AI-verrijking in Azure AI Search
In Azure AI Search verwijst AI-verrijking naar integratie met Azure AI-services om inhoud te verwerken die niet doorzoekbaar is in de onbewerkte vorm. Door middel van verrijking, analyse en deductie worden gebruikt om doorzoekbare inhoud en structuur te maken waar nog geen eerder bestond.
Omdat Azure AI Search wordt gebruikt voor tekst- en vectorquery's, is het doel van AI-verrijking het hulpprogramma van uw inhoud in zoekgerelateerde scenario's te verbeteren. Onbewerkte inhoud moet tekst of afbeeldingen zijn (u kunt geen vectoren verrijken), maar de uitvoer van een verrijkingspijplijn kan worden gevectoriseerd en geïndexeerd in een vectorindex met vaardigheden zoals de vaardigheid Text Split voor segmentering en AzureOpenAIEmbedding-vaardigheid voor codering. Zie Geïntegreerde gegevenssegmentering en insluiting voor meer informatie over het gebruik van vaardigheden in vectorscenario's.
AI-verrijking is gebaseerd op vaardigheden.
Ingebouwde vaardigheden tikken op Azure AI-services. Ze passen de volgende transformaties en verwerking toe op onbewerkte inhoud:
- Vertaal- en taaldetectie voor meertalige zoekopdrachten
- Entiteitsherkenning voor het extraheren van namen, plaatsen en andere entiteiten van grote stukken tekst
- Sleuteltermextractie om belangrijke termen te identificeren en uit te voeren
- Optical Character Recognition (OCR) voor het herkennen van gedrukte en handgeschreven tekst in binaire bestanden
- Afbeeldingsanalyse om afbeeldingsinhoud te beschrijven en de beschrijvingen uit te voeren als doorzoekbare tekstvelden
Aangepaste vaardigheden voeren uw externe code uit. Aangepaste vaardigheden kunnen worden gebruikt voor elke aangepaste verwerking die u wilt opnemen in de pijplijn.
AI-verrijking is een uitbreiding van een indexeerpijplijn die verbinding maakt met Azure-gegevensbronnen. Een verrijkingspijplijn bevat alle onderdelen van een indexeerpijplijn (indexeerfunctie, gegevensbron, index), plus een vaardighedenset waarmee atomische verrijkingsstappen worden opgegeven.
In het volgende diagram ziet u de voortgang van AI-verrijking:
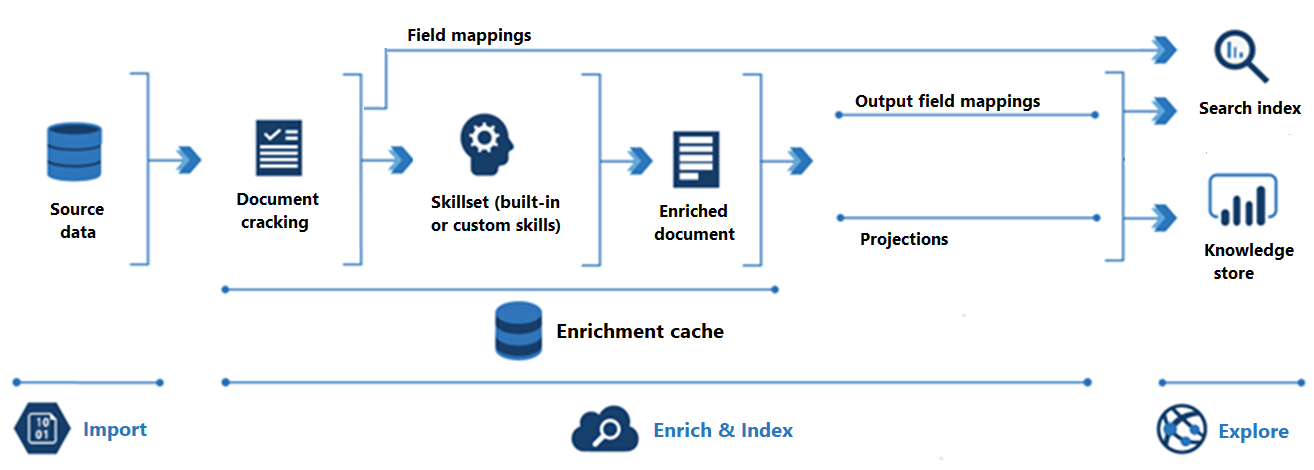
Importeren is de eerste stap. Hier maakt de indexeerfunctie verbinding met een gegevensbron en haalt inhoud (documenten) op in de zoekservice. Azure Blob Storage is de meest voorkomende resource die wordt gebruikt in AI-verrijkingsscenario's, maar elke ondersteunde gegevensbron kan inhoud bieden.
