Spark를 사용하여 데이터 변환 및 SQL을 사용하여 쿼리
이 가이드에서는 다음을 수행합니다.
OneLake 파일 탐색기를 사용하여 OneLake에 데이터를 업로드합니다.
Fabric Notebook을 사용하여 OneLake에서 데이터를 읽고 델타 테이블로 다시 씁니다.
Fabric Notebook을 사용하여 Spark를 사용하여 데이터를 분석하고 변환합니다.
SQL을 사용하여 OneLake에서 데이터 복사본 하나를 쿼리합니다.
필수 조건
시작하기 전에 다음을 수행해야 합니다.
OneLake 파일 탐색기를 다운로드하여 설치합니다.
Lakehouse 항목을 사용하여 작업 영역을 만듭니다.
WideWorldImportersDW 데이터 세트를 다운로드합니다. Azure Storage Explorer를 사용하여 csv 파일 집합에 연결하고 다운로드할
https://azuresynapsestorage.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_city수 있습니다. 또는 사용자 고유의 csv 데이터를 사용하고 필요에 따라 세부 정보를 업데이트할 수 있습니다.
참고 항목
항상 Lakehouse의 테이블 섹션 바로 아래에 Delta-Parquet 데이터에 대한 바로 가기를 만들거나 로드하거나 만듭니다. 테이블 섹션 아래 의 하위 폴더에 테이블을 중첩하지 마세요. 레이크하우스가 테이블로 인식되지 않고 미확인 테이블로 레이블을 지정하기 때문에 테이블 섹션의 하위 폴더에 테이블을 중첩하지 마세요.
데이터 업로드, 읽기, 분석 및 쿼리
OneLake 파일 탐색기에서 레이크하우스로 이동하고 디렉터리 아래에서
/Files이름이 지정된dimension_city하위 디렉터리를 만듭니다.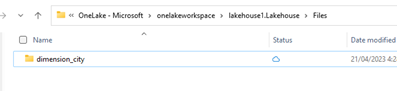
OneLake 파일 탐색기를 사용하여 샘플 csv 파일을 OneLake 디렉터리에
/Files/dimension_city복사합니다.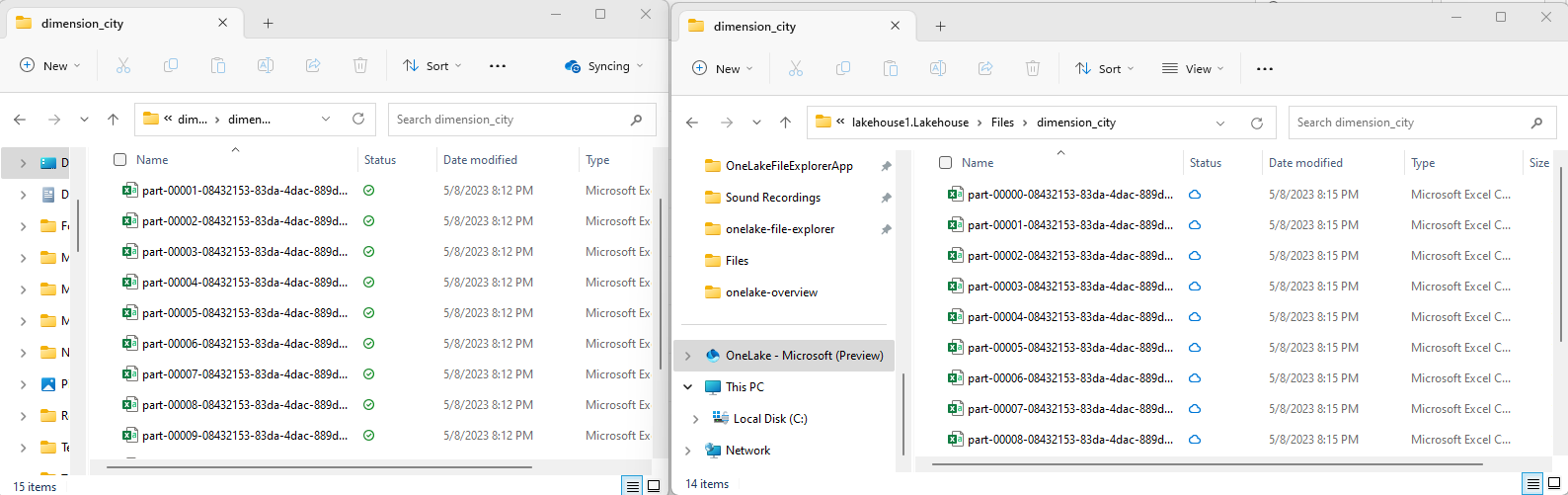
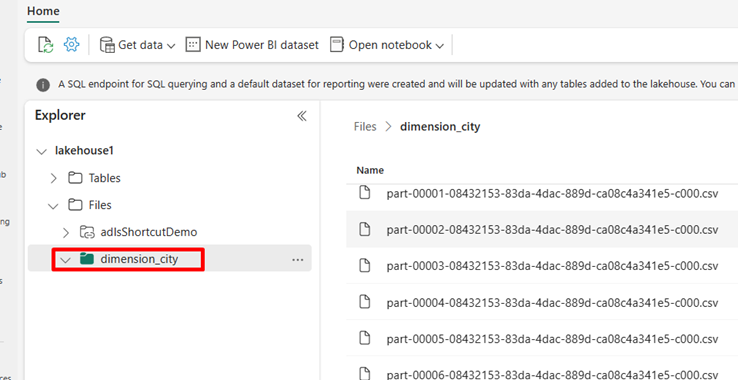
Power BI 서비스 레이크하우스로 이동하여 파일을 봅니다.
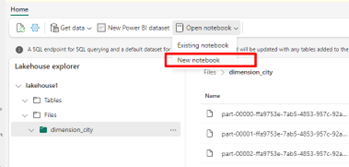
전자 필기장 열기를 선택한 다음 새 전자 필기장을 선택하여 전자 필기장을 만듭니다.
Fabric Notebook을 사용하여 CSV 파일을 델타 형식으로 변환합니다. 다음 코드 조각은 사용자가 만든 디렉터리
/Files/dimension_city에서 데이터를 읽고 델타 테이블dim_city로 변환합니다.import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")새 테이블을 보려면 디렉터리 보기를
/Tables새로 고칩니다.
동일한 Fabric Notebook에서 SparkSQL을 사용하여 테이블을 쿼리합니다.
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;데이터 형식 정수로 newColumn이라는 새 열을 추가하여 델타 테이블을 수정합니다. 새로 추가된 이 열의 모든 레코드에 대해 9 값을 설정합니다.
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;SQL 분석 엔드포인트를 통해 OneLake의 모든 델타 테이블에 액세스할 수도 있습니다. SQL 분석 엔드포인트는 OneLake에서 델타 테이블의 동일한 물리적 복사본을 참조하고 T-SQL 환경을 제공합니다. lakehouse1에 대한 SQL 분석 엔드포인트를 선택한 다음 새 SQL 쿼리를 선택하여 T-SQL을 사용하여 테이블을 쿼리합니다.
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];

관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기