Azure Data Factory 변환 유형 설명
매핑 데이터 흐름은 데이터를 수정할 수 있는 여러 다양한 변환 유형을 제공합니다. 변환 유형은 다음 범주로 분류됩니다.
| 범주 이름 | 설명 |
|---|---|
| 스키마 한정자 변환 | 이 유형의 변환은 변환 작업을 기반으로 새 열을 생성하여 싱크 대상을 수정합니다. 이에 대한 예로는 기존 열에서 수행된 작업을 기반으로 새 열을 생성하는 파생 열 변환을 들 수 있습니다. |
| 행 한정자 변환 | 이 유형의 변환은 행이 대상에 표시되는 방식에 영향을 줍니다. 이에 대한 예로는 데이터를 정렬하는 정렬 변환을 들 수 있습니다. |
| 다중 입력/출력 변환 | 이 유형의 변환은 새 데이터 파이프라인을 생성하거나 파이프라인을 하나로 병합합니다. 이에 대한 예로는 여러 데이터 스트림을 결합하는 공용 구조체 변환을 들 수 있습니다. |
다음은 매핑 데이터 흐름에서 사용할 수 있는 변환 목록입니다.
| 이름 | 범주 | 설명 |
|---|---|---|
| 집계 | 스키마 한정자 | 기존 열 또는 계산 열로 그룹화된 SUM, MIN, MAX, COUNT와 같은 다양한 유형의 집계를 정의합니다. |
| 행 변경 | 행 한정자 | 행에 대한 삽입, 삭제, 업데이트 및 upsert 정책을 설정합니다. 일대다 조건을 식으로 추가할 수 있습니다. 일대다 조건은 각 행이 첫 번째로 일치하는 식에 해당하는 정책으로 표시되므로 우선 순위에 따라 지정해야 합니다. 각 조건으로 인해 하나의 행(또는 여러 행)이 삽입, 업데이트, 삭제 또는 upsert될 수 있습니다. 행 변경은 데이터베이스에 대해 DDL 작업과 DML 작업을 모두 생성할 수 있습니다. |
| 조건부 분할 | 다중 입력/출력 | 일치 조건에 따라 데이터 행을 서로 다른 스트림으로 라우팅합니다. |
| 파생 열 | 스키마 한정자 | 데이터 흐름 식 언어를 사용하여 새 열을 생성하거나 기존 필드를 수정합니다. |
| Exists | 다중 입력/출력 | 데이터가 다른 원본 또는 스트림에 있는지 확인합니다. |
| Filter | 행 한정자 | 조건에 따라 행을 필터링합니다. |
| 평면화(flatten) | 스키마 한정자 | JSON과 같은 계층 구조 내부의 배열 값을 가져와서 개별 행으로 언롤합니다. |
| Join | 다중 입력/출력 | 두 원본 또는 스트림의 데이터를 결합합니다. |
| 조회 | 다중 입력/출력 | 다른 원본의 데이터를 참조할 수 있습니다. |
| 새 분기 | 다중 입력/출력 | 동일한 데이터 스트림에 대해 여러 작업 및 변환 세트를 적용합니다. |
| 피벗 | 스키마 한정자 | 하나 이상의 그룹화 열에 개별 열로서 변환된 고유한 행 값이 있는 집계입니다. |
| Select | 스키마 한정자 | 열 및 스트림 이름의 별칭을 지정하고, 열을 삭제하거나 다시 정렬합니다. |
| 싱크 | - | 데이터의 최종 대상입니다. |
| Sort | 행 한정자 | 현재 데이터 스트림에서 들어오는 행을 정렬합니다. |
| 원본 | - | 데이터 흐름의 데이터 원본입니다. |
| 서로게이트 키 | 스키마 한정자 | 증가하는 업무 외 임의 키 값을 추가합니다. |
| Union | 다중 입력/출력 | 여러 데이터 스트림을 수직으로 결합합니다. |
| 피벗 해제 | 스키마 한정자 | 열을 행 값으로 피벗합니다. |
| 창 | 스키마 한정자 | 데이터 스트림에서 창 기반 열 집계를 정의합니다. |
데이터 흐름 식 작성기
정의할 수 있는 일부 변환에는 해당 상자에 데이터 흐름의 열, 필드, 변수, 매개 변수, 함수를 사용하여 변환 기능을 사용자 지정할 수 있는 데이터 흐름 식 작성기가 있습니다.
식을 작성하려면 변환 내의 식 텍스트 상자를 클릭할 때 시작되는 식 작성기를 사용합니다. 변환에 사용할 열을 선택할 때 “계산 열” 옵션이 표시되는 경우도 있습니다. 이 옵션을 클릭해도 식 작성기가 시작됩니다.
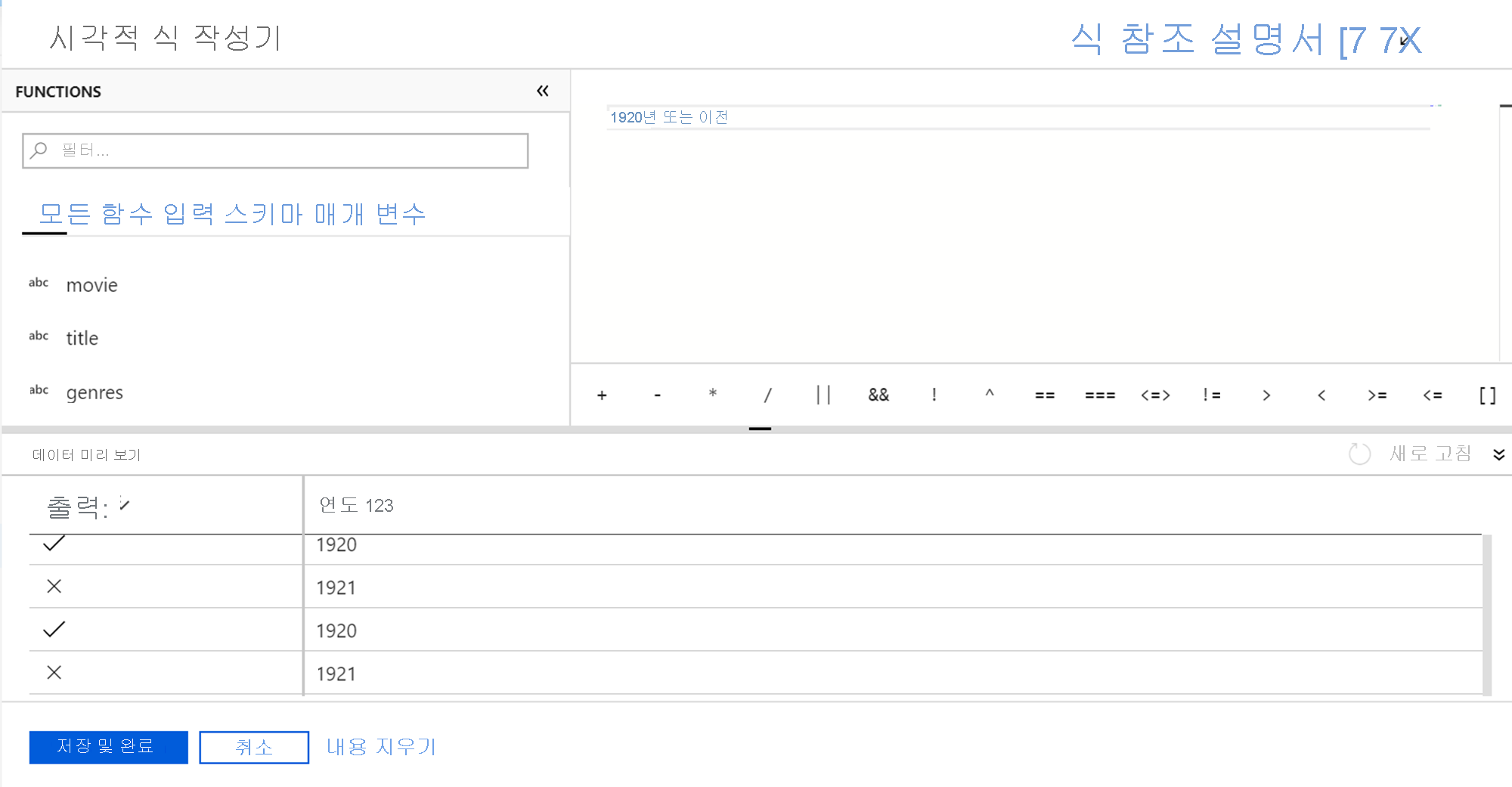
식 작성기 도구는 기본적으로 텍스트 편집기 옵션으로 설정되어 있습니다. 자동 완성 기능은 구문 검사 및 강조 표시를 사용하여 전체 Azure Data Factory Data Flow 개체 모델에서 읽어옵니다.