Document Intelligence-leesmodel
Belangrijk
- Openbare preview-versies van Document Intelligence bieden vroegtijdige toegang tot functies die actief zijn in ontwikkeling.
- Functies, benaderingen en processen kunnen veranderen, vóór algemene beschikbaarheid (GA), op basis van feedback van gebruikers.
- De openbare preview-versie van Document Intelligence-clientbibliotheken is standaard ingesteld op REST API-versie 2024-02-29-preview.
- Openbare preview-versie 2024-02-29-preview is momenteel alleen beschikbaar in de volgende Azure-regio's:
- VS - oost
- VS - west 2
- Europa -west
Deze inhoud is van toepassing op:![]() v4.0 (preview) | Vorige versies:
v4.0 (preview) | Vorige versies:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Deze inhoud is van toepassing op:![]() v3.1 (GA) | Nieuwste versie:
v3.1 (GA) | Nieuwste versie:![]() v4.0 (preview) | Vorige versies:
v4.0 (preview) | Vorige versies:![]() v3.0
v3.0
Deze inhoud is van toepassing op:![]() v3.0 (GA) | Nieuwste versies:
v3.0 (GA) | Nieuwste versies:![]() v4.0 (preview)
v4.0 (preview)![]() v3.1
v3.1
Notitie
Voor het extraheren van tekst uit externe afbeeldingen, zoals labels, straatborden en posters, gebruikt u de azure AI-afbeeldingsanalyse v4.0-leesfunctie die is geoptimaliseerd voor algemene, niet-documentafbeeldingen met een synchrone API die het gemakkelijker maakt OCR in te sluiten in scenario's met gebruikerservaring.
Het OCR-model (Document Intelligence Read Optical Character Recognition) wordt uitgevoerd met een hogere resolutie dan Azure AI Vision Lezen en extraheert afdrukken en handgeschreven tekst uit PDF-documenten en gescande afbeeldingen. Het bevat ook ondersteuning voor het extraheren van tekst uit Microsoft Word-, Excel-, PowerPoint- en HTML-documenten. Hiermee worden alinea's, tekstregels, woorden, locaties en talen gedetecteerd. Het leesmodel is de onderliggende OCR-engine voor andere vooraf samengestelde Document Intelligence-modellen, zoals Indeling, Algemeen Document, Factuur, Ontvangst, Id-document, Gezondheidsverzekeringskaart, W2 naast aangepaste modellen.
Wat is OCR voor documenten?
Optical Character Recognition (OCR) voor documenten is geoptimaliseerd voor grote tekstzware documenten in meerdere bestandsindelingen en globale talen. Het bevat functies zoals het scannen van documentafbeeldingen met een hogere resolutie voor een betere verwerking van kleinere en compacte tekst; alineadetectie; en invulbaar formulierbeheer. OCR-mogelijkheden omvatten ook geavanceerde scenario's zoals vakken met één teken en nauwkeurige extractie van sleutelvelden die vaak worden gevonden in facturen, ontvangsten en andere vooraf gedefinieerde scenario's.
Ontwikkelingsopties
Document Intelligence v4.0 (2024-02-29-preview, 2023-10-31-preview) ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Resources | Model-id |
|---|---|---|
| OCR-model lezen | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
vooraf gedefinieerde leesbewerking |
Document Intelligence v3.1 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Resources | Model-id |
|---|---|---|
| OCR-model lezen | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
vooraf gedefinieerde leesbewerking |
Document Intelligence v3.0 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Resources | Model-id |
|---|---|---|
| OCR-model lezen | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
vooraf gedefinieerde leesbewerking |
Vereisten voor invoer
Geef voor de beste resultaten één duidelijke foto of een hoogwaardige scan per document op.
Ondersteunde bestandsindelingen:
Model PDF Afbeelding:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) en HTMLRead ✔ ✔ ✔ Indeling ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Algemeen document ✔ ✔ Vooraf gebouwd ✔ ✔ Aangepaste extractie ✔ ✔ Aangepaste classificatie ✔ ✔ ✔ (2024-02-29-preview) Voor PDF en TIFF kunnen maximaal 2000 pagina's worden verwerkt (met een abonnement op de gratis laag worden alleen de eerste twee pagina's verwerkt).
De bestandsgrootte voor het analyseren van documenten is 500 MB voor betaalde (S0) laag en 4 MB gratis (F0).
De afmetingen van de afbeelding moeten tussen 50 x 50 pixels en 10.000 pixels x 10.000 pixels zijn.
Als uw PDF's zijn vergrendeld met een wachtwoord, moet u de vergrendeling verwijderen voordat u ze indient.
De minimale hoogte van de tekst die moet worden geëxtraheerd, is 12 pixels voor een afbeelding van 1024 x 768 pixels. Deze dimensie komt overeen met ongeveer
8-punttekst op 150 punten per inch (DPI).Voor aangepaste modeltraining is het maximum aantal pagina's voor trainingsgegevens 500 voor het aangepaste sjabloonmodel en 50.000 voor het aangepaste neurale model.
Voor het trainen van aangepaste extractiemodellen is de totale grootte van trainingsgegevens 50 MB voor het sjabloonmodel en 1G-MB voor het neurale model.
Voor het trainen van aangepast classificatiemodel is
1GBde totale grootte van trainingsgegevens maximaal 10.000 pagina's.
Aan de slag met het leesmodel
Probeer tekst uit formulieren en documenten te extraheren met behulp van Document Intelligence Studio. U hebt de volgende assets nodig:
Een Azure-abonnement: u kunt er gratis een maken.
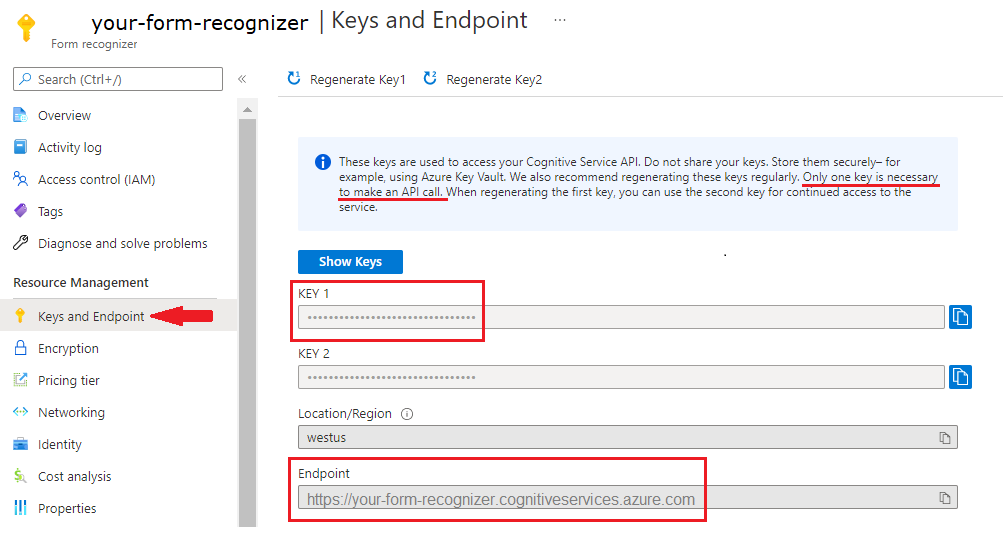
Een Document Intelligence-exemplaar in Azure Portal. U kunt de gratis prijscategorie (
F0) gebruiken om de service te proberen. Nadat uw resource is geïmplementeerd, selecteert u Ga naar de resource om uw sleutel en eindpunt op te halen.
Notitie
Op dit moment biedt Document Intelligence Studio geen ondersteuning voor Microsoft Word-, Excel-, PowerPoint- en HTML-bestandsindelingen.
Voorbeelddocument verwerkt met Document Intelligence Studio
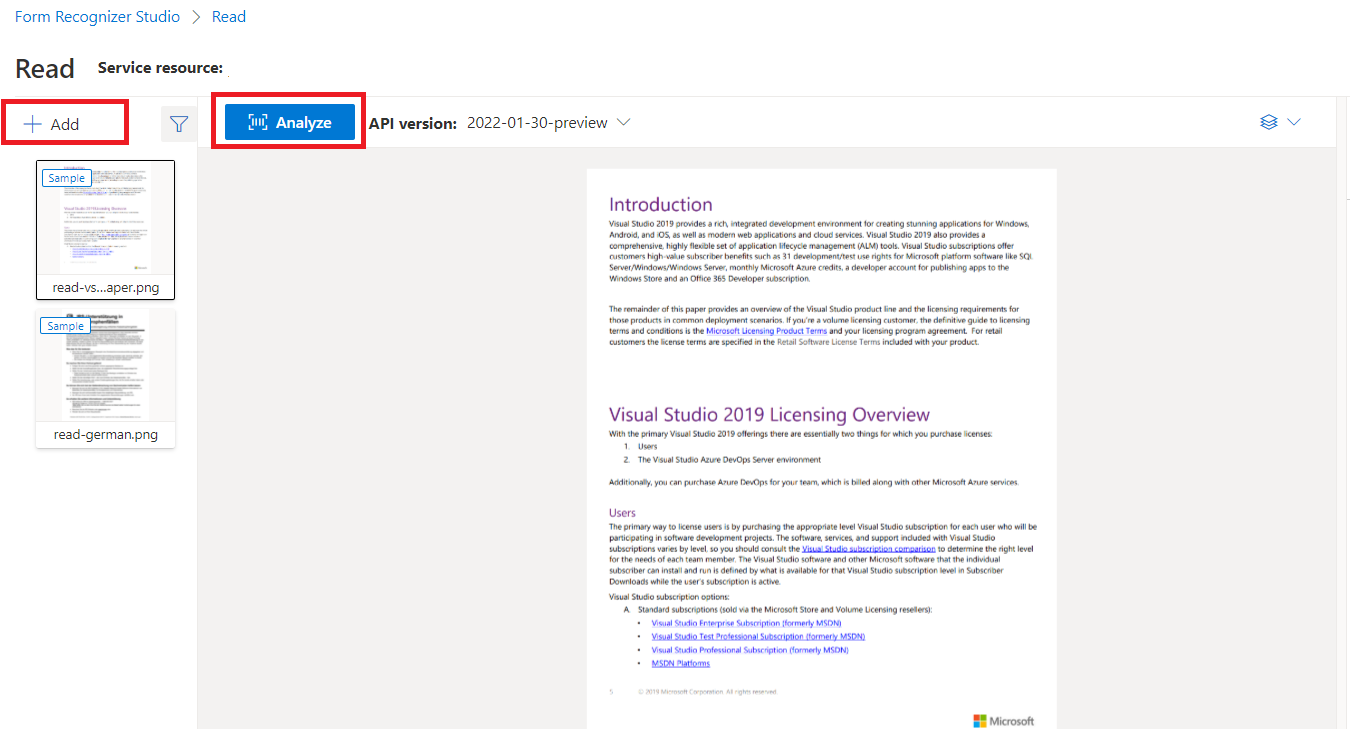
Selecteer Lezen op de startpagina van Document Intelligence Studio.
U kunt het voorbeelddocument analyseren of uw eigen bestanden uploaden.
Selecteer de knop Analyse uitvoeren en configureer indien nodig de opties analyseren:

Ondersteunde talen en landinstellingen
Zie onze pagina Taalondersteuning: documentanalysemodellen voor een volledige lijst met ondersteunde talen.
Gegevensextractie
Notitie
Microsoft Word- en HTML-bestand worden ondersteund in v3.1 en latere versies. In vergelijking met PDF en afbeeldingen worden de onderstaande functies niet ondersteund:
- Er zijn geen hoeken, breedte/hoogte en eenheid voor elk paginaobject.
