Gegevensproducten voor analyse op cloudschaal in Azure
Gegevensproducten zijn gegevens die als product worden geleverd en die worden berekend, opgeslagen en geleverd door polyglot persistentieservices, die door bepaalde gebruiksscenario's kunnen worden vereist. Het proces van het maken en leveren van een gegevensproduct kan services en technologieën vereisen die niet zijn opgenomen in de kernservices van de gegevenslandingszone . Een voorbeeld hiervan is rapportage met nichevereisten, zoals naleving en belastingrapportage.
Overwegingen bij het ontwerpen
Een gegevenslandingszone kan worden geleverd aan meerdere gegevensproducten die zijn gemaakt door gegevens op te nemen vanuit dezelfde gegevenslandingszone of vanuit meerdere gegevenslandingszones. Dit wordt weergegeven in het volgende diagram.
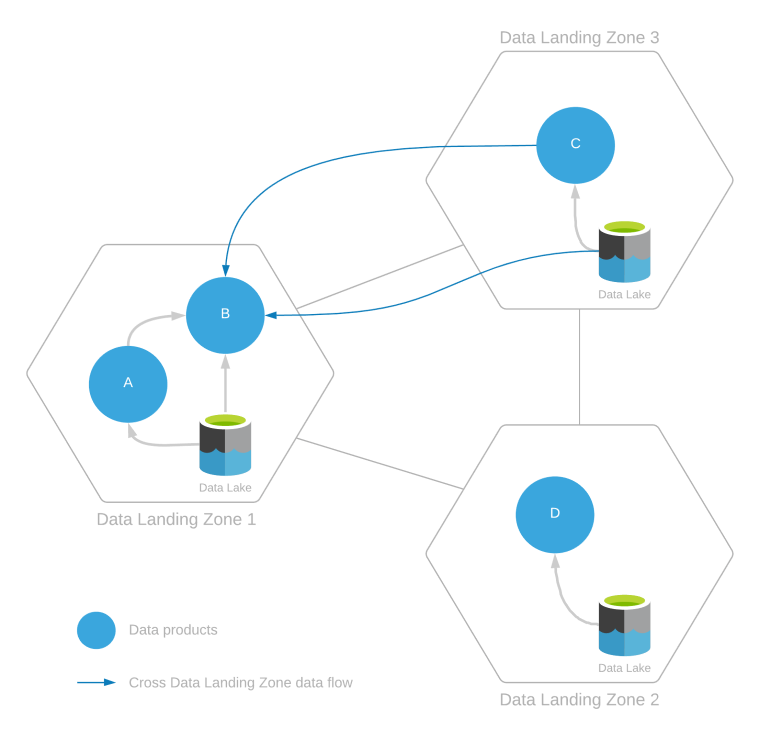
In het bovenstaande voorbeeld ziet u het volgende:
- Gegevensverbruik binnen de zone:
- Gegevensproduct B verbruikt gegevens uit gegevensproduct A en andere gegevens of gegevensproducten die in de data lake binnen de eigen landingszone bestaan.
- Gegevensproducten C en D verbruiken alleen gegevens uit hun eigen respectieve datalandingszones.
- Interzonegegevensverbruik:
- Gegevensproduct B gebruikt ook gegevens uit gegevensproduct C en de gegevens in de data lake van landingszone 3.
Belangrijk
In het geval van interzonegegevensverbruik, omdat gegevensproduct B wordt gemaakt door te lezen uit gegevenslandingszone 3, vereist deze leestoegang goedkeuring van de bewerkingsteams voor gegevenslandingszones en integratiebewerkingen van gegevenslandingszone 3.
Belangrijk
Gegevensproduct B verbruikt gegevens uit gegevensproducten A en C. Voordat dit kan gebeuren, moet dataproduct B het verbruik van gegevensproducten registreren via overeenkomsten voor het delen van gegevens. Deze overeenkomst voor het delen van gegevens moet de herkomst van gegevensproduct A naar gegevensproduct B en van gegevensproduct C naar gegevensproduct B bijwerken.
