Secundaire hyperscale-replica's
Van toepassing op:![]() Azure SQL Database
Azure SQL Database
Zoals beschreven in de architectuur van gedistribueerde functies, heeft Azure SQL Database Hyperscale twee verschillende typen rekenknooppunten, ook wel replica's genoemd:
- Primair: dient lees- en schrijfbewerkingen
- Secundair: biedt uitschalen van leesbewerkingen, hoge beschikbaarheid en geo-replicatie
Secundaire replica's zijn altijd alleen-lezen en kunnen van drie verschillende typen zijn:
- Replica met hoge beschikbaarheid
- Geo-replica
- Benoemde replica
Elk type heeft een andere architectuur, functieset, doel en kosten. Op basis van de functies die u nodig hebt, kunt u slechts één of zelfs alle drie tegelijk gebruiken. Secundaire replica's worden ondersteund door zowel serverloze als ingerichte rekenlagen.
Replica met hoge beschikbaarheid
Een hoge beschikbaarheidsreplica maakt gebruik van dezelfde paginaservers als de primaire replica, dus er is geen gegevenskopie vereist om een HA-replica toe te voegen. HA-replica's worden voornamelijk gebruikt om de beschikbaarheid van databases te vergroten; ze fungeren als hot stand-bys voor failoverdoeleinden. Als de primaire replica niet meer beschikbaar is, is failover naar een van de bestaande HA-replica's automatisch en snel. De verbindingsreeks hoeft niet te veranderen. Tijdens failovertoepassingen kan er minimale downtime optreden omdat actieve verbindingen zijn verbroken. Zoals gebruikelijk voor dit scenario wordt de juiste logica voor opnieuw proberen aanbevolen. Verschillende stuurprogramma's bieden al enige mate van automatische logica voor opnieuw proberen. Als u .NET gebruikt, biedt de nieuwste Microsoft.Data.SqlClient-bibliotheek systeemeigen volledige ondersteuning voor configureerbare logica voor automatische nieuwe pogingen.
Hoge beschikbaarheidsreplica's gebruiken dezelfde server- en databasenaam als de primaire replica. Hun serviceniveaudoelstelling is ook altijd hetzelfde als voor de primaire replica. HA-replica's zijn niet zichtbaar of beheerbaar als zelfstandige resource vanuit de portal of vanuit een API.
Er kunnen maximaal vier HA-replica's zijn. Het nummer kan worden gewijzigd tijdens het maken van een database of nadat de database is gemaakt, via de algemene beheereindpunten en -hulpprogramma's (bijvoorbeeld PowerShell, AZ CLI, Portal, REST API). Het maken of verwijderen van HA-replica's heeft geen invloed op actieve verbindingen op de primaire replica.
Verbinding maken naar een replica met hoge beschikbaarheid
In Hyperscale-databases bepaalt het ApplicationIntent argument in de verbindingsreeks die door de client wordt gebruikt, of de verbinding wordt gerouteerd naar de primaire replica voor lezen/schrijven of naar een alleen-lezen HA-replica. Als ApplicationIntent deze optie is ingesteld ReadOnly op en de database geen secundaire replica heeft, wordt de verbinding gerouteerd naar de primaire replica en wordt standaard het ReadWrite gedrag gebruikt.
-- Connection string with application intent
Server=tcp:<myserver>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Alle HA-replica's zijn identiek in hun resourcecapaciteit. Als er meer dan één ha-replica aanwezig is, wordt de workload leesintentie willekeurig verdeeld over alle beschikbare HA-replica's. Wanneer er meerdere HA-replica's zijn, moet u er rekening mee houden dat elke replica een andere gegevenslatentie kan hebben met betrekking tot gegevenswijzigingen die zijn aangebracht op de primaire replica. Elke HA-replica gebruikt dezelfde gegevens als de primaire replica op dezelfde set paginaservers. Lokale gegevenscaches op elke HA-replica weerspiegelen echter de wijzigingen die zijn aangebracht op de primaire replica via de transactielogboekservice, waarmee logboekrecords van de primaire replica naar HA-replica's worden doorgestuurd. Afhankelijk van de werkbelasting die wordt verwerkt door een HA-replica, kunnen de toepassing van logboekrecords zich op verschillende snelheden voordoen en kunnen er dus verschillende replica's verschillende gegevenslatentie hebben ten opzichte van de primaire replica.
Benoemde replica
Een benoemde replica, net als een HA-replica, gebruikt dezelfde paginaservers als de primaire replica. Net als bij HA-replica's is er geen gegevenskopie nodig om een benoemde replica toe te voegen.
Er zijn verschillen tussen HA-replica's en benoemde replica's:
- Benoemde replica's worden weergegeven als gewone (alleen-lezen) Azure SQL-databases in de portal en in API-aanroepen (AZ CLI, PowerShell, T-SQL).
- Benoemde replica's kunnen een andere databasenaam hebben dan de primaire replica en eventueel op een andere logische server bevinden (zolang deze zich in dezelfde regio bevindt als de primaire replica).
- Benoemde replica's hebben hun eigen serviceniveaudoelstelling die onafhankelijk van de primaire replica kan worden ingesteld en gewijzigd.
- Ondersteuning voor benoemde replica's voor maximaal 30 benoemde replica's (voor elke primaire replica).
- Benoemde replica's ondersteunen verschillende verificatie voor elke benoemde replica door verschillende aanmeldingen te maken op logische servers die als host fungeren voor benoemde replica's.
Als gevolg hiervan bieden benoemde replica's verschillende voordelen ten opzichte van HA-replica's, wat betrekking heeft op alleen-lezen workloads:
- Gebruikers die zijn verbonden met een benoemde replica, hebben geen verbinding als de primaire replica omhoog of omlaag wordt geschaald; Tegelijkertijd worden gebruikers die zijn verbonden met de primaire replica niet beïnvloed door benoemde replica's omhoog of omlaag te schalen.
- Workloads die worden uitgevoerd op elke replica, primaire of benoemde, worden niet beïnvloed door langlopende query's die worden uitgevoerd op andere replica's.
Het belangrijkste doel van benoemde replica's is om een breed scala aan uitschaalscenario's voor lezen mogelijk te maken en om HTAP-workloads (Hybrid Transactional and Analytical Processing) te verbeteren. Voorbeelden van het maken van dergelijke oplossingen zijn hier beschikbaar:
Afgezien van de bovenstaande hoofdscenario's bieden benoemde replica's flexibiliteit en elasticiteit om ook te voldoen aan veel andere gebruiksscenario's:
- Isolatie van toegang: u kunt toegang verlenen tot een specifieke benoemde replica, maar niet de primaire replica of andere benoemde replica's.
- Doel van workloadafhankelijk serviceniveau: als een benoemde replica een eigen serviceniveaudoelstelling kan hebben, is het mogelijk om verschillende benoemde replica's te gebruiken voor verschillende workloads en use cases. Een benoemde replica kan bijvoorbeeld worden gebruikt om Power BI-aanvragen te verwerken, terwijl een andere kan worden gebruikt om gegevens te leveren aan Apache Spark voor Datawetenschap taken. Elke service kan onafhankelijk van elkaar een doelstelling op serviceniveau hebben en onafhankelijk schalen.
- Workloadafhankelijke routering: met maximaal 30 benoemde replica's is het mogelijk om benoemde replica's in groepen te gebruiken, zodat een toepassing kan worden geïsoleerd van een andere replica. Een groep van vier benoemde replica's kan bijvoorbeeld worden gebruikt voor aanvragen die afkomstig zijn van mobiele toepassingen, terwijl een andere groep twee benoemde replica's kan worden gebruikt voor aanvragen die afkomstig zijn van een webtoepassing. Met deze aanpak kunnen de prestaties en kosten voor elke groep nauwkeurig worden afgestemd.
