“연습 - Azure Data Factory 매핑 데이터 흐름 작성”
매핑 데이터 흐름을 사용하여 데이터 변환
매핑 데이터 흐름 태스크를 사용하여 Azure Data Factory에서 코드 없이 기본적으로 데이터 변환을 수행할 수 있습니다. 매핑 데이터 흐름은 코딩이 필요 없는 완벽한 시각적 환경을 제공합니다. 데이터 흐름은 스케일 아웃 데이터 처리를 위해 고유한 실행 클러스터에서 실행됩니다. 데이터 흐름 작업은 기존 Data Factory 일정, 제어, 흐름, 모니터링 기능을 통해 운용할 수 있습니다.
데이터 흐름을 빌드할 때 디버그 모드를 활성화하여 소규모 대화형 Spark 클러스터를 활성화할 수 있습니다. 작성 모듈 상단에 있는 슬라이더를 토글하여 디버그 모드를 활성화합니다. 디버그 클러스터는 준비하는 데 몇 분이 걸리지만 변환 논리의 출력을 대화형으로 미리 보는 데 사용할 수 있습니다.

매핑 데이터 흐름을 추가하고 Spark 클러스터를 실행하면 변환을 수행할 수 있으며 데이터를 실행하고 미리 볼 수 있습니다. Azure Data Factory는 모든 코드 변환, 경로 최적화 및 데이터 흐름 작업 실행을 처리하므로 코딩이 필요하지 않습니다.
매핑 데이터 흐름에 원본 데이터 추가
매핑 데이터 흐름 캔버스를 엽니다. 데이터 흐름 캔버스에서 원본 추가 단추를 클릭합니다. 원본 데이터세트 드롭다운에서 데이터 원본을 선택합니다. 이 예제에서는 ADLS Gen2 데이터세트를 사용합니다.
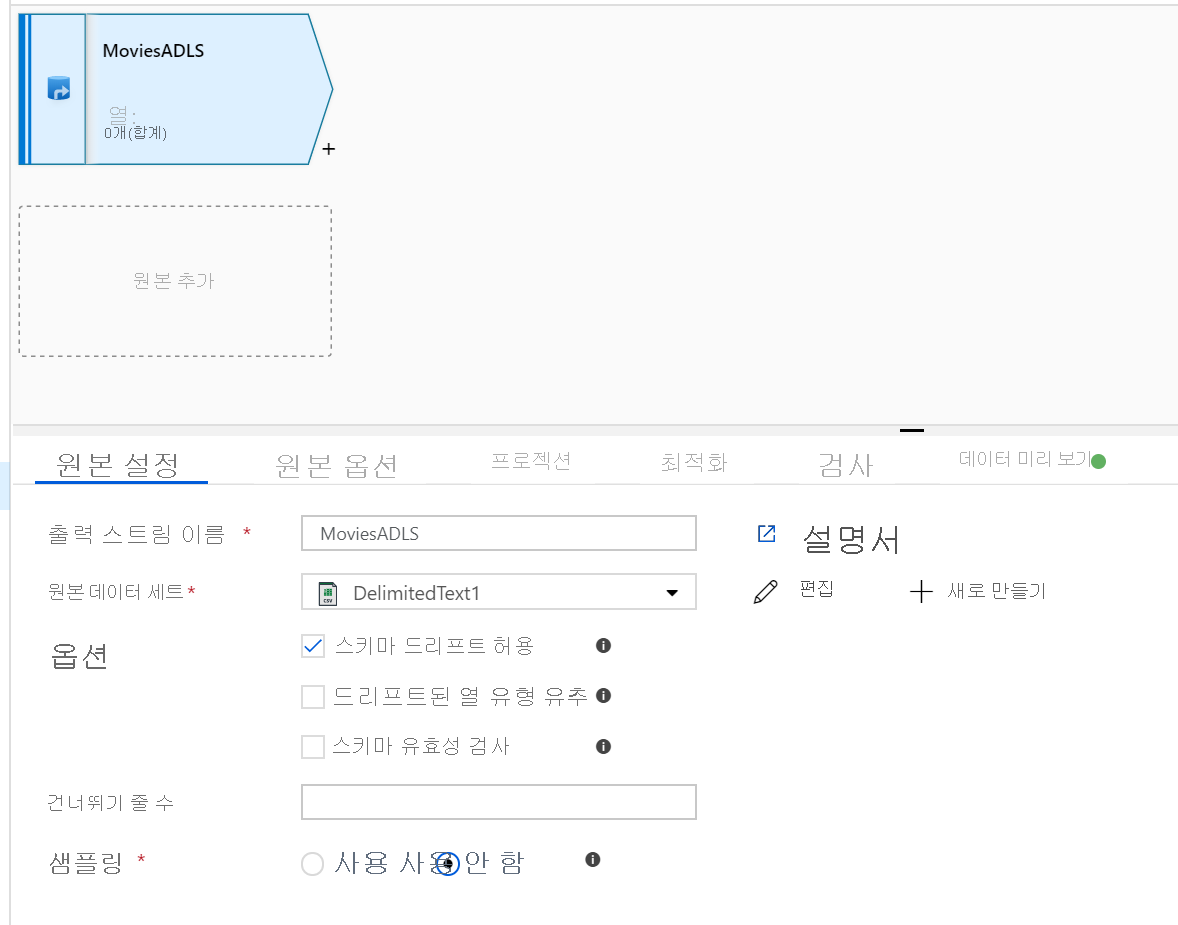
주의해야 할 몇 가지 사항이 있습니다.