De resourcegroep voor een gegevensproduct bevat alle services die nodig zijn om het te maken en te onderhouden. We kunnen deze resourcegroep een gegevenstoepassing noemen. Voorbeelden van services die deel kunnen uitmaken van een gegevenstoepassing zijn Azure Functions, Azure App Service, Logic Apps, Azure Analysis Services, Azure Cognitive Services, Azure Machine Learning, Azure SQL Database, Azure Database for MySQLen Azure Cosmos DB. Zie voorbeelden van gegevenstoepassingen voor meer informatie.
Gegevensproducten bevatten gegevens uit READ-gegevensbronnen waarop enkele gegevenstransformaties zijn toegepast. Voorbeelden zijn een nieuw gecureerde gegevensset of een BI-rapport.
Ontwerpaanbeveling
Bouw gegevensproducten binnen uw gegevenslandingszone door te voldoen aan de ontwerpprincipes waarmee u kunt schalen met gegevensbeheer. De volgende secties bevatten ontwerpaanbeveling om u te helpen bij het plannen van het ecosysteem van uw gegevenstoepassing.
Meerdere resourcegroepen implementeren
Elke gegevenstoepassing is een resourcegroep. Omdat gegevenstoepassingen rekenservices, polyglot persistentieservices of beide zijn, kunnen ze alleen worden vereist, afhankelijk van bepaalde gebruiksscenario's. Als zodanig worden ze beschouwd als een optioneel onderdeel van de landingszone voor gegevens. Als u gegevenstoepassingen nodig hebt, maakt u meerdere resourcegroepen per gegevenstoepassing, zoals in het volgende diagram wordt weergegeven.

Stel kaders in
Azure Policy bepaalt de standaardconfiguratie van services binnen een gegevenslandingszone. U kunt operationele analyses beschouwen als meerdere resourcegroepen die uw gegevensproductteam kan aanvragen bij een standaardservicecatalogus. Met Azure Policy kunt u de beveiligingsgrens en de vereiste functieset configureren.
Belangrijk
Als u consistentie wilt stimuleren, configureert u één Azure Policy voor elke gegevenstoepassing.
Gegevens van meerdere locaties gebruiken
Gegevenstoepassingen beheren, organiseren en begrijpen gegevens van meerdere gegevensassets en presenteren inzichten die zijn verkregen. Een gegevensproduct is het resultaat van gegevens uit een of meer gegevenstoepassingen binnen datalandingszones. Geef uw gegevenstoepassingen indien nodig toegang tot gegevens uit meerdere en verschillende bronnen.
Schaal naar behoefte
Services waaruit gegevenstoepassingen bestaan, zijn incrementele implementaties in de gegevenslandingszone. Schaal uw gegevenstoepassingen naar behoefte.
Gegevensdetectie inschakelen
Registreer uw gegevensproducten automatisch in een gegevenscatalogus zoals Azure Purview om gegevensscans toe te staan.
Uw gegevensproducten identificeren
Wanneer u begint met het plannen van een datalandingszone, identificeert u zoveel gegevensproducten (en de gegevenstoepassingen die deze uitvoeren en onderhouden) als nodig is om de architectuur van uw gegevensproducttoepassing te stimuleren. Conformiteit met geïmplementeerde platformgovernance moet de grootste rol spelen in uw beslissingen.
Richt u op de wijze waarop uw gegevenstoepassingen gegevensproducenten en consumenten voor anderen zijn. Stel dat u een reeks gegevensproducten (A, B, C en D) hebt geïdentificeerd die worden geproduceerd en verbruikt. U hebt gegevensproducten A en D nodig als bronnen voor de gegevens in Gegevenstoepassing B voor gegevensproduct B. Gegevensproduct B wordt gemaakt op basis van de gegevens die Gegevenstoepassing B verbruikt van gegevensproducten A en D. Gegevenstoepassing B fungeert zelf als gegevensproducent en produceert ook gegevens voor gegevensproduct C.
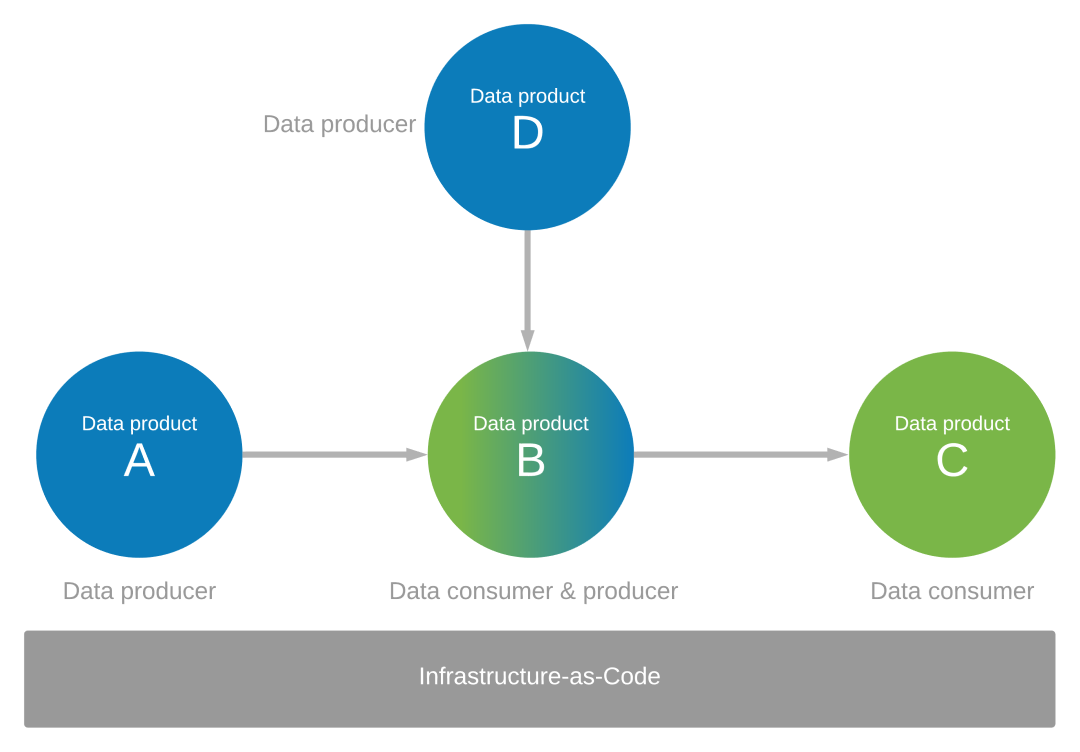
Uw gegevenstoepassingsomgeving beheren met infrastructure-as-code
Governance en infrastructuur-als-code moeten de omgeving van de gegevenstoepassing beheren in het ecosysteem van uw gegevensproducten, zoals weergegeven in het vorige diagram.
Gegevensmodellen publiceren
Uw dataproductteams moeten hun gegevensmodellen publiceren in een opslagplaats voor modellen.
Verwachtingen instellen voor gebruikers van gegevensproducten
Werk uw contracten voor het delen van gegevens bij met serviceovereenkomsten en certificeringen voor uw gegevensproducten, zodat u nauwkeurige verwachtingen kunt overbrengen aan potentiële gebruikers van het gegevensproduct.
Gegevensherkomst vastleggen
Als gegevensproduct B wordt gemaakt op basis van gegevens die afkomstig zijn van gegevensproducten A en D, moet de herkomst van A en D naar B worden vastgelegd. Verdere gegevensherkomst moet ook worden vastgelegd voor gegevensproduct C, omdat het is gemaakt met gegevens uit gegevens van gegevensproduct B. Bijgewerkte gegevensherkomst moet worden vastgelegd in een gegevensherkomsttoepassing vóór elke release van uw gegevensproduct.
Notitie
Met Behulp van Azure Pipelines kunt u goedkeuringspoorten bouwen en functies aanroepen die ervoor kunnen zorgen dat metagegevens, herkomst en SLA's zijn geregistreerd in de juiste governanceservice.
Architectuur van gegevenstoepassing definiëren
U moet voor elk gegevensproduct een gedetailleerde architectuur maken waarin de relatie met andere gegevensproducten, de afhankelijkheden en de toegangsvereisten volledig worden gedefinieerd.
Voorbeeld van een ontwerpscenario
Als u het definitieproces van de architectuur wilt begrijpen, bekijkt u het volgende voorbeeld van een financiële instelling en het bijbehorende product voor kredietbewakingsgegevens.