In het volgende voorbeeld wordt een benoemde replica WideWorldImporters_NamedReplica voor de database gemaakt WideWorldImporters. De primaire replica maakt gebruik van serviceniveaudoelstelling HS_Gen5_4, terwijl de benoemde replica gebruikmaakt van HS_Gen5_2. Beide gebruiken dezelfde logische server contosoeast. Als u liever rechtstreeks REST API gebruikt, is deze optie ook mogelijk: Databases - Een database maken als secundaire replica met de naam.
Blader in Azure Portal naar de database waarvoor u de benoemde replica wilt maken.
Selecteer uw database op de pagina SQL Database, blader naar Gegevensbeheer, selecteer Replica's en selecteer vervolgens Replica's maken.
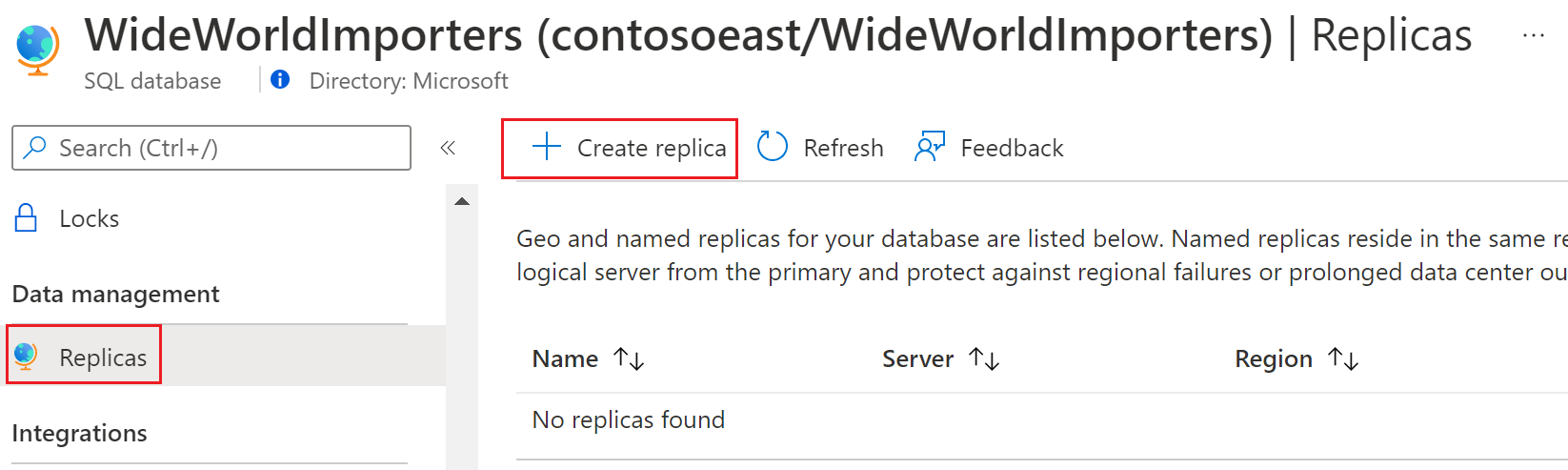
Kies Benoemde replica onder Replicaconfiguratie, selecteer of maak de server voor de benoemde replica, voer de naam van de replicadatabase in en configureer indien nodig de opties compute en opslag .
