Deze referentiearchitectuur laat zien hoe u neurale overdracht toepast op een video met behulp van Azure Machine Learning. Stijloverdracht is een deep learning-techniek die een bestaande afbeelding samenstelt in de stijl van een andere afbeelding. U kunt deze architectuur generaliseren voor elk scenario dat gebruikmaakt van batchgewijs scoren met deep learning.
Architectuur
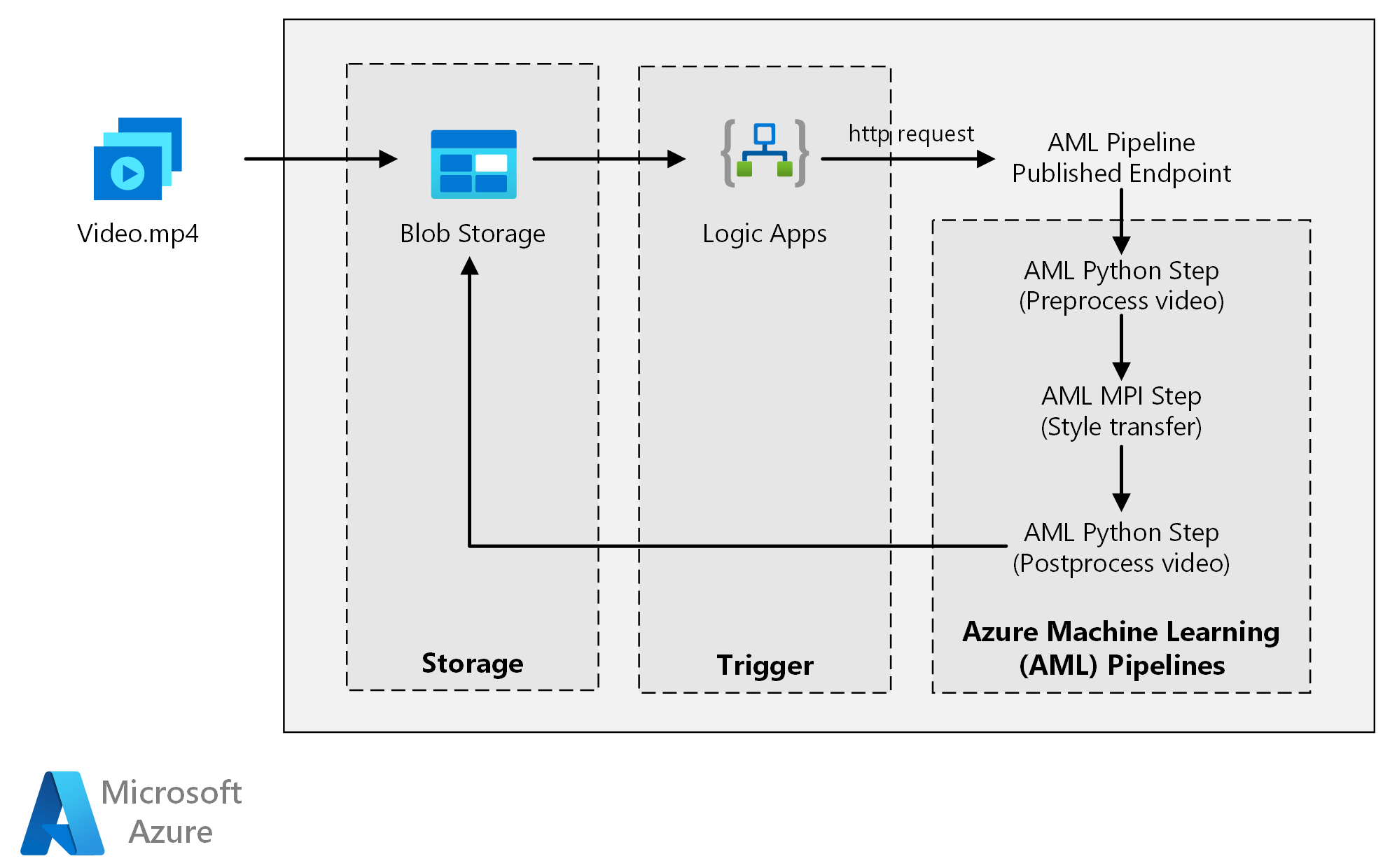
Een Visio-bestand van deze architectuur downloaden.
Workflow
Deze architectuur bestaat uit de volgende onderdelen.
