Python에서 히스토그램 그리기
적용 대상:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
이 문서에서는 Python 패키지 pandas'.hist()를 사용하여 데이터를 그리는 방법을 설명합니다. SQL 데이터베이스가 중복되지 않는 연속 값이 포함된 히스토그램 데이터 간격을 시각화하는 데 사용되는 원본입니다.
필수 구성 요소
샘플 데이터베이스를 Azure SQL Managed Instance로 복원하기 위한 SQL Server Management Studio.
Azure Data Studio. 설치하려면 Azure Data Studio를 참조하세요.
샘플 DW 데이터베이스를 복원하여 이 문서에서 사용되는 샘플 데이터를 가져옵니다.
복원된 데이터베이스 확인
Person.CountryRegion 테이블을 쿼리하여 복원된 데이터베이스가 있는지 확인할 수 있습니다.
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Python 패키지 설치
Azure Data Studio를 다운로드 및 설치합니다.
다음 Python 패키지를 설치합니다.
pyodbcpandassqlalchemymatplotlib
이러한 패키지를 설치하려면
- Azure Data Studio Notebook에서 패키지 관리를 선택합니다.
- 패키지 관리 창에서 새로 추가 탭을 선택합니다.
- 다음 패키지 각각에 대해 패키지 이름을 입력하고 검색을 선택한 다음 설치를 선택합니다.
히스토그램 그리기
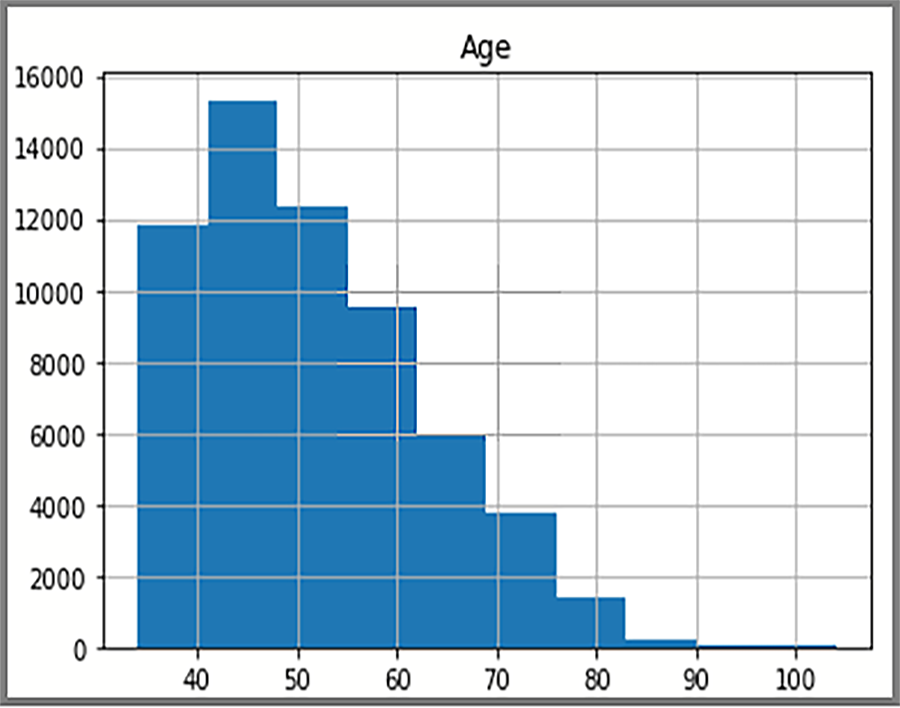
히스토그램에 표시되는 분산 데이터는 AdventureWorksDW2022의 SQL 쿼리를 기반으로 합니다. 이 히스토그램은 데이터와 데이터 값 빈도를 시각화합니다.
SQL Server 데이터베이스에 연결하기 위한 연결 문자열 변수 'server', 'database', 'username' 및 'password'를 편집합니다.
새 Notebook을 만들려면:
- Azure Data Studio에서 파일을 선택하고 새 Notebook을 선택합니다.
- Notebook에서 커널 Python3를 선택하고 +code를 선택합니다.
- Notebook에 코드를 붙여넣고 모두 실행을 선택합니다.
import pyodbc
import pandas as pd
import matplotlib
import sqlalchemy
from sqlalchemy import create_engine
matplotlib.use('TkAgg', force=True)
from matplotlib import pyplot as plt
# Some other example server values are
# server = 'localhost\sqlexpress' # for a named instance
# server = 'myserver,port' # to specify an alternate port
server = 'servername'
database = 'AdventureWorksDW2022'
username = 'yourusername'
password = 'databasename'
url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database)
engine = create_engine(url)
sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey"
df = pd.read_sql(sql, engine)
df.hist(bins=50)
plt.show()
이 표시에서는 FactInternetSales 테이블에 있는 고객의 연령 분포를 보여 줍니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기