복사 작업에서 데이터 웨어하우스 구성
이 문서에서는 데이터 파이프라인의 복사 작업을 사용하여 데이터 웨어하우스 간 데이터를 복사하는 방법을 간략하게 설명합니다.
지원되는 구성
복사 작업에서 각 탭의 구성에 대해 각각 다음 섹션으로 이동합니다.
일반
일반 탭 구성의 경우 일반으로 이동합니다.
Source
복사 작업에서 데이터 웨어하우스가 원본으로 지원되는 속성은 다음과 같습니다.
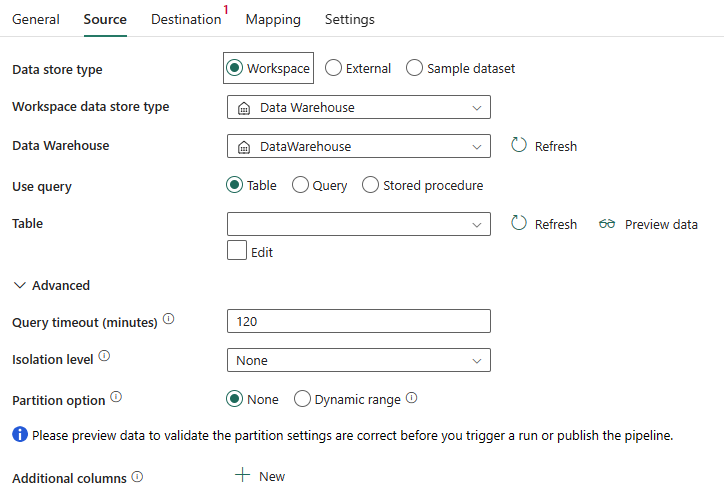
다음 속성이 필요합니다.
데이터 저장소 유형: 작업 영역을 선택합니다.
작업 영역 데이터 저장소 유형: 데이터 저장소 유형 목록에서 데이터 웨어하우스를 선택합니다.
데이터 웨어하우스: 작업 영역에서 기존 데이터 웨어하우스 를 선택합니다.
쿼리 사용: 테이블, 쿼리 또는 저장 프로시저를 선택합니다.
테이블을 선택하는 경우 테이블 목록에서 기존 테이블을 선택하거나 편집 상자를 선택하여 테이블 이름을 수동으로 지정합니다.

쿼리를 선택하는 경우 사용자 지정 SQL 쿼리 편집기를 사용하여 원본 데이터를 검색하는 SQL 쿼리를 작성합니다.

저장 프로시저를 선택하는 경우 드롭다운 목록에서 기존 저장 프로시저를 선택하거나 편집 상자를 선택하여 저장 프로시저 이름을 원본으로 지정합니다.

고급에서 다음 필드를 지정할 수 있습니다.
쿼리 시간 제한(분): 쿼리 명령 실행에 대한 시간 제한(기본값: 120분)입니다. 이 속성을 설정하면 허용되는 값은 "02:00:00"(120분)과 같은 시간 범위 형식입니다.
격리 수준: SQL 원본에 대한 트랜잭션 잠금 동작을 지정합니다.
파티션 옵션: 데이터 웨어하우스에서 데이터를 로드하는 데 사용되는 데이터 분할 옵션을 지정합니다. 없음 또는 동적 범위를 선택할 수 있습니다.
동적 범위를 선택하는 경우 병렬 사용 쿼리를 사용할 때 범위 파티션 매개 변수(
?AdfDynamicRangePartitionCondition)가 필요합니다. 샘플 쿼리:SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition.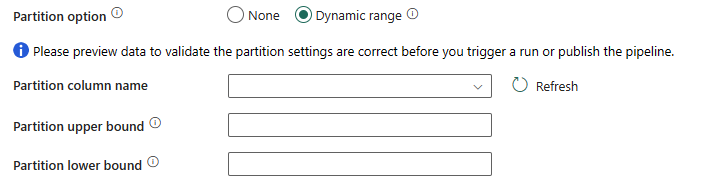
- 파티션 열 이름: 병렬 복사를 위해 범위 분할에 사용되는 정수 또는 date/datetime 형식(
int,,smallint,bigint,date,smalldatetime,datetime2datetime또는datetimeoffset)으로 원본 열의 이름을 지정합니다. 지정하지 않으면 테이블의 인덱스 또는 기본 키가 자동으로 검색되어 파티션 열로 사용됩니다. - 파티션 상한: 파티션 범위 분할에 대한 파티션 열의 최대값입니다. 이 값은 테이블의 행을 필터링하는 것이 아니라 파티션 진행 속도를 결정하는 데 사용됩니다. 테이블 또는 쿼리 결과의 모든 행이 분할되고 복사됩니다.
- 하한 파티션: 파티션 범위 분할에 대한 파티션 열의 최소값입니다. 이 값은 테이블의 행을 필터링하는 것이 아니라 파티션 진행 속도를 결정하는 데 사용됩니다. 테이블 또는 쿼리 결과의 모든 행이 분할되고 복사됩니다.
- 파티션 열 이름: 병렬 복사를 위해 범위 분할에 사용되는 정수 또는 date/datetime 형식(
추가 열: 원본 파일의 상대 경로 또는 정적 값을 저장할 추가 데이터 열을 추가합니다. 식은 후자에 대해 지원됩니다.


대상
복사 작업에서 Data Warehouse 가 대상으로 지원되는 속성은 다음과 같습니다.
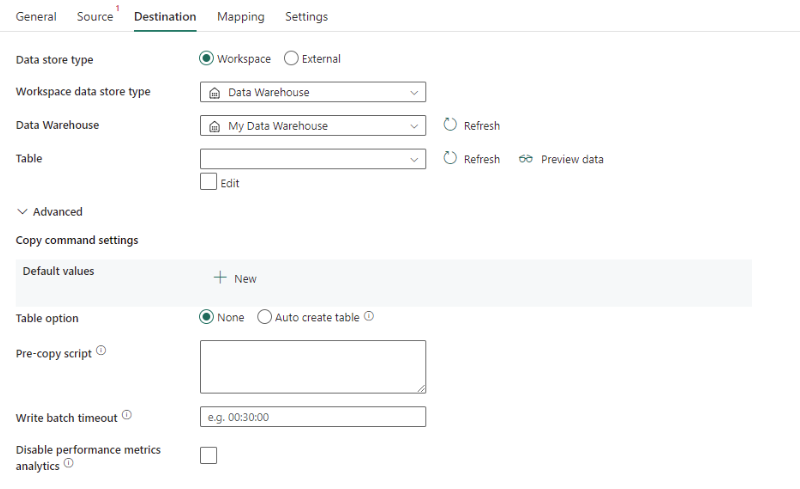
다음 속성이 필요합니다.
- 데이터 저장소 유형: 작업 영역을 선택합니다.
- 작업 영역 데이터 저장소 유형: 데이터 저장소 유형 목록에서 데이터 웨어하우스를 선택합니다.
- 데이터 웨어하우스: 작업 영역에서 기존 데이터 웨어하우스 를 선택합니다.
- 테이블: 테이블 목록에서 기존 테이블을 선택하거나 테이블 이름을 대상으로 지정합니다.
고급에서 다음 필드를 지정할 수 있습니다.
명령 설정 복사: 복사 명령 속성을 지정합니다.

테이블 옵션: 원본 스키마를 기반으로 하는 테이블이 없는 경우 대상 테이블을 자동으로 만들지 여부를 지정합니다. 없음 또는 자동 만들기 테이블을 선택할 수 있습니다.
사전 복사 스크립트: 각 실행에서 데이터 웨어하우스에 데이터를 쓰기 전에 실행할 SQL 쿼리를 지정합니다. 이 속성을 사용하여 미리 로드된 데이터를 정리합니다.
쓰기 일괄 처리 시간 제한: 시간 초과되기 전에 일괄 삽입 작업이 완료되기 위한 대기 시간입니다. 허용되는 값은 시간 범위 형식입니다. 기본값은 "00:30:00"(30분)입니다.
성능 메트릭 분석 사용 안 함: 서비스는 복사 성능 최적화 및 권장 사항에 대한 메트릭을 수집합니다. 이 동작에 관심이 있는 경우 이 기능을 해제합니다.
COPY 명령을 사용하여 직접 복사
Data Warehouse COPY 명령은 Azure Blob Storage 및 Azure Data Lake Storage Gen2를 원본 데이터 저장소로 직접 지원합니다. 원본 데이터가 이 섹션에 설명된 조건을 충족하는 경우 COPY 명령을 사용하여 원본 데이터 저장소에서 Data Warehouse로 직접 복사합니다.
원본 데이터 및 형식에는 다음과 같은 형식 및 인증 방법이 포함됩니다.
지원되는 원본 데이터 저장소 유형 지원되는 형식 지원되는 원본 인증 유형 Azure Blob Storage 구분된 텍스트
Parquet익명 인증
계정 키 인증
공유 액세스 서명 인증Azure Data Lake Storage Gen2 구분된 텍스트
Parquet계정 키 인증
공유 액세스 서명 인증다음 형식 설정을 지정할 수 있습니다.
- Parquet의 경우 압축 유형은 None, snappy 또는 gzip일 수 있습니다.
- DelimitedText의 경우:
- 행 구분 기호: 직접 COPY 명령을 통해 구분된 텍스트를 Data Warehouse에 복사할 때 행 구분 기호를 명시적으로 지정합니다(\r; \n; 또는 \r\n). 원본 파일의 행 구분 기호가 \r\n인 경우에만 기본값(\r, \n 또는 \r\n)이 작동합니다. 그렇지 않으면 시나리오에 대한 스테이징을 사용하도록 설정합니다.
- Null 값 은 기본값으로 남아 있거나 빈 문자열("")로 설정 됩니다.
- 인코딩은 기본값으로 남아 있거나 UTF-8 또는 UTF-16으로 설정됩니다.
- 건너뛰기 줄 수는 기본값으로 남아 있거나 0으로 설정됩니다.
- 압축 형식은 None 또는 gzip일 수 있습니다.
원본이 폴더인 경우 재귀적으로 검사box를 선택해야 합니다.
마지막으로 수정한 필터, 접두사, 파티션 검색 사용 및 추가 열의 시작 시간(UTC) 및 UTC(종료 시간)는 지정되지 않습니다.
COPY 명령을 사용하여 데이터 웨어하우스에 데이터를 수집하는 방법을 알아보려면 이 문서를 참조하세요.
원본 데이터 저장소 및 형식이 원래 COPY 명령에서 지원되지 않는 경우 COPY 명령 기능을 대신 사용하여 스테이징된 복사본을 사용합니다. 데이터를 COPY 명령 호환 형식으로 자동으로 변환한 다음 COPY 명령을 호출하여 데이터를 Data Warehouse로 로드합니다.
매핑
매핑 탭 구성의 경우 자동 만들기 테이블을 대상으로 데이터 웨어하우스를 적용하지 않으면 매핑으로 이동합니다.
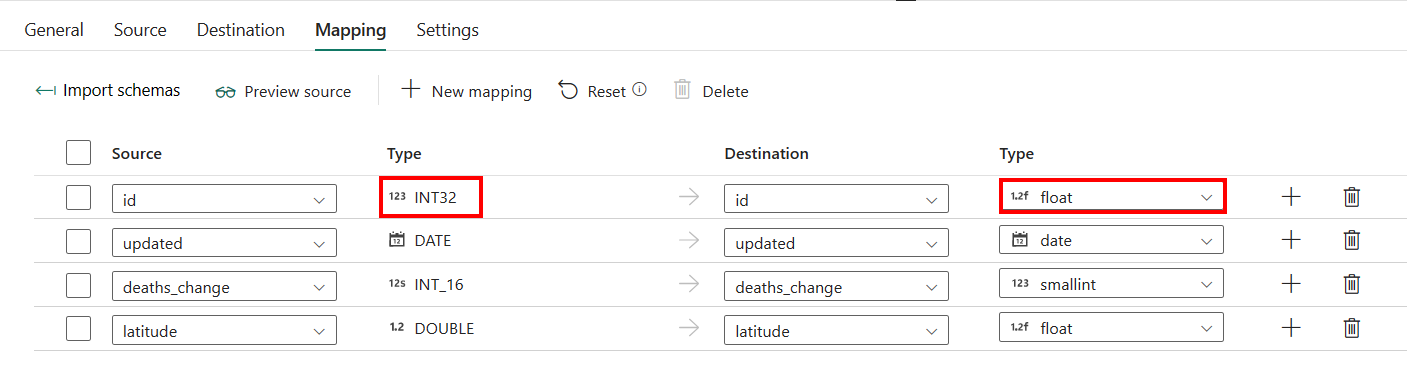
매핑의 구성을 제외하고 자동 만들기 테이블을 대상으로 데이터 웨어하우스를 적용하는 경우 대상 열의 형식을 편집할 수 있습니다. 스키마 가져오기를 선택한 후 대상에서 열 형식을 지정할 수 있습니다.
예를 들어 원본의 ID 열 형식은 int이며 대상 열에 매핑할 때 부동 형식으로 변경할 수 있습니다.
설정
설정 탭 구성의 경우 설정 이동합니다.
테이블 요약
다음 표에는 Data Warehouse의 복사 활동에 대한 자세한 정보가 포함되어 있습니다.
원본 정보
| 속성 | 설명 | 값 | Required | JSON 스크립트 속성 |
|---|---|---|---|---|
| 데이터 저장소 유형 | 데이터 저장소 유형입니다. | 작업 영역 | 예 | / |
| 작업 영역 데이터 저장소 유형 | 작업 영역 데이터 저장소 유형을 선택할 섹션입니다. | 데이터 웨어하우스 | 예 | type |
| 데이터 웨어하우스 | 사용하려는 데이터 웨어하우스입니다. | <데이터 웨어하우스> | 예 | endpoint artifactId |
| 쿼리 사용 | 데이터 웨어하우스에서 데이터를 읽는 방법입니다. | •테이블 •쿼리 • 저장 프로시저 |
아니요 | (-에서typeProperties>source)• typeProperties: schema(스키마) table • sqlReaderQuery • sqlReaderStoredProcedureName |
| 쿼리 시간 제한(분) | 쿼리 명령 실행에 대한 시간 제한(기본값은 120분)입니다. 이 속성을 설정하면 허용되는 값은 "02:00:00"(120분)과 같은 시간 범위 형식입니다. | timespan | 아니요 | queryTimeout |
| 격리 수준 | 원본에 대한 트랜잭션 잠금 동작입니다. | •없음 •스냅숏 |
아니요 | isolationLevel |
| 파티션 옵션 | 데이터 웨어하우스에서 데이터를 로드하는 데 사용되는 데이터 분할 옵션입니다. | •없음 • 동적 범위 |
아니요 | partitionOption |
| 파티션 열 이름 | 병렬 복사를 위해 범위 분할에 사용되는 정수 또는 date/datetime 형식(int, , bigintsmallint, date, smalldatetime, datetime, datetime2또는 datetimeoffset)의 원본 열 이름입니다. 지정하지 않으면 테이블의 인덱스 또는 기본 키가 자동으로 검색되어 파티션 열로 사용됩니다. |
<파티션 열 이름> | 아니요 | partitionColumnName |
| 파티션 상한 | 파티션 범위 분할에 대한 파티션 열의 최댓값입니다. 이 값은 테이블의 행을 필터링하는 것이 아니라 파티션 진행 속도를 결정하는 데 사용됩니다. 테이블 또는 쿼리 결과의 모든 행이 분할되고 복사됩니다. | <파티션 상한> | 아니요 | partitionUpperBound |
| 하한 파티션 | 파티션 범위 분할에 대한 파티션 열의 최솟값입니다. 이 값은 테이블의 행을 필터링하는 것이 아니라 파티션 진행 속도를 결정하는 데 사용됩니다. 테이블 또는 쿼리 결과의 모든 행이 분할되고 복사됩니다. | <파티션 하한> | 아니요 | partitionLowerBound |
| 추가 열 | 추가 데이터 열을 추가하여 원본 파일의 상대 경로 또는 정적 값을 저장합니다. | • 이름 •값 |
아니요 | additionalColumns: •이름 •값 |
대상 정보
| 속성 | 설명 | 값 | Required | JSON 스크립트 속성 |
|---|---|---|---|---|
| 데이터 저장소 유형 | 데이터 저장소 유형입니다. | 작업 영역 | 예 | / |
| 작업 영역 데이터 저장소 유형 | 작업 영역 데이터 저장소 유형을 선택할 섹션입니다. | 데이터 웨어하우스 | 예 | type |
| 데이터 웨어하우스 | 사용하려는 데이터 웨어하우스입니다. | <데이터 웨어하우스> | 예 | endpoint artifactId |
| 테이블 | 데이터를 쓸 대상 테이블입니다. | <대상 테이블의 이름> | 예 | 스키마 table |
| 명령 설정 복사 | 복사 명령 속성 설정입니다. 기본값 설정을 포함합니다. | 기본값: •열 •값 |
아니요 | copyCommand설정: defaultValues: •Columnname •Defaultvalue |
| 테이블 옵션 | 원본 스키마를 기반으로 하는 테이블이 없는 경우 대상 테이블을 자동으로 만들지 여부입니다. | •없음 • 테이블 자동 만들기 |
아니요 | tableOption: • autoCreate |
| 사전 복사 스크립트 | 각 실행에서 데이터 웨어하우스에 데이터를 쓰기 전에 실행할 SQL 쿼리입니다. 이 속성을 사용하여 미리 로드된 데이터를 정리합니다. | <사전 복사 스크립트> | 아니요 | preCopyScript |
| 쓰기 일괄 처리 시간 제한 | 시간 초과되기 전에 일괄 처리 삽입 작업이 완료되기까지의 대기 시간입니다. 허용되는 값은 시간 범위 형식입니다. 기본값은 "00:30:00"(30분)입니다. | timespan | 아니요 | writeBatchTimeout |
| 성능 메트릭 분석 사용 안 함 | 이 서비스는 복사 성능 최적화 및 권장 사항에 대한 메트릭을 수집하여 추가 마스터 DB 액세스를 도입합니다. | 선택 또는 선택 취소 | 아니요 | disableMetricsCollection: true 또는 false |
관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기