Skalering av lokal datagateway
Denne artikkelen er rettet mot Power BI-administratorer som må installere og administrere den lokale datagatewayen.
Gatewayen kreves når Power BI må ha tilgang til data som ikke er tilgjengelig direkte via Internett. Den kan installeres på en lokal server eller vm-vertsbasert infrastruktur som en tjeneste (IaaS).
Gateway-arbeidsbelastninger
Den lokale datagatewayen støtter to arbeidsbelastninger. Det er viktig at du først forstår disse arbeidsbelastningene før vi diskuterer gateway-størrelse og anbefalinger.
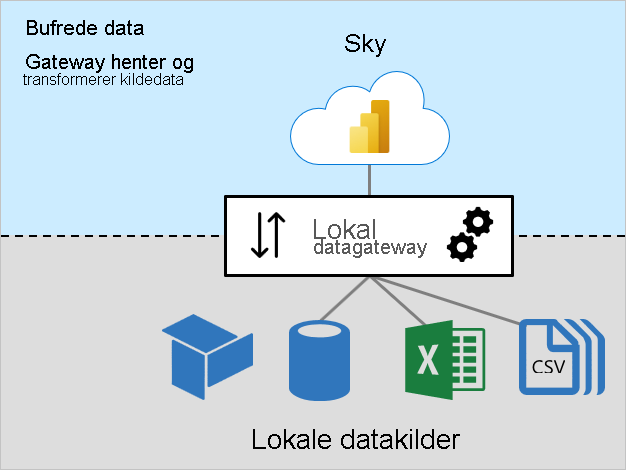
Hurtigbufret dataarbeidsbelastning
Den bufrede dataarbeidsbelastningen henter og transformerer kildedata for innlasting i Semantiske Power BI-modeller (tidligere kalt datasett). Det gjør det i tre trinn:
- Koble til ion: Gatewayen kobler til kildedata.
- Datahenting og transformasjon: Data hentes, og om nødvendig transformeres. Når det er mulig, sender Power Query-mashup-motoren transformasjonstrinn til datakilden – det kalles spørringsdelegering. Når det ikke er mulig, må transformasjoner gjøres av gatewayen. I dette tilfellet vil gatewayen bruke mer CPU- og minneressurser.
- Overføring: Data overføres til Power Bi-tjeneste – en pålitelig og rask Internett-tilkobling er viktig, spesielt for store datavolumer.
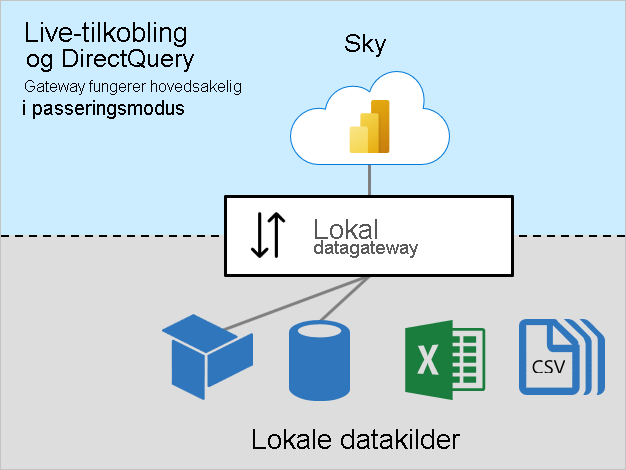
Arbeidsbelastninger for direkte Koble til ion og DirectQuery
Arbeidsbelastningen Live Koble til ion og DirectQuery fungerer for det meste i direktemodus. Power Bi-tjeneste sender spørringer, og gatewayen svarer med spørringsresultater. Vanligvis er spørringsresultatene små i størrelse.
- Hvis du vil ha mer informasjon om Live Koble til ion, kan du se Semantiske modeller i Power Bi-tjeneste (eksternt vertsbaserte modeller).
- Hvis du vil ha mer informasjon om DirectQuery, kan du se semantiske modellmoduser i Power Bi-tjeneste (DirectQuery-modus).
Denne arbeidsbelastningen krever CPU-ressurser for rutingsspørringer og spørringsresultater. Vanligvis er det mye mindre etterspørsel etter CPU enn det som kreves av hurtigbufferdataarbeidsbelastningen, spesielt når det kreves for å transformere data for hurtigbufring.
Pålitelig, rask og konsekvent tilkobling er viktig for å sikre at rapportbrukere har responsive opplevelser.
Skaleringshensyn
Å fastslå riktig skalering for gatewaymaskinen kan avhenge av følgende variabler:
- For arbeidsbelastninger for hurtigbufferdata:
- Antall samtidige semantiske modelloppdateringer
- Datakildetypene (relasjonsdatabase, analytisk database, datafeeder eller filer)
- Datavolumet som skal hentes fra datakilder
- Eventuelle transformasjoner som kreves for å gjøres av Power Query-mashup-motoren
- Datavolumet som skal overføres til Power Bi-tjeneste
- For direkte Koble til ion- og DirectQuery-arbeidsbelastninger:
- Antall samtidige rapportbrukere
- Antall visualobjekter på rapportsider (hvert visualobjekt sender minst én spørring)
- Hyppigheten av oppdateringer for spørringsbuffer for Power BI-instrumentbord
- Antall sanntidsrapporter ved hjelp av funksjonen Automatisk sideoppdatering
- Om semantiske modeller håndhever sikkerhet på radnivå (RLS)
Vanligvis krever arbeidsbelastninger for direkte Koble til ion og DirectQuery tilstrekkelig CPU, mens hurtigbufferdataarbeidsbelastninger krever mer CPU og minne. Begge arbeidsbelastningene avhenger av god tilkobling til Power Bi-tjeneste og datakildene.
Merk
Power BI-kapasiteter innfører begrensninger på parallellitet for modelloppdatering, og Direkte Koble til ion- og DirectQuery-gjennomstrømming. Det er ingen vits å endre størrelsen på gatewayene for å levere mer enn det Power Bi-tjeneste støtter. Grensene varierer etter Premium SKU (og tilsvarende størrelse A SKU). Hvis du vil ha mer informasjon, kan du se Kapasitetslisenser for Microsoft Fabric og Hva er Power BI Premium? (Kapasitetsnoder).
Viktig
Til tider refererer denne artikkelen til Power BI Premium eller dets kapasitetsabonnementer (P SKU-er). Vær oppmerksom på at Microsoft for øyeblikket konsoliderer kjøpsalternativer og trekker tilbake Power BI Premium per kapasitet sKU-er. Nye og eksisterende kunder bør vurdere å kjøpe Fabric-kapasitetsabonnementer (F SKU-er) i stedet.
Hvis du vil ha mer informasjon, kan du se Viktige oppdateringer som kommer til Power BI Premium-lisensiering og vanlige spørsmål om Power BI Premium.
Anbefalinger
Anbefalinger for gateway-størrelse avhenger av mange variabler. I denne delen gir vi deg generelle anbefalinger som du kan ta hensyn til.
Første skalering
Det kan være vanskelig å beregne riktig størrelse nøyaktig. Vi anbefaler at du starter med en maskin med minst 8 CPU-kjerner, 8 GB RAM og flere Gigabit-nettverkskort. Deretter kan du måle en vanlig gateway-arbeidsbelastning ved å logge CPU- og minnesystemtellere. Hvis du vil ha mer informasjon, kan du se Overvåke og optimalisere lokal datagatewayytelse.
Tilkobling
Planlegg for best mulig tilkobling mellom Power Bi-tjeneste og gatewayen, gatewayen og datakildene.
- Strebe etter pålitelighet, raske hastigheter og lave, konsekvente ventetider.
- Fjern – eller reduser – maskinhopp mellom gatewayen og datakildene dine.
- Fjern alle nettverksbegrensninger som er pålagt av brannmurens proxy-lag. Hvis du vil ha mer informasjon om Power BI-endepunkter, kan du se Legge til Power BI-nettadresser i tillatelseslisten.
- Konfigurer Azure ExpressRoute for å etablere private, administrerte tilkoblinger til Power BI.
- For datakilder i Azure-virtuelle maskiner må du sørge for at virtuelle maskiner er sammenkoblet med Power Bi-tjeneste.
- Sørg for god tilkobling mellom gatewaymaskinen og lokal Active Directory for Live Koble til ion-arbeidsbelastninger til SQL Server Analysis Services (SSAS) som involverer dynamisk RLS.
Klynging
For distribusjoner i stor skala kan du opprette en gateway med flere klyngemedlemmer. Klynger unngår enkle feilpunkter, og kan laste inn saldotrafikk på tvers av gatewayer. Du kan gjøre følgende:
- Installer én eller flere gatewayer i en klynge.
- Isolere arbeidsbelastninger til frittstående gatewayer eller klynger med gateway-servere.
Hvis du vil ha mer informasjon, kan du se Administrere lokale datagateway-klynger med høy tilgjengelighet og belastningsfordeling.
Utforming og innstillinger for semantisk modell
Semantisk modellutforming og innstillingene deres kan påvirke gateway-arbeidsbelastninger. Hvis du vil redusere gateway-arbeidsbelastningen, kan du vurdere følgende handlinger.
For semantiske importmodeller:
- Konfigurer mindre hyppig dataoppdatering.
- Konfigurer trinnvis oppdatering for å minimere mengden data som skal overføres.
- Når det er mulig, må du sørge for at spørringsdelegering finner sted.
- Spesielt for store datavolumer eller et behov for resultater med lav ventetid, konverterer du utformingen til en DirectQuery- eller Composite-modell .
For Semantiske DirectQuery-modeller:
- Optimaliser datakilder, modell- og rapportutforminger – hvis du vil ha mer informasjon, kan du se Veiledning for DirectQuery-modell i Power BI Desktop.
- Opprett aggregasjoner for å bufre resultater på høyere nivå for å redusere antall DirectQuery-forespørsler.
- Begrens intervaller for automatisk sideoppdatering , i rapportutforminger og kapasitetsinnstillinger.
- Spesielt når dynamisk RLS håndheves, begrenser du oppdateringsfrekvensen for instrumentbordets hurtigbuffer.
- Spesielt for mindre datavolumer eller for ikke-flyktige data konverterer du utformingen til en import- eller sammensatt modell.
For semantiske modeller for live Koble til ion:
- Spesielt når dynamisk RLS håndheves, begrenser du oppdateringsfrekvensen for instrumentbordets hurtigbuffer.
Relatert innhold
Hvis du vil ha mer informasjon om denne artikkelen, kan du se følgende ressurser:
- Planlegging av Power BI-implementering: Datagatewayer
- Veiledning for distribusjon av en datagateway for Power BI
- Konfigurer proxy-innstillinger for den lokale datagatewayen
- Overvåke og optimalisere lokal datagatewayytelse
- Feilsøke gatewayer – Power BI
- Feilsøke lokal datagateway
- Viktigheten av spørringsdelegering
- Spørsmål? Prøv å spørre Power BI-fellesskap
- Forslag? Bidra med ideer for å forbedre Power BI