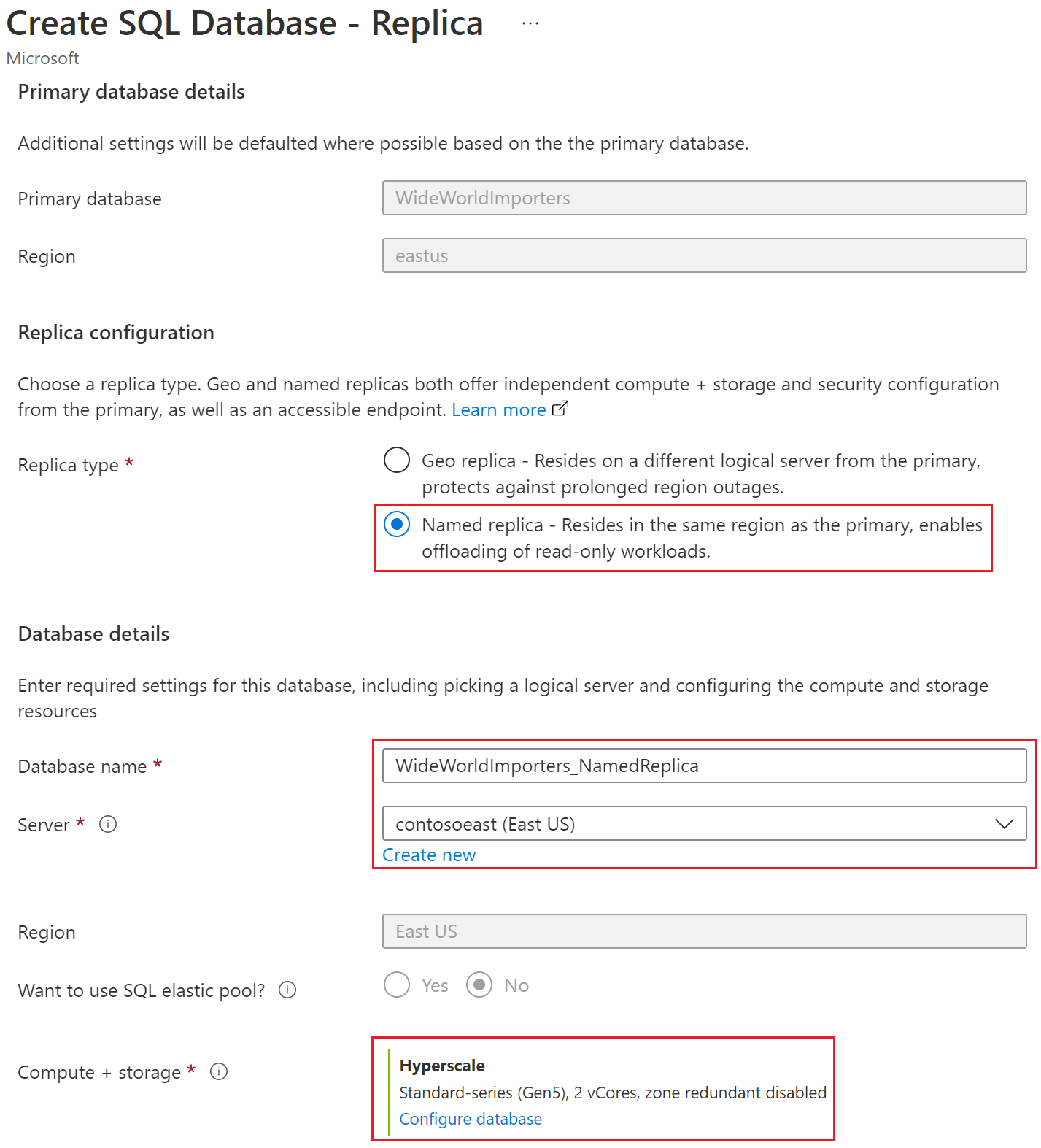
Selecteer Beoordelen en maken, controleer de informatie en selecteer vervolgens Maken.
Het benoemde replica-implementatieproces begint.
Wanneer de implementatie is voltooid, wordt de status van de benoemde replica weergegeven.