- 데이터 세트는 다른 파일이 있는 폴더를 가리키는데 하나의 파일만 사용하고자 하는 경우에는 또 다른 데이터 세트를 생성하거나 매개 변수화를 활용하여 특정 파일만 읽도록 해야 할 수 있습니다.
- ADLS에서 스키마를 가져오지 않았지만 이미 데이터를 수집한 경우 데이터 흐름이 스키마 프로젝션을 인식하도록 데이터 세트의 ‘스키마’ 탭으로 이동하여 ‘스키마 가져오기’를 클릭합니다.
매핑 데이터 흐름은 ELT(추출, 로드, 변환) 접근 방식을 따르며 Azure에 모두 있는 준비 데이터 세트와 함께 작동합니다. 현재 원본 변환에서 다음 데이터 세트를 사용할 수 있습니다.
- Azure Blob Storage(JSON, Avro, 텍스트, Parquet)
- Azure Data Lake Storage Gen1(JSON, Avro, 텍스트, Parquet)
- Azure Data Lake Storage Gen2(JSON, Avro, 텍스트, Parquet)
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Azure Data Factory는 80개가 넘는 네이티브 커넥터에 액세스할 수 있습니다. 다른 원본의 데이터를 데이터 흐름에 포함하려면 복사 작업을 사용하여 지원되는 준비 영역 중 하나에 해당 데이터를 로드합니다.
디버그 클러스터가 준비되면 데이터 미리 보기 탭을 통해 데이터가 올바르게 로드되었는지 확인합니다. 새로 고침 단추를 클릭하면 매핑 데이터 흐름이 데이터가 각각의 변환 시에 어떻게 보이는지에 대한 스냅샷을 보여 줍니다.
매핑 데이터 흐름에서 변환 사용
데이터를 Azure Data Lake Store Gen2로 이동했으므로 이제 Spark 클러스터를 통해 데이터를 대규모로 변환한 후 데이터 웨어하우스에 로드하는 매핑 데이터 흐름을 빌드할 준비가 되었습니다.
이를 위한 주요 작업은 다음과 같습니다.
환경 준비
데이터 원본 추가
매핑 데이터 흐름 변환 사용
데이터 싱크에 쓰기
작업 1: 환경 준비
데이터 흐름 디버그 활성화. 작성 모듈 상단에 있는 데이터 흐름 디버그 슬라이더를 켭니다.
참고
데이터 흐름 클러스터는 준비하는 데 5~7분 정도 걸립니다.
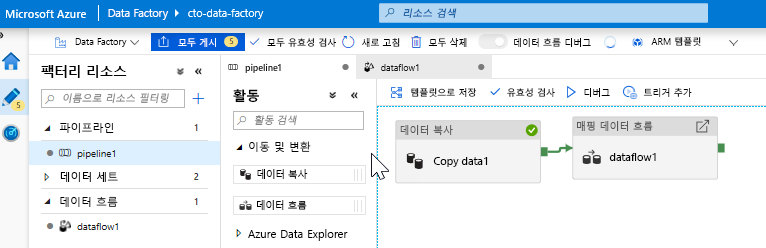
데이터 흐름 작업 추가. 작업 창에서 이동 및 변환 아코디언을 열고, 데이터 흐름 작업을 파이프라인 캔버스로 끌어서 놓습니다. 표시되는 블레이드에서 새 데이터 흐름 만들기를 클릭하고 매핑 데이터 흐름을 선택한 후 확인을 클릭합니다. pipeline1 탭을 클릭하고 복사 작업의 녹색 상자를 데이터 흐름 작업으로 끌어서 성공 조건을 만듭니다. 캔버스에 다음이 표시됩니다.