Enrich & Index omvat het grootste deel van de AI-verrijkingspijplijn:
Verrijking begint wanneer de indexeerfunctie documenten kraken en afbeeldingen en tekst extraheert. Het soort verwerking dat vervolgens plaatsvindt, is afhankelijk van uw gegevens en welke vaardigheden u hebt toegevoegd aan een vaardighedenset. Als u afbeeldingen hebt, kunnen ze worden doorgestuurd naar vaardigheden die afbeeldingsverwerking uitvoeren. Tekstinhoud wordt in de wachtrij geplaatst voor verwerking van tekst en natuurlijke taal. Intern maken vaardigheden een 'verrijkt document' waarmee de transformaties worden verzameld wanneer ze plaatsvinden.
Verrijkte inhoud wordt gegenereerd tijdens het uitvoeren van de vaardighedenset en is tijdelijk, tenzij u deze opslaat. U kunt een verrijkingscache inschakelen om gekraakte documenten en uitvoer van vaardigheden te behouden voor later hergebruik tijdens toekomstige uitvoeringen van vaardighedensets.
Als u inhoud in een zoekindex wilt ophalen, moet de indexeerfunctie toewijzingsgegevens hebben voor het verzenden van verrijkte inhoud naar het doelveld. Veldtoewijzingen (expliciet of impliciet) stellen het gegevenspad van brongegevens in op een zoekindex. Met uitvoerveldtoewijzingen wordt het gegevenspad van verrijkte documenten ingesteld op een index.
Indexering is het proces waarbij onbewerkte en verrijkte inhoud wordt opgenomen in de fysieke gegevensstructuren van een zoekindex (de bestanden en mappen). Lexicale analyse en tokenisatie vinden plaats in deze stap.
Verkennen is de laatste stap. Uitvoer is altijd een zoekindex die u kunt opvragen vanuit een client-app. Uitvoer kan eventueel een kennisarchief zijn dat bestaat uit blobs en tabellen in Azure Storage die worden geopend via hulpprogramma's voor gegevensverkenning of downstreamprocessen. Als u een kennisarchief maakt, bepalen projecties het gegevenspad voor verrijkte inhoud. Dezelfde verrijkte inhoud kan worden weergegeven in zowel indexen als kennisarchieven.
Wanneer ai-verrijking gebruiken
Verrijking is handig als onbewerkte inhoud ongestructureerde tekst, afbeeldingsinhoud of inhoud is die taaldetectie en vertaling nodig heeft. Het toepassen van AI via de ingebouwde vaardigheden kan deze inhoud ontgrendelen voor zoekopdrachten in volledige tekst en data science-toepassingen.
U kunt ook aangepaste vaardigheden maken om externe verwerking te bieden. Opensource-, externe of externe code kan als aangepaste vaardigheid in de pijplijn worden geïntegreerd. Classificatiemodellen die opvallende kenmerken van verschillende documenttypen identificeren, vallen in deze categorie, maar elk extern pakket dat waarde toevoegt aan uw inhoud, kan worden gebruikt.
Use-cases voor ingebouwde vaardigheden
Ingebouwde vaardigheden zijn gebaseerd op de AZURE AI-services-API's: Azure AI Computer Vision en Language Service. Tenzij uw inhoudsinvoer klein is, verwacht u dat u een factureerbare Azure AI-servicesresource koppelt om grotere workloads uit te voeren.
