Azure Synapse Data Explorer data ingestion overview (Preview)
Data ingestion is the process used to load data records from one or more sources to import data into a table in Azure Synapse Data Explorer pool. Once ingested, the data becomes available for query.
The Azure Synapse Data Explorer data management service, which is responsible for data ingestion, implements the following process:
- Pulls data in batches or streaming from an external source and reads requests from a pending Azure queue.
- Batch data flowing to the same database and table is optimized for ingestion throughput.
- Initial data is validated and the format is converted where necessary.
- Further data manipulation including matching schema, organizing, indexing, encoding, and compressing the data.
- Data is persisted in storage according to the set retention policy.
- Ingested data is committed into the engine, where it's available for query.
Supported data formats, properties, and permissions
Ingestion properties: The properties that affect how the data will be ingested (for example, tagging, mapping, creation time).
Permissions: To ingest data, the process requires database ingestor level permissions. Other actions, such as query, may require database admin, database user, or table admin permissions.
Batching vs streaming ingestions
Batching ingestion does data batching and is optimized for high ingestion throughput. This method is the preferred and most performant type of ingestion. Data is batched according to ingestion properties. Small batches of data are merged and optimized for fast query results. The ingestion batching policy can be set on databases or tables. By default, the maximum batching value is 5 minutes, 1000 items, or a total size of 1 GB. The data size limit for a batch ingestion command is 4 GB.
Streaming ingestion is ongoing data ingestion from a streaming source. Streaming ingestion allows near real-time latency for small sets of data per table. Data is initially ingested to row store, then moved to column store extents.
Ingestion methods and tools
Azure Synapse Data Explorer supports several ingestion methods, each with its own target scenarios. These methods include ingestion tools, connectors and plugins to diverse services, managed pipelines, programmatic ingestion using SDKs, and direct access to ingestion.
Ingestion using managed pipelines
For organizations who wish to have management (throttling, retries, monitors, alerts, and more) done by an external service, using a connector is likely the most appropriate solution. Queued ingestion is appropriate for large data volumes. Azure Synapse Data Explorer supports the following Azure Pipelines:
- Event Hub: A pipeline that transfers events from services to Azure Synapse Data Explorer. For more information, see Ingest data from Event Hub into Azure Synapse Data Explorer.
- Synapse pipelines: A fully managed data integration service for analytic workloads in Synapse pipelines connects with over 90 supported sources to provide efficient and resilient data transfer. Synapse pipelines prepares, transforms, and enriches data to give insights that can be monitored in different kinds of ways. This service can be used as a one-time solution, on a periodic timeline, or triggered by specific events.
Programmatic ingestion using SDKs
Azure Synapse Data Explorer provides SDKs that can be used for query and data ingestion. Programmatic ingestion is optimized for reducing ingestion costs (COGs), by minimizing storage transactions during and following the ingestion process.
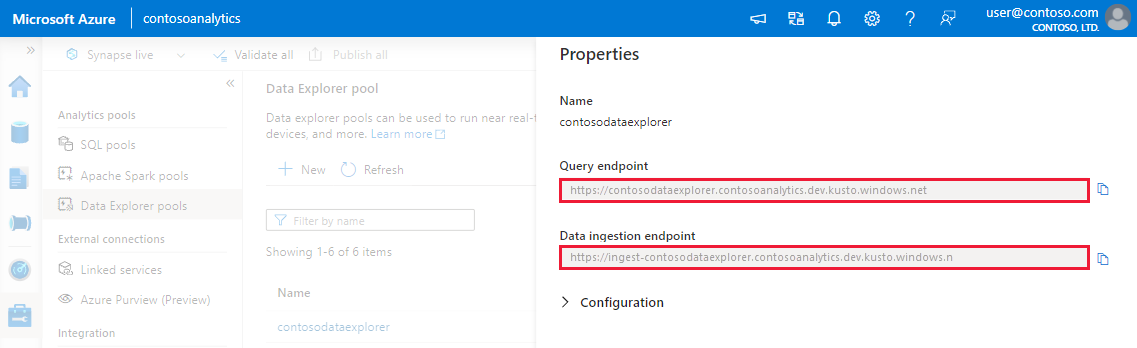
Before you start, use the following steps to get the Data Explorer pool endpoints for configuring programmatic ingestion.
In Synapse Studio, on the left-side pane, select Manage > Data Explorer pools.
Select the Data Explorer pool you want to use to view its details.
Make a note of the Query and Data Ingestion endpoints. Use the Query endpoint as the cluster when configuring connections to your Data Explorer pool. When configuring SDKs for data ingestion, use the data ingestion endpoint.
Available SDKs and open-source projects
Tools
- One-click ingestion: Enables you to quickly ingest data by creating and adjusting tables from a wide range of source types. One-click ingestion automatically suggests tables and mapping structures based on the data source in Azure Synapse Data Explorer. One-click ingestion can be used for one-time ingestion, or to define continuous ingestion via Event Grid on the container to which the data was ingested.
Kusto Query Language ingest control commands
There are a number of methods by which data can be ingested directly to the engine by Kusto Query Language (KQL) commands. Because this method bypasses the Data Management services, it's only appropriate for exploration and prototyping. Don't use this method in production or high-volume scenarios.
Inline ingestion: A control command .ingest inline is sent to the engine, with the data to be ingested being a part of the command text itself. This method is intended for improvised testing purposes.
Ingest from query: A control command .set, .append, .set-or-append, or .set-or-replace is sent to the engine, with the data specified indirectly as the results of a query or a command.
Ingest from storage (pull): A control command .ingest into is sent to the engine, with the data stored in some external storage (for example, Azure Blob Storage) accessible by the engine and pointed-to by the command.
For an example of using ingest control commands, see Analyze with Data Explorer.
Ingestion process
Once you have chosen the most suitable ingestion method for your needs, do the following steps:
Set retention policy
Data ingested into a table in Azure Synapse Data Explorer is subject to the table's effective retention policy. Unless set on a table explicitly, the effective retention policy is derived from the database's retention policy. Hot retention is a function of cluster size and your retention policy. Ingesting more data than you have available space will force the first in data to cold retention.
Make sure that the database's retention policy is appropriate for your needs. If not, explicitly override it at the table level. For more information, see retention policy.
Create a table
In order to ingest data, a table needs to be created beforehand. Use one of the following options:
Create a table with a command. For an example of using the create a table command, see Analyze with Data Explorer.
Create a table using One-click Ingestion.
Note
If a record is incomplete or a field cannot be parsed as the required data type, the corresponding table columns will be populated with null values.
Create schema mapping
Schema mapping helps bind source data fields to destination table columns. Mapping allows you to take data from different sources into the same table, based on the defined attributes. Different types of mappings are supported, both row-oriented (CSV, JSON and AVRO), and column-oriented (Parquet). In most methods, mappings can also be pre-created on the table and referenced from the ingest command parameter.
Set update policy (optional)
Some of the data format mappings (Parquet, JSON, and Avro) support simple and useful ingest-time transformations. Where the scenario requires more complex processing at ingest time, use update policy, which allows for lightweight processing using Kusto Query Language commands. The update policy automatically runs extractions and transformations on ingested data on the original table, and ingests the resulting data into one or more destination tables. Set your update policy.
Next steps
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for