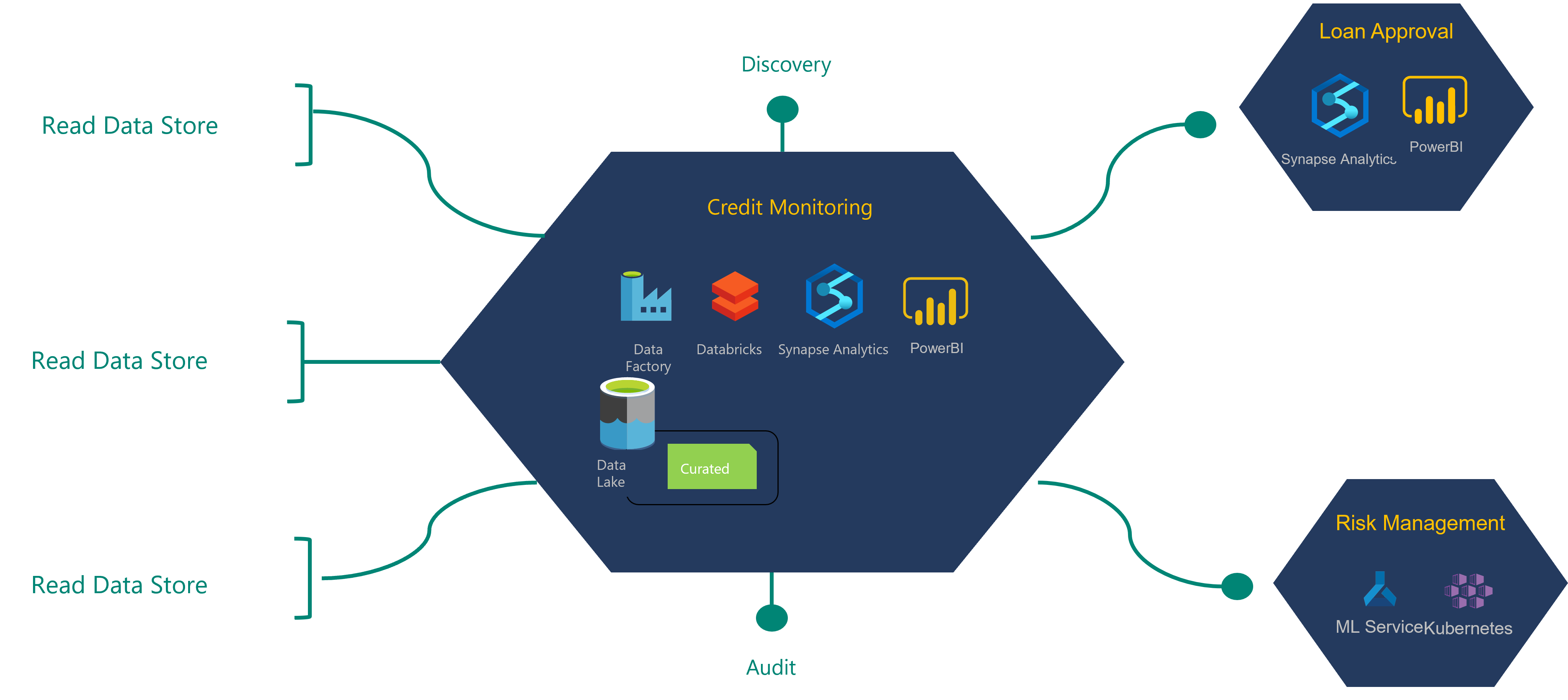
Het gegevensproduct voor kredietbewaking dat in dit diagram wordt weergegeven, verbruikt gegevens uit een leesgegevensarchief dat is opgenomen door het team voor integratiebewerkingen. Het produceert gegevensproduct(en) die ook worden gebruikt door twee andere gegevensproducten.
Notitie
Een gelezen gegevensbron of -archief wordt ook wel een gouden recordbron genoemd. Deze gegevensbronnen zijn opgeschoond, maar er zijn geen transformaties op toegepast.
Het productteam voor kredietbewakingsgegevens vraagt leestoegang aan voor leesgegevensarchieven die ze nodig hebben voor het maken van hun gegevensproduct. Hun aanvragen worden ter goedkeuring doorgestuurd naