Tutorial: Build a machine learning app with Apache Spark MLlib and Azure Synapse Analytics
In this article, you'll learn how to use Apache Spark MLlib to create a machine learning application that does simple predictive analysis on an Azure open dataset. Spark provides built-in machine learning libraries. This example uses classification through logistic regression.
SparkML and MLlib are core Spark libraries that provide many utilities that are useful for machine learning tasks, including utilities that are suitable for:
- Classification
- Regression
- Clustering
- Topic modeling
- Singular value decomposition (SVD) and principal component analysis (PCA)
- Hypothesis testing and calculating sample statistics
Understand classification and logistic regression
Classification, a popular machine learning task, is the process of sorting input data into categories. It's the job of a classification algorithm to figure out how to assign labels to input data that you provide. For example, you can think of a machine learning algorithm that accepts stock information as input and divide the stock into two categories: stocks that you should sell and stocks that you should keep.
Logistic regression is an algorithm that you can use for classification. Spark's logistic regression API is useful for binary classification, or classifying input data into one of two groups. For more information about logistic regression, see Wikipedia.
In summary, the process of logistic regression produces a logistic function that you can use to predict the probability that an input vector belongs in one group or the other.
Predictive analysis example on NYC taxi data
In this example, you use Spark to perform some predictive analysis on taxi-trip tip data from New York. The data is available through Azure Open Datasets. This subset of the dataset contains information about yellow taxi trips, including information about each trip, the start and end time and locations, the cost, and other interesting attributes.
Important
There might be additional charges for pulling this data from its storage location.
In the following steps, you develop a model to predict whether a particular trip includes a tip or not.
Create an Apache Spark machine learning model
Create a notebook by using the PySpark kernel. For instructions, see Create a notebook.
Import the types required for this application. Copy and paste the following code into an empty cell, and then press Shift+Enter. Or run the cell by using the blue play icon to the left of the code.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorBecause of the PySpark kernel, you don't need to create any contexts explicitly. The Spark context is automatically created for you when you run the first code cell.
Construct the input DataFrame
Because the raw data is in a Parquet format, you can use the Spark context to pull the file into memory as a DataFrame directly. Although the code in the following steps uses the default options, it's possible to force mapping of data types and other schema attributes if needed.
Run the following lines to create a Spark DataFrame by pasting the code into a new cell. This step retrieves the data via the Open Datasets API. Pulling all of this data generates about 1.5 billion rows.
Depending on the size of your serverless Apache Spark pool, the raw data might be too large or take too much time to operate on. You can filter this data down to something smaller. The following code example uses
start_dateandend_dateto apply a filter that returns a single month of data.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())The downside to simple filtering is that, from a statistical perspective, it might introduce bias into the data. Another approach is to use the sampling built into Spark.
The following code reduces the dataset to about 2,000 rows, if it's applied after the preceding code. You can use this sampling step instead of the simple filter or in conjunction with the simple filter.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)It's now possible to look at the data to see what was read. It's normally better to review data with a subset rather than the full set, depending on the size of the dataset.
The following code offers two ways to view the data. The first way is basic. The second way provides a much richer grid experience, along with the capability to visualize the data graphically.
#sampled_taxi_df.show(5) display(sampled_taxi_df)Depending on the size of the generated dataset, and your need to experiment or run the notebook many times, you might want to cache the dataset locally in the workspace. There are three ways to perform explicit caching:
- Save the DataFrame locally as a file.
- Save the DataFrame as a temporary table or view.
- Save the DataFrame as a permanent table.
The first two of these approaches are included in the following code examples.
Creating a temporary table or view provides different access paths to the data, but it lasts only for the duration of the Spark instance session.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Prepare the data
The data in its raw form is often not suitable for passing directly to a model. You must perform a series of actions on the data to get it into a state where the model can consume it.
In the following code, you perform four classes of operations:
- The removal of outliers or incorrect values through filtering.
- The removal of columns, which are not needed.
- The creation of new columns derived from the raw data to make the model work more effectively. This operation is sometimes called featurization.
- Labeling. Because you're undertaking binary classification (will there be a tip or not on a given trip), there's a need to convert the tip amount into a 0 or 1 value.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
You then make a second pass over the data to add the final features.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Create a logistic regression model
The final task is to convert the labeled data into a format that can be analyzed through logistic regression. The input to a logistic regression algorithm needs to be a set of label/feature vector pairs, where the feature vector is a vector of numbers that represent the input point.
So, you need to convert the categorical columns into numbers. Specifically, you need to convert the trafficTimeBins and weekdayString columns into integer representations. There are multiple approaches to performing the conversion. The following example takes the OneHotEncoder approach, which is common.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
This action results in a new DataFrame with all columns in the right format to train a model.
Train a logistic regression model
The first task is to split the dataset into a training set and a testing or validation set. The split here is arbitrary. Experiment with different split settings to see if they affect the model.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Now that there are two DataFrames, the next task is to create the model formula and run it against the training DataFrame. Then you can validate against the testing DataFrame. Experiment with different versions of the model formula to see the impact of different combinations.
Note
To save the model, assign the Storage Blob Data Contributor role to the Azure SQL Database server resource scope. For detailed steps, see Assign Azure roles using the Azure portal. Only members with owner privileges can perform this step.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
The output from this cell is:
Area under ROC = 0.9779470729751403
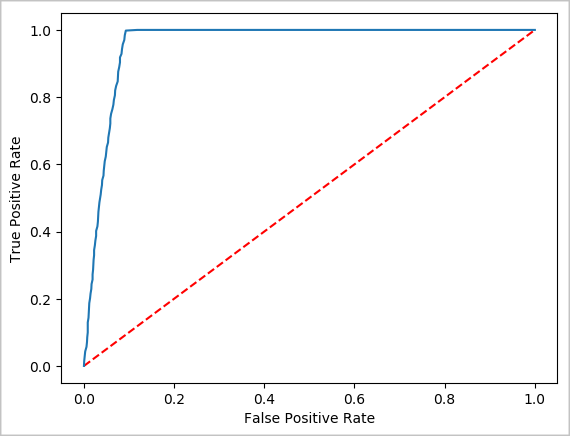
Create a visual representation of the prediction
You can now construct a final visualization to help you reason about the results of this test. An ROC curve is one way to review the result.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Shut down the Spark instance
After you finish running the application, shut down the notebook to release the resources by closing the tab. Or select End Session from the status panel at the bottom of the notebook.
See also
Next steps
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for