Azure 데이터 에코시스템 이해
최신 분석에는 여러 원본으로부터 데이터를 저장하고 변환할 수 있는 도구가 필요합니다. 이 단원에서는 Azure 데이터 스토리지 솔루션, 데이터 수집 및 데이터 처리에 대해 알아봅니다.
Relecloud의 CEO에게 분석 솔루션을 제시하기 전에 데이터 팀은 데이터가 어디에서 오는지, 어떤 형식의 데이터가 있는지, 들어오는 데이터의 예상 규모 및 빈도를 명확하게 이해해야 합니다. 구조화된 요구 사항 수집을 수행하기 전에 팀과 함께 주요 데이터 개념을 검토합니다.
Azure 데이터 스토리지 솔루션
Azure Storage 계정은 Azure 내에서 사용되는 기본 스토리지 유형입니다. Azure Storage는 데이터 개체용으로 스케일링 가능한 개체 저장소, 클라우드의 파일 시스템 서비스를 제공합니다.
분석 솔루션에서는 다양한 원본의 데이터를 결합하고 사용할 준비를 합니다. 데이터는 데이터 레이크 저장소 또는 데이터베이스에 파일로 저장할 수 있습니다. 데이터 엔지니어는 Azure 내의 기본 스토리지 유형을 이해하는 것은 중요한 반면, 데이터 분석가는 분석 도구를 사용하여 쿼리할 수 있는 형식으로 처리된 데이터를 제공하는 분석 데이터 저장소에 익숙해야 합니다.
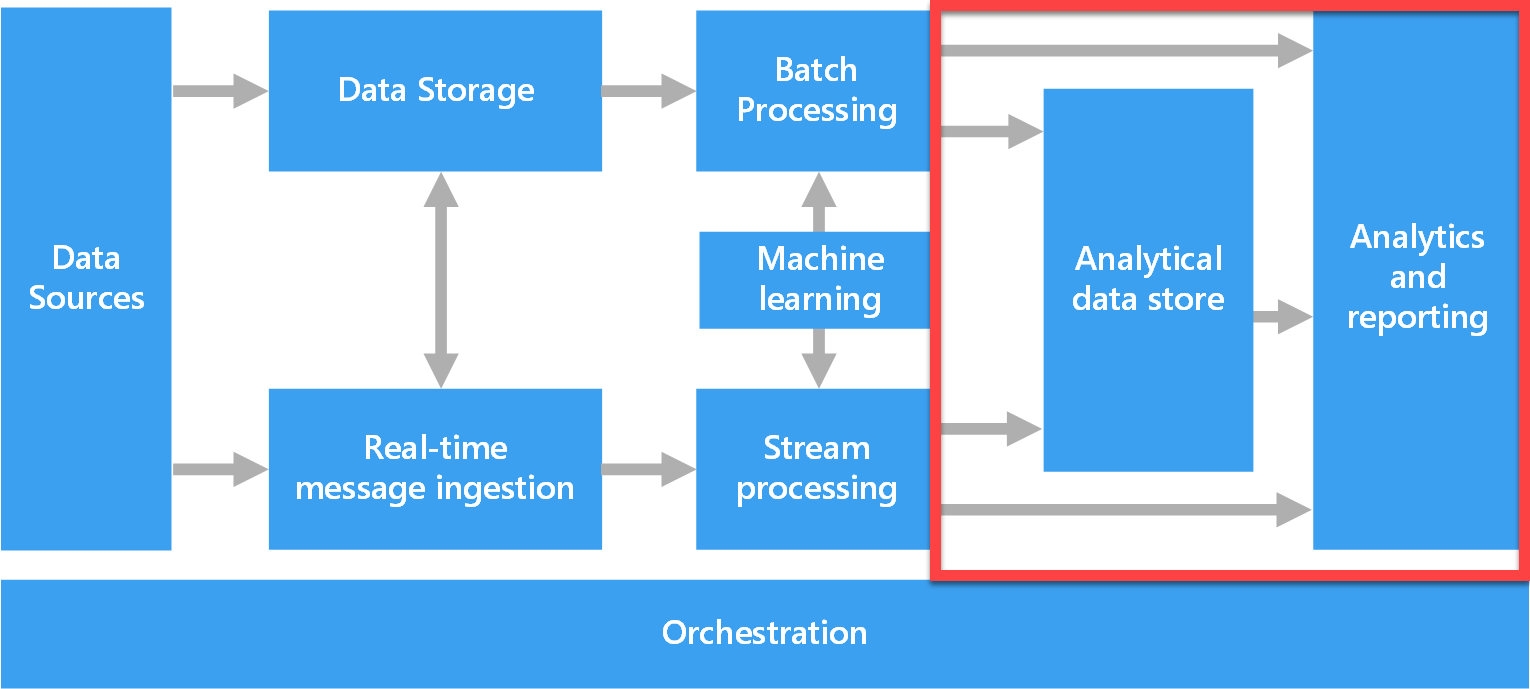
위의 이미지에서 빨간색으로 표시된 영역에는 데이터 분석가가 분석 솔루션에서 데이터를 이해하는 데 사용하는 부분이 강조 표시되어 있습니다.
