Azure에서 Ubuntu Data Science Virtual Machine을 사용하는 데이터 과학
이 연습에서는 Ubuntu DSVM(Data Science Virtual Machine)을 사용하여 몇 가지 일반적인 데이터 과학 작업을 수행하는 방법을 보여 줍니다. Ubuntu DSVM은 Azure에서 사용할 수 있는 가상 머신 이미지이며, 데이터 분석 및 기계 학습에 일반적으로 사용되는 도구 모음과 함께 사전 설치되어 있습니다. 주요 소프트웨어 구성 요소는 Ubuntu Data Science Virtual Machine 프로비저닝에 항목별로 나와 있습니다. DSVM 이미지를 사용하면 각 도구를 개별적으로 설치하고 구성할 필요 없이 몇 분 내에 데이터 과학 작업을 쉽게 시작할 수 있습니다. 필요한 경우 DSVM을 쉽게 확장할 수 있으며 사용하지 않을 때는 중지할 수 있습니다. 이 DSVM 리소스는 탄력적이고 비용 효율적입니다.
이 연습에서는 spambase 데이터 세트를 분석합니다. Spambase는 스팸 또는 햄(스팸이 아님)으로 표시된 이메일 집합입니다. Spambase에는 이메일의 내용에 대한 일부 통계도 포함되어 있습니다. 이 연습의 뒷부분에서 이러한 통계에 대해 설명합니다.
필수 조건
Linux DSVM을 사용하려면 먼저 다음과 같은 필수 구성 요소가 있어야 합니다.
Azure 구독. Azure 구독을 얻으려면 지금 무료 Azure 계정 만들기를 참조하세요.
Ubuntu Data Science Virtual Machine. 가상 머신을 프로비전하는 방법에 대한 자세한 내용은 Ubuntu Data Science Virtual Machine 프로비저닝을 참조하세요.
열린 XFCE 세션을 사용하여 컴퓨터에 설치된 X2Go. 자세한 내용은 X2Go 클라이언트 설치 및 구성을 참조하세요.
spambase 데이터 세트 다운로드
spambase 데이터 세트는 4,601개 예제를 포함하는 비교적 작은 데이터 세트입니다. 이 데이터 세트는 리소스 요구 사항을 적당한 수준으로 유지하므로 DSVM의 몇 가지 주요 기능을 보여 줄 수 있는 편리한 크기입니다.
참고 항목
이 연습은 D2 v2 크기 Linux DSVM을 사용하여 만들었습니다. 이 크기의 DSVM을 사용하여 이 연습에서 설명하는 절차를 완료할 수 있습니다.
스토리지 공간이 더 필요한 경우 추가 디스크를 만들고 DSVM에 연결할 수 있습니다. 이러한 디스크는 영구 Azure Storage를 사용하므로 서버가 크기 조정으로 인해 다시 프로비전되거나 종료되는 경우에도 해당 데이터는 보존됩니다. DSVM에 디스크를 추가하고 연결하려면 Linux VM에 디스크 추가의 단계를 완료합니다. 디스크를 추가하는 단계는 DSVM에 이미 설치되어 있는 Azure CLI를 사용합니다. DSVM 자체에서 전체 단계를 완료할 수 있습니다. 스토리지를 늘리는 또 다른 옵션은 Azure Files를 사용하는 것입니다.
데이터를 다운로드하려면 터미널 창을 열고 다음 명령을 실행합니다.
wget --no-check-certificate https://archive.ics.uci.edu/ml/machine-learning-databases/spambase/spambase.data
다운로드한 파일에는 헤더 행이 없습니다. 헤더를 포함하는 다른 파일을 만들어 보겠습니다. 다음 명령을 실행하여 적합한 머리글이 있는 파일을 만듭니다.
echo 'word_freq_make, word_freq_address, word_freq_all, word_freq_3d,word_freq_our, word_freq_over, word_freq_remove, word_freq_internet,word_freq_order, word_freq_mail, word_freq_receive, word_freq_will,word_freq_people, word_freq_report, word_freq_addresses, word_freq_free,word_freq_business, word_freq_email, word_freq_you, word_freq_credit,word_freq_your, word_freq_font, word_freq_000, word_freq_money,word_freq_hp, word_freq_hpl, word_freq_george, word_freq_650, word_freq_lab,word_freq_labs, word_freq_telnet, word_freq_857, word_freq_data,word_freq_415, word_freq_85, word_freq_technology, word_freq_1999,word_freq_parts, word_freq_pm, word_freq_direct, word_freq_cs, word_freq_meeting,word_freq_original, word_freq_project, word_freq_re, word_freq_edu,word_freq_table, word_freq_conference, char_freq_semicolon, char_freq_leftParen,char_freq_leftBracket, char_freq_exclamation, char_freq_dollar, char_freq_pound, capital_run_length_average,capital_run_length_longest, capital_run_length_total, spam' > headers
그런 다음 두 파일을 연결합니다.
cat spambase.data >> headers
mv headers spambaseHeaders.data
데이터 세트에는 각 메일에 대한 다양한 통계가 있습니다.
- word_freq_WORD와 같은 열은 메일에서 WORD와 일치하는 단어의 백분율을 나타냅니다. 예를 들어 word_freq_make가 1인 경우에는 메일에 있는 모든 단어의 1%가 make입니다.
- char_freq_CHAR와 같은 열은 메일에 있는 모든 문자 중 CHAR 문자의 백분율을 나타냅니다.
- capital_run_length_longest는 대문자 시퀀스의 가장 긴 길이입니다.
- capital_run_length_average는 모든 대문자 시퀀스의 평균 길이입니다.
- capital_run_length_total은 모든 대문자 시퀀스의 총 길이입니다.
- spam 은 메일이 스팸으로 간주되는지 여부를 나타냅니다(1 = 스팸, 0 = 스팸이 아님).
R Open을 사용하여 데이터 세트 탐색
R을 사용하여 데이터를 검토하고 몇 가지 기본 기계 학습을 수행해 보겠습니다. DSVM은 CRAN R이 사전 설치되어 제공됩니다.
이 연습에서 사용되는 코드 샘플의 복사본을 가져오려면 git를 사용하여 Azure-Machine-Learning-Data-Science 리포지토리를 복제합니다. Git는 DSVM에 사전 설치되어 있습니다. Git 명령줄에서 다음을 실행합니다.
git clone https://github.com/Azure/Azure-MachineLearning-DataScience.git
터미널 창을 열고 R 대화형 콘솔에서 새 R 세션을 시작합니다. 데이터를 가져오고 환경을 설정하려면
data <- read.csv("spambaseHeaders.data")
set.seed(123)
각 열에 대한 요약 통계를 보려면
summary(data)
데이터를 다른 보기로 보려면
str(data)
이 보기에서는 각 변수 유형과 데이터 세트의 처음 몇 개의 값을 보여 줍니다.
spam 열은 정수로 읽었지만 실제로는 범주 변수(또는 요소)입니다. 해당 형식을 설정하려면
data$spam <- as.factor(data$spam)
일부 예비 분석을 수행하려면 DSVM에 사전 설치되어 있는 인기 있는 R용 그래프 작성 라이브러리인 ggplot2 패키지를 사용합니다. 앞에서 표시된 요약 데이터를 기반으로 느낌표 문자의 빈도에 대한 요약 통계가 있습니다. 다음 명령을 실행하여 해당 빈도를 도표로 나타내 보겠습니다.
library(ggplot2)
ggplot(data) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
0 막대는 도표를 왜곡시키기 때문에 제거하겠습니다.
email_with_exclamation = data[data$char_freq_exclamation > 0, ]
ggplot(email_with_exclamation) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
흥미롭게도 1보다 큰 특수한 밀도가 있습니다. 이 데이터만 살펴보겠습니다.
ggplot(data[data$char_freq_exclamation > 1, ]) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
그런 다음 스팸과 햄을 구분합니다.
ggplot(data[data$char_freq_exclamation > 1, ], aes(x=char_freq_exclamation)) +
geom_density(lty=3) +
geom_density(aes(fill=spam, colour=spam), alpha=0.55) +
xlab("spam") +
ggtitle("Distribution of spam \nby frequency of !") +
labs(fill="spam", y="Density")
이러한 예제는 비슷한 도표를 만들고 다른 열의 데이터를 탐색하는 데 도움이 됩니다.
기계 학습 모델 학습 및 테스트
스팸 또는 햄을 포함하도록 데이터 세트에서 메일을 분류하는 기계 학습 모델 두 가지를 학습하겠습니다. 이 섹션에서는 의사 결정 트리 모델 및 임의 포리스트 모델을 학습합니다. 그런 다음 예측의 정확도를 테스트합니다.
참고 항목
다음 코드에 사용되는 rpart(재귀 분할 및 회귀 트리) 패키지는 이미 DSVM에 설치되어 있습니다.
먼저 데이터 세트를 학습 집합과 테스트 집합으로 분할합니다.
rnd <- runif(dim(data)[1])
trainSet = subset(data, rnd <= 0.7)
testSet = subset(data, rnd > 0.7)
그런 다음 메일을 분류하는 의사 결정 트리를 만듭니다.
require(rpart)
model.rpart <- rpart(spam ~ ., method = "class", data = trainSet)
plot(model.rpart)
text(model.rpart)
결과:
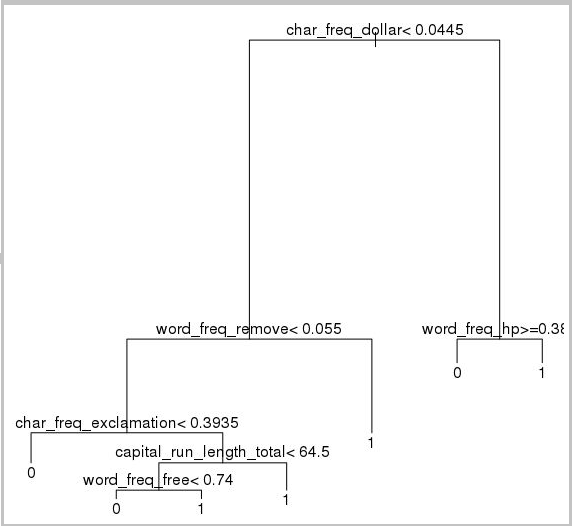
학습 집합에 대해 얼마나 잘 수행하는지를 확인하려면 다음 코드를 사용합니다.
trainSetPred <- predict(model.rpart, newdata = trainSet, type = "class")
t <- table(`Actual Class` = trainSet$spam, `Predicted Class` = trainSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
테스트 집합에 대해 얼마나 잘 수행하는지를 확인하려면
testSetPred <- predict(model.rpart, newdata = testSet, type = "class")
t <- table(`Actual Class` = testSet$spam, `Predicted Class` = testSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
임의 포리스트 모델도 살펴보겠습니다. 임의 포리스트는 다양한 의사 결정 트리를 학습하고 모든 개별 의사 결정 트리의 분류 모드인 클래스를 출력합니다. 이들은 의사 결정 트리 모델이 학습 데이터 세트를 과잉 맞춤하는 경향을 수정하기 때문에 더 강력한 기계 학습 접근 방식을 제공합니다.
require(randomForest)
trainVars <- setdiff(colnames(data), 'spam')
model.rf <- randomForest(x=trainSet[, trainVars], y=trainSet$spam)
trainSetPred <- predict(model.rf, newdata = trainSet[, trainVars], type = "class")
table(`Actual Class` = trainSet$spam, `Predicted Class` = trainSetPred)
testSetPred <- predict(model.rf, newdata = testSet[, trainVars], type = "class")
t <- table(`Actual Class` = testSet$spam, `Predicted Class` = testSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
딥 러닝 자습서 및 연습
프레임워크 기반 샘플 외에도 일련의 종합적인 연습도 제공됩니다. 이러한 연습을 통해 이미지 및 텍스트/언어 이해와 같이 도메인에서 딥 러닝 애플리케이션의 개발을 빠르게 시작할 수 있습니다.
다양한 프레임워크에서 신경망 실행: 한 프레임워크에서 다른 프레임워크로 코드를 마이그레이션하는 방법을 보여주는 포괄적인 연습입니다. 또한 프레임워크 간에 모델 및 런타임 성능을 비교하는 방법을 보여 줍니다.
이미지 내 제품을 검색하는 엔드투엔드 솔루션을 빌드하는 방법 가이드: 이미지 검색은 이미지 내의 개체를 찾고 분류할 수 있는 기술입니다. 이 기술은 많은 실제 비즈니스 도메인에서 엄청난 성과를 거둘 수 있습니다. 예를 들어 소매업체는 이 기술을 사용하여 고객이 선택한 제품을 확인할 수 있습니다. 또한 이 정보는 매장의 제품 재고를 관리하는 데 도움이 됩니다.
오디오 딥 러닝: 이 자습서에서는 도시 소리 데이터 세트에서 오디오 이벤트를 검색하기 위한 딥 러닝 모델을 학습시키는 방법을 보여 줍니다. 이 자습서에서는 오디오 데이터로 작업하는 방법에 대한 개요를 제공합니다.
텍스트 문서의 분류: 이 연습에서는 두 개의 다른 신경망 아키텍처(Hierarchical Attention Network 및 LSTM(Long Short Term Memory).)를 빌드 및 학습하는 방법을 보여줍니다. 이러한 신경망은 Keras API를 딥 러닝에 사용하여 텍스트 문서를 분류합니다. Keras는 가장 인기 있는 딥 러닝 프레임워크인 Microsoft Cognitive Toolkit, TensorFlow 및 Theano의 프런트 엔드입니다.
기타 도구
나머지 섹션에서는 Linux DSVM에 설치된 일부 도구를 사용하는 방법을 보여 줍니다. 다음 도구에 대해 설명합니다.
- XGBoost
- Python
- JupyterHub
- Rattle
- PostgreSQL 및 SQuirreL SQL
- Azure Synapse Analytics(이전의 SQL DW)
XGBoost
XGBoost는 빠르고 정확하게 부스트되는 트리 구현을 제공합니다.
require(xgboost)
data <- read.csv("spambaseHeaders.data")
set.seed(123)
rnd <- runif(dim(data)[1])
trainSet = subset(data, rnd <= 0.7)
testSet = subset(data, rnd > 0.7)
bst <- xgboost(data = data.matrix(trainSet[,0:57]), label = trainSet$spam, nthread = 2, nrounds = 2, objective = "binary:logistic")
pred <- predict(bst, data.matrix(testSet[, 0:57]))
accuracy <- 1.0 - mean(as.numeric(pred > 0.5) != testSet$spam)
print(paste("test accuracy = ", accuracy))
또한 XGBoost는 Python 또는 명령줄에서 호출할 수도 있습니다.
Python
Python 개발의 경우 Anaconda Python 배포판 3.5 및 2.7이 DSVM에 설치되어 있습니다.
참고 항목
Anaconda 배포판은 Conda를 포함합니다. Conda를 사용하여 다른 버전 또는 패키지를 설치하는 사용자 지정 Python 환경을 만들 수 있습니다.
spambase 데이터 세트의 일부를 읽고 Scikit-learn에서 벡터 컴퓨터를 지원하는 메일을 분류해 보겠습니다.
import pandas
from sklearn import svm
data = pandas.read_csv("spambaseHeaders.data", sep = ',\s*')
X = data.ix[:, 0:57]
y = data.ix[:, 57]
clf = svm.SVC()
clf.fit(X, y)
예측하려면
clf.predict(X.ix[0:20, :])
Azure Machine Learning 엔드포인트를 게시하는 방법을 보여 주기 위해 더 기본적인 모델을 만들어 보겠습니다. 이전에 R 모델을 게시할 때 사용한 세 가지 변수를 사용합니다.
X = data[["char_freq_dollar", "word_freq_remove", "word_freq_hp"]]
y = data.ix[:, 57]
clf = svm.SVC()
clf.fit(X, y)
JupyterHub
DSVM에서 Anaconda 배포판에는 Jupyter Notebook, Python R 공유를 위한 플랫폼 간 환경 또는 Julia 코드 및 분석이 함께 제공됩니다. JupyterHub를 통해 Jupyter Notebook에 액세스합니다. https://<DSVM DNS name or IP address>:8000/에서 로컬 Linux 사용자 이름 및 암호를 사용하여 로그인합니다. JupyterHub에 대한 모든 구성 파일은 /etc/jupyterhub 디렉터리에서 찾을 수 있습니다.
참고 항목
현재 커널의 Jupyter Notebook에서 pip 명령을 통해 Python 패키지 관리자를 사용하려면 코드 셀에 다음 명령을 사용합니다.
import sys
! {sys.executable} -m pip install numpy -y
현재 커널의 Jupyter Notebook에서 conda 명령을 통해 Conda 설치 관리자를 사용하려면 코드 셀에 다음 명령을 사용합니다.
import sys
! {sys.prefix}/bin/conda install --yes --prefix {sys.prefix} numpy
몇 가지 샘플 Notebook이 DSVM에 이미 설치되어 있습니다.
- 샘플 Python Notebook:
- 샘플 R Notebook:
참고 항목
또한 Julia 언어는 Linux DSVM의 명령줄에서 사용할 수도 있습니다.
Rattle
Rattle(RAnalytical Tool To Learn Easily)은 데이터 마이닝을 위한 그래픽 R 도구입니다. Rattle에는 손쉽게 데이터를 로드, 탐색 및 변환하고 모델을 빌드 및 평가할 수 있는 직관적인 인터페이스가 있습니다. Rattle: A Data Mining GUI for R(Rattle: R용 데이터 마이닝 GUI)은 Rattle의 기능을 보여 주는 연습을 제공합니다.
다음 명령을 실행하여 Rattle을 설치하고 시작합니다.
if(!require("rattle")) install.packages("rattle")
require(rattle)
rattle()
참고 항목
DSVM에 Rattle를 설치할 필요가 없습니다. 그러나 Rattle이 열릴 때 추가 패키지를 설치하라는 메시지가 표시될 수 있습니다.
Rattle은 탭 기반 인터페이스를 사용합니다. 대부분의 탭은 데이터를 로드하거나 데이터를 탐색하는 등 팀 데이터 과학 프로세스의 단계에 해당합니다. 데이터 과학 프로세스는 탭을 통해 왼쪽에서 오른쪽으로 진행됩니다. 하지만 마지막 탭에는 Rattle에서 실행한 R 명령의 로그가 있습니다.
데이터 세트를 로드하고 구성하려면
- 파일을 로드하려면 데이터 탭을 선택합니다.
- 파일 이름 옆의 선택기를 선택한 다음 spambaseHeaders.data를 선택합니다.
- 파일을 로드하려면 실행을 선택합니다. 입력, 대상 또는 다른 유형의 변수인지 고유한 값의 수인지 식별된 데이터 형식을 포함하여 각 열에 대한 요약이 표시됩니다.
- Rattle은 spam 열을 대상으로 제대로 식별합니다. spam 열을 선택한 다음 대상 데이터 형식을 범주로 설정합니다.
데이터를 탐색하려면
- 탐색 탭을 선택합니다.
- 변수 형식 및 일부 요약 통계에 대한 정보를 보려면 요약>실행을 선택합니다.
- 각 변수에 대한 다른 종류의 통계를 보려면 설명 또는 기본 사항 등 다른 옵션을 선택합니다.
탐색 탭을 사용하여 통찰력 있는 도표를 생성할 수도 있습니다. 데이터의 히스토그램을 나타내려면
- 배포를 선택합니다.
- word_freq_remove 및 word_freq_you에서 히스토그램을 선택합니다.
- 실행을 선택합니다. 두 밀도 도표가 단일 그래프 창에 표시되고 여기서 단어 you가 remove보다 메일에 훨씬 더 자주 나오는 것을 볼 수 있습니다.
상관 관계 도표도 흥미롭습니다. 도표를 만들려면
- 유형에 대해 상관 관계를 선택합니다.
- 실행을 선택합니다.
- 권장 최대 변수는 40개라는 경고 메시지가 표시됩니다. 도표를 보려면 예 를 선택합니다.