작업 2: 데이터 원본 추가
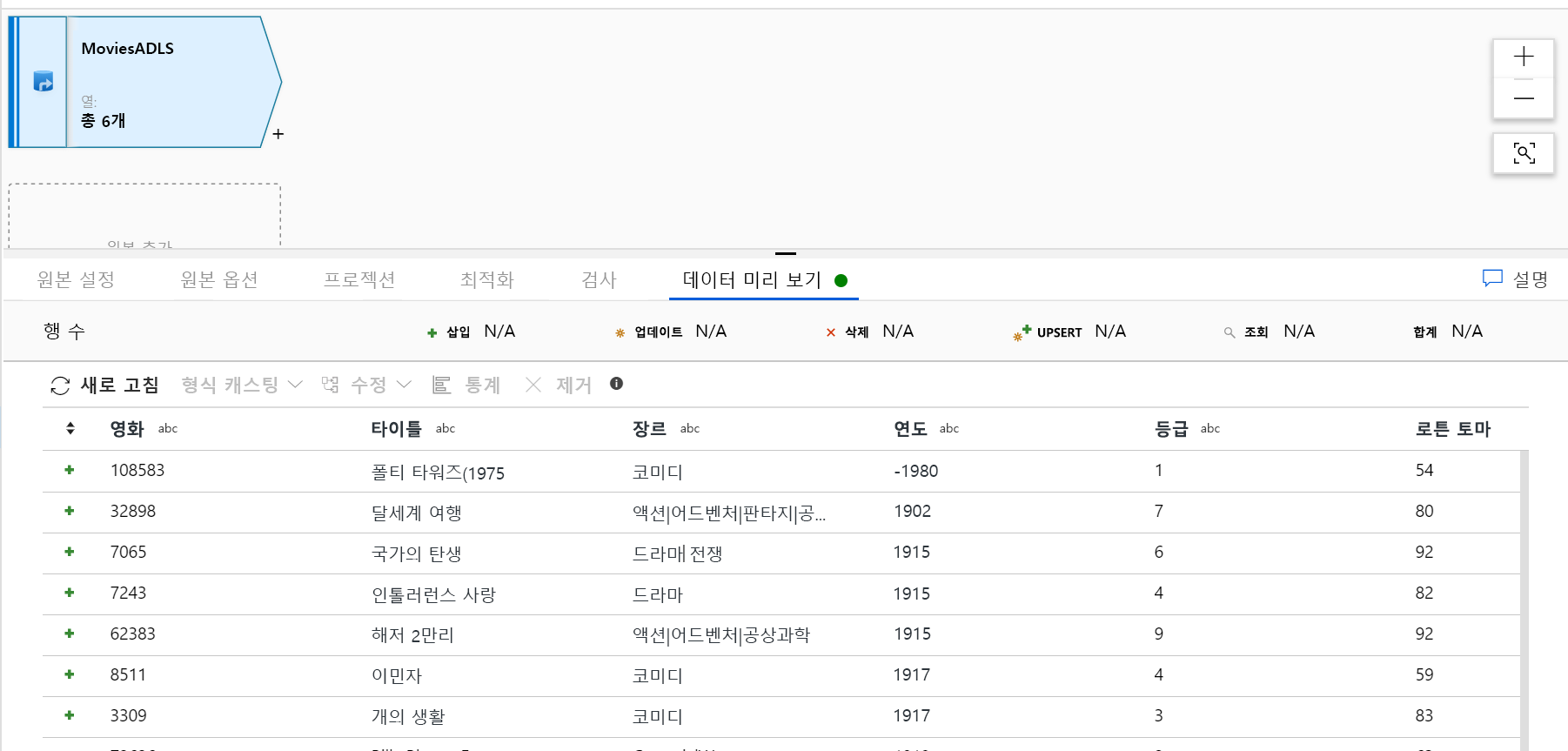
ADLS 원본 추가. 캔버스에서 매핑 데이터 흐름 개체를 두 번 클릭합니다. 데이터 흐름 캔버스에서 원본 추가 단추를 클릭합니다. 원본 데이터 세트 드롭다운에서 복사 작업에 사용된 ADLSG2 데이터 세트를 선택합니다.
- 데이터 세트가 다른 파일이 있는 폴더를 가리키는 경우 또 다른 데이터 세트를 생성하거나 매개 변수화를 활용하여 moviesDB.csv 파일만 읽도록 해야 할 수 있습니다.
- ADLS에서 스키마를 가져오지 않았지만 이미 데이터를 수집한 경우 데이터 흐름이 스키마 프로젝션을 인식하도록 데이터 세트의 ‘스키마’ 탭으로 이동하여 ‘스키마 가져오기’를 클릭합니다.
