Power BI Premium-gegevensstroomworkloads configureren
U kunt gegevensstroomworkloads maken in uw Power BI Premium-abonnement. Power BI maakt gebruik van het concept van workloads om Premium-inhoud te beschrijven. Workloads omvatten gegevenssets, gepagineerde rapporten, gegevensstromen en AI. Met de workload voor gegevensstromen kunt u selfservicegegevensvoorbereiding van gegevensstromen gebruiken om gegevens op te nemen, te transformeren, te integreren en te verrijken. Power BI Premium-gegevensstromen worden beheerd in de Beheer-portal.
In de volgende secties wordt beschreven hoe u gegevensstromen in uw organisatie inschakelt, hoe u hun instellingen in uw Premium-capaciteit kunt verfijnen en richtlijnen voor gemeenschappelijk gebruik.
Gegevensstromen inschakelen in Power BI Premium
De eerste vereiste voor het gebruik van gegevensstromen in uw Power BI Premium-abonnement is het maken en gebruiken van gegevensstromen voor uw organisatie mogelijk te maken. Selecteer Tenant Instellingen in de Beheer-portal en zet de schuifregelaar onder Gegevensstroominstellingen op Ingeschakeld, zoals wordt weergegeven in de volgende afbeelding.
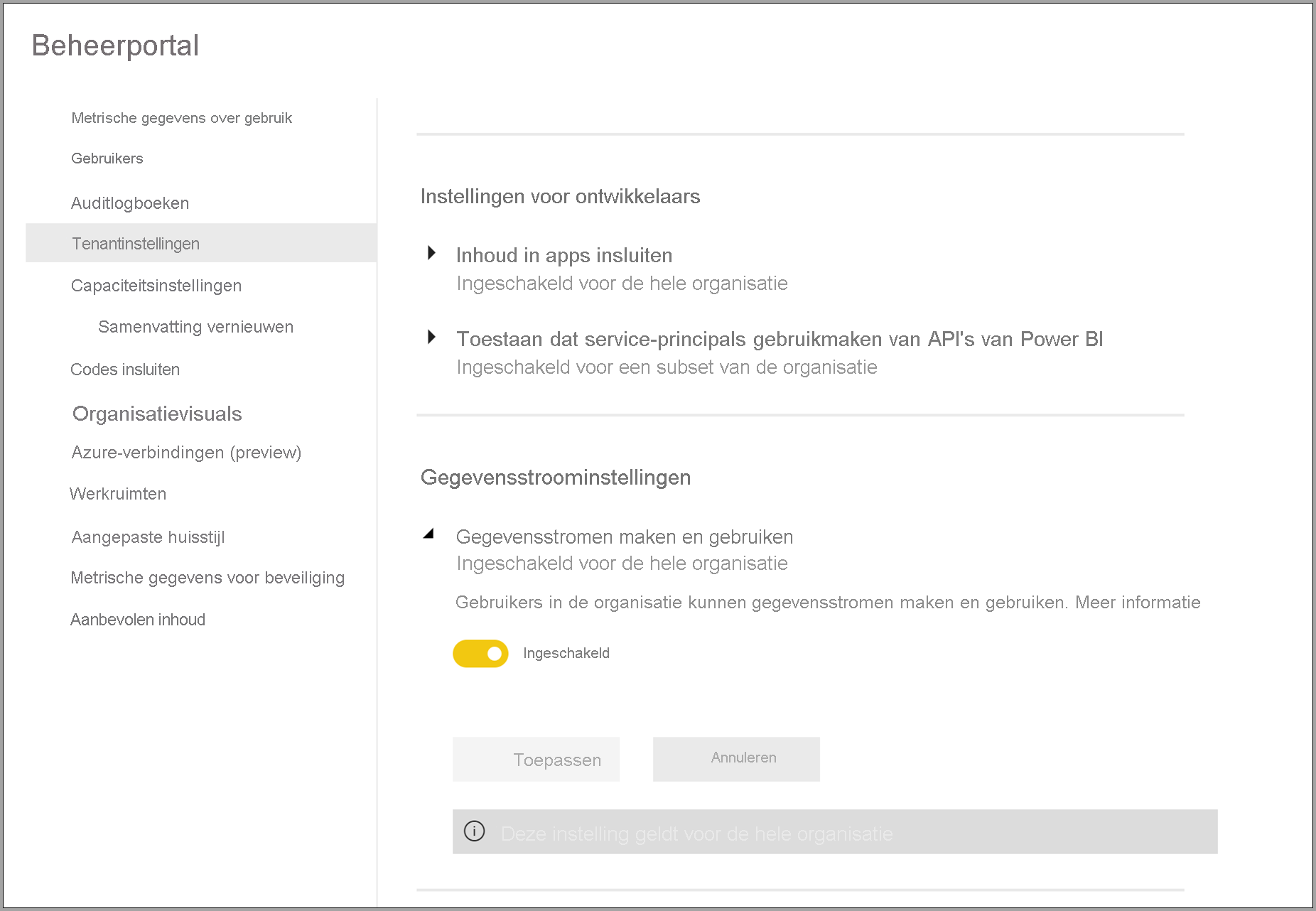
Nadat de werkbelasting voor gegevensstromen is ingeschakeld, wordt deze geconfigureerd met standaardinstellingen. Mogelijk wilt u deze instellingen aanpassen naar wens. Vervolgens beschrijven we waar deze instellingen zich bevinden, beschrijven ze elk en helpen we u te begrijpen wanneer u de waarden wilt wijzigen om de prestaties van uw gegevensstroom te optimaliseren.
Gegevensstroominstellingen verfijnen in Premium
Zodra gegevensstromen zijn ingeschakeld, kunt u de Beheer-portal gebruiken om te wijzigen of verfijnen hoe gegevensstromen worden gemaakt en hoe ze resources gebruiken in uw Power BI Premium-abonnement. Voor Power BI Premium hoeven geen geheugeninstellingen te worden gewijzigd. Geheugen in Power BI Premium wordt automatisch beheerd door het onderliggende systeem. In de volgende stappen ziet u hoe u de instellingen voor uw gegevensstroom kunt aanpassen.
Selecteer in de Beheer-portal tenantinstellingen om alle capaciteiten weer te geven die zijn gemaakt. Selecteer een capaciteit om de instellingen te beheren.
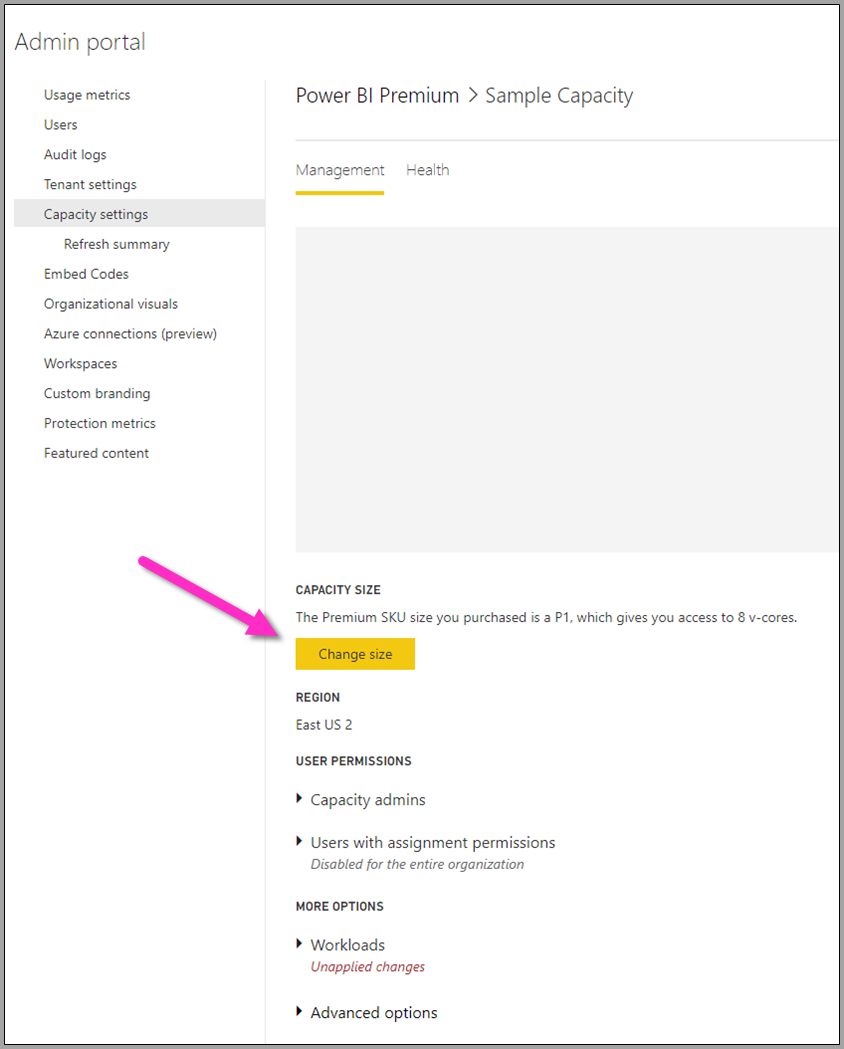
Uw Power BI Premium-capaciteit weerspiegelt de resources die beschikbaar zijn voor uw gegevensstromen. U kunt de grootte van uw capaciteit wijzigen door de knop Grootte wijzigen te selecteren, zoals wordt weergegeven in de volgende afbeelding.
Premium-capaciteitS-SKU's : de hardware omhoog schalen
Power BI Premium-workloads maken gebruik van v-cores om snelle query's uit te voeren voor de verschillende workloadtypen. Capaciteiten en SKU's bevatten een grafiek die de huidige specificaties illustreert voor elk van de beschikbare workloadaanbiedingen. Capaciteiten van A3 en hoger kunnen profiteren van de rekenengine, dus als u de verbeterde berekeningsengine wilt gebruiken, begint u daar.
Verbeterde berekeningsengine: een mogelijkheid om de prestaties te verbeteren
De verbeterde berekeningsengine is een engine die uw query's kan versnellen. Power BI maakt gebruik van een rekenengine om uw query's en vernieuwingsbewerkingen te verwerken. De verbeterde berekeningsengine is een verbetering ten opzichte van de standaardengine en werkt door gegevens naar een SQL-cache te laden en SQL te gebruiken om de transformatie van tabellen te versnellen, bewerkingen te vernieuwen en DirectQuery-connectiviteit mogelijk te maken. Wanneer deze is geconfigureerd voor Aan of Geoptimaliseerd voor berekende entiteiten, als uw bedrijfslogica dit toestaat, maakt Power BI gebruik van SQL om de prestaties te versnellen. Als de engine ingeschakeld is, is er ook directQuery-connectiviteit mogelijk. Zorg ervoor dat het gebruik van uw gegevensstroom gebruikmaakt van de verbeterde berekeningsengine. Gebruikers kunnen configureren dat de verbeterde berekeningsengine is ingeschakeld, geoptimaliseerd of uitgeschakeld per gegevensstroom.
Notitie
De verbeterde berekeningsengine is nog niet beschikbaar in alle regio's.
Richtlijnen voor veelvoorkomende scenario's
Deze sectie bevat richtlijnen voor veelvoorkomende scenario's bij het gebruik van gegevensstroomworkloads met Power BI Premium.
Trage vernieuwingstijden
Trage vernieuwingstijden zijn meestal een parallellismeprobleem. Bekijk de volgende opties, in volgorde:
Een belangrijk concept voor trage vernieuwingstijden is de aard van uw gegevensvoorbereiding. Wanneer u uw trage vernieuwingstijden kunt optimaliseren door gebruik te maken van uw gegevensbron om daadwerkelijk de voorbereiding uit te voeren en querylogica vooraf uit te voeren, moet u dit doen. Als u een relationele database zoals SQL als bron gebruikt, controleert u of de eerste query op de bron kan worden uitgevoerd en gebruikt u die bronquery voor de eerste extractiegegevensstroom voor de gegevensbron. Als u geen systeemeigen query in het bronsysteem kunt gebruiken, voert u bewerkingen uit die de gegevensstroomengine kan vouwen naar de gegevensbron.
Evalueer het uitspreiden van vernieuwingstijden op dezelfde capaciteit. Vernieuwingsbewerkingen zijn een proces dat aanzienlijke rekenkracht vereist. Met onze restaurantanalogie is het spreiden van vernieuwingstijden vergelijkbaar met het beperken van het aantal gasten in uw restaurant. Net zoals restaurants gasten plannen en capaciteit plannen, wilt u ook overwegen om vernieuwingsbewerkingen te overwegen wanneer het gebruik zich niet op de volle piek bevindt. Dit kan een lange weg gaan naar het verlichten van de belasting van de capaciteit.
Als de stappen in deze sectie niet de gewenste mate van parallelle uitvoering bieden, kunt u overwegen om uw capaciteit te upgraden naar een hogere SKU. Volg vervolgens de vorige stappen in deze volgorde opnieuw.
De berekeningsengine gebruiken om de prestaties te verbeteren
Voer de volgende stappen uit om workloads in te schakelen om de berekeningsengine te activeren en de prestaties altijd te verbeteren:
Voor berekende en gekoppelde entiteiten in dezelfde werkruimte:
Voor opnamefocus op het zo snel mogelijk ophalen van de gegevens in de opslag, gebruikt u alleen filters als ze de totale grootte van de gegevensset verkleinen. Het is raadzaam om uw transformatielogica gescheiden te houden van deze stap en de engine te laten focussen op de eerste verzameling ingrediënten. Scheid vervolgens uw transformatie en bedrijfslogica in een afzonderlijke gegevensstroom in dezelfde werkruimte, met behulp van gekoppelde of berekende entiteiten; Hierdoor kan de engine uw berekeningen activeren en versnellen. Uw logica moet afzonderlijk worden voorbereid voordat deze kan profiteren van de berekeningsengine.
Zorg ervoor dat u de bewerkingen uitvoert die worden samengevouwen, zoals samenvoegingen, joins, conversie en andere bewerkingen.
Gegevensstromen bouwen binnen gepubliceerde richtlijnen en beperkingen.
U kunt ook DirectQuery gebruiken.
De berekeningsengine is ingeschakeld, maar de prestaties zijn traag
Voer de volgende stappen uit bij het onderzoeken van scenario's waarin de compute-engine is ingeschakeld, maar u ziet tragere prestaties:
Beperk berekende en gekoppelde entiteiten die in de werkruimte bestaan.
Wanneer u de eerste vernieuwing uitvoert terwijl de berekeningsengine is ingeschakeld, worden de gegevens geschreven in de lake en in de cache. Deze dubbele schrijfbewerking betekent dat deze vernieuwingen langzamer zijn.
Als u een gegevensstroom hebt die is gekoppeld aan meerdere gegevensstromen, moet u ervoor zorgen dat u vernieuwingen van de brongegevensstromen plant, zodat ze niet allemaal tegelijk worden vernieuwd.
Gerelateerde inhoud
De volgende artikelen bevatten meer informatie over gegevensstromen en Power BI:
Feedback
Binnenkort: Gedurende 2024 wordt GitHub Issues uitgefaseerd als het feedbackmechanisme voor inhoud. Dit wordt vervangen door een nieuw feedbacksysteem. Ga voor meer informatie naar: https://aka.ms/ContentUserFeedback.
Feedback verzenden en bekijken voor