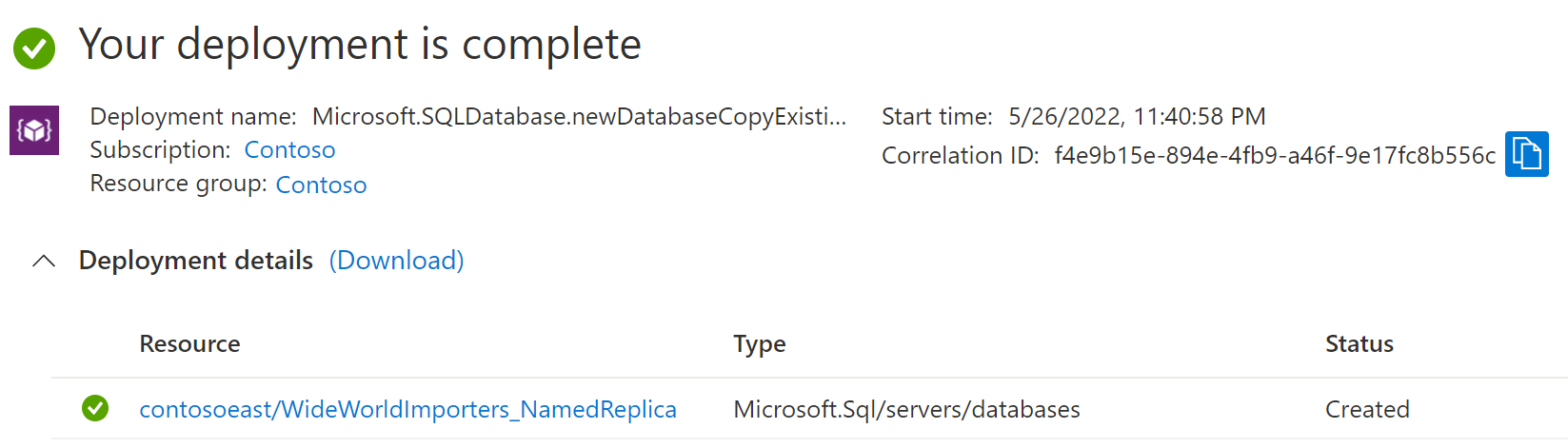
Ga terug naar de primaire databasepagina en selecteer Replica's. De benoemde replica wordt vermeld onder Benoemde replica's.
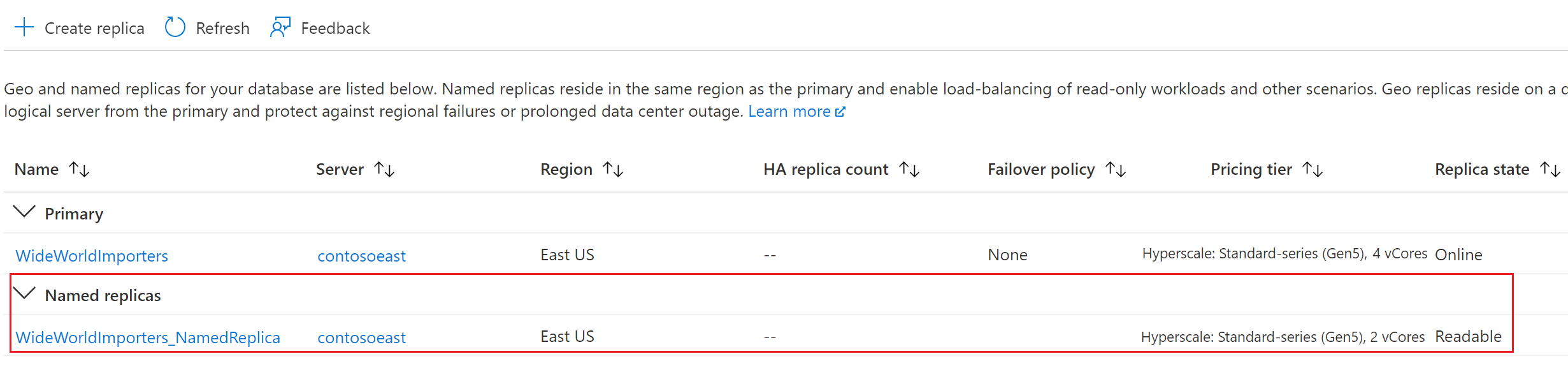
Omdat er geen gegevensverplaatsing is betrokken, wordt in de meeste gevallen een benoemde replica ongeveer een minuut gemaakt. Zodra de benoemde replica beschikbaar is, is deze zichtbaar vanuit de portal of een opdrachtregelprogramma zoals AZ CLI of PowerShell. Een benoemde replica kan worden gebruikt als een gewone alleen-lezendatabase.
Notitie
Zie veelgestelde vragen over Hyperscale benoemde replica's in Azure SQL Database Hyperscale, veelgestelde vragen over replica's.
Verbinding maken naar een benoemde replica
Als u verbinding wilt maken met een benoemde replica, moet u de verbindingsreeks voor die benoemde replica gebruiken, die verwijst naar de server- en databasenamen. U hoeft de optie ApplicationIntent=ReadOnly niet op te geven, omdat benoemde replica's altijd alleen-lezen zijn.
Net als bij replica's met hoge beschikbaarheid worden gegevenscaches op elke benoemde replica gesynchroniseerd met de primaire replica via de transactielogboekservice, waarmee logboekrecords van de primaire naar benoemde replica's worden doorgestuurd. Afhankelijk van de workload die door een benoemde replica wordt verwerkt, kan de toepassing van de logboekrecords zich op verschillende snelheden voordoen en kunnen er dus verschillende replica's verschillende gegevenslatentie hebben ten opzichte van de primaire replica.
Een benoemde replica wijzigen
U kunt de serviceniveaudoelstelling van een benoemde replica definiëren wanneer u deze maakt, via de ALTER DATABASE opdracht of op een andere ondersteunde manier (Portal, AZ CLI, PowerShell, REST API). Als u de serviceniveaudoelstelling wilt wijzigen nadat de benoemde replica is gemaakt, kunt u dit doen met behulp van de ALTER DATABASE ... MODIFY opdracht op de benoemde replica zelf. Als dit bijvoorbeeld WideWorldImporters_NamedReplica de benoemde replica van WideWorldImporters de database is, kunt u dit doen zoals hieronder wordt weergegeven.
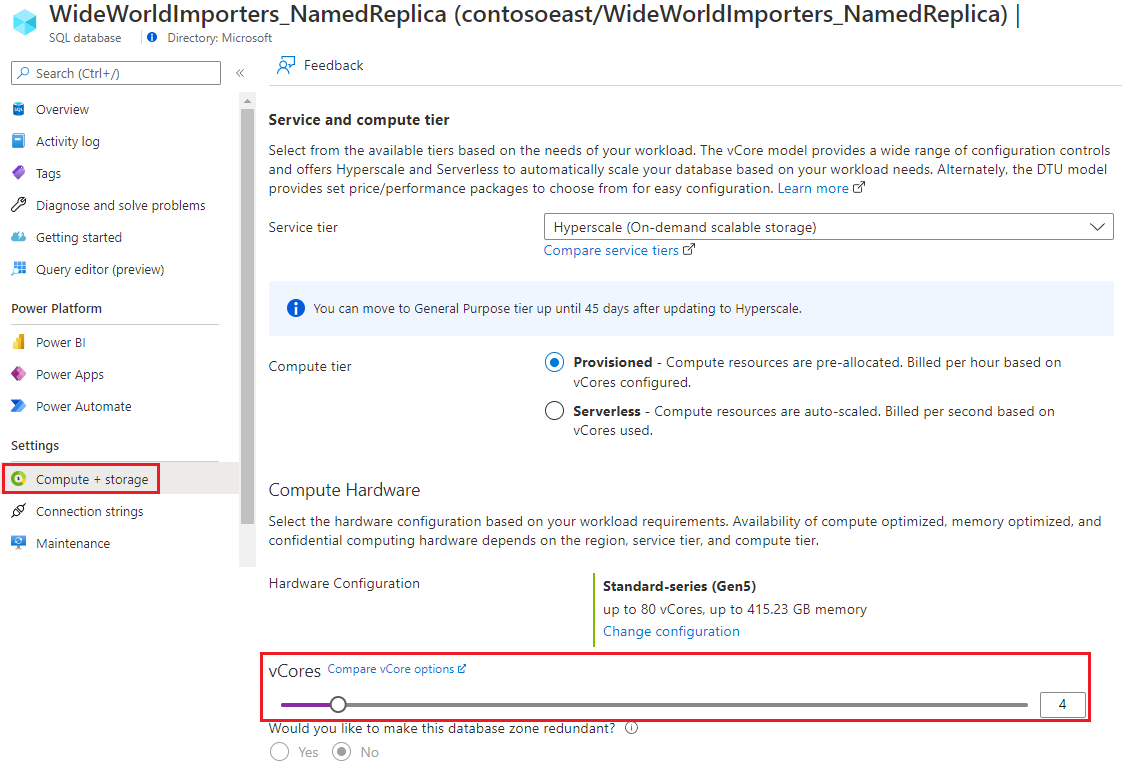
Open de pagina benoemde replicadatabase en selecteer Vervolgens Compute + opslag. Werk de vCores bij.