디버그 클러스터가 준비되면 데이터 미리 보기 탭을 통해 데이터가 올바르게 로드되었는지 확인합니다. 새로 고침 단추를 클릭하면 매핑 데이터 흐름이 데이터가 각각의 변환 시에 어떻게 보이는지에 대한 스냅샷을 보여 줍니다.
작업 3: 매핑 데이터 흐름 변환 사용
선택 변환을 추가하여 열 이름 바꾸기 및 열 삭제. 데이터 미리 보기에서 “Rotton Tomatoes” 열의 철자가 잘못된 것을 알 수 있습니다. 이름을 올바르게 지정하고 사용하지 않는 Rating 열을 삭제하려면 ADLS 원본 노드 옆에 있는 + 아이콘을 클릭하고 스키마 한정자에서 Select를 선택하여 선택 변환을 추가합니다.
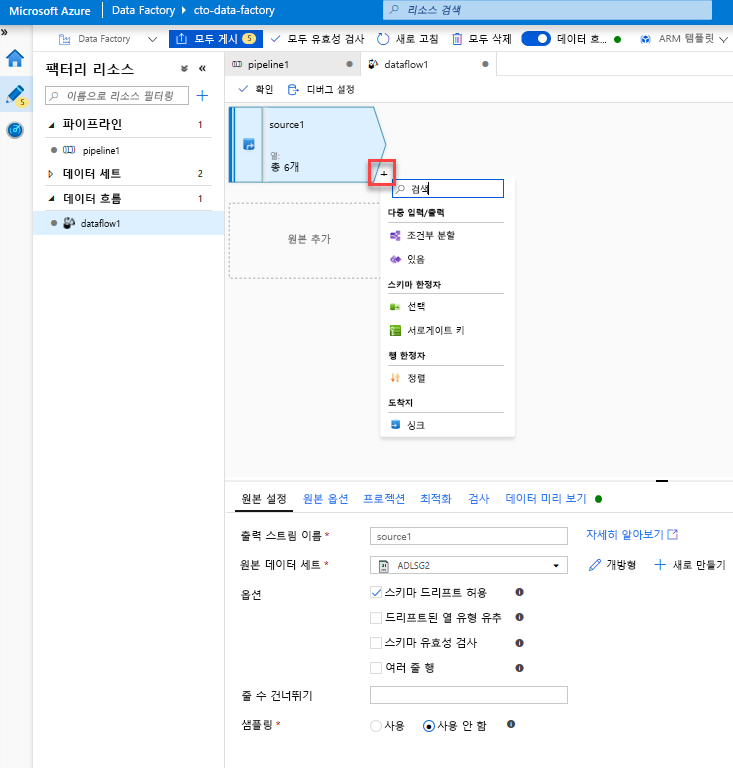
이름 필드에서 ‘Rotton’을 ‘Rotten’으로 변경합니다. Rating 열을 삭제하려면 해당 열을 마우스로 가리키고 휴지통 아이콘을 클릭합니다.
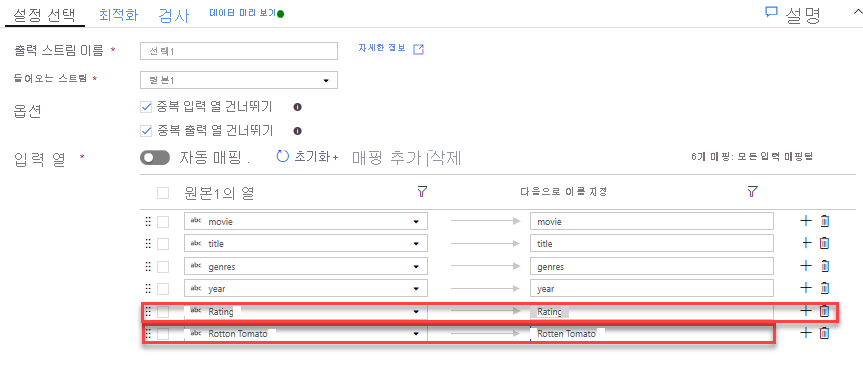
필터 변환을 추가하여 원치 않는 연도 필터링. 1951년 이후에 제작된 영화에만 관심이 있다고 가정해 보겠습니다. 선택 변환 옆에 있는 + 아이콘을 클릭하고 행 한정자에서 Filter를 선택하여 필터 변환을 추가해 필터 조건을 지정할 수 있습니다. 식 상자를 클릭하여 식 작성기를 열고 필터 조건을 입력합니다. 매핑 데이터 흐름 식 언어의 구문을 사용하여 toInteger(year) > 1950이라고 입력하면 문자열 연도 값을 정수로 변환하고 해당 값이 1950보다 크면 행을 필터링합니다.
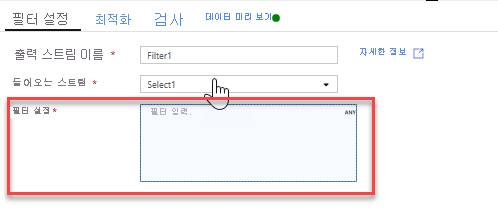
식 작성기에 포함된 데이터 미리 보기 창을 사용하여 조건이 제대로 작동하는지 확인할 수 있습니다.
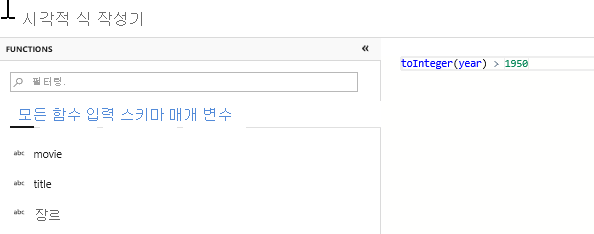
파생 변환을 추가하여 기본 장르 계산. 아시다시피, genres 열은 ‘|’ 문자로 구분된 문자열입니다. 각 열의 첫 번째 장르에만 관심이 있는 경우 필터 변환 옆에 있는 + 아이콘을 클릭하고 스키마 한정자에서 파생을 선택하여 파생 열 변환을 통해 PrimaryGenre라는 새 열을 파생시킬 수 있습니다. 필터 변환과 유사하게 파생 열은 매핑 데이터 흐름 식 작성기를 사용하여 새 열의 값을 지정합니다.

이 시나리오에서는 ‘genre1|genre2|...|genreN’으로 형식이 지정된 genres 열에서 첫 번째 장르를 추출하려고 합니다. locate 함수를 사용하여 장르 문자열에서 ‘|’의 첫 번째 1 기반 인덱스를 가져옵니다. iif 함수 사용 시, 이 인덱스가 1보다 크면 인덱스 왼쪽에 있는 문자열의 모든 문자를 반환하는 left 함수를 통해 기본 장르를 계산할 수 있습니다. 그렇지 않으면 PrimaryGenre 값은 장르 필드와 같습니다. 식 작성기의 데이터 미리 보기 창을 통해 출력을 확인할 수 있습니다.
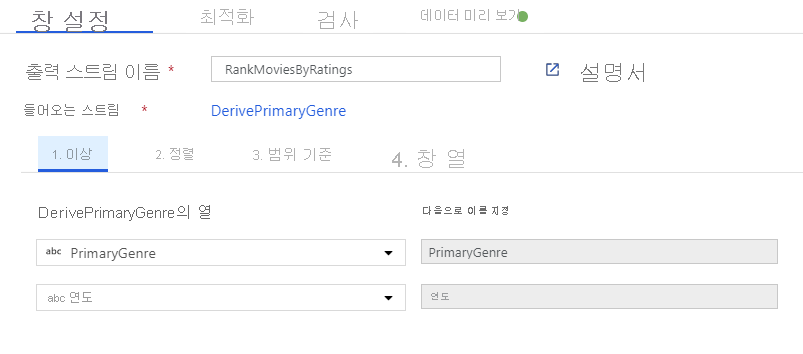
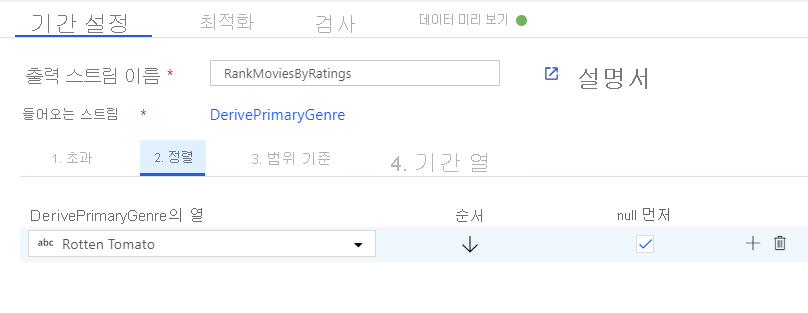
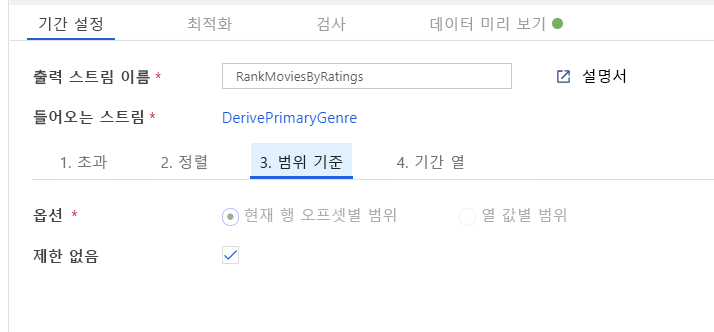
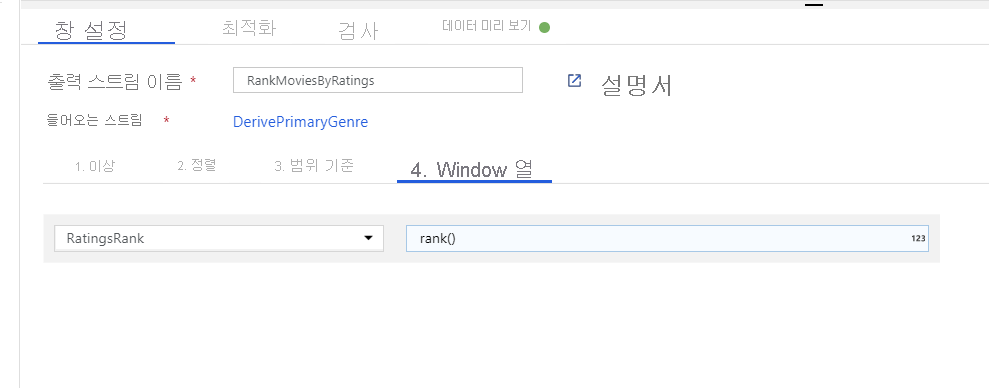
창 변환을 통해 영화 순위 지정. 영화가 특정 장르에서 해당 연도 내에 어떻게 순위가 지정되는지에 관심이 있다고 가정해 보겠습니다. 파생 열 변환 옆에 있는 + 아이콘을 클릭하고 스키마 한정자에서 Window를 클릭하여 창 변환을 추가해 창 기반 집계를 정의할 수 있습니다. 이를 수행하려면 창에 표시할 항목, 정렬 기준, 범위 및 새 창 열을 계산하는 방법을 지정합니다. 이 예에서는 제한 없는 범위로 PrimaryGenre 및 연도를 창에 표시하고, Rotten Tomato를 기준으로 내림차순 정렬하며, 각 영화의 특정 장르-연도 내 순위와 동일한 RatingsRank라는 새 열을 계산합니다.
집계 변환으로 평가 집계. 필요한 모든 데이터를 수집하고 파생시켰으므로 이제 창 변환 옆에 있는 + 아이콘을 클릭하고 스키마 한정자에서 집계를 클릭하여 집계 변환을 추가해 원하는 그룹을 기반으로 메트릭을 계산할 수 있습니다. 창 변환에서 했던 것처럼 PrimaryGenre 및 연도별로 영화를 그룹화할 수 있습니다.
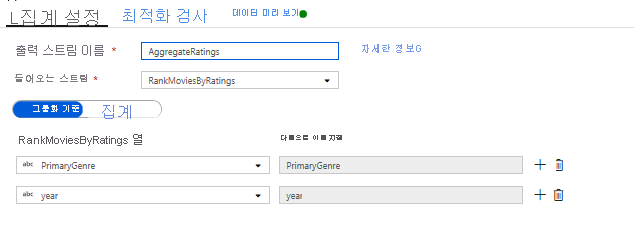
집계 탭에서는 지정된 열별 그룹화에 대해 계산된 집계를 만들 수 있습니다. 모든 장르 및 연도에 대해 평균 Rotten Tomatoes 평가, 최고 및 최저 평점 영화(창 작업 함수 활용), 각 그룹에 속한 영화 수를 가져옵니다. 집계는 변환 스트림의 행 수를 크게 줄이고 변환에 지정된 그룹화 방법 및 집계 열만 전파합니다.
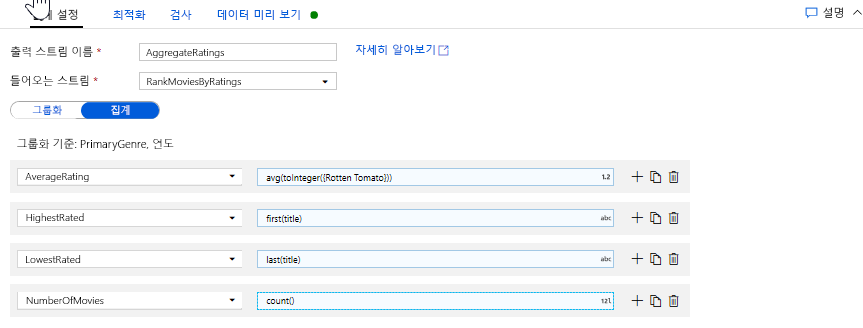
- 집계 변환이 데이터를 어떻게 변경하는지 확인하려면 데이터 미리 보기 탭을 사용합니다.
행 변경 변환을 통해 Upsert 조건 지정. 테이블 형식 싱크에 쓸 경우 집계 변환 옆의 + 아이콘을 클릭하고 행 한정자에서 행 변경을 클릭하여 행 변경 변환을 사용해 행에 대한 삽입, 삭제, 업데이트 및 upsert 정책을 지정할 수 있습니다. 항상 삽입 및 업데이트를 수행하므로 모든 행이 항상 upsert되도록 지정할 수 있습니다.

작업 4: 데이터 싱크에 쓰기
- Azure Synapse Analytics 싱크에 쓰기. 모든 변환 논리를 완료했으므로 이제 싱크에 쓸 준비가 되었습니다.
Upsert 변환 옆에 있는 + 아이콘을 클릭하고 대상에서 싱크를 클릭하여 싱크를 추가합니다.
싱크 탭에서 + 새로 만들기 단추를 통해 새로운 데이터 웨어하우스 데이터 세트를 만듭니다.
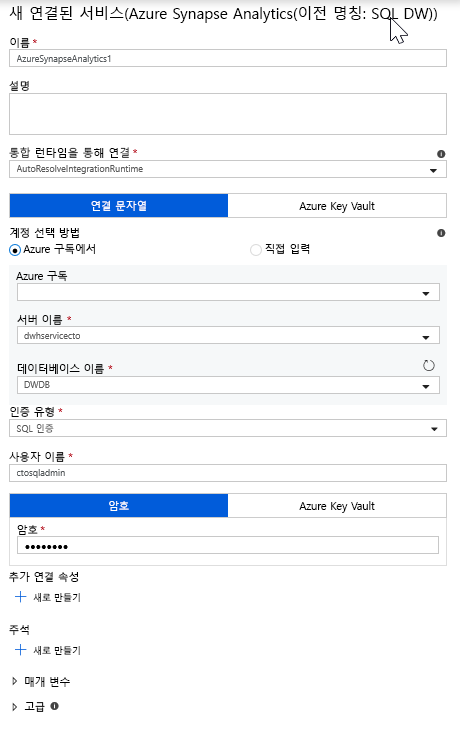
타일 목록에서 Azure Synapse Analytics를 선택합니다.
새 연결된 서비스를 선택하고 DWDB 데이터베이스에 연결하도록 Azure Synapse Analytics 연결을 구성합니다. 작업을 마쳤으면 만들기를 클릭합니다.
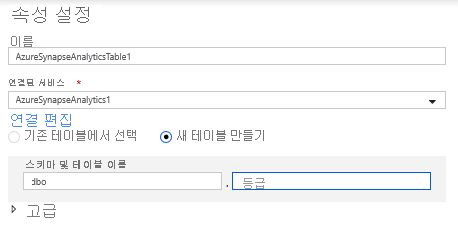
데이터 세트 구성에서 새 테이블 만들기를 선택하고 Dbo 스키마 및 Ratings 테이블 이름을 입력합니다. 완료되면 확인을 클릭합니다.
upsert 조건을 지정했으므로 설정 탭으로 이동하여 키 열인 PrimaryGenre 및 연도를 기반으로 ‘upsert 허용’을 선택해야 합니다.
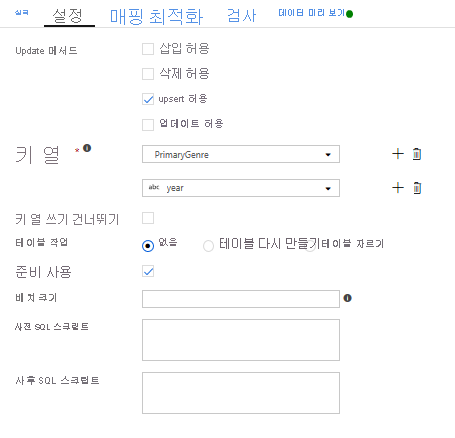
이제 8개의 변환 매핑 데이터 흐름 빌드를 완료했습니다. 파이프라인을 실행하고 결과를 확인할 시간입니다.

작업 5: 파이프라인 실행
캔버스에서 pipeline1 탭으로 이동합니다. 데이터 흐름의 Azure Synapse Analytics는 PolyBase를 사용하므로 BLOB 또는 ADLS 준비 폴더를 지정해야 합니다. 데이터 흐름 실행 작업의 설정 탭에서 PolyBase 아코디언을 열고 ADLS 연결된 서비스를 선택하고 준비 폴더 경로를 지정합니다.
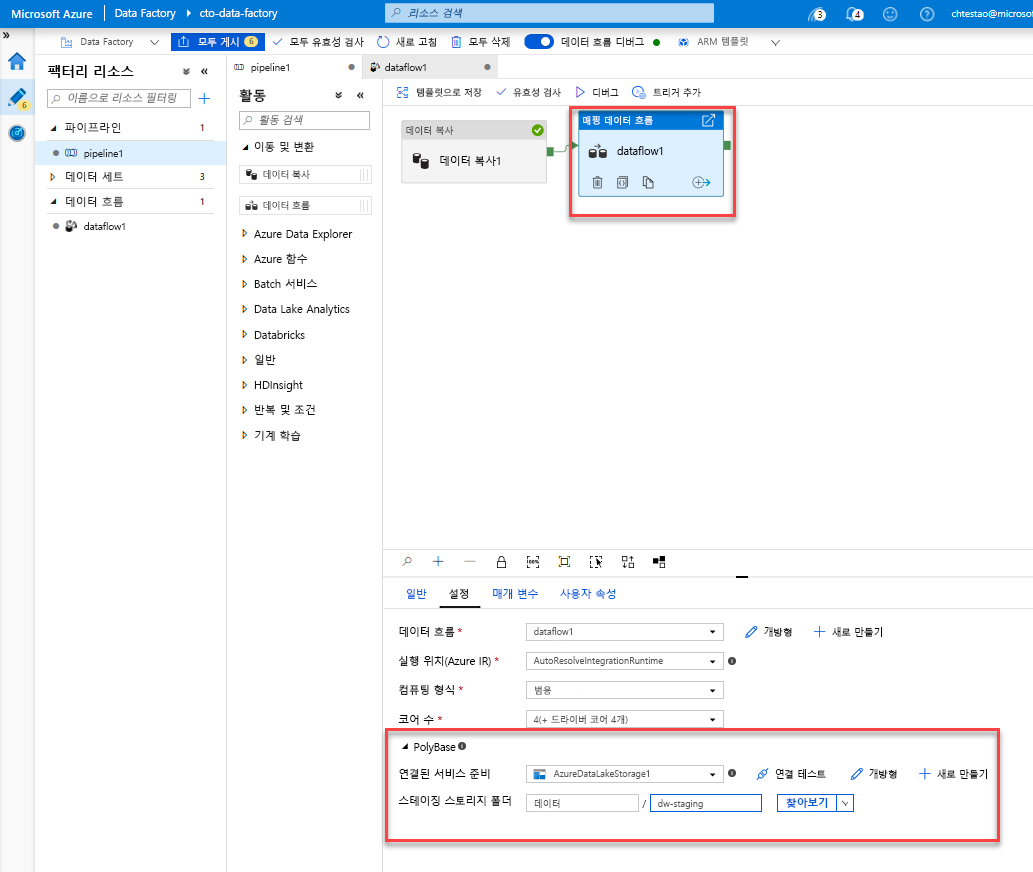
파이프라인을 게시하기 전에 먼저, 다른 디버그 실행을 실행하여 예상대로 작동하는지 확인합니다. 출력 탭을 살펴보면 실행 중인 두 작업의 상태를 모니터링할 수 있습니다.
두 작업이 모두 성공하면 데이터 흐름 작업 옆에 있는 안경 아이콘을 클릭하여 데이터 흐름 실행을 자세히 살펴볼 수 있습니다.
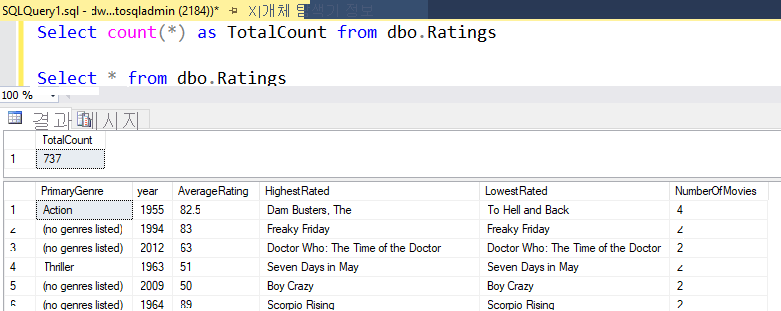
이 랩에서 설명한 것과 동일한 논리를 사용한 경우 데이터 흐름은 SQL DW에 737개의 행을 작성합니다. SQL Server Management Studio로 이동하여 파이프라인이 올바르게 작동하는지 확인하고 작성된 내용을 볼 수 있습니다.