Een vaardighedenset die is samengesteld met behulp van ingebouwde vaardigheden is geschikt voor de volgende toepassingsscenario's:
Afbeeldingsverwerkingsvaardigheden omvatten Optical Character Recognition (OCR) en identificatie van visuele kenmerken, zoals gezichtsdetectie, afbeeldingsinterpretatie, afbeeldingsherkenning (beroemde personen en oriëntatiepunten) of kenmerken zoals de afdrukstand van afbeeldingen. Deze vaardigheden maken tekstweergaven van afbeeldingsinhoud voor zoeken in volledige tekst in Azure AI Search.
Machinevertaling wordt geleverd door de vaardigheid Tekstomzetting, die vaak is gekoppeld aan taaldetectie voor oplossingen in meerdere talen.
Verwerking van natuurlijke taal analyseert stukken tekst. Vaardigheden in deze categorie zijn Onder andere Entiteitsherkenning, Sentimentdetectie (inclusief meninganalyse) en Detectie van persoonlijke gegevens. Met deze vaardigheden wordt ongestructureerde tekst toegewezen als doorzoekbare en filterbare velden in een index.
Use cases voor aangepaste vaardigheden
Aangepaste vaardigheden voeren externe code uit die u levert en verpakt in de webinterface voor aangepaste vaardigheden. Er zijn verschillende voorbeelden van aangepaste vaardigheden te vinden in de GitHub-opslagplaats azure-search-power-skills .
Aangepaste vaardigheden zijn niet altijd complex. Als u bijvoorbeeld een bestaand pakket hebt dat patroonkoppeling of een documentclassificatiemodel biedt, kunt u het verpakken in een aangepaste vaardigheid.
Uitvoer opslaan
In Azure AI Search slaat een indexeerfunctie de uitvoer op die wordt gemaakt. Eén indexeerfunctie kan maximaal drie gegevensstructuren maken die verrijkte en geïndexeerde uitvoer bevatten.
| Gegevensopslag | Vereist | Locatie | Beschrijving |
|---|---|---|---|
| doorzoekbare index | Vereist | Zoekservice | Wordt gebruikt voor zoeken in volledige tekst en andere queryformulieren. Het opgeven van een index is een indexeervereiste. Indexinhoud wordt ingevuld op basis van vaardigheiduitvoer, plus bronvelden die rechtstreeks aan velden in de index zijn toegewezen. |
| kennisarchief | Optioneel | Azure Storage | Wordt gebruikt voor downstream-apps, zoals kennisanalyse of gegevenswetenschap. Een kennisarchief wordt gedefinieerd in een vaardighedenset. De definitie bepaalt of uw verrijkte documenten worden geprojecteerd als tabellen of objecten (bestanden of blobs) in Azure Storage. |
| verrijkingscache | Optioneel | Azure Storage | Wordt gebruikt voor het opslaan van verrijkingen in cache voor hergebruik in volgende uitvoeringen van vaardighedensets. In de cache worden geïmporteerde, niet-verwerkte inhoud (gekraakte documenten) opgeslagen. Ook worden de verrijkte documenten opgeslagen die zijn gemaakt tijdens de uitvoering van de vaardighedenset. Caching is handig als u afbeeldingsanalyse of OCR gebruikt en u de tijd en kosten voor het opnieuw verwerken van afbeeldingsbestanden wilt voorkomen. |
Indexen en kennisarchieven zijn volledig onafhankelijk van elkaar. Hoewel u een index moet koppelen om te voldoen aan de vereisten van de indexeerfunctie, kunt u, als uw enige doelstelling een kennisarchief is, de index negeren nadat deze is ingevuld.
Inhoud verkennen
Nadat u een zoekindex of kennisarchief hebt gedefinieerd en geladen, kunt u de bijbehorende gegevens verkennen.
Een query uitvoeren op een zoekindex
Voer query's uit om toegang te krijgen tot de verrijkte inhoud die door de pijplijn wordt gegenereerd. De index is net als elke andere die u kunt maken voor Azure AI Search: u kunt tekstanalyse aanvullen met aangepaste analysefuncties, fuzzy zoekquery's aanroepen, filters toevoegen of experimenteren met scoreprofielen om de relevantie van zoekopdrachten af te stemmen.
Hulpprogramma's voor gegevensverkenning gebruiken in een kennisarchief
In Azure Storage kan een kennisarchief de volgende formulieren aannemen: een blobcontainer van JSON-documenten, een blobcontainer van afbeeldingsobjecten of tabellen in Table Storage. U kunt Storage Explorer, Power BI of elke app gebruiken die verbinding maakt met Azure Storage om toegang te krijgen tot uw inhoud.
Een blobcontainer legt verrijkte documenten in zijn geheel vast, wat handig is als u een feed in andere processen maakt.
Een tabel is handig als u segmenten van verrijkte documenten nodig hebt of als u specifieke delen van de uitvoer wilt opnemen of uitsluiten. Voor analyse in Power BI zijn tabellen de aanbevolen gegevensbron voor gegevensverkenning en visualisatie in Power BI.
Beschikbaarheid en prijzen
Verrijking is beschikbaar in regio's met Azure AI-services. U kunt de beschikbaarheid van verrijking controleren op de pagina met regio's .
Facturering volgt een prijsmodel voor betalen per gebruik. De kosten voor het gebruik van ingebouwde vaardigheden worden doorgegeven wanneer een Azure AI-servicessleutel voor meerdere regio's wordt opgegeven in de vaardighedenset. Er zijn ook kosten verbonden aan het extraheren van afbeeldingen, zoals gemeten door Azure AI Search. Tekstextractie en hulpprogrammavaardigheden zijn echter niet factureerbaar. Zie Hoe er kosten in rekening worden gebracht voor Azure AI Search voor meer informatie.
Controlelijst: Een typische werkstroom
Een verrijkingspijplijn bestaat uit indexeerfuncties met vaardighedensets. Na het indexeren kunt u een query uitvoeren op een index om uw resultaten te valideren.
Begin met een subset met gegevens in een ondersteunde gegevensbron. Het ontwerp van indexeerfuncties en vaardighedensets is een iteratief proces. Het werk gaat sneller met een kleine representatieve gegevensset.
Maak een gegevensbron waarmee een verbinding met uw gegevens wordt opgegeven.
Maak een vaardighedenset. Tenzij uw project klein is, moet u een Azure AI-resource voor meerdere services koppelen. Als u een kennisarchief maakt, definieert u deze in de vaardighedenset.
Maak een indexschema waarmee een zoekindex wordt gedefinieerd.
Maak en voer de indexeerfunctie uit om alle bovenstaande onderdelen samen te brengen. Met deze stap worden de gegevens opgehaald, de vaardighedenset uitgevoerd en de index geladen.
Een indexeerfunctie is ook de plaats waar u veldtoewijzingen en uitvoerveldtoewijzingen opgeeft waarmee het gegevenspad naar een zoekindex wordt ingesteld.
Schakel eventueel verrijkingscaching in de configuratie van de indexeerfunctie in. Met deze stap kunt u later bestaande verrijkingen opnieuw gebruiken.
Voer query's uit om resultaten te evalueren of start een foutopsporingssessie om eventuele vaardighedensetproblemen te doorlopen.
Als u een van de bovenstaande stappen wilt herhalen, stelt u de indexeerfunctie opnieuw in voordat u deze uitvoert. U kunt ook de objecten voor elke uitvoering verwijderen en opnieuw maken (aanbevolen als u de gratis laag gebruikt). Als u caching van de indexeerfunctie hebt ingeschakeld, wordt deze opgehaald uit de cache als de gegevens ongewijzigd zijn bij de bron en als uw wijzigingen in de pijplijn de cache niet ongeldig maken.