여기서 몇 가지 흥미로운 상관 관계를 볼 수 있습니다. 예를 들어 technology는 HP 및 labs와 밀접하게 상호 관련되어 있습니다. 데이터 세트 기부자의 지역 번호가 650이기 때문에 650과도 아주 밀접하게 상호 관련됩니다.
단어 사이의 상관 관계에 대한 숫자 값은 탐색 창에서 사용할 수 있습니다. 예를 들어 technology가 your 및 money와 부정적으로 상호 관련되어 있다는 점도 흥미로운 사실입니다.
Rattle은 몇 가지 일반적인 문제를 처리하기 위해 데이터 세트를 변환할 수 있습니다. 예를 들어 기능 크기 재조정, 누락된 값 대체, 이상값 처리, 데이터가 누락된 관찰 또는 변수를 제거할 수 있습니다. Rattle은 관찰 및 변수 간의 연결 규칙을 식별할 수도 있습니다. 이러한 탭은 이 소개 연습에서 다루지 않습니다.
또한 Rattle은 클러스터 분석도 실행할 수 있습니다. 출력을 더 쉽게 읽을 수 있도록 일부 기능을 제외하겠습니다. 데이터 탭에서 다음 10개 항목을 제외하고 각 변수 옆의 무시를 선택합니다.
- word_freq_hp
- word_freq_technology
- word_freq_george
- word_freq_remove
- word_freq_your
- word_freq_dollar
- word_freq_money
- capital_run_length_longest
- word_freq_business
- 스팸
클러스터 탭으로 돌아갑니다. KMeans를 선택하고 클러스터 수를 4로 설정합니다. 실행을 선택합니다. 결과가 출력 창에 표시됩니다. 한 클러스터가 george 및 hp의 빈도가 높고 아마도 합법적인 비즈니스 메일입니다.
기본적인 의사 결정 트리 기계 학습 모델을 빌드하려면
- 모델 탭을 선택합니다.
- 형식에 대해 트리를 선택합니다.
- 실행 을 선택하여 출력 창에 텍스트 형식으로 트리를 표시합니다.
- 그리기 단추를 선택하여 그래픽 버전을 봅니다. 의사 결정 트리는 앞서 rpart를 사용하여 가져온 트리와 비슷합니다.
Rattle의 유용한 기능 중 하나는 여러 기계 학습 방법을 실행하고 신속하게 평가하는 기능입니다. 단계는 다음과 같습니다.
- 형식에 대해 모두를 선택합니다.
- 실행을 선택합니다.
- Rattle 실행이 완료되면 SVM같은 형식 값을 선택하고 결과를 볼 수 있습니다.
- 평가 탭을 사용하여 유효성 검사 집합에서 모델의 성능을 비교할 수도 있습니다. 예를 들어 오류 매트릭스 를 선택하면 유효성 검사 집합에서 각 모델에 대한 혼동 행렬, 전체 오류 및 평균 클래스 오류를 볼 수 있습니다. 또한 ROC 곡선을 그림으로 나타내고, 민감도 분석을 실행하고, 다른 유형의 모델 평가를 수행할 수도 있습니다.
모델 빌드가 완료된 후 로그 탭을 선택하면 세션 동안 Rattle이 실행한 R 코드를 볼 수 있습니다. 내보내기 단추를 선택하여 저장할 수 있습니다.
참고 항목
현재 릴리스의 Rattle에는 버그가 포함되어 있습니다. 스크립트를 수정하거나 나중에 단계를 반복하여 사용하려면 로그 텍스트의 Export this log ... 앞에 # 문자를 삽입해야 합니다.
PostgreSQL 및 SQuirreL SQL
DSVM은 PostgreSQL이 설치된 상태로 제공됩니다. PostgreSQL은 정교한 오픈 소스 관계형 데이터베이스입니다. 이 섹션에서는 PostgreSQL에 spambase 데이터 세트를 로드한 다음 쿼리하는 방법을 보여 줍니다.
