Document Intelligence algemeen documentmodel
Belangrijk
Vanaf Document Intelligence-versies 2024-02-29-preview, 2023-10-31-preview en in de toekomst wordt het algemene documentmodel (prebuilt-document) afgeschaft. Gebruik de volgende modellen om sleutel-waardeparen, selectiemarkeringen, tekst, tabellen en structuur uit documenten te extraheren:
| Functie | version | Model-id |
|---|---|---|
Layout model waarbij de optionele queryreeksparameter features=keyValuePairs is ingeschakeld. |
• v4:2024-02-29-preview • v3.1:2023-07-31 (GA) |
prebuilt-layout |
| Algemeen documentmodel | • v3.1:2023-07-31 (GA) • v3.0:2022-08-31 (GA) • v2.1 (GA) |
prebuilt-document |
Deze inhoud is van toepassing op:![]() v3.1 (GA) | Nieuwste versie:
v3.1 (GA) | Nieuwste versie:![]() v4.0 (preview) | Vorige versie:
v4.0 (preview) | Vorige versie:![]() v3.0
v3.0
Deze inhoud is van toepassing op:![]() v3.0 (GA) | Nieuwste versies:
v3.0 (GA) | Nieuwste versies:![]() v4.0 (preview)
v4.0 (preview)![]() v3.1
v3.1
Het algemene documentmodel combineert krachtige OCR-mogelijkheden (Optical Character Recognition) met deep learning-modellen om sleutel-waardeparen, tabellen en selectiemarkeringen uit documenten te extraheren. Algemeen document is beschikbaar met de v3.1- en v3.0-API's. Zie onze migratiehandleiding voor meer informatie.
Algemene documentfuncties
Het algemene documentmodel is een vooraf getraind model; hiervoor zijn geen labels of training vereist.
Met één API worden sleutel-waardeparen, selectiemarkeringen, tekst, tabellen en structuur uit documenten geëxtraheerd.
Het algemene documentmodel ondersteunt gestructureerde, semi-gestructureerde en ongestructureerde documenten.
Selectiemarkeringen worden aangeduid als velden met een waarde van
:selected:of:unselected:.
Voorbeelddocument dat is verwerkt in Document Intelligence Studio
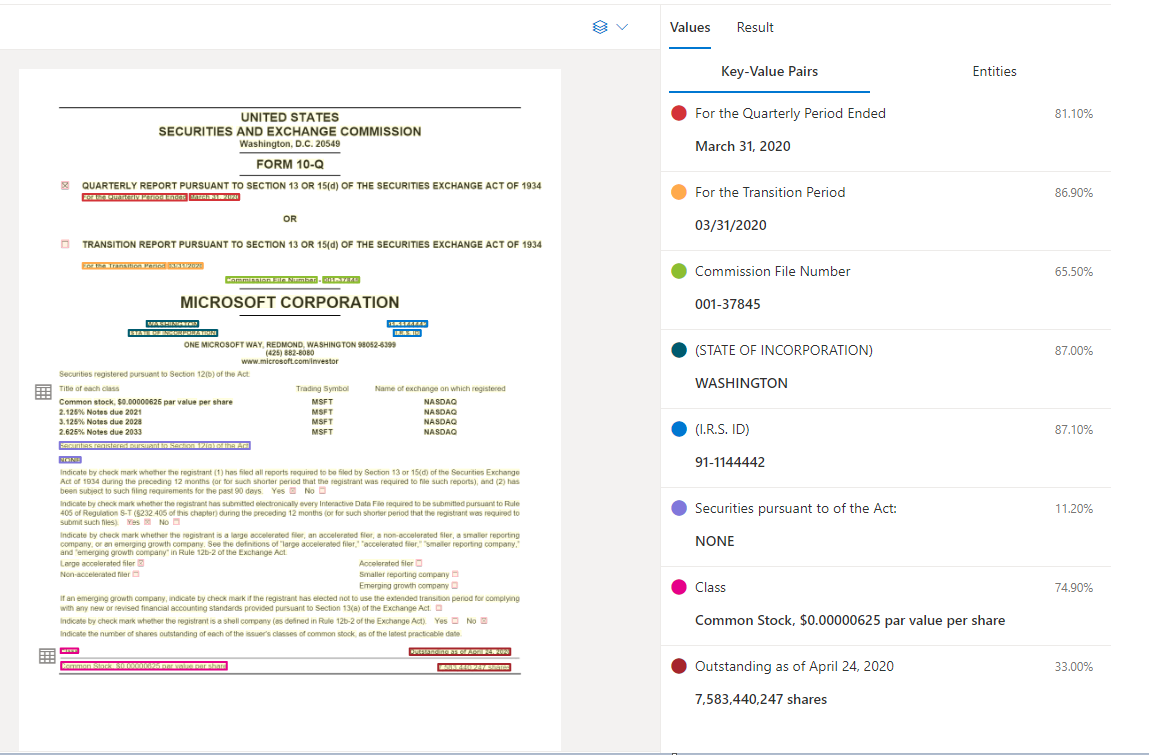
Sleutel-waardeparextractie
De algemene document-API ondersteunt de meeste formuliertypen en analyseert uw documenten en extraheert sleutels en bijbehorende waarden. Het is ideaal voor het extraheren van algemene sleutel-waardeparen uit documenten. U kunt het algemene documentmodel gebruiken als alternatief voor het trainen van een aangepast model zonder labels.
Ontwikkelingsopties
Document Intelligence v3.1 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Resources | Model-id |
|---|---|---|
| Algemeen documentmodel | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
vooraf samengesteld document |
Document Intelligence v3.0 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Resources | Model-id |
|---|---|---|
| Algemeen documentmodel | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
vooraf samengesteld document |
Vereisten voor invoer
Geef voor de beste resultaten één duidelijke foto of een hoogwaardige scan per document op.
Ondersteunde bestandsindelingen:
Model PDF Afbeelding:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) en HTMLRead ✔ ✔ ✔ Indeling ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Algemeen document ✔ ✔ Vooraf gebouwd ✔ ✔ Aangepaste extractie ✔ ✔ Aangepaste classificatie ✔ ✔ ✔ (2024-02-29-preview) Voor PDF en TIFF kunnen maximaal 2000 pagina's worden verwerkt (met een abonnement op de gratis laag worden alleen de eerste twee pagina's verwerkt).
De bestandsgrootte voor het analyseren van documenten is 500 MB voor betaalde (S0) laag en 4 MB gratis (F0).
De afmetingen van de afbeelding moeten tussen 50 x 50 pixels en 10.000 pixels x 10.000 pixels zijn.
Als uw PDF's zijn vergrendeld met een wachtwoord, moet u de vergrendeling verwijderen voordat u ze indient.
De minimale hoogte van de tekst die moet worden geëxtraheerd, is 12 pixels voor een afbeelding van 1024 x 768 pixels. Deze dimensie komt overeen met ongeveer
8-punttekst op 150 punten per inch (DPI).Voor aangepaste modeltraining is het maximum aantal pagina's voor trainingsgegevens 500 voor het aangepaste sjabloonmodel en 50.000 voor het aangepaste neurale model.
Voor het trainen van aangepaste extractiemodellen is de totale grootte van trainingsgegevens 50 MB voor het sjabloonmodel en 1G-MB voor het neurale model.
Voor het trainen van aangepast classificatiemodel is
1GBde totale grootte van trainingsgegevens maximaal 10.000 pagina's.
Algemene gegevensextractie van documentmodel
Probeer gegevens uit formulieren en documenten te extraheren met behulp van Document Intelligence Studio.
U hebt de volgende resources nodig:
Een Azure-abonnement: u kunt er gratis een maken.
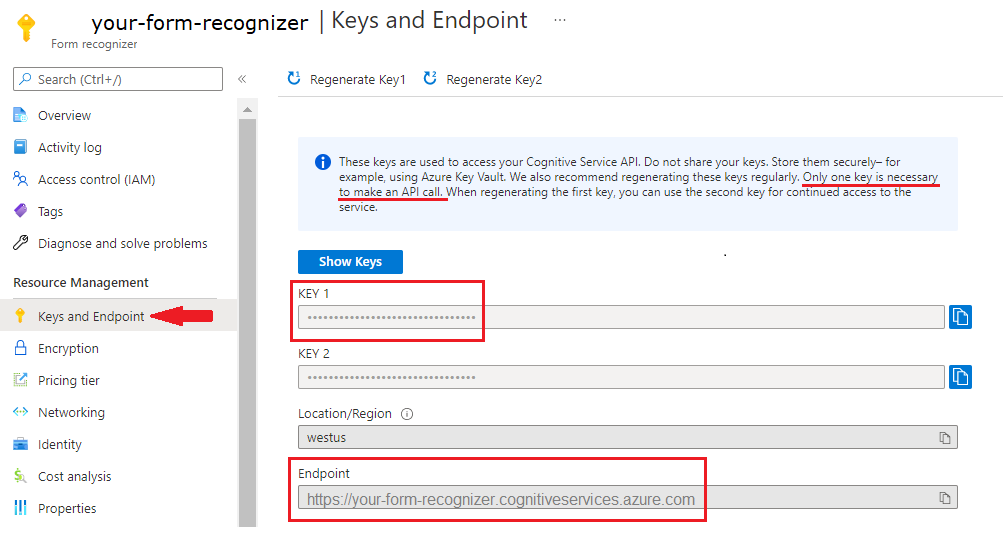
Een Document Intelligence-exemplaar in Azure Portal. U kunt de gratis prijscategorie (
F0) gebruiken om de service te proberen. Nadat uw resource is geïmplementeerd, selecteert u Ga naar de resource om uw sleutel en eindpunt op te halen.
Notitie
Document Intelligence Studio en het algemene documentmodel zijn beschikbaar met de v3.0-API.
Selecteer algemene documenten op de startpagina van Document Intelligence Studio.
U kunt het voorbeelddocument analyseren of uw eigen bestanden uploaden.
Selecteer de knop Analyse uitvoeren en configureer indien nodig de opties analyseren:

Sleutel-waardeparen
Sleutel-waardeparen zijn specifieke spanten binnen het document waarmee een label of sleutel en de bijbehorende reactie of waarde worden geïdentificeerd. In een gestructureerd formulier kunnen deze paren het label zijn en de waarde die de gebruiker voor dat veld heeft ingevoerd. In een ongestructureerd document kunnen ze de datum zijn waarop een contract is uitgevoerd op basis van de tekst in een alinea. Het AI-model is getraind om identificeerbare sleutels en waarden te extraheren op basis van een groot aantal documenttypen, indelingen en structuren.
Sleutels kunnen ook geïsoleerd bestaan wanneer het model detecteert dat er een sleutel bestaat, zonder gekoppelde waarde of bij het verwerken van optionele velden. In sommige gevallen kan bijvoorbeeld een veld met een middelste naam leeg blijven in een formulier. Sleutel-waardeparen zijn tekstbereiken in het document. Voor documenten waarbij dezelfde waarde op verschillende manieren wordt beschreven, bijvoorbeeld klant/gebruiker, is de bijbehorende sleutel klant of gebruiker (op basis van context).
Gegevensextractie
| Model | Tekstextractie | Sleutel-waardeparen | Selectiemarkeringen | Tabellen | Algemene namen |
|---|---|---|---|---|---|
| Algemeen document | ✓ | ✓ | ✓ | ✓ | ✓* |
✓* - Alleen beschikbaar in de 2023-07-31 API-versies (v3.1) en latere API-versies.
Ondersteunde talen en landinstellingen
Zie onze pagina Taalondersteuning: documentanalysemodellen voor een volledige lijst met ondersteunde talen.
Overwegingen
Omdat sleutels uit het document bestaan uit tekst die uit het document is geëxtraheerd, moeten sleutels worden toegewezen aan een bestaande woordenlijst met sleutels.
Verwacht dat sleutel-waardeparen worden weergegeven met een sleutel, maar geen waarde. Als een gebruiker bijvoorbeeld geen e-mailadres opgeeft in het formulier.
Volgende stappen
Volg onze migratiehandleiding voor Document Intelligence v3.1 voor meer informatie over het gebruik van de versie v3.1 in uw toepassingen en werkstromen.
Verken onze REST API.