Azure Storage-provider (Azure Functions)
In dit document worden de kenmerken van de Durable Functions Azure Storage-provider beschreven, met de nadruk op prestatie- en schaalbaarheidsaspecten. De Azure Storage-provider is de standaardprovider. De instantiestatussen en wachtrijen worden opgeslagen in een Azure Storage-account (klassiek).
Notitie
Zie de documentatie over Durable Functions opslagproviders voor meer informatie over de ondersteunde opslagproviders voor Durable Functions en hoe deze zich verhouden.
In de Azure Storage-provider wordt alle uitvoering van functies aangestuurd door Azure Storage-wachtrijen. Indeling en entiteitsstatus en -geschiedenis worden opgeslagen in Azure Tables. Azure-blobs en blob-leases worden gebruikt om indelingsexemplaren en entiteiten te verdelen over meerdere app-exemplaren (ook wel werkrollen of gewoon VM's genoemd). In deze sectie wordt dieper ingegaan op de verschillende Azure Storage-artefacten en hoe deze van invloed zijn op de prestaties en schaalbaarheid.
Opslagweergave
Een task hub blijft permanent alle exemplaarstatussen en alle berichten behouden. Zie het voorbeeld van taakhubuitvoering voor een beknopt overzicht van hoe deze worden gebruikt om de voortgang van een indeling bij te houden.
De Azure Storage-provider vertegenwoordigt de taakhub in de opslag met behulp van de volgende onderdelen:
- Tussen twee en drie Azure-tabellen. Twee tabellen worden gebruikt om geschiedenissen en exemplaarstatussen weer te geven. Als Tabelpartitiebeheer is ingeschakeld, wordt er een derde tabel geïntroduceerd om partitiegegevens op te slaan.
- In één Azure-wachtrij worden de activiteitsberichten opgeslagen.
- De exemplaarberichten worden opgeslagen in een of meer Azure-wachtrijen. Elk van deze zogenaamde controlewachtrijen vertegenwoordigt een partitie waaraan een subset van alle exemplaarberichten is toegewezen, op basis van de hash van de exemplaar-id.
- Enkele extra blobcontainers die worden gebruikt voor lease-blobs en/of grote berichten.
Een taakhub met de naam xyz met PartitionCount = 4 bevat bijvoorbeeld de volgende wachtrijen en tabellen:

Vervolgens beschrijven we deze onderdelen en de rol die ze spelen in meer detail.
Geschiedenistabel
De tabel Geschiedenis is een Azure Storage-tabel die de geschiedenis-gebeurtenissen bevat voor alle indelingsexemplaren binnen een taakhub. De naam van deze tabel is in de vorm TaskHubNameHistory. Wanneer exemplaren worden uitgevoerd, worden nieuwe rijen toegevoegd aan deze tabel. De partitiesleutel van deze tabel is afgeleid van de instantie-id van de indeling. Instantie-id's zijn standaard willekeurig, waardoor een optimale distributie van interne partities in Azure Storage wordt gegarandeerd. De rijsleutel voor deze tabel is een reeksnummer dat wordt gebruikt voor het ordenen van de geschiedenis gebeurtenissen.
Wanneer een indelingsinstantie moet worden uitgevoerd, worden de bijbehorende rijen van de tabel Geschiedenis in het geheugen geladen met behulp van een bereikquery binnen één tabelpartitie. Deze geschiedenisgebeurtenissen worden vervolgens opnieuw afgespeeld in de code van de orchestrator-functie om deze terug te brengen naar de eerder controleerpuntstatus. Het gebruik van uitvoeringsgeschiedenis om de status op deze manier opnieuw te bouwen, wordt beïnvloed door het patroon Gebeurtenisbronnen.
Tip
Indelingsgegevens die zijn opgeslagen in de tabel Geschiedenis bevatten uitvoerpayloads van activiteiten en sub-orchestratorfuncties. Nettoladingen van externe gebeurtenissen worden ook opgeslagen in de tabel Geschiedenis. Omdat de volledige geschiedenis in het geheugen wordt geladen telkens wanneer een orchestrator moet worden uitgevoerd, kan een geschiedenis die groot genoeg is, leiden tot een aanzienlijke geheugenbelasting op een bepaalde VM. De lengte en grootte van de indelingsgeschiedenis kunnen worden verminderd door grote indelingen op te splitsen in meerdere subindelingen of door de grootte te verkleinen van de uitvoer die wordt geretourneerd door de activiteit en sub-orchestratorfuncties die worden aangeroepen. U kunt ook het geheugengebruik verminderen door de gelijktijdigheidsbeperkingen per VM te verlagen om te beperken hoeveel indelingen gelijktijdig in het geheugen worden geladen.