Een benoemde replica verwijderen
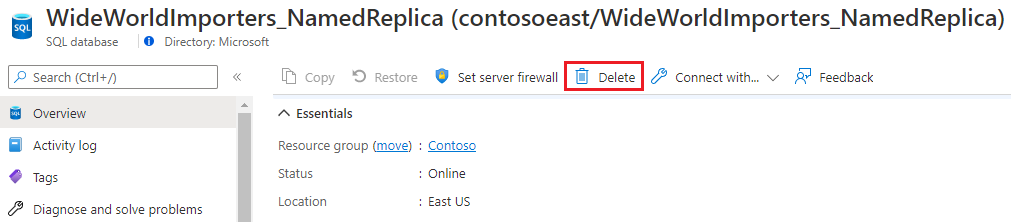
Als u een benoemde replica wilt verwijderen, zet u deze neer op een gewone database.
Open de pagina benoemde replicadatabase en kies Delete de optie.
Belangrijk
Benoemde replica's worden automatisch verwijderd wanneer de primaire replica waaruit ze zijn gemaakt, wordt verwijderd.
Bekende problemen
Gedeeltelijk onjuiste gegevens die worden geretourneerd door sys.databases
Rijwaarden die worden geretourneerd door sys.databases, voor benoemde replica's, in andere kolommen dan name en database_id, kunnen inconsistent en onjuist zijn. De kolom voor een benoemde replica kan bijvoorbeeld compatibility_level worden gerapporteerd als 140, zelfs als de primaire database waaruit de benoemde replica is gemaakt, is ingesteld op 150. Een tijdelijke oplossing is, indien mogelijk, om dezelfde gegevens op te halen met behulp van de DATABASEPROPERTYEX() functie, die de juiste gegevens retourneert.
Geo-replica
Met actieve geo-replicatie kunt u een leesbare secundaire replica van de primaire Hyperscale-database maken in hetzelfde of in een andere Azure-regio. Geo-replica's moeten worden gemaakt op een andere logische server. De databasenaam van een geo-replica komt altijd overeen met de databasenaam van de primaire replica.
Bij het maken van een geo-replica worden alle gegevens gekopieerd van de primaire naar een andere set paginaservers. Een geo-replica deelt geen paginaservers met de primaire server, zelfs niet als ze zich in dezelfde regio bevinden. Deze architectuur biedt de benodigde redundantie voor geo-failovers.
Geo-replica's worden gebruikt om een transactioneel consistente kopie van de database te onderhouden via asynchrone replicatie. Als een geo-replica zich in een andere Azure-regio bevindt, kan deze worden gebruikt voor herstel na noodgevallen in het geval van een noodgeval of storing in de primaire regio. Geo-replica's kunnen ook worden gebruikt voor geografische scenario's voor uitschalen van leesbewerkingen. Vanaf oktober 2022 wordt databasekopie van een secundaire replica van Hyperscale geo ondersteund.
Geo-replicatie voor Hyperscale-database heeft de volgende huidige beperkingen:
- Er kan slechts één geo-replica worden gemaakt (in dezelfde of een andere regio).
- Herstel naar een bepaald tijdstip van de geo-replica wordt niet ondersteund.
- Het maken van geo-replica's van een geo-replica (ook wel geo-replicaketening genoemd) wordt niet ondersteund.
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub Issues geleidelijk uitfaseren als het feedbackmechanisme voor inhoud. Het wordt vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor