Deze referentiearchitectuur laat zien hoe u batchgewijs scoren met R-modellen uitvoert met behulp van Azure Batch. Azure Batch werkt goed met intrinsiek parallelle workloads en omvat taakplanning en rekenbeheer. Batchdeductie (score) wordt veel gebruikt om klanten te segmenteren, verkoop te voorspellen, klantgedrag te voorspellen, onderhoud te voorspellen of cyberbeveiliging te verbeteren.
Een Visio-bestand van deze architectuur downloaden.
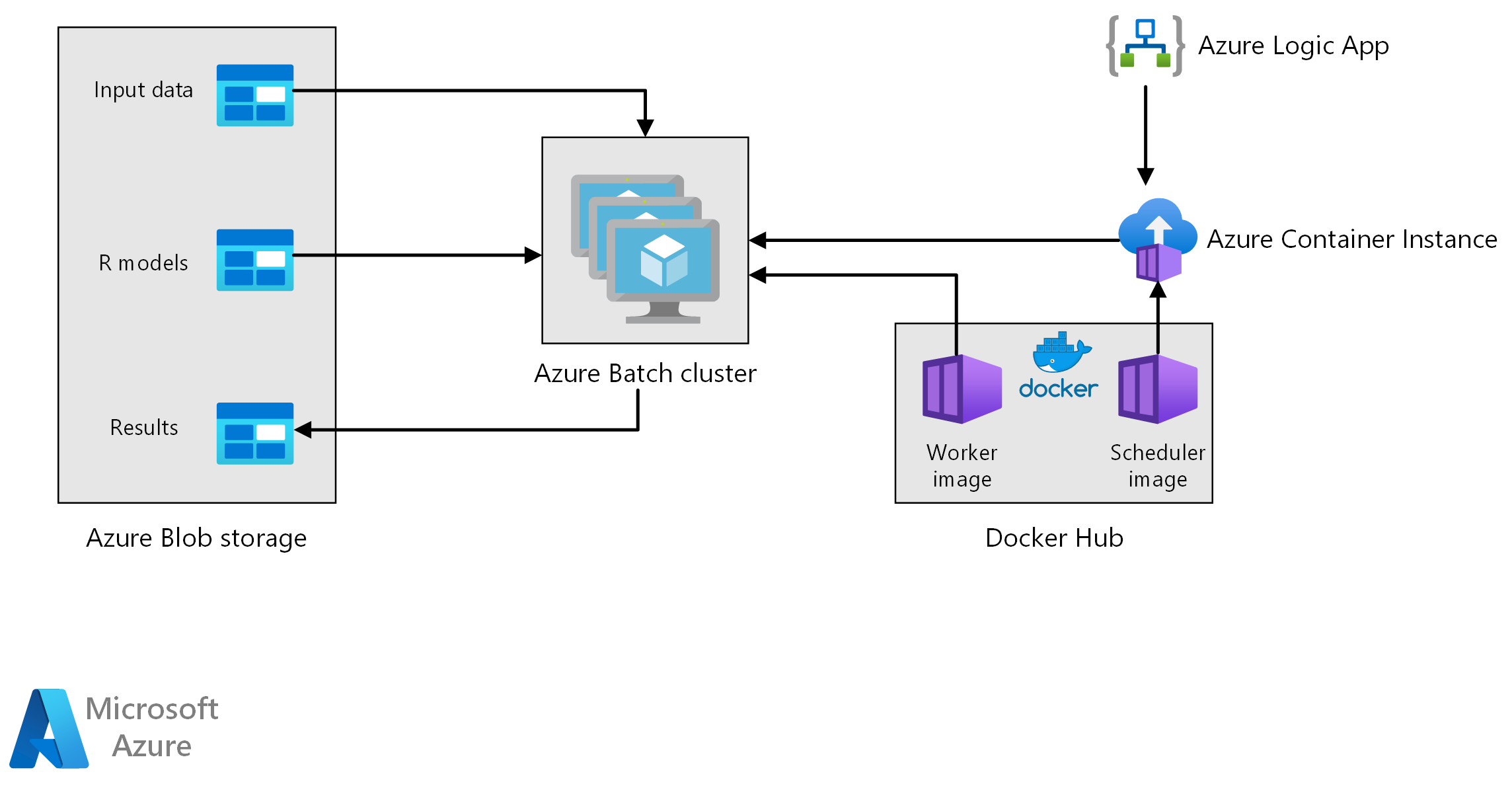
Workflow
Deze architectuur bestaat uit de volgende onderdelen.
In Azure Batch worden prognosegeneratietaken parallel uitgevoerd op een cluster met virtuele machines. Voorspellingen worden gedaan met behulp van vooraf getrainde machine learning-modellen die zijn geïmplementeerd in R. Azure Batch kan het aantal VIRTUELE machines automatisch schalen op basis van het aantal taken dat is verzonden naar het cluster. Op elk knooppunt wordt een R-script uitgevoerd in een Docker-container om gegevens te scoren en prognoses te genereren.
Azure Blob Storage slaat de invoergegevens, de vooraf getrainde machine learning-modellen en de prognoseresultaten op. Het biedt rendabele opslag voor de prestaties die deze workload nodig heeft.
Azure Container Instances biedt serverloze berekeningen op aanvraag. In dit geval wordt een containerinstantie geïmplementeerd volgens een planning om de Batch-taken te activeren die de prognoses genereren. De Batch-taken worden geactiveerd vanuit een R-script met behulp van het doAzureParallel-pakket . De containerinstantie wordt automatisch afgesloten zodra de taken zijn voltooid.
Azure Logic Apps activeert de hele werkstroom door de containerinstanties volgens een schema te implementeren. Met een Azure Container Instances-connector in Logic Apps kan een exemplaar worden geïmplementeerd op een reeks trigger-gebeurtenissen.
Onderdelen
Details oplossing
Hoewel het volgende scenario is gebaseerd op verkoopprognoses in de detailhandel, kan de architectuur worden gegeneraliseerd voor elk scenario waarvoor het genereren van voorspellingen op grotere schaal met behulp van R-modellen vereist is. Een referentie-implementatie voor deze architectuur is beschikbaar op GitHub.
Potentiële gebruikscases
Een supermarktketen moet de verkoop van producten in het komende kwartaal voorspellen. De prognose stelt het bedrijf in staat om de toeleveringsketen beter te beheren en ervoor te zorgen dat het kan voldoen aan de vraag naar producten in elk van de winkels. Het bedrijf werkt de prognoses elke week bij naarmate er nieuwe verkoopgegevens van de vorige week beschikbaar zijn en de marketingstrategie voor het volgende kwartaal is ingesteld. Kwantielprognoses worden gegenereerd om de onzekerheid van de afzonderlijke verkoopprognoses te schatten.
Verwerking omvat de volgende stappen:
Met een logische Azure-app wordt het proces voor het genereren van prognoses eenmaal per week geactiveerd.
De logische app start een Azure Container Instance waarop de Scheduler Docker-container wordt uitgevoerd, waarmee de scoretaken in het Batch-cluster worden geactiveerd.
Scoretaken worden parallel uitgevoerd op de knooppunten van het Batch-cluster. Elk knooppunt:
Haalt de Docker-installatiekopie van de werkrol op en start een container.
Leest invoergegevens en vooraf getrainde R-modellen uit Azure Blob Storage.
Beoordeelt de gegevens om prognoses te produceren.
Hiermee schrijft u prognoseresultaten naar blobopslag.
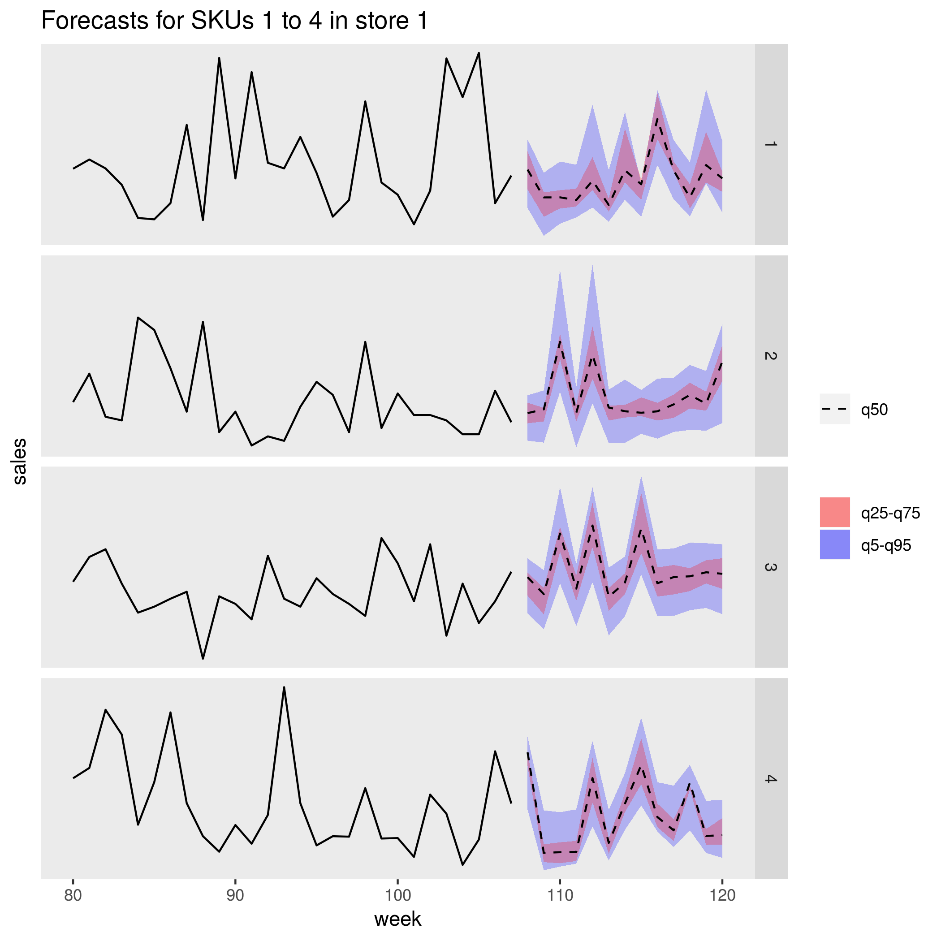
In de volgende afbeelding ziet u de voorspelde verkoop voor vier producten (SKU's) in één winkel. De zwarte lijn is de verkoopgeschiedenis, de stippellijn is de mediaanprognose (q50), de roze band vertegenwoordigt het 25e en 75e percentiel en de blauwe band vertegenwoordigt de 50e en 95e percentielen.
Overwegingen
Met deze overwegingen worden de pijlers van het Azure Well-Architected Framework geïmplementeerd. Dit is een set richtlijnen die kunnen worden gebruikt om de kwaliteit van een workload te verbeteren. Zie Microsoft Azure Well-Architected Framework voor meer informatie.
Prestaties
Gecontaineriseerde implementatie
Met deze architectuur worden alle R-scripts uitgevoerd in Docker-containers . Het gebruik van containers zorgt ervoor dat de scripts elke keer in een consistente omgeving worden uitgevoerd, met dezelfde R-versie en pakkettenversies. Afzonderlijke Docker-installatiekopieën worden gebruikt voor de planner- en werkcontainers, omdat elk een andere set R-pakketafhankelijkheden heeft.
Azure Container Instances biedt een serverloze omgeving om de scheduler-container uit te voeren. De scheduler-container voert een R-script uit waarmee de afzonderlijke scoretaken worden geactiveerd die worden uitgevoerd op een Azure Batch-cluster.
Elk knooppunt van het Batch-cluster voert de werkrolcontainer uit, waarmee het scorescript wordt uitgevoerd.
De workload parallelliseren
Wanneer u batchgewijs scoren met R-modellen, kunt u overwegen hoe u de workload parallelliseert. De invoergegevens moeten worden gepartitioneerd, zodat de scorebewerking kan worden gedistribueerd over de clusterknooppunten. Probeer verschillende benaderingen om de beste keuze te ontdekken voor het distribueren van uw workload. Houd rekening met het volgende per geval:
- Hoeveel gegevens kunnen worden geladen en verwerkt in het geheugen van één knooppunt.
- De overhead voor het starten van elke batchtaak.
- De overhead van het laden van de R-modellen.