Tabel exemplaren
De tabel Instances bevat de statussen van alle indelings- en entiteitsexemplaren binnen een taakhub. Wanneer exemplaren worden gemaakt, worden nieuwe rijen toegevoegd aan deze tabel. De partitiesleutel van deze tabel is de instantie-id of entiteitssleutel van de indeling en de rijsleutel is een lege tekenreeks. Er is één rijindeling of entiteitsexemplaar.
Deze tabel wordt gebruikt om te voldoen aan exemplaarqueryaanvragen van code en http-API-aanroepen voor statusquery's . Het wordt uiteindelijk consistent gehouden met de inhoud van de eerder genoemde geschiedenistabel. Het gebruik van een afzonderlijke Azure Storage-tabel om op deze manier efficiënt te voldoen aan querybewerkingen van exemplaren, wordt beïnvloed door het patroon CQRS (Command and Query Responsibility Segregation).
Tip
Met de partitionering van de tabel Instances kunnen miljoenen indelingsexemplaren worden opgeslagen zonder merkbare invloed op de prestaties of schaal van de runtime. Het aantal exemplaren kan echter een aanzienlijke invloed hebben op de queryprestaties voor meerdere exemplaren . Als u de hoeveelheid gegevens wilt beheren die in deze tabellen zijn opgeslagen, kunt u overwegen om regelmatig oude exemplaargegevens op te wissen.
Partitietabel
Notitie
Deze tabel wordt alleen weergegeven in de taakhub wanneer Table Partition Manager deze is ingeschakeld. Als u deze wilt toepassen, configureert u useTablePartitionManagement de instelling in de host.json van uw app.
De tabel Partities bevat de status van partities voor de Durable Functions-app en wordt gebruikt om partities te verdelen over de werkrollen van uw app. Er is één rij per partitie.
Wachtrijen
Orchestrator-, entiteits- en activiteitsfuncties worden allemaal geactiveerd door interne wachtrijen in de taakhub van de functie-app. Het gebruik van wachtrijen op deze manier biedt betrouwbare garanties voor 'ten minste eenmaal'-berichtbezorging. Er zijn twee soorten wachtrijen in Durable Functions: de besturingselementwachtrij en de wachtrij met werkitems.
De werkitemwachtrij
Er is één werkitemwachtrij per taakhub in Durable Functions. Het is een eenvoudige wachtrij en gedraagt zich op dezelfde manier als andere queueTrigger wachtrijen in Azure Functions. Deze wachtrij wordt gebruikt om staatloze activiteitenfuncties te activeren door één bericht tegelijk uit de wachtrij te verwijderen. Elk van deze berichten bevat activiteitsfunctie-invoer en aanvullende metagegevens, zoals welke functie moet worden uitgevoerd. Wanneer een Durable Functions toepassing wordt uitgeschaald naar meerdere VM's, concurreren deze VM's allemaal om taken uit de werkitemwachtrij op te halen.
Wachtrij(en) beheren
Er zijn meerdere besturingswachtrijen per taakhub in Durable Functions. Een besturingswachtrij is geavanceerder dan de eenvoudigere werkitemwachtrij. Beheerwachtrijen worden gebruikt om de stateful orchestrator- en entiteitsfuncties te activeren. Omdat de orchestrator- en entiteitsfunctie-exemplaren stateful singletons zijn, is het belangrijk dat elke indeling of entiteit slechts door één werkrol tegelijk wordt verwerkt. Om deze beperking te bereiken, wordt elk indelingsexemplaar of elke entiteit toegewezen aan één beheerwachtrij. Deze besturingswachtrijen worden verdeeld over werkrollen om ervoor te zorgen dat elke wachtrij door slechts één werkrol tegelijk wordt verwerkt. Meer informatie over dit gedrag vindt u in de volgende secties.
Beheerwachtrijen bevatten verschillende berichttypen voor de indelingslevenscyclus. Voorbeelden zijn orchestrator-besturingsberichten, antwoordberichten van activiteitsfuncties en timerberichten. In één poll worden maar liefst 32 berichten uit een controlewachtrij verwijderd. Deze berichten bevatten nettoladinggegevens en metagegevens, waaronder voor welk indelingsexemplaar het is bedoeld. Als meerdere berichten uit de wachtrij zijn geplaatst voor hetzelfde indelingsexemplaar, worden ze verwerkt als een batch.
Berichten in de beheerwachtrij worden voortdurend gepeild met behulp van een achtergrondthread. De batchgrootte van elke wachtrijpoll wordt bepaald door de controlQueueBatchSize instelling in host.json en heeft een standaardwaarde van 32 (de maximale waarde die wordt ondersteund door Azure Queues). Het maximum aantal vooraf geplaatste control-queue-berichten dat in het geheugen wordt gebufferd, wordt bepaald door de controlQueueBufferThreshold instelling in host.json. De standaardwaarde voor controlQueueBufferThreshold varieert afhankelijk van verschillende factoren, waaronder het type hostingabonnement. Zie de documentatie over het host.json-schema voor meer informatie over deze instellingen.
Tip
Door de waarde voor controlQueueBufferThreshold te verhogen, kan één indeling of entiteit gebeurtenissen sneller verwerken. Het verhogen van deze waarde kan echter ook leiden tot een hoger geheugengebruik. Het hogere geheugengebruik is deels te wijten aan het ophalen van meer berichten uit de wachtrij en deels door het ophalen van meer indelingsgeschiedenissen in het geheugen. Het verminderen van de waarde voor controlQueueBufferThreshold kan daarom een effectieve manier zijn om het geheugengebruik te verminderen.
Polling van wachtrijen
De duurzame taakextensie implementeert een willekeurig exponentieel uitstelalgoritme om het effect van polling van niet-actieve wachtrijen op de opslagtransactiekosten te verminderen. Wanneer een bericht wordt gevonden, controleert de runtime onmiddellijk op een ander bericht. Wanneer er geen bericht wordt gevonden, wacht het een bepaalde tijd voordat het opnieuw wordt geprobeerd. Na volgende mislukte pogingen om een wachtrijbericht op te halen, blijft de wachttijd toenemen totdat de maximale wachttijd wordt bereikt, die standaard 30 seconden is.
De maximale pollingvertraging kan worden geconfigureerd via de maxQueuePollingInterval eigenschap in het bestand host.json. Als u deze eigenschap instelt op een hogere waarde, kan dit leiden tot een hogere latentie voor berichtverwerking. Hogere latenties worden alleen verwacht na perioden van inactiviteit. Als u deze eigenschap instelt op een lagere waarde, kan dit leiden tot hogere opslagkosten vanwege verhoogde opslagtransacties.
Notitie
Wanneer u de Azure Functions Consumption- en Premium-abonnementen uitvoert, controleert de Azure Functions-schaalcontroller elke 10 seconden elke wachtrij met besturingselementen en werkitems. Deze aanvullende polling is nodig om te bepalen wanneer exemplaren van functie-apps moeten worden geactiveerd en om schaalbeslissingen te nemen. Op het moment van schrijven is dit interval van 10 seconden constant en kan deze niet worden geconfigureerd.
Vertraging van indelingsstart
Orchestrations-exemplaren worden gestart door een ExecutionStarted bericht in een van de beheerwachtrijen van de taakhub te plaatsen. Onder bepaalde omstandigheden kunt u vertragingen van meerdere seconden zien tussen het moment waarop een indeling volgens de planning moet worden uitgevoerd en het moment waarop deze daadwerkelijk wordt uitgevoerd. Gedurende dit tijdsinterval blijft het orchestration-exemplaar in de Pending status. Er zijn twee mogelijke oorzaken van deze vertraging:
Backlogged control queues: Als de controlewachtrij voor dit exemplaar een groot aantal berichten bevat, kan het enige tijd duren voordat het
ExecutionStartedbericht wordt ontvangen en verwerkt door de runtime. Berichtenachterstanden kunnen optreden wanneer indelingen veel gebeurtenissen gelijktijdig verwerken. Gebeurtenissen die in de besturingswachtrij worden geplaatst, zijn indelingsstartgebeurtenissen, voltooiingen van activiteiten, duurzame timers, beëindiging en externe gebeurtenissen. Als deze vertraging zich onder normale omstandigheden voordoet, kunt u een nieuwe taakhub maken met een groter aantal partities. Als u meer partities configureert, maakt de runtime meer controlewachtrijen voor belastingdistributie. Elke partitie komt overeen met 1:1 met een controlewachtrij, met een maximum van 16 partities.Back-off poll-vertragingen: Een andere veelvoorkomende oorzaak van indelingsvertragingen is het eerder beschreven back-off pollinggedrag voor controlewachtrijen. Deze vertraging wordt echter alleen verwacht wanneer een app wordt uitgeschaald naar twee of meer exemplaren. Als er slechts één app-exemplaar is of als het app-exemplaar waarmee de indeling wordt gestart, ook hetzelfde exemplaar is dat de doelbeheerwachtrij pollt, is er geen pollingvertraging in de wachtrij. Vertragingen bij back-off-polling kunnen worden verminderd door de host.json-instellingen bij te werken, zoals eerder beschreven.
Blobs
In de meeste gevallen gebruikt Durable Functions geen Azure Storage-blobs om gegevens te behouden. Wachtrijen en tabellen hebben echter groottelimieten die kunnen voorkomen dat Durable Functions alle vereiste gegevens in een opslagrij of wachtrijbericht op te slaan. Wanneer een stukje gegevens dat moet worden opgeslagen in een wachtrij bijvoorbeeld groter is dan 45 kB wanneer deze is geserialiseerd, worden de gegevens door Durable Functions gecomprimeerd en in plaats daarvan opgeslagen in een blob. Wanneer gegevens op deze manier naar blobopslag worden bewaard, slaat Durable Function een verwijzing naar die blob op in de tabelrij of het wachtrijbericht. Wanneer Durable Functions de gegevens moet ophalen, wordt deze automatisch opgehaald uit de blob. Deze blobs worden opgeslagen in de blobcontainer <taskhub>-largemessages.
Prestatieoverwegingen
De extra compressie- en blobbewerkingsstappen voor grote berichten kunnen duur zijn in termen van CPU- en I/O-latentiekosten. Bovendien moet Durable Functions persistente gegevens in het geheugen laden en kan dit voor veel verschillende functie-uitvoeringen tegelijkertijd worden uitgevoerd. Als gevolg hiervan kunnen persistente grote nettoladingen van gegevens ook een hoog geheugengebruik veroorzaken. Als u geheugenoverhead wilt minimaliseren, kunt u overwegen om grote nettoladingen van gegevens handmatig te behouden (bijvoorbeeld in blobopslag) en in plaats daarvan verwijzingen naar deze gegevens door te geven. Op deze manier kan uw code de gegevens alleen laden wanneer dat nodig is om redundante belasting te voorkomen tijdens herhalingen van orchestratorfuncties. Het opslaan van nettoladingen op lokale schijven wordt echter niet aanbevolen, omdat de status van de schijf niet gegarandeerd beschikbaar is, omdat functies gedurende hun levensduur op verschillende VM's kunnen worden uitgevoerd.
Selectie van opslagaccount
De wachtrijen, tabellen en blobs die door Durable Functions worden gebruikt, worden gemaakt in een geconfigureerd Azure Storage-account. Het te gebruiken account kan worden opgegeven met behulp van de durableTask/storageProvider/connectionStringName instelling (of durableTask/azureStorageConnectionStringName instelling in Durable Functions 1.x) in het bestand host.json.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"connectionStringName": "MyStorageAccountAppSetting"
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"azureStorageConnectionStringName": "MyStorageAccountAppSetting"
}
}
}
Als dit niet is opgegeven, wordt het standaardopslagaccount AzureWebJobsStorage gebruikt. Voor prestatiegevoelige workloads wordt echter het configureren van een niet-standaardopslagaccount aanbevolen. Durable Functions maakt veel gebruik van Azure Storage en het gebruik van een toegewezen opslagaccount isoleert Durable Functions opslaggebruik van het interne gebruik door de Azure Functions host.
Notitie
Standaard Azure Storage-accounts voor algemeen gebruik zijn vereist wanneer u de Azure Storage-provider gebruikt. Alle andere typen opslagaccounts worden niet ondersteund. U wordt ten zeerste aangeraden verouderde v1-opslagaccounts voor algemeen gebruik te gebruiken voor Durable Functions. De nieuwere v2-opslagaccounts kunnen aanzienlijk duurder zijn voor Durable Functions workloads. Zie de overzichtsdocumentatie voor opslagaccounts voor meer informatie over Azure Storage-accounttypen .
Uitschalen van Orchestrator
Hoewel activiteitsfuncties oneindig kunnen worden uitgeschaald door meer virtuele machines elastisch toe te voegen, worden afzonderlijke orchestrator-exemplaren en entiteiten beperkt tot één partitie en wordt het maximum aantal partities gebonden door de partitionCount instelling in uw host.json.
Notitie
Over het algemeen zijn orchestratorfuncties bedoeld om lichtgewicht te zijn en moeten ze geen grote hoeveelheden rekenkracht vereisen. Het is daarom niet nodig om een groot aantal control-queue-partities te maken om een geweldige doorvoer voor indelingen te krijgen. Het grootste deel van het zware werk moet worden uitgevoerd in staatloze activiteitsfuncties, die oneindig kunnen worden uitgeschaald.
Het aantal besturingswachtrijen wordt gedefinieerd in het bestand host.json . In het volgende voorbeeld van het host.json-fragment wordt de durableTask/storageProvider/partitionCount eigenschap (of durableTask/partitionCount in Durable Functions 1.x) ingesteld op 3. Houd er rekening mee dat er net zoveel beheerwachtrijen zijn als er partities zijn.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Een taakhub kan worden geconfigureerd met tussen 1 en 16 partities. Als dit niet is opgegeven, is het standaardaantal partities 4.
Tijdens scenario's met weinig verkeer wordt uw toepassing ingeschaald, zodat partities worden beheerd door een klein aantal werknemers. Bekijk als voorbeeld het onderstaande diagram.
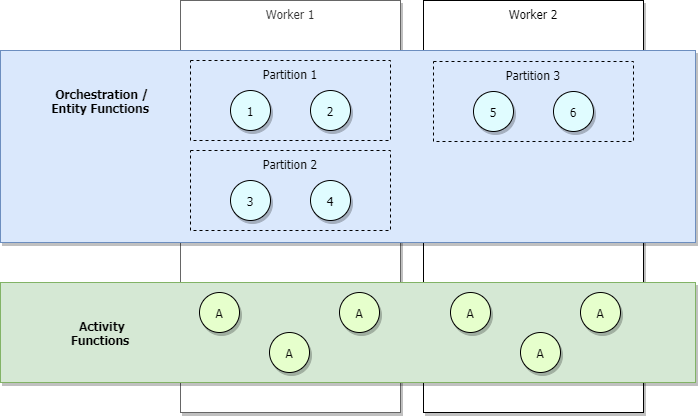
In het vorige diagram zien we dat orchestrators 1 tot en met 6 taakverdeling hebben over partities. Op dezelfde manier worden partities, zoals activiteiten, verdeeld over werkrollen. Partities worden verdeeld over werkrollen, ongeacht het aantal orchestrators dat aan de slag gaat.
Als u gebruikmaakt van het Azure Functions Consumption- of Elastic Premium-abonnement, of als u automatisch schalen op basis van belasting hebt geconfigureerd, worden er meer werkrollen toegewezen naarmate het verkeer toeneemt en partities uiteindelijk de taakverdeling over alle werkrollen verdelen. Als we doorgaan met uitschalen, wordt uiteindelijk elke partitie beheerd door één werkrol. Activiteiten daarentegen zullen over alle werkrollen gelijkmatig verdeeld blijven. Dit wordt weergegeven in de onderstaande afbeelding.
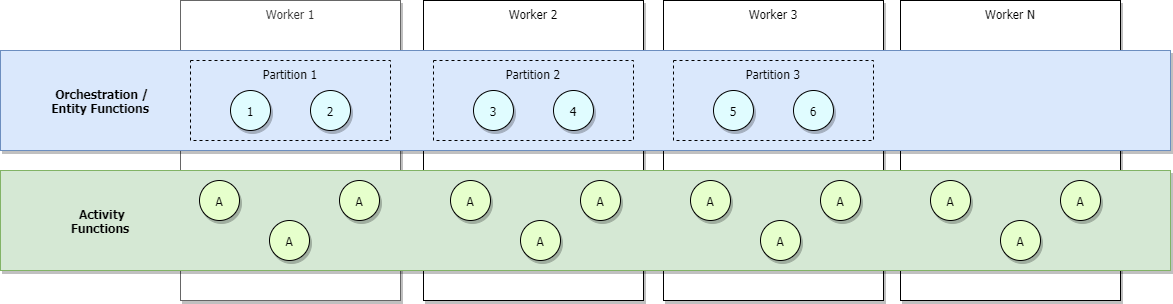
De bovengrens van het maximum aantal gelijktijdige actieve indelingen op een bepaald moment is gelijk aan het aantal werkrollen dat aan uw toepassing is toegewezen , maal uw waarde voor maxConcurrentOrchestratorFunctions. Deze bovengrens kan nauwkeuriger worden gemaakt wanneer uw partities volledig zijn uitgeschaald tussen werkrollen. Wanneer de schaal volledig is uitgeschaald, en omdat elke werkrol slechts één Functions-hostexemplaar heeft, is het maximum aantal actieve gelijktijdige orchestrator-exemplaren gelijk aan uw aantal partities maal uw waarde voor maxConcurrentOrchestratorFunctions.
Notitie
In deze context betekent actief dat een indeling of entiteit in het geheugen wordt geladen en nieuwe gebeurtenissen worden verwerkt. Als de indeling of entiteit wacht op meer gebeurtenissen, zoals de retourwaarde van een activiteitsfunctie, wordt deze uit het geheugen verwijderd en wordt deze niet meer als actief beschouwd. Indelingen en entiteiten worden vervolgens alleen opnieuw in het geheugen geladen wanneer er nieuwe gebeurtenissen moeten worden verwerkt. Er is geen praktisch maximum aantal indelingen of entiteiten dat op één virtuele machine kan worden uitgevoerd, zelfs niet als ze allemaal de status 'Actief' hebben. De enige beperking is het aantal gelijktijdig actieve indelings- of entiteitsexemplaren.
In de onderstaande afbeelding ziet u een volledig uitgeschaald scenario waarin meer orchestrators worden toegevoegd, maar sommige inactief zijn, weergegeven in het grijs.
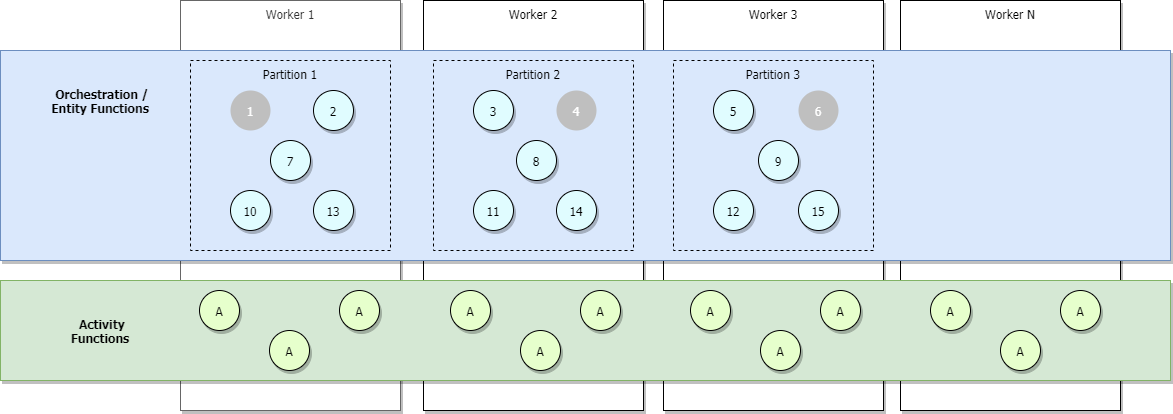
Tijdens het uitschalen kunnen leases van besturingswachtrijen opnieuw worden verdeeld over functions-hostexemplaren om ervoor te zorgen dat partities gelijkmatig worden verdeeld. Deze leases worden intern geïmplementeerd als Azure Blob Storage-leases en zorgen ervoor dat elk afzonderlijk indelingsexemplaar of elke afzonderlijke entiteit slechts op één hostexemplaar tegelijk wordt uitgevoerd. Als een taakhub is geconfigureerd met drie partities (en dus drie beheerwachtrijen), kunnen indelingsexemplaren en entiteiten worden verdeeld over alle drie de lease-holding hostexemplaren. Er kunnen extra VM's worden toegevoegd om de capaciteit voor de uitvoering van activiteitsfuncties te vergroten.
In het volgende diagram ziet u hoe de Azure Functions host communiceert met de opslagentiteiten in een uitgeschaalde omgeving.
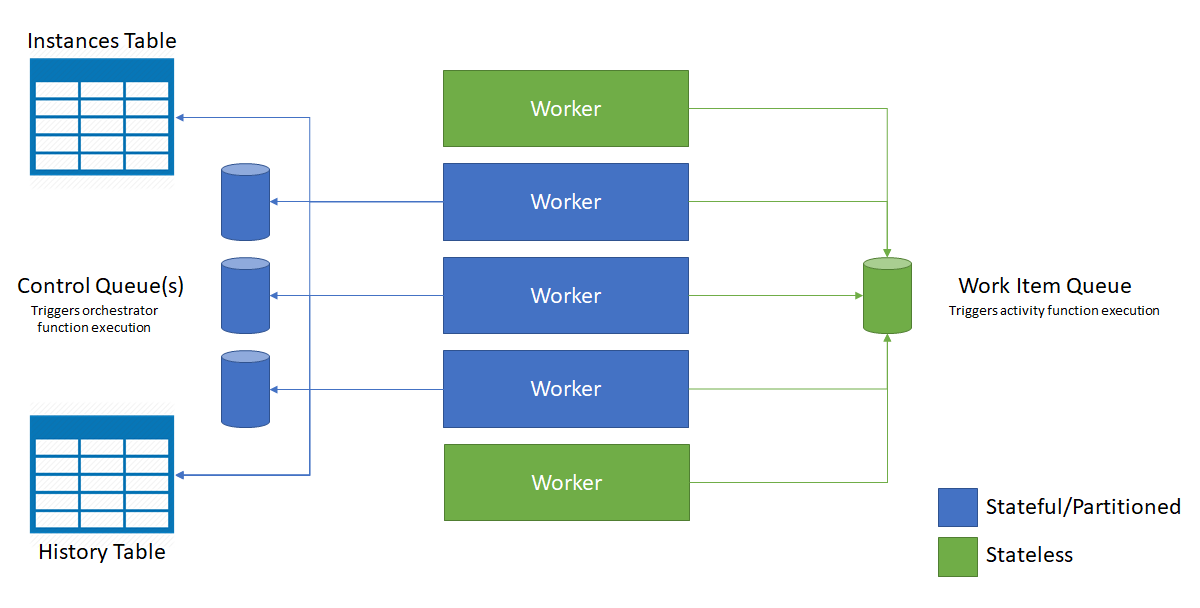
Zoals in het vorige diagram wordt weergegeven, concurreren alle VM's om berichten in de werkitemwachtrij. Er kunnen echter slechts drie VM's berichten ophalen uit besturingswachtrijen en elke VM vergrendelt één besturingswachtrij.
