자습서: Spark 작업을 사용하여 SQL Server 데이터 풀로 데이터 수집
적용 대상:![]() SQL Server 2019(15.x)
SQL Server 2019(15.x)
중요
Microsoft SQL Server 2019 빅 데이터 클러스터 추가 기능이 사용 중지됩니다. SQL Server 2019 빅 데이터 클러스터에 대한 지원은 2025년 2월 28일에 종료됩니다. Software Assurance를 사용하는 SQL Server 2019의 모든 기존 사용자는 플랫폼에서 완전히 지원되며, 소프트웨어는 지원 종료 시점까지 SQL Server 누적 업데이트를 통해 계속 유지 관리됩니다. 자세한 내용은 공지 블로그 게시물 및 Microsoft SQL Server 플랫폼의 빅 데이터 옵션을 참조하세요.
이 자습서에서는 Spark 작업을 사용하여 SQL Server 2019 빅 데이터 클러스터의 데이터 풀로 데이터를 수집하는 방법을 보여 줍니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- 데이터 풀에 외부 테이블을 만듭니다.
- HDFS에서 데이터를 로드하는 Spark 작업을 만듭니다.
- 외부 테이블에서 결과를 쿼리합니다.
팁
원하는 경우 이 자습서의 명령에 대한 스크립트를 다운로드하고 실행할 수 있습니다. 자세한 내용은 GitHub에서 데이터 풀 샘플을 참조하세요.
필수 조건
- 빅 데이터 도구
- kubectl
- Azure Data Studio
- SQL Server 2019 확장
- SQL Server 빅 데이터 클러스터에 샘플 데이터 로드
데이터 풀에서 외부 테이블 만들기
다음 단계에서는 web_clickstreams_spark_results라는 데이터 풀에 외부 테이블을 만듭니다. 그런 다음 이 테이블을 빅 데이터 클러스터로 데이터를 수집하기 위한 위치로 사용할 수 있습니다.
Azure Data Studio에서 사용자의 빅 데이터 클러스터의 SQL Server 마스터 인스턴스에 연결합니다. 자세한 내용은 SQL Server 마스터 인스턴스에 연결을 참조하세요.
서버 창에서 연결을 두 번 클릭하여 SQL Server 마스터 인스턴스의 서버 대시보드를 표시합니다. 새 쿼리를 선택합니다.
MSSQL-Spark 커넥터에 대한 사용 권한을 만듭니다.
USE Sales CREATE LOGIN sample_user WITH PASSWORD ='password123!#' CREATE USER sample_user FROM LOGIN sample_user -- To create external tables in data pools GRANT ALTER ANY EXTERNAL DATA SOURCE TO sample_user; -- To create external tables GRANT CREATE TABLE TO sample_user; GRANT ALTER ANY SCHEMA TO sample_user; -- To view database state for Sales GRANT VIEW DATABASE STATE ON DATABASE::Sales TO sample_user; ALTER ROLE [db_datareader] ADD MEMBER sample_user ALTER ROLE [db_datawriter] ADD MEMBER sample_user외부 데이터 원본이 존재하지 않는 경우 데이터 풀에 외부 데이터 원본을 만듭니다.
USE Sales GO IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlDataPool') CREATE EXTERNAL DATA SOURCE SqlDataPool WITH (LOCATION = 'sqldatapool://controller-svc/default');다음 단계에서는 web_clickstreams_spark_results라는 외부 테이블을 데이터 풀에 만듭니다.
USE Sales GO IF NOT EXISTS(SELECT * FROM sys.external_tables WHERE name = 'web_clickstreams_spark_results') CREATE EXTERNAL TABLE [web_clickstreams_spark_results] ("wcs_click_date_sk" BIGINT , "wcs_click_time_sk" BIGINT , "wcs_sales_sk" BIGINT , "wcs_item_sk" BIGINT , "wcs_web_page_sk" BIGINT , "wcs_user_sk" BIGINT) WITH ( DATA_SOURCE = SqlDataPool, DISTRIBUTION = ROUND_ROBIN );데이터 풀에 대한 로그인을 만들고 사용자에게 권한을 제공합니다.
EXECUTE( ' Use Sales; CREATE LOGIN sample_user WITH PASSWORD = ''password123!#'' ;') AT DATA_SOURCE SqlDataPool; EXECUTE('Use Sales; CREATE USER sample_user; ALTER ROLE [db_datareader] ADD MEMBER sample_user; ALTER ROLE [db_datawriter] ADD MEMBER sample_user;') AT DATA_SOURCE SqlDataPool;
데이터 풀 외부 테이블을 만드는 작업은 차단 작업입니다. 모든 백 엔드 데이터 풀 노드에서 지정된 테이블이 만들어질 때 컨트롤이 반환됩니다. 만들기 작업 중 실패가 발생한 경우 오류 메시지가 호출자에게 반환됩니다.
Spark 스트리밍 작업 시작
다음 단계는 HDFS(저장소 풀)로부터 데이터 풀에 만들었던 외부 테이블로 웹 클릭스트림 데이터를 로드하는 Spark 스트리밍 작업을 만드는 것입니다. 이 데이터는 빅 데이터 클러스터에 샘플 데이터 로드에서 /clickstream_data에 추가되었습니다.
Azure Data Studio에서 사용자의 빅 데이터 클러스터의 마스터 인스턴스에 연결합니다. 자세한 내용은 빅 데이터 클러스터에 연결을 참조하세요.
새 Notebook 만들기 및 Spark 선택 | Scala를 커널로 선택합니다.
Spark 수집 작업 실행
- Spark-SQL 커넥터 매개 변수 구성
참고 항목
빅 데이터 클러스터가 Active Directory 통합과 함께 배포된 경우 서비스 이름에 추가된 FQDN을 포함하도록 아래 호스트 이름의 값을 대체합니다. 예를 들어, hostname=master-p-svc.<domainName>입니다.
import org.apache.spark.sql.types._ import org.apache.spark.sql.{SparkSession, SaveMode, Row, DataFrame} // Change per your installation val user= "username" val password= "****" val database = "MyTestDatabase" val sourceDir = "/clickstream_data" val datapool_table = "web_clickstreams_spark_results" val datasource_name = "SqlDataPool" val schema = StructType(Seq( StructField("wcs_click_date_sk",LongType,true), StructField("wcs_click_time_sk",LongType,true), StructField("wcs_sales_sk",LongType,true), StructField("wcs_item_sk",LongType,true), StructField("wcs_web_page_sk",LongType,true), StructField("wcs_user_sk",LongType,true) )) val hostname = "master-p-svc" val port = 1433 val url = s"jdbc:sqlserver://${hostname}:${port};database=${database};user=${user};password=${password};"- Spark 작업 정의 및 실행
- 각 작업은 readStream과 writeStream의 두 부분입니다. 아래에서는 위에 정의된 스키마를 사용하여 데이터 프레임을 만든 다음 데이터 풀의 외부 테이블에 씁니다.
import org.apache.spark.sql.{SparkSession, SaveMode, Row, DataFrame} val df = spark.readStream.format("csv").schema(schema).option("header", true).load(sourceDir) val query = df.writeStream.outputMode("append").foreachBatch{ (batchDF: DataFrame, batchId: Long) => batchDF.write .format("com.microsoft.sqlserver.jdbc.spark") .mode("append") .option("url", url) .option("dbtable", datapool_table) .option("user", user) .option("password", password) .option("dataPoolDataSource",datasource_name).save() }.start() query.awaitTermination(40000) query.stop()
데이터 쿼리
다음 단계에서는 Spark 스트리밍 작업이 HDFS에서 데이터 풀로 데이터를 로드했음을 보여 줍니다.
수집한 데이터를 쿼리하기 전에 Yarn 앱 ID, Spark UI 및 드라이버 로그를 포함하는 Spark 실행 상태를 확인합니다. 이 정보는 Spark 애플리케이션을 처음 시작할 때 Notebook에 표시됩니다.
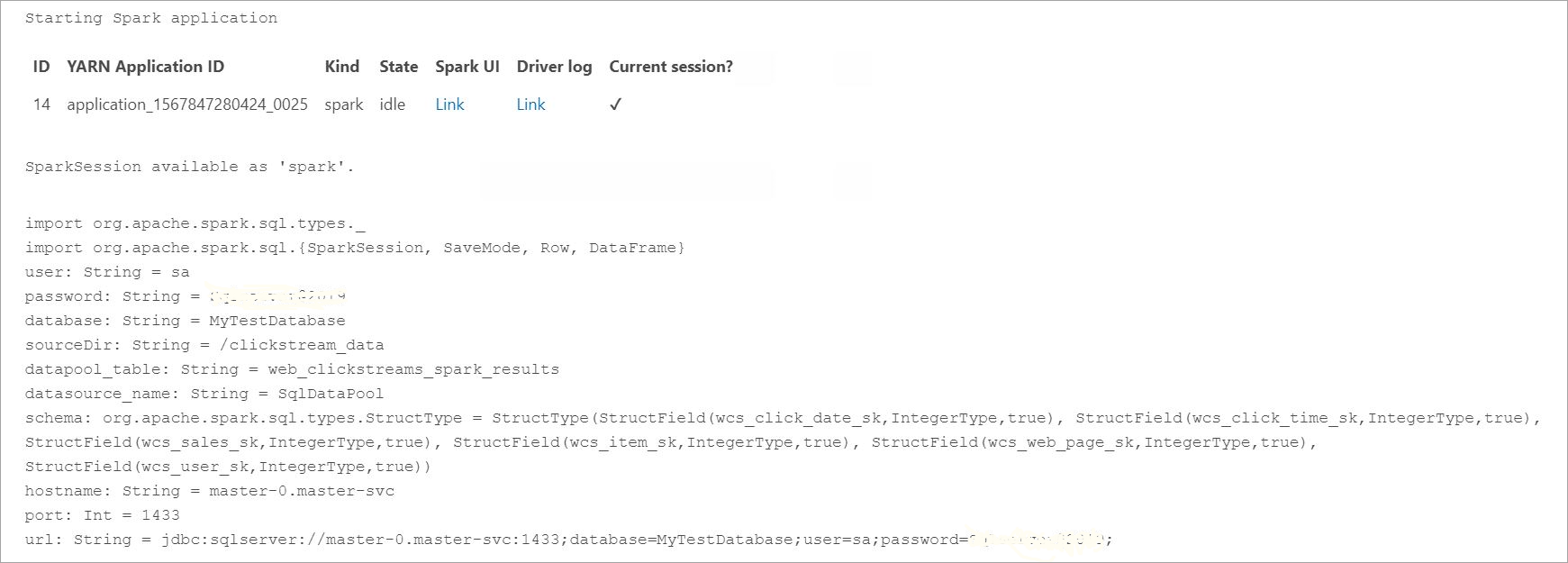
이 자습서의 시작 부분에서 열었던 SQL Server 마스터 인스턴스 쿼리 창으로 돌아갑니다.
다음 쿼리를 실행하여 수집된 데이터를 검사합니다.
USE Sales GO SELECT count(*) FROM [web_clickstreams_spark_results]; SELECT TOP 10 * FROM [web_clickstreams_spark_results];Spark에서 데이터를 쿼리할 수도 있습니다. 예를 들어 아래 코드는 테이블의 레코드 수를 출력합니다.
def df_read(dbtable: String, url: String, dataPoolDataSource: String=""): DataFrame = { spark.read .format("com.microsoft.sqlserver.jdbc.spark") .option("url", url) .option("dbtable", dbtable) .option("user", user) .option("password", password) .option("dataPoolDataSource", dataPoolDataSource) .load() } val new_df = df_read(datapool_table, url, dataPoolDataSource=datasource_name) println("Number of rows is " + new_df.count)
정리
다음 명령을 사용하여 이 자습서에서 만든 데이터베이스 개체를 제거합니다.
DROP EXTERNAL TABLE [dbo].[web_clickstreams_spark_results];
다음 단계
Azure Data Studio에서 샘플 Notebook을 실행하는 방법을 알아봅니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기