데이터를 로드하기 전에 먼저 localhost에서 암호 인증을 허용해야 합니다. 명령 프롬프트에서 다음을 실행합니다.
sudo gedit /var/lib/pgsql/data/pg_hba.conf
구성 파일의 아래쪽 몇 줄은 허용되는 연결을 자세히 설명하는 줄입니다.
# "local" is only for Unix domain socket connections:
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 ident
# IPv6 local connections:
host all all ::1/128 ident
사용자 이름 및 암호를 사용하여 로그인할 수 있도록 ident 대신 md5를 사용하도록 IPv4 local connections 줄을 변경합니다.
# IPv4 local connections:
host all all 127.0.0.1/32 md5
그런 다음 PostgreSQL 서비스를 다시 시작합니다.
sudo systemctl restart postgresql
PostgreSQL용 대화형 터미널인 psql을 기본 제공 postgres 사용자로 시작하려면 다음 명령을 실행합니다.
sudo -u postgres psql
로그인하는 데 사용한 Linux 계정의 사용자 이름을 사용하여 새 사용자 계정을 만듭니다. 암호를 만듭니다.
CREATE USER <username> WITH CREATEDB;
CREATE DATABASE <username>;
ALTER USER <username> password '<password>';
\quit
psql에 로그인합니다.
psql
데이터를 새 데이터베이스로 가져옵니다.
CREATE DATABASE spam;
\c spam
CREATE TABLE data (word_freq_make real, word_freq_address real, word_freq_all real, word_freq_3d real,word_freq_our real, word_freq_over real, word_freq_remove real, word_freq_internet real,word_freq_order real, word_freq_mail real, word_freq_receive real, word_freq_will real,word_freq_people real, word_freq_report real, word_freq_addresses real, word_freq_free real,word_freq_business real, word_freq_email real, word_freq_you real, word_freq_credit real,word_freq_your real, word_freq_font real, word_freq_000 real, word_freq_money real,word_freq_hp real, word_freq_hpl real, word_freq_george real, word_freq_650 real, word_freq_lab real,word_freq_labs real, word_freq_telnet real, word_freq_857 real, word_freq_data real,word_freq_415 real, word_freq_85 real, word_freq_technology real, word_freq_1999 real,word_freq_parts real, word_freq_pm real, word_freq_direct real, word_freq_cs real, word_freq_meeting real,word_freq_original real, word_freq_project real, word_freq_re real, word_freq_edu real,word_freq_table real, word_freq_conference real, char_freq_semicolon real, char_freq_leftParen real,char_freq_leftBracket real, char_freq_exclamation real, char_freq_dollar real, char_freq_pound real, capital_run_length_average real, capital_run_length_longest real, capital_run_length_total real, spam integer);
\copy data FROM /home/<username>/spambase.data DELIMITER ',' CSV;
\quit
이제 JDBC 드라이버를 통해 데이터베이스와 상호 작용하는 데 사용할 수 있는 그래픽 도구인 SQuirreL SQL을 사용하여 데이터를 탐색하고 일부 쿼리를 실행하겠습니다.
시작하려면 애플리케이션 메뉴에서 SQuirreL SQL을 엽니다. 드라이버를 설정하려면
- Windows>드라이버 보기를 선택합니다.
- PostgreSQL을 마우스 오른쪽 단추로 클릭하고 드라이버 수정을 선택합니다.
- 추가 클래스 경로>추가를 선택합니다.
- 파일 이름에 /usr/share/java/jdbcdrivers/postgresql-9.4.1208.jre6.jar을 입력합니다.
- 열기를 선택합니다.
- 드라이버 나열을 선택합니다. 클래스 이름에 대해 org.postgresql.Driver를 선택한 다음 확인을 선택합니다.
로컬 서버에 연결을 설정하려면
- Windows>별칭 보기를 선택합니다.
- + 단추를 선택하여 새 별칭을 만듭니다. 새 별칭 이름에 Spam database를 입력합니다.
- 드라이버에 대해 PostgreSQL을 선택합니다.
- URL을 jdbc:postgresql://localhost/spam으로 설정합니다.
- 사용자 이름 및 암호를 입력합니다.
- 확인을 선택합니다.
- 연결 창을 열려면 별칭 스팸 데이터베이스를 두 번 클릭합니다.