Compute
Azure Machine Learning maakt gebruik van pijplijnen om reproduceerbare en eenvoudig te beheren reeksen berekeningen te maken. Het biedt ook een beheerd rekendoel (waarop een pijplijnberekening kan worden uitgevoerd) met de naam Azure Machine Learning Compute voor het trainen, implementeren en scoren van machine learning-modellen.
Storage
In Azure Blob Storage worden alle afbeeldingen opgeslagen (invoerafbeeldingen, stijlafbeeldingen en uitvoerafbeeldingen). Azure Machine Learning kan worden geïntegreerd met Blob Storage, zodat gebruikers geen gegevens handmatig hoeven te verplaatsen tussen rekenplatforms en blobopslag. Blob Storage is ook rendabel voor de prestaties die deze workload nodig heeft.
Activator
Azure Logic Apps activeert de werkstroom. Wanneer de logische app detecteert dat een blob is toegevoegd aan de container, wordt de Azure Machine Learning-pijplijn geactiveerd. Logic Apps is geschikt voor deze referentiearchitectuur, omdat het een eenvoudige manier is om wijzigingen in blob-opslag te detecteren, met een eenvoudig proces voor het wijzigen van de trigger.
De gegevens vooraf verwerken en naverwerken
Deze referentiearchitectuur maakt gebruik van videobeelden van een orang-oetan in een boom.
- Gebruik FFmpeg om het audiobestand uit de videobeelden te extraheren, zodat het audiobestand later weer in de uitvoervideo kan worden geplakt.
- Gebruik FFmpeg om de video op te splitsen in afzonderlijke frames. De frames worden onafhankelijk van elkaar verwerkt, parallel.
- Op dit moment kunt u neurale stijloverdracht toepassen op elk afzonderlijk frame parallel.
- Nadat elk frame is verwerkt, gebruikt u FFmpeg om de frames weer samen te plaatsen.
- Sluit ten slotte het audiobestand opnieuw aan op de restitched beelden.
Onderdelen
Details oplossing
Deze referentiearchitectuur is ontworpen voor workloads die worden geactiveerd door de aanwezigheid van nieuwe media in Azure Storage.
Verwerking omvat de volgende stappen:
- Upload een videobestand naar Azure Blob Storage.
- Het videobestand activeert Azure Logic Apps om een aanvraag te verzenden naar het gepubliceerde eindpunt van de Azure Machine Learning-pijplijn.
- De pijplijn verwerkt de video, past stijloverdracht toe met MPI en postprocesseert de video.
- De uitvoer wordt weer opgeslagen in Blob Storage zodra de pijplijn is voltooid.
Potentiële gebruikscases
Een mediaorganisatie heeft een video waarvan de stijl die ze willen wijzigen, eruitziet als een specifiek schilderij. De organisatie wil deze stijl op alle frames van de video tijdig en op geautomatiseerde wijze toepassen. Zie Image Style Transfer Using Convolutional Neural Networks (PDF) voor meer achtergrondinformatie over algoritmen voor neurale stijloverdracht.
Overwegingen
Met deze overwegingen worden de pijlers van het Azure Well-Architected Framework geïmplementeerd. Dit is een set richtlijnen die kunnen worden gebruikt om de kwaliteit van een workload te verbeteren. Zie Microsoft Azure Well-Architected Framework voor meer informatie.
Prestatie-efficiëntie
Prestatie-efficiëntie is de mogelijkheid om op efficiënte wijze uw werkbelasting te schalen om te voldoen aan de vereisten die gebruikers eraan stellen. Zie overzicht van de pijler Prestatie-efficiëntie voor meer informatie.
GPU versus CPU
Voor deep learning-workloads leveren GPU's over het algemeen een aanzienlijke hoeveelheid CPU's uit, in de mate dat een groot cluster cpu's doorgaans nodig is om vergelijkbare prestaties te krijgen. Hoewel u in deze architectuur alleen CPU's kunt gebruiken, bieden GPU's een veel beter kosten-/prestatieprofiel. We raden u aan om de nieuwste NCv3-serie met geoptimaliseerde GPU-VM's te gebruiken.
GPU's zijn niet standaard ingeschakeld in alle regio's. Zorg ervoor dat u een regio selecteert waarvoor GPU's zijn ingeschakeld. Daarnaast hebben abonnementen een standaardquotum van nul kernen voor vm's die zijn geoptimaliseerd voor GPU. U kunt dit quotum verhogen door een ondersteuningsaanvraag te openen. Zorg ervoor dat uw abonnement voldoende quotum heeft om uw workload uit te voeren.
Parallelliseren tussen VM's versus kernen
Wanneer u een proces voor stijloverdracht uitvoert als batchtaak, moeten de taken die voornamelijk op GPU's worden uitgevoerd, parallel worden uitgevoerd op vm's. Er zijn twee benaderingen mogelijk: u kunt een groter cluster maken met behulp van VM's met één GPU of een kleiner cluster maken met behulp van VM's met veel GPU's.
Voor deze workload hebben deze twee opties vergelijkbare prestaties. Het gebruik van minder VM's met meer GPU's per VM kan helpen bij het verminderen van gegevensverplaatsing. Het gegevensvolume per taak voor deze workload is echter niet groot, dus u ziet niet veel beperking door Blob Storage.
MPI-stap
Bij het maken van de Azure Machine Learning-pijplijn is een van de stappen die worden gebruikt om parallelle berekeningen uit te voeren de MPI-stap (berichtverwerkingsinterface). De MPI-stap helpt de gegevens gelijkmatig over de beschikbare knooppunten te splitsen. De MPI-stap wordt pas uitgevoerd als alle aangevraagde knooppunten gereed zijn. Als één knooppunt mislukt of wordt geprempt (als het een virtuele machine met lage prioriteit is), moet de MPI-stap opnieuw worden uitgevoerd.
Beveiliging
Beveiliging biedt garanties tegen opzettelijke aanvallen en misbruik van uw waardevolle gegevens en systemen. Zie Overzicht van de beveiligingspijler voor meer informatie. Deze sectie bevat overwegingen voor het bouwen van veilige oplossingen.
Toegang tot Azure Blob Storage beperken
In deze referentiearchitectuur is Azure Blob Storage het belangrijkste opslagonderdeel dat moet worden beveiligd. De basislijnimplementatie die wordt weergegeven in de GitHub-opslagplaats maakt gebruik van opslagaccountsleutels voor toegang tot de blobopslag. Voor verdere controle en beveiliging kunt u in plaats daarvan een SAS (Shared Access Signature) gebruiken. Hiermee verleent u beperkte toegang tot objecten in de opslag, zonder dat u de accountsleutels hoeft te coderen of ze in tekst zonder opmaak hoeft op te slaan. Deze methode is vooral handig omdat accountsleutels zichtbaar zijn in tekst zonder opmaak in de ontwerpinterface van de logische app. Het gebruik van een SAS helpt ook ervoor te zorgen dat het opslagaccount over de juiste governance beschikt en dat alleen toegang wordt verleend aan de personen die het willen hebben.
Voor scenario's met gevoeligere gegevens moet u ervoor zorgen dat al uw opslagsleutels zijn beveiligd, omdat deze sleutels volledige toegang verlenen tot alle invoer- en uitvoergegevens van de workload.
Gegevensversleuteling en gegevensverplaatsing
Deze referentiearchitectuur maakt gebruik van stijloverdracht als voorbeeld van een batchscoreproces. Voor meer gegevensgevoelige scenario's moeten de gegevens in de opslag in rust worden versleuteld. Telkens wanneer gegevens van de ene locatie naar de andere worden verplaatst, gebruikt u Transport Layer Security (TSL) om de gegevensoverdracht te beveiligen. Zie de Beveiligingshandleiding voor Azure Storage voor meer informatie.
Uw berekening beveiligen in een virtueel netwerk
Wanneer u uw Machine Learning-rekencluster implementeert, kunt u configureren dat uw cluster wordt ingericht in een subnet van een virtueel netwerk. Met dit subnet kunnen de rekenknooppunten in het cluster veilig communiceren met andere virtuele machines.
Bescherming tegen schadelijke activiteiten
In scenario's waarin meerdere gebruikers zijn, moet u ervoor zorgen dat gevoelige gegevens zijn beveiligd tegen schadelijke activiteiten. Als andere gebruikers toegang krijgen tot deze implementatie om de invoergegevens aan te passen, moet u rekening houden met de volgende voorzorgsmaatregelen en overwegingen:
- Gebruik op rollen gebaseerd toegangsbeheer van Azure (RBAC) om de toegang van gebruikers te beperken tot alleen de resources die ze nodig hebben.
- Richt twee afzonderlijke opslagaccounts in. Sla invoer- en uitvoergegevens op in het eerste account. Externe gebruikers kunnen toegang krijgen tot dit account. Sla uitvoerbare scripts en uitvoerlogboekbestanden op in het andere account. Externe gebruikers mogen geen toegang hebben tot dit account. Deze scheiding zorgt ervoor dat externe gebruikers geen uitvoerbare bestanden kunnen wijzigen (om schadelijke code in te voeren) en geen toegang hebben tot logboekbestanden, die gevoelige informatie kunnen bevatten.
- Kwaadwillende gebruikers kunnen een DDoS-aanval uitvoeren op de taakwachtrij of verkeerd gevormde gifberichten in de taakwachtrij injecteren, waardoor het systeem fouten kan vergrendelen of veroorzaken.
Kostenoptimalisatie
Kostenoptimalisatie gaat over manieren om onnodige uitgaven te verminderen en operationele efficiëntie te verbeteren. Zie Overzicht van de pijler kostenoptimalisatie voor meer informatie.
Vergeleken met de opslag- en planningsonderdelen, beheersen de rekenresources die in deze referentiearchitectuur worden gebruikt verreweg wat betreft kosten. Een van de belangrijkste uitdagingen is het effectief parallelliseren van het werk in een cluster met GPU-machines.
De grootte van het Azure Machine Learning Compute-cluster kan automatisch omhoog en omlaag worden geschaald, afhankelijk van de taken in de wachtrij. U kunt automatische schaalaanpassing programmatisch inschakelen door het minimum en maximum aantal knooppunten in te stellen.
Voor werk waarvoor geen onmiddellijke verwerking is vereist, configureert u automatisch schalen, zodat de standaardstatus (minimum) een cluster van nulknooppunten is. Met deze configuratie begint het cluster met nul knooppunten en wordt het alleen omhoog geschaald wanneer taken in de wachtrij worden gedetecteerd. Als het batchscoreproces slechts een paar keer per dag of minder plaatsvindt, leidt deze instelling tot aanzienlijke kostenbesparingen.
Automatisch schalen is mogelijk niet geschikt voor batchtaken die te dicht bij elkaar plaatsvinden. De tijd die nodig is om een cluster op te zetten en uit te schakelen, kost ook kosten. Als een batchworkload dus slechts enkele minuten na het einde van de vorige taak begint, kan het rendabeler zijn om het cluster tussen taken actief te houden.
Azure Machine Learning Compute biedt ook ondersteuning voor virtuele machines met lage prioriteit, waarmee u uw berekening kunt uitvoeren op gereduceerde virtuele machines, met het nadeel dat ze op elk gewenst moment kunnen worden afgewend. Virtuele machines met lage prioriteit zijn ideaal voor niet-kritieke workloads voor batchscores.
Batchtaken bewaken
Tijdens het uitvoeren van uw taak is het belangrijk om de voortgang te controleren en ervoor te zorgen dat de taak werkt zoals verwacht. Het kan echter een uitdaging zijn om te bewaken in een cluster met actieve knooppunten.
Als u de algehele status van het cluster wilt controleren, gaat u naar de Machine Learning-service in Azure Portal om de status van de knooppunten in het cluster te controleren. Als een knooppunt inactief is of als een taak is mislukt, worden de foutenlogboeken opgeslagen in Blob Storage en zijn ze ook toegankelijk in Azure Portal.
Bewaking kan verder worden verrijkt door logboeken te verbinden met Application Insights of door afzonderlijke processen uit te voeren om te peilen naar de status van het cluster en de bijbehorende taken.
Aanmelden met Azure Machine Learning
Met Azure Machine Learning worden alle stdout/stderr automatisch vastgelegd in het bijbehorende Blob Storage-account. Tenzij anders opgegeven, wordt in uw Azure Machine Learning-werkruimte automatisch een opslagaccount ingericht en worden uw logboeken hierin gedumpt. U kunt ook een hulpprogramma voor opslagnavigatie gebruiken, zoals Azure Storage Explorer. Dit is een eenvoudigere manier om door logboekbestanden te navigeren.
Dit scenario implementeren
Als u deze referentiearchitectuur wilt implementeren, volgt u de stappen die worden beschreven in de GitHub-opslagplaats.
U kunt ook een architectuur voor batchgewijs scoren implementeren voor Deep Learning-modellen met behulp van de Azure Kubernetes Service. Volg de stappen die worden beschreven in deze GitHub-opslagplaats.
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- Jian Tang | Program Manager II
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Volgende stappen
- Batchgewijs scoren van Spark-modellen in Azure Databricks
- Batchgewijs scoren van Python-modellen in Azure
- Batchgewijs scoren met R-modellen om de verkoop te voorspellen