Indelingsexemplaren en entiteiten worden verdeeld over alle exemplaren van de beheerwachtrij. De distributie wordt uitgevoerd door de instantie-id van de indeling of de naam en het sleutelpaar van de entiteit te hashen. Indelingsexemplaar-id's zijn standaard willekeurige GUID's, zodat exemplaren gelijkmatig worden verdeeld over alle beheerwachtrijen.
Over het algemeen zijn orchestratorfuncties bedoeld om lichtgewicht te zijn en moeten ze geen grote hoeveelheden rekenkracht vereisen. Het is daarom niet nodig om een groot aantal beheerwachtrijpartities te maken om een geweldige doorvoer voor indelingen te krijgen. Het grootste deel van het zware werk moet worden uitgevoerd in staatloze activiteitsfuncties, die oneindig kunnen worden uitgeschaald.
Uitgebreide sessies
Uitgebreide sessies is een cachemechanisme dat indelingen en entiteiten in het geheugen houdt, zelfs nadat ze klaar zijn met het verwerken van berichten. Het typische effect van het inschakelen van uitgebreide sessies is een verminderde I/O ten opzichte van de onderliggende durable store en een algehele verbeterde doorvoer.
U kunt uitgebreide sessies inschakelen door in te true stellen durableTask/extendedSessionsEnabled op in het bestand host.json. De durableTask/extendedSessionIdleTimeoutInSeconds instelling kan worden gebruikt om te bepalen hoe lang een niet-actieve sessie in het geheugen wordt bewaard:
Functies 2.0
{
"extensions": {
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
}
Functies 1.0
{
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
Er zijn twee mogelijke nadelen van deze instelling waarmee u rekening moet houden:
- Het geheugengebruik van de functie-app neemt over het algemeen toe omdat niet-actieve exemplaren niet zo snel uit het geheugen worden verwijderd.
- Er kan een algehele afname in doorvoer zijn als er veel gelijktijdige, afzonderlijke, kortdurende orchestrator- of entiteitsfunctieuitvoeringen zijn.
Als bijvoorbeeld durableTask/extendedSessionIdleTimeoutInSeconds is ingesteld op 30 seconden, neemt een kortstondige orchestrator of entiteitsfunctieaflevering die in minder dan 1 seconde wordt uitgevoerd, nog steeds geheugen in beslag gedurende 30 seconden. Het wordt ook meegeteld voor het durableTask/maxConcurrentOrchestratorFunctions eerder genoemde quotum, waardoor andere orchestrator- of entiteitsfuncties mogelijk niet kunnen worden uitgevoerd.
De specifieke effecten van uitgebreide sessies op orchestrator- en entiteitsfuncties worden beschreven in de volgende secties.
Notitie
Uitgebreide sessies worden momenteel alleen ondersteund in .NET-talen, zoals C# of F#. Instelling extendedSessionsEnabled op true voor andere platforms kan leiden tot runtimeproblemen, zoals het niet uitvoeren van activiteiten en door indeling geactiveerde functies op de achtergrond.
Orchestrator-functieherhaling
Zoals eerder vermeld, worden orchestratorfuncties opnieuw afgespeeld met behulp van de inhoud van de tabel Geschiedenis . Standaard wordt de code van de orchestratorfunctie opnieuw afgespeeld telkens wanneer een batch berichten uit een besturingselementwachtrij worden verwijderd. Zelfs als u het uitwaaieringspatroon gebruikt en wacht op het voltooien van alle taken (bijvoorbeeld Task.WhenAll() in .NET, context.df.Task.all() in JavaScript of context.task_all() in Python), zijn er herhalingen die plaatsvinden als batches met taakantwoorden in de loop van de tijd worden verwerkt. Wanneer uitgebreide sessies zijn ingeschakeld, worden orchestratorfunctie-exemplaren langer in het geheugen bewaard en kunnen nieuwe berichten worden verwerkt zonder een volledige herhaling van de geschiedenis.
De prestatieverbetering van uitgebreide sessies wordt meestal waargenomen in de volgende situaties:
- Wanneer er een beperkt aantal indelingsexemplaren gelijktijdig wordt uitgevoerd.
- Wanneer indelingen een groot aantal opeenvolgende acties hebben (bijvoorbeeld honderden aanroepen van activiteitsfuncties) die snel worden voltooid.
- Wanneer indelingen uitwaaieren en fan-in een groot aantal acties die rond dezelfde tijd worden voltooid.
- Wanneer orchestratorfuncties grote berichten moeten verwerken of cpu-intensieve gegevensverwerking moeten uitvoeren.
In alle andere situaties is er meestal geen waarneembare prestatieverbetering voor orchestrator-functies.
Notitie
Deze instellingen mogen alleen worden gebruikt nadat een orchestratorfunctie volledig is ontwikkeld en getest. Het standaard agressieve herhalingsgedrag kan handig zijn voor het detecteren van codebeperkingen voor orchestrator-functies tijdens de ontwikkeling en is daarom standaard uitgeschakeld.
Prestatiedoelen
In de volgende tabel ziet u de verwachte maximale doorvoer voor de scenario's die worden beschreven in de sectie Prestatiedoelen van het artikel Prestaties en schaal .
'Exemplaar' verwijst naar één exemplaar van een orchestratorfunctie die wordt uitgevoerd op één kleine vm (A1) in Azure App Service. In alle gevallen wordt ervan uitgegaan dat uitgebreide sessies zijn ingeschakeld. De werkelijke resultaten kunnen variëren, afhankelijk van het CPU- of I/O-werk dat door de functiecode wordt uitgevoerd.
| Scenario | Maximale doorvoer |
|---|---|
| Uitvoering van sequentiële activiteit | 5 activiteiten per seconde, per exemplaar |
| Uitvoering van parallelle activiteit (uitwaaieren) | 100 activiteiten per seconde, per exemplaar |
| Verwerking van parallelle reacties (fan-in) | 150 antwoorden per seconde, per exemplaar |
| Verwerking van externe gebeurtenissen | 50 gebeurtenissen per seconde, per exemplaar |
| Verwerking van entiteitsbewerkingen | 64 bewerkingen per seconde |
Als u de verwachte doorvoercijfers niet ziet en uw CPU- en geheugengebruik in orde zijn, controleert u of de oorzaak te maken heeft met de status van uw opslagaccount. De Durable Functions-extensie kan een Azure Storage-account aanzienlijk belasten en voldoende hoge belasting kan leiden tot beperking van opslagaccounts.
Tip
In sommige gevallen kunt u de doorvoer van externe gebeurtenissen, fan-inactiviteit en entiteitsbewerkingen aanzienlijk verhogen door de waarde van de controlQueueBufferThreshold instelling in host.json te verhogen. Het verhogen van deze waarde boven de standaardwaarde zorgt ervoor dat de Durable Task Framework-opslagprovider meer geheugen gebruikt om deze gebeurtenissen agressiever voor te zetten, waardoor vertragingen worden verminderd die gepaard gaan met het verwijderen van berichten uit de Azure Storage-beheerwachtrijen. Zie de naslagdocumentatie voor host.json voor meer informatie.
Verwerking met hoge doorvoer
De architectuur van de Back-end van Azure Storage legt bepaalde beperkingen op de maximale theoretische prestaties en schaalbaarheid van Durable Functions. Als uit uw test blijkt dat Durable Functions in Azure Storage niet aan uw doorvoervereisten voldoet, kunt u overwegen om in plaats daarvan de Netherite-opslagprovider te gebruiken voor Durable Functions.
Als u de haalbare doorvoer voor verschillende basisscenario's wilt vergelijken, raadpleegt u de sectie Basisscenario's van de documentatie van de Netherite-opslagprovider.
De netherite-opslagback-end is ontworpen en ontwikkeld door Microsoft Research. Het maakt gebruik van Azure Event Hubs en de FASTER-databasetechnologie boven op Azure Page-blobs. Het ontwerp van Netherite maakt de verwerking van indelingen en entiteiten aanzienlijk hoger in vergelijking met andere providers. In sommige benchmarkscenario's is aangetoond dat de doorvoer meer dan een orde van grootte toeneemt in vergelijking met de standaard Azure Storage-provider.
Zie de documentatie over Durable Functions opslagproviders voor meer informatie over de ondersteunde opslagproviders voor Durable Functions en hoe deze zich verhouden.