테스트 및 학습 데이터 집합
모델을 학습하는 데 사용하는 데이터를 학습 데이터 집합이라고 합니다. 이 작업에서 이미 살펴보았습니다. 안타깝게도, 학습 후 모델을 실제 세계에서 사용할 때, 모델이 얼마나 잘 작동할지는 알 수 없습니다. 이러한 불확실성은 학습 데이터 집합이 실제 세계의 데이터와 다를 수 있기 때문입니다.
과대적합이란?
모델이 다른 데이터에서 수행하는 것 보다 학습 데이터에 대해 더 잘 작동하는 경우에는 과잉 맞춤이라고 합니다. 이 이름은 모델이 적합하다는 것을 의미하므로, 다른 데이터에 적용되는 광범위한 규칙을 찾는 것이 아니라, 학습 집합의 세부 정보를 기억합니다. 과잉 맞춤은 일반적이지만 이상적이지는 않습니다. 하루가 끝날 때, 모델이 실제 데이터에서 얼마나 잘 작동하는지에 주의합니다.
과잉 맞춤을 방지할 수 있는 방법은 무엇인가요?
다양한 방법으로 과잉 맞춤을 방지할 수 있습니다. 가장 간단한 방법은 모델을 좀 더 간단하게 생성하거나 실제 데이터 집합을 사용하는 것입니다. 이러한 방법을 이해하려면, 실제 데이터가 다음과 같은 시나리오를 고려해 보세요.
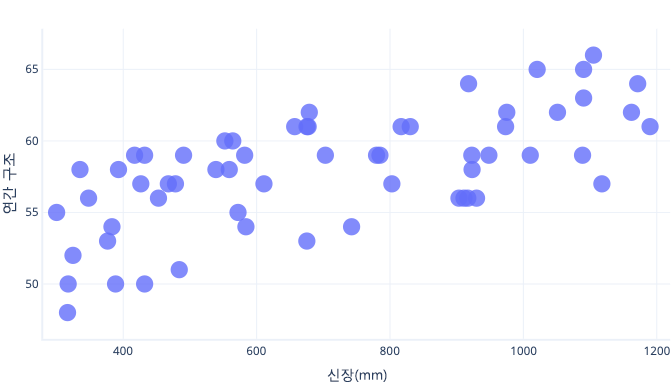
5마리의 개에게서만 정보를 수집하고 복합선에 맞게 학습 데이터 집합으로 사용하는 경우를 가정해 보겠습니다. 이것이 가능할 경우, 다음 경우에 대해 매우 적합할 수 있습니다.
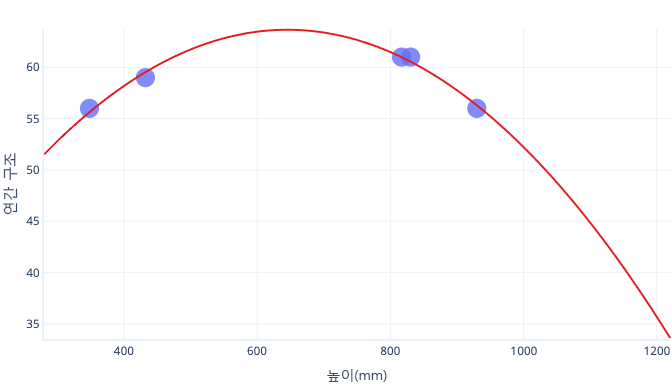
그러나 실제 세계에서 사용되는 경우, 잘못된 예측을 생성할 수 있습니다.
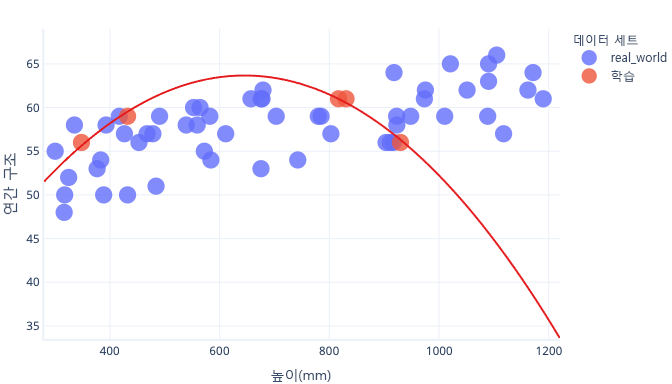
더 대표적인 데이터 집합 및 간단한 모델을 사용하는 경우, 이에 적합한 선은 완벽한 예측은 아니지만 더 나은 예측을 제공합니다.
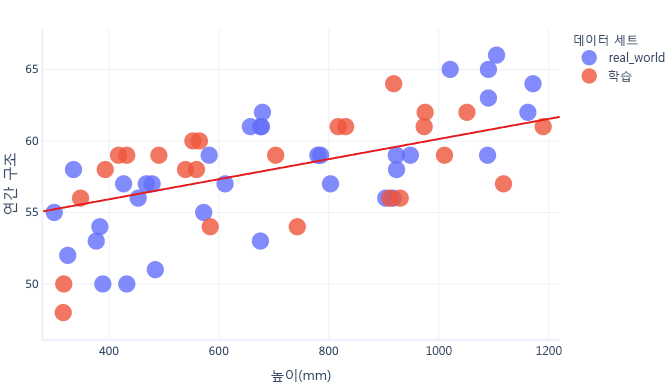
모델이 일반적인 규칙을 학습하고 과잉 맞춤이 되기 전에 학습을 중지하는 방법도 있습니다. 이를 수행하기 위해서는 모델이 과잉 맞춤이 되기 시작할 때 이를 탐지해야 합니다. 테스트 데이터 집합을 사용하여 이 작업을 수행할 수 있습니다.
테스트 데이터 집합이란?
유효성 검사 데이터 집합이라고도 하는 테스트 데이터 집합은 학습 데이터 집합과 유사한 데이터 집합입니다. 실제로 테스트 데이터 집합은 많은 데이터 집합을 가져와 분할하여 생성합니다. 한 부분은 학습 데이터 집합이라고 하고 다른 부분은 테스트 데이터 집합 이라고 합니다.
학습 데이터 집합의 역할은 모델을 학습시키는 것입니다. 학습에 대해서는 이미 살펴보았습니다. 테스트 데이터 집합의 역할은 모델이 얼마나 잘 작동하는지 확인하는 것입니다. 이는 학습에 직접 기여하지 않습니다.
중요한 점이 무엇인가요?
테스트 데이터 집합에 있어 중요한 점은 두 가지입니다.
첫째, 학습 중에 테스트 성능이 개선을 멈추는 경우, 계속하는 지점이 없도록 중지할 수 있습니다. 계속하는 경우, 모델이 테스트 데이터 집합에 없는 학습 데이터 집합에 대한 세부 정보를 학습하게 될 수 있습니다(과대적합).
두 번째로, 학습 후에 테스트 데이터 집합을 사용할 수 있습니다. 이를 통해, 전에 사용되지 않은 '실제 데이터'를 사용할 때 최종 모델이 얼마나 잘 작동하는지를 알 수 있습니다.
비용 함수는 무엇을 의미하나요?
학습 데이터 집합과 테스트 데이터 집합을 모두 사용하는 경우, 두 개의 비용 함수를 계산합니다.
첫 번째 비용 함수는 앞서 살펴본 것처럼 학습 데이터 집합을 사용합니다. 이 비용 함수는 최적화 프로그램에 공급되며 모델을 학습하는 데 사용됩니다.
두 번째 비용 함수는 테스트 데이터 집합을 사용하여 계산됩니다. 이는 모델이 실제 세계에서 얼마나 잘 작동하는지 확인하는 데 사용됩니다. 비용 함수의 결과는 모델을 학습시키는 데 사용되지 않습니다. 이를 계산하기 위해, 학습을 일시 중지하고, 테스트 데이터 집합에서 모델이 얼마나 잘 작동하고 있는지 확인 한 다음, 학습을 다시 시작합니다.