In het scenario dat voor dit voorbeeld wordt gebruikt, zijn de modelobjecten groot en duurt het slechts enkele seconden om een prognose voor afzonderlijke producten te genereren. Daarom kunt u de producten groeperen en één Batch-taak per knooppunt uitvoeren. Een lus binnen elke taak genereert sequentieel prognoses voor de producten. Deze methode is de meest efficiënte manier om deze specifieke workload te parallelliseren. Het voorkomt de overhead van het starten van veel kleinere Batch-taken en het herhaaldelijk laden van de R-modellen.
Een alternatieve methode is om één Batch-taak per product te activeren. Azure Batch vormt automatisch een wachtrij met taken en verzendt deze om te worden uitgevoerd op het cluster zodra er knooppunten beschikbaar komen. Gebruik automatisch schalen om het aantal knooppunten in het cluster aan te passen, afhankelijk van het aantal taken. Deze methode is handig als het relatief lang duurt om elke scorebewerking te voltooien, waardoor de overhead van het starten van de taken wordt rechtvaardigd en de modelobjecten opnieuw worden geladen. Deze aanpak is ook eenvoudiger te implementeren en biedt u de flexibiliteit om automatisch schalen te gebruiken, een belangrijke overweging als de grootte van de totale workload niet van tevoren bekend is.
Azure Batch-taken bewaken
Batch-taken bewaken en beëindigen vanuit het deelvenster Taken van het Batch-account in Azure Portal. Bewaak het batchcluster, inclusief de status van afzonderlijke knooppunten, vanuit het deelvenster Pools .
Aanmelden met doAzureParallel
Het doAzureParallel-pakket verzamelt automatisch logboeken van alle stdout/stderr voor elke taak die is ingediend in Azure Batch. Deze logboeken vindt u in het opslagaccount dat tijdens de installatie is gemaakt. Als u ze wilt weergeven, gebruikt u een hulpprogramma voor opslagnavigatie, zoals Azure Storage Explorer of Azure Portal.
Als u tijdens de ontwikkeling snel fouten in Batch-taken wilt opsporen, bekijkt u de logboeken in uw lokale R-sessie. Zie voor meer informatie het gebruik van de trainingsuitvoeringen configureren en verzenden.
Kostenoptimalisatie
Kostenoptimalisatie gaat over manieren om onnodige uitgaven te verminderen en operationele efficiëntie te verbeteren. Zie Overzicht van de pijler kostenoptimalisatie voor meer informatie.
De rekenresources die in deze referentiearchitectuur worden gebruikt, zijn de duurste onderdelen. Voor dit scenario wordt een cluster met vaste grootte gemaakt wanneer de taak wordt geactiveerd en vervolgens wordt afgesloten nadat de taak is voltooid. Er worden alleen kosten gemaakt terwijl de clusterknooppunten worden gestart, uitgevoerd of afgesloten. Deze benadering is geschikt voor een scenario waarin de rekenresources die nodig zijn om de prognoses te genereren relatief constant blijven van taak naar taak.
In scenario's waarin de hoeveelheid rekenkracht die nodig is om de taak te voltooien niet van tevoren bekend is, is het mogelijk geschikter om automatisch schalen te gebruiken. Met deze benadering wordt de grootte van het cluster omhoog of omlaag geschaald, afhankelijk van de grootte van de taak. Azure Batch ondersteunt een reeks formules voor automatisch schalen, die u kunt instellen bij het definiëren van het cluster met behulp van de doAzureParallel-API .
In sommige scenario's kan de tijd tussen taken te kort zijn om het cluster af te sluiten en te starten. In dergelijke gevallen moet het cluster zo nodig tussen taken worden uitgevoerd.
Azure Batch en doAzureParallel ondersteunen het gebruik van VM's met lage prioriteit. Deze VM's hebben een aanzienlijke korting, maar risico's worden gebruikt door andere workloads met een hogere prioriteit. Daarom wordt het gebruik van VM's met lage prioriteit niet aanbevolen voor kritieke productieworkloads. Ze zijn echter handig voor experimentele of ontwikkelworkloads.
Dit scenario implementeren
Als u deze referentiearchitectuur wilt implementeren, volgt u de stappen die worden beschreven in de GitHub-opslagplaats .
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- Angus Taylor | Senior Datawetenschapper
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.