힙(클러스터형 인덱스가 없는 테이블)
적용 대상:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
힙은 클러스터형 인덱스가 없는 테이블입니다. 힙으로 저장된 테이블에 하나 이상의 비클러스터형 인덱스를 만들 수 있습니다. 데이터는 순서를 지정하지 않고 힙에 저장됩니다. 일반적으로 데이터는 처음에 행이 테이블에 삽입되는 순서대로 저장되지만 데이터베이스 엔진은 행을 효율적으로 저장하기 위해 힙에서 데이터를 이동할 수 있습니다. 따라서 데이터 순서를 예측할 수 없습니다. 힙에서 반환된 행의 순서를 보장하려면 절을 ORDER BY 사용해야 합니다. 행을 저장하기 위한 영구 논리 순서를 지정하려면 테이블이 힙이 아니도록 테이블에 클러스터형 인덱스를 만듭니다.
참고 항목
클러스터형 인덱스를 만드는 대신 테이블을 힙으로 남겨 두는 좋은 이유가 있지만 힙을 효과적으로 사용하는 것은 고급 기술입니다. 테이블을 힙으로 남겨 두는 적절한 이유가 없는 한 대부분의 테이블에는 신중하게 선택된 클러스터형 인덱스가 있어야 합니다.
힙을 사용하는 경우
테이블이 힙으로 저장되면 개별 행은 파일 번호, 데이터 페이지 번호 및 페이지의 슬롯(FileID:PageID:SlotID)으로 구성된 RID(8 바이트 행 식별자)에 대한 참조로 식별됩니다. 행 ID는 작고 효율적인 구조입니다.
힙은 정렬되지 않은 대규모 삽입 작업의 준비 테이블로 사용할 수 있습니다. 엄격한 순서를 적용하지 않고 데이터가 삽입되기 때문에 삽입 작업은 일반적으로 클러스터형 인덱스에 대한 동등한 삽입보다 빠릅니다. 힙의 데이터를 읽고 최종 대상으로 처리하는 경우 읽기 쿼리에서 사용하는 검색 조건자를 포함하는 좁은 비클러스터형 인덱스 만들기가 유용할 수 있습니다.
참고 항목
데이터는 데이터 페이지 순서로 힙에서 검색되지만 반드시 데이터가 삽입된 순서는 아닙니다.
비클러스터형 인덱스를 통해 데이터에 항상 액세스하고 RID가 클러스터형 인덱스 키보다 작은 경우 데이터 전문가가 힙을 사용하는 경우도 있습니다.
테이블이 힙이고 비클러스터형 인덱스가 없는 경우 행을 찾으려면 전체 테이블을 읽어야 합니다(테이블 검색). SQL Server는 힙에서 직접 RID를 검색할 수 없습니다. 테이블이 작을 때 이 옵션을 사용할 수 있습니다.
힙을 사용하지 않는 경우
데이터가 정렬된 순서로 자주 반환되는 경우 힙을 사용하지 마세요. 정렬 열의 클러스터형 인덱스가 정렬 작업을 방지할 수 있습니다.
데이터가 자주 그룹화되는 경우 힙을 사용하지 마세요. 데이터를 그룹화하기 전에 정렬해야 하며 정렬 열의 클러스터형 인덱스는 정렬 작업을 방지할 수 있습니다.
테이블에서 데이터 범위를 자주 쿼리하는 경우 힙을 사용하지 마세요. 범위 열의 클러스터형 인덱스로 전체 힙을 정렬하지 않습니다.
지정된 순서 없이 전체 테이블 콘텐츠를 반환하지 않는 한 비클러스터형 인덱스가 없고 테이블이 큰 경우 힙을 사용하지 마세요. 힙에서 행을 찾으려면 힙의 모든 행을 읽어야 합니다.
데이터가 자주 업데이트되는 경우 힙을 사용하지 마세요. 레코드를 업데이트하고 업데이트에서 현재 사용 중인 것보다 데이터 페이지에 더 많은 공간을 사용하는 경우 충분한 여유 공간이 있는 데이터 페이지로 레코드를 이동해야 합니다. 이렇게 하면 데이터의 새 위치를 가리키는 전달된 레코드가 생성되고, 새 물리적 위치를 나타내도록 이전에 데이터가 있었던 페이지에 전달하는 포인터가 작성되어야 합니다. 이로 인해 힙이 조각화됩니다. 힙을 스캔할 때 이러한 포인터는 미리 읽기 성능을 제한하고 추가 I/O를 발생시켜 스캔 성능을 저하시킬 수 있는 다음을 따라야 합니다.
힙 관리
힙을 만들려면 클러스터형 인덱스가 없는 테이블을 만듭니다. 테이블에 이미 클러스터형 인덱스가 있는 경우 클러스터형 인덱스 삭제를 통해 테이블을 힙으로 반환합니다.
힙을 제거하려면 힙에 클러스터형 인덱스 만들기
불필요하게 사용된 공간을 회수하기 위해 힙을 다시 빌드하려면:
- 힙에서 클러스터형 인덱스를 만든 다음 해당 클러스터형 인덱스를 삭제합니다.
- 명령을
ALTER TABLE ... REBUILD사용하여 힙을 다시 빌드합니다.
경고
클러스터형 인덱스를 만들거나 삭제하려면 전체 테이블을 다시 작성해야 합니다. 테이블에 비클러스터형 인덱스가 포함되어 있는 경우 클러스터형 인덱스가 변경될 때마다 모든 비클러스터형 인덱스를 다시 만들어야 합니다. 따라서 힙을 클러스터형 인덱스 구조로 변경하거나 클러스터형 인덱스를 힙으로 변경하면 tempdb에서 데이터를 다시 정렬하는 데 많은 디스크 공간이 필요하고 많은 시간이 소요될 수 있습니다.
힙 구조체
힙은 클러스터형 인덱스가 없는 테이블입니다. 힙에는 sys.partitions에 하나의 행이 있으며 index_id = 0 , 각 파티션은 힙에서 사용됩니다. 기본적으로 힙에는 단일 파티션이 있습니다. 힙이 다중 파티션을 사용하는 경우 각 파티션은 해당 특정 파티션에 대한 데이터를 포함하는 힙 구조를 갖습니다. 예를 들어 힙에 4개의 파티션이 있는 경우 4개의 힙 구조가 있습니다. 각 파티션에 하나씩.
힙의 데이터 형식에 따라 각 힙 구조에는 특정 파티션에 대한 데이터를 저장하고 관리하는 하나 이상의 할당 단위가 있습니다. 최소한 각 힙에는 파티션당 하나의 IN_ROW_DATA 할당 단위가 있습니다. 또한 힙에 LOB(큰 개체) 열이 포함된 경우 파티션당 하나의 LOB_DATA 할당 단위가 있습니다. 8,060바이트 행 크기 제한을 초과하는 가변 길이 열이 포함된 경우 파티션당 하나의 ROW_OVERFLOW_DATA 할당 단위도 있습니다.
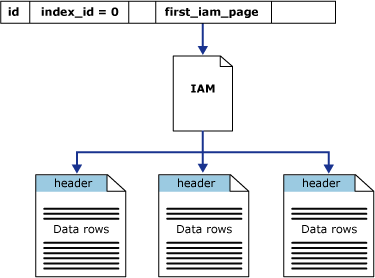
시스템 뷰의 sys.system_internals_allocation_units 열 first_iam_page 은 특정 파티션의 힙에 할당된 공간을 관리하는 IAM 페이지 체인의 첫 번째 IAM 페이지를 가리킵니다. SQL Server에서는 IAM 페이지를 사용하여 힙 간을 이동합니다. 데이터 페이지와 행 내의 행은 특정 순서가 아니며 연결되지 않습니다. 데이터 페이지 간의 유일한 논리적 연결은 IAM 페이지에 기록된 정보입니다.
Important
sys.system_internals_allocation_units 시스템 뷰는 SQL Server 내부용으로만 예약되어 있습니다. 향후 호환성은 보장되지 않습니다.
IAM을 검색하여 힙의 페이지를 보유하는 익스텐트를 찾음으로써 힙의 테이블 검색 또는 연속 읽기를 수행할 수 있습니다. IAM은 데이터 파일에 있는 것과 동일한 순서로 익스텐션을 나타내므로 직렬 힙은 각 파일을 순차적으로 검사합니다. 또한 IAM 페이지를 사용하여 스캔 시퀀스를 설정하면 힙의 행이 일반적으로 삽입된 순서대로 반환되지 않습니다.
다음 그림에서는 SQL Server 데이터베이스 엔진이 IAM 페이지를 사용하여 단일 파티션 힙에서 데이터 행을 검색하는 방법을 보여 줍니다.
관련 내용
CREATE INDEX(Transact-SQL)
DROP INDEX(Transact-SQL)
클러스터형 및 비클러스터형 인덱스 설명
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기