- 연결을 선택합니다.
일부 쿼리를 실행하려면
- SQL 탭을 선택합니다.
- SQL 탭 맨 위에 있는 쿼리 상자에
SELECT * from data;와 같은 기본 쿼리를 입력합니다. - Ctrl + Enter 키를 눌러 쿼리를 실행합니다. 기본적으로 SQuirreL SQL은 쿼리에서 처음 100개의 행을 반환합니다.
이 데이터를 탐색하기 위해 실행할 수 있는 훨씬 많은 쿼리가 있습니다. 예를 들어 스팸과 햄 간에 make 라는 단어의 빈도가 얼마나 차이가 있을까요?
SELECT avg(word_freq_make), spam from data group by spam;
또는 3d가 자주 포함되는 메일의 특징은 무엇일까요?
SELECT * from data order by word_freq_3d desc;
3d가 많이 나타나는 메일은 대부분 스팸으로 보입니다. 이 정보는 이메일을 분류하는 예측 모델을 작성하는 데 유용할 수 있습니다.
PostgreSQL 데이터베이스에 저장된 데이터를 사용하여 기계 학습을 수행하려면 MADlib을 사용하는 것이 좋습니다.
Azure Synapse Analytics(이전의 SQL DW)
Azure Synapse Analytics는 방대한 양의 관계형 및 비관계형 데이터를 처리할 수 있는 클라우드 기반 규모 스케일 아웃 데이터베이스입니다. 자세한 내용은 Azure Synapse Analytics란?을 참조하세요.
데이터 웨어하우스에 연결하고 테이블을 만들려면 명령 프롬프트에서 다음 명령을 실행합니다.
sqlcmd -S <server-name>.database.windows.net -d <database-name> -U <username> -P <password> -I
sqlcmd 프롬프트에서 다음 명령을 실행합니다.
CREATE TABLE spam (word_freq_make real, word_freq_address real, word_freq_all real, word_freq_3d real,word_freq_our real, word_freq_over real, word_freq_remove real, word_freq_internet real,word_freq_order real, word_freq_mail real, word_freq_receive real, word_freq_will real,word_freq_people real, word_freq_report real, word_freq_addresses real, word_freq_free real,word_freq_business real, word_freq_email real, word_freq_you real, word_freq_credit real,word_freq_your real, word_freq_font real, word_freq_000 real, word_freq_money real,word_freq_hp real, word_freq_hpl real, word_freq_george real, word_freq_650 real, word_freq_lab real,word_freq_labs real, word_freq_telnet real, word_freq_857 real, word_freq_data real,word_freq_415 real, word_freq_85 real, word_freq_technology real, word_freq_1999 real,word_freq_parts real, word_freq_pm real, word_freq_direct real, word_freq_cs real, word_freq_meeting real,word_freq_original real, word_freq_project real, word_freq_re real, word_freq_edu real,word_freq_table real, word_freq_conference real, char_freq_semicolon real, char_freq_leftParen real,char_freq_leftBracket real, char_freq_exclamation real, char_freq_dollar real, char_freq_pound real, capital_run_length_average real, capital_run_length_longest real, capital_run_length_total real, spam integer) WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = ROUND_ROBIN);
GO
bcp를 사용하여 데이터를 복사합니다.
bcp spam in spambaseHeaders.data -q -c -t ',' -S <server-name>.database.windows.net -d <database-name> -U <username> -P <password> -F 1 -r "\r\n"
참고 항목
다운로드한 파일에는 Windows 스타일 줄 끝이 포함됩니다. bcp 도구에는 Unix 스타일 줄 끝이 필요합니다. -r 플래그를 사용하여 bcp에 지시합니다.
그런 다음 sqlcmd를 사용하여 쿼리합니다.
select top 10 spam, char_freq_dollar from spam;
GO
SQuirreL SQL을 사용하여 쿼리할 수도 있습니다. SQL Server JDBC 드라이버를 사용하여 PostgreSQL과 유사한 단계를 수행합니다. JDBC 드라이버는 /usr/share/java/jdbcdrivers/sqljdbc42.jar 폴더에 있습니다.