참고
Azure의 데이터 스토리지 및 분석 데이터 저장소용 기술 선택에 대해 자세히 알아보세요.
데이터 수집 및 처리
데이터 수집은 데이터베이스에서 즉시 사용하거나 분석 데이터 저장소에 저장하기 위해 데이터를 획득하고 가져오는 프로세스입니다.
데이터 처리는 프로세스를 통해 원시 데이터를 의미 있는 정보로 변환하는 것입니다. 데이터를 시스템으로 수집하는 방법에 따라, 각 데이터 항목이 도착할 때마다 처리하거나 원시 데이터를 버퍼링한 다음 그룹으로 처리할 수도 있습니다. 도착할 때 데이터를 처리하는 것을 ‘스트리밍’이라고 합니다. 데이터를 버퍼링한 다음 그룹으로 처리하는 것을 ‘일괄 처리’라고 합니다.
일괄 처리에서는 새로 도착하는 데이터 요소가 그룹으로 수집됩니다. 그리고 전체 그룹은 추후 일괄처리됩니다. 각 그룹을 처리하는 정확한 시점을 여러 방법으로 결정할 수 있습니다. 예를 들어 예약된 시간 간격(예: 매시간)을 기준으로 데이터를 처리하거나 특정 양의 데이터가 도착했을 때 데이터 처리를 트리거할 수도 있습니다. Relecloud의 월별 청구 프로세스는 계정 트랜잭션이 매월 처리되고 청구되므로 일괄 처리의 좋은 예입니다.
참고
일괄 처리는 데이터 처리의 가장 일반적인 유형으로, 레거시 데이터 시스템에서 들어오는 대규모 데이터 세트 또는 데이터에 가장 적합합니다. 일괄 처리는 신속한 분석 및 의사 결정에 적합하지 않습니다.
스트림 처리에서는 각각의 새로운 데이터가 도착할 때마다 처리됩니다. 예를 들어 데이터 수집은 본질적으로 스트리밍 프로세스입니다.
스트리밍은 실시간으로 데이터를 처리합니다. 일괄 처리와 달리 다음 일괄 처리 주기까지 기다리지 않으며 데이터를 한 번에 일괄 처리하지 않고 개별 단위로 처리합니다. 스트리밍 데이터 처리는 새로운 동적 데이터가 지속적으로 생성되는 대부분의 시나리오에서 유용합니다.
사기 방지 부서에서는 스트림 처리를 사용하여 실시간 사기 및 변칙 검색을 처리합니다.
참고
스트림 처리는 실시간 분석이 필요한 프로젝트에 적합하고 복잡한 분석이 필요한 프로젝트에는 적합하지 않습니다.
데이터 처리는 일반적으로 분석 데이터 저장소의 업스트림에서 발생하지만, 분석가는 적절한 분석 솔루션을 빌드하기 위해 데이터가 수집되는 방식 및 빈도를 이해하는 것이 중요합니다.