- Voor elk gedetecteerd object is er geen begrenzings- of begrenzingsregio.
- Paginabereik (
pages) wordt niet ondersteund als parameter. - Geen
linesobject.
Pagina's
De verzameling pagina's is een lijst met pagina's in het document. Elke pagina wordt opeenvolgend in het document weergegeven en bevat de richtingshoek die aangeeft of de pagina wordt gedraaid en de breedte en hoogte (afmetingen in pixels). De pagina-eenheden in de modeluitvoer worden berekend zoals weergegeven:
| Bestandsindeling | Berekende pagina-eenheid | Totaal aantal pagina's |
|---|---|---|
| Afbeeldingen (JPEG/JPG, PNG, BMP, HEIF) | Elke afbeelding = 1 pagina-eenheid | Totaal aantal afbeeldingen |
| Elke pagina in de PDF = 1 pagina-eenheid | Totaal aantal pagina's in het PDF-bestand | |
| TIFF | Elke afbeelding in de TIFF = 1 pagina-eenheid | Totaal aantal afbeeldingen in de TIFF |
| Word (DOCX) | Maximaal 3000 tekens = 1 pagina-eenheid, ingesloten of gekoppelde afbeeldingen worden niet ondersteund | Totaal aantal pagina's van maximaal 3000 tekens per pagina |
| Excel (XLSX) | Elk werkblad = 1 pagina-eenheid, ingesloten of gekoppelde afbeeldingen wordt niet ondersteund | Totaal aantal werkbladen |
| PowerPoint (PPTX) | Elke dia = 1 pagina-eenheid, ingesloten of gekoppelde afbeeldingen wordt niet ondersteund | Totaal aantal dia's |
| HTML | Maximaal 3000 tekens = 1 pagina-eenheid, ingesloten of gekoppelde afbeeldingen worden niet ondersteund | Totaal aantal pagina's van maximaal 3000 tekens per pagina |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
Pagina's selecteren voor tekstextractie
Voor grote PDF-documenten met meerdere pagina's gebruikt u de pages queryparameter om specifieke paginanummers of paginabereiken aan te geven voor tekstextractie.
Leden
Het READ OCR-model in Document Intelligence extraheert alle geïdentificeerde tekstblokken in de paragraphs verzameling als een object op het hoogste niveau onder analyzeResults. Elke vermelding in deze verzameling vertegenwoordigt een tekstblok en bevat de geëxtraheerde tekst alscontent en de begrenzingscoördinaten polygon . De span informatie verwijst naar het tekstfragment in de eigenschap op het hoogste niveau content die de volledige tekst uit het document bevat.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Tekst, regels en woorden
Het OCR-model Lezen extraheert tekst in afdruk- en handgeschreven stijl als lines en words. Het model voert begrenzingscoördinaten polygon en confidence voor de geëxtraheerde woorden uit. De styles verzameling bevat een handgeschreven stijl voor lijnen als deze worden gedetecteerd, samen met de spanten die verwijzen naar de bijbehorende tekst. Deze functie is van toepassing op ondersteunde handgeschreven talen.
Voor Microsoft Word, Excel, PowerPoint en HTML extraheert Document Intelligence Read model v3.1 en latere versies alle ingesloten tekst zoals dat is. Teksten worden als woorden en alinea's uitgeleverd. Ingesloten afbeeldingen worden niet ondersteund.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
Handgeschreven stijl voor tekstregels
Het antwoord omvat het classificeren of elke tekstregel een handschriftstijl heeft of niet, samen met een betrouwbaarheidsscore. Zie handgeschreven taalondersteuning voor meer informatie. In het volgende voorbeeld ziet u een voorbeeld van een JSON-fragment.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Als u de mogelijkheid voor de invoegtoepassing lettertype/stijl hebt ingeschakeld, krijgt u ook het resultaat lettertype/stijl als onderdeel van het styles object.
Volgende stappen
Voltooi een quickstart voor Document Intelligence:
Verken onze REST API: