF = log of corpus_size / document_frequencyTF-IDF 가중치: 추출된 n-gram에 TF/IDF(용어 빈도/역 문서 빈도) 점수를 할당합니다. 각 n-gram의 값은 해당 TF 점수와 IDF 점수를 곱한 값입니다.
최소 단어 길이를 n-gram의 모든 ‘단일 단어’에서 사용할 수 있는 최소 문자 수로 설정합니다.
최대 단어 길이를 사용하여 n-gram의 모든 ‘단일 단어’에서 사용할 수 있는 최대 문자 수를 설정합니다.
기본적으로 단어 또는 토큰당 최대 25자까지 허용됩니다.
최소 n-gram 문서 절대 빈도를 사용하여 n-gram 사전에 포함될 모든 n-gram에 필요한 최소 발생 횟수를 설정합니다.
예를 들어 기본값 5를 사용하는 경우 n-gram 사전에 포함되는 모음에 어떤 n-gram이든 5번 이상 나타나야 합니다.
최대 n-gram 문서 비율을 전체 모음의 행 수에 대해 특정 n-gram을 포함하는 행 수의 최대 비율로 설정합니다.
예를 들어 비율 1은 특정 n-gram이 모든 행에 있는 경우에도 n-gram을 n-gram 사전에 추가할 수 있음을 나타냅니다. 일반적으로 모든 행에서 발생하는 단어는 의미 없는 단어로 간주되고 제거됩니다. 도메인에 종속되는 의미 없는 단어를 필터링하려면 이 비율을 줄여 보세요.
중요
특정 단어의 발생률은 균일하지 않습니다. 문서마다 다릅니다. 예를 들어 특정 제품에 대한 고객의 의견을 분석하는 경우 제품 이름의 발생 빈도가 매우 높아져서 의미 없는 단어에 근접해지지만 다른 컨텍스트에서는 중요한 용어일 수 있습니다.
n-gram 기능 벡터 정규화 옵션을 선택하여 기능 벡터를 정규화합니다. 이 옵션을 사용하면 각 n-gram 기능 벡터가 해당 L2 표준으로 나누어집니다.
파이프라인을 제출합니다.
기존 n-gram 사전 사용
텍스트에서 N-Gram 기능 추출 구성 요소를 파이프라인에 추가하고 처리하려는 텍스트가 있는 데이터 세트를 데이터 세트 포트에 연결합니다.
텍스트 열을 사용하여 기능화할 텍스트가 포함된 텍스트 열을 선택합니다. 기본적으로 구성 요소는 문자열 형식의 모든 열을 선택합니다. 최상의 결과를 얻기 위해 한 번에 하나의 열을 처리합니다.
이전에 생성된 n-gram 사전을 포함하는 저장된 데이터 세트를 추가하고 입력 어휘 포트에 연결합니다. 텍스트에서 N-Gram 기능 추출 구성 요소의 업스트림 인스턴스에 대한 결과 어휘 출력을 연결할 수도 있습니다.
어휘 모드의 경우 드롭다운 목록에서 읽기 전용 업데이트 옵션을 선택합니다.
읽기 전용 옵션은 입력 어휘에 대한 입력 모음을 나타냅니다. 새 텍스트 데이터 세트(왼쪽 입력)에서 용어 빈도를 계산하는 대신 입력 어휘의 n-gram 가중치가 있는 그대로 적용됩니다.
팁
텍스트 분류자를 채점하는 경우 이 옵션을 사용합니다.
다른 모든 옵션은 이전 섹션의 속성 설명을 참조하세요.
파이프라인을 제출합니다.
n-gram을 사용하여 실시간 엔드포인트를 배포하는 유추 파이프라인 빌드
테스트 데이터 세트에 대한 예측을 수행하기 위해 텍스트에서 N-Gram 기능 추출과 모델 채점을 포함하는 학습 파이프라인은 다음 구조로 빌드됩니다.
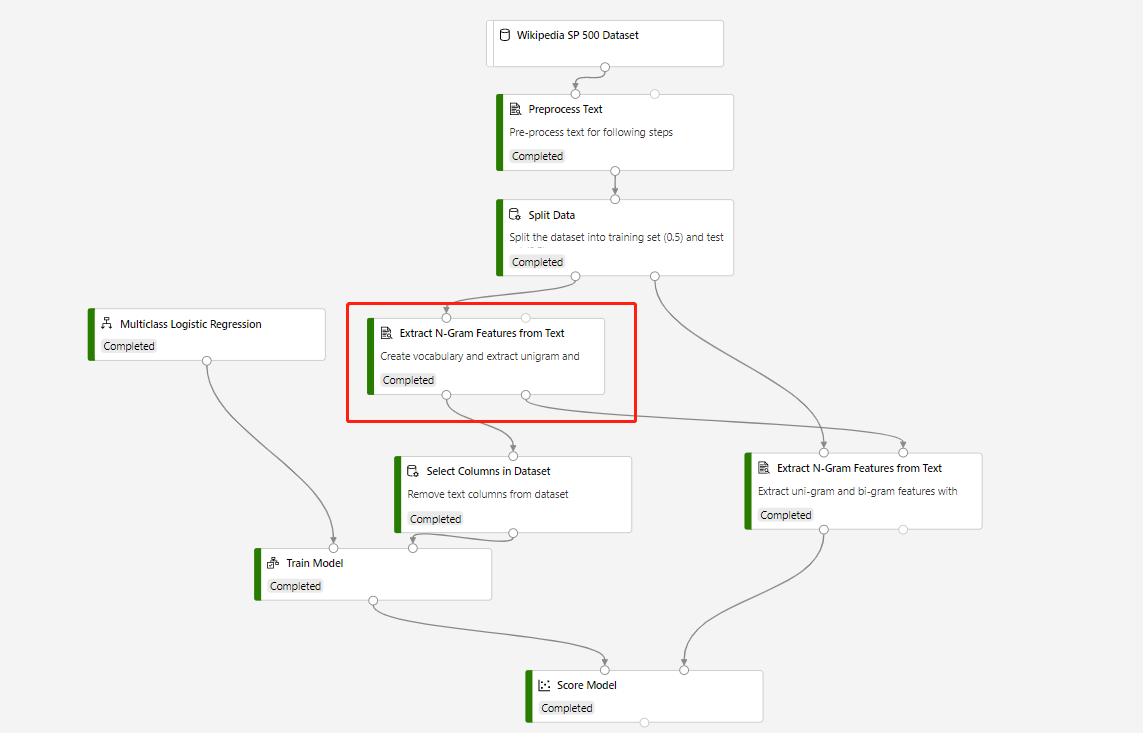
강조 표시된 텍스트에서 N-Gram 기능 추출 구성 요소의 어휘 모드는 만들기이고 모델 채점 구성 요소에 연결되는 구성 요소의 어휘 모드는 읽기 전용입니다.
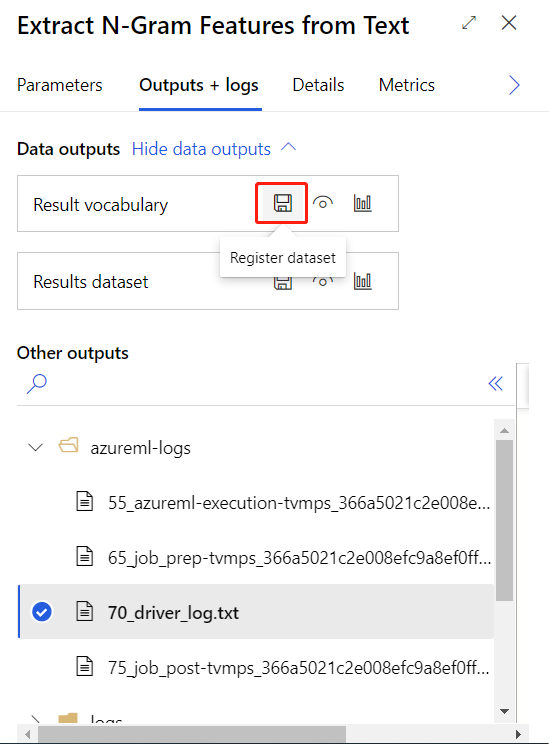
위의 학습 파이프라인을 성공적으로 제출한 후 강조 표시된 구성 요소의 출력을 데이터 세트로 등록할 수 있습니다.
그런 다음, 실시간 유추 파이프라인을 만들 수 있습니다. 유추 파이프라인을 만든 후에 다음과 같이 유추 파이프라인을 수동으로 조정해야 합니다.
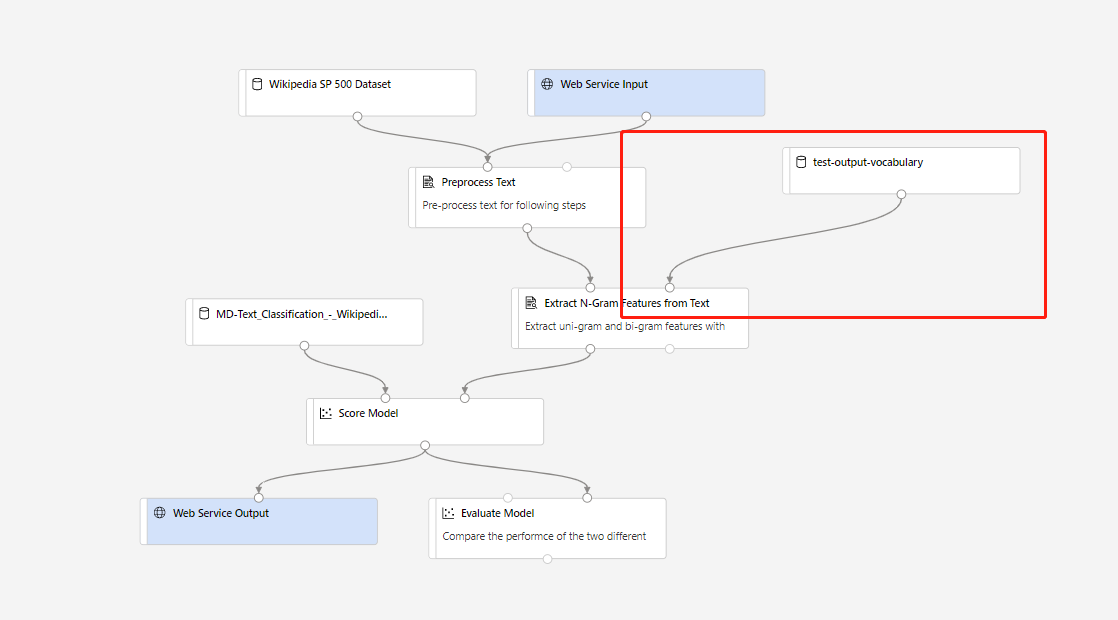
그런 다음, 유추 파이프라인을 제출하고 실시간 엔드포인트를 배포합니다.
결과
텍스트에서 N-Gram 기능 추출 구성 요소는 다음 두 가지 유형의 출력을 만듭니다.
결과 데이터 세트: 이 출력은 추출된 n-gram과 결합되어 있는 분석된 텍스트의 요약입니다. 텍스트 열 옵션에서 선택하지 않은 열은 출력으로 전달됩니다. 분석하는 텍스트의 각 열에 대해 구성 요소는 다음 열을 생성합니다.
- n-gram 발생 행렬: 구성 요소는 총 모음에서 발견된 각 n-gram에 대해 열을 생성하고 각 열에 점수를 추가하여 해당 행에 대한 n-gram의 가중치를 표시합니다.
결과 어휘: 어휘에는 분석의 일부로 생성되는 용어 빈도 점수와 더불어 실제 n-gram 사전이 포함되어 있습니다. 다른 입력 집합에서 다시 사용하거나 다음에 업데이트하기 위해 데이터 세트를 저장할 수 있습니다. 모델링과 채점을 위해 어휘를 다시 사용할 수도 있습니다.
결과 어휘
어휘에는 분석의 일부로 생성되는 용어 빈도 점수와 더불어 n-gram 사전이 포함되어 있습니다. DF 및 IDF 점수는 다른 옵션과 관계없이 생성됩니다.
- ID: 각각의 고유 n-gram에 대해 생성되는 식별자입니다.
- NGram: n-gram입니다. 공백이나 다른 단어 구분 기호는 밑줄 문자로 바뀝니다.
- DF: 원래 모음의 n-gram에 대한 용어 빈도 점수입니다.
- IDF: 원래 모음의 n-gram에 대한 역 문서 빈도 점수입니다.
이 데이터 세트를 수동으로 업데이트할 수 있지만 오류가 발생할 수 있습니다. 예를 들면 다음과 같습니다.
- 구성 요소가 입력 어휘에서 동일한 키를 가진 중복 행을 찾으면 오류가 발생합니다. 어휘의 두 행이 동일한 단어를 포함하지 않도록 하세요.
- 어휘 데이터 세트의 입력 스키마는 열 이름과 열 유형을 포함하여 정확하게 일치해야 합니다.
- ID 열 및 DF 열은 정수 형식이어야 합니다.
- IDF 열은 float 형식이어야 합니다.
참고
데이터 출력을 모델 학습 구성 요소에 직접 연결하지 마세요. 학습 모델에 공급하기 전에 자유 텍스트 열을 제거해야 합니다. 그러지 않으면 자유 텍스트 열이 범주 기능으로 처리됩니다.
다음 단계
Azure Machine Learning에서 사용 가능한 구성 요소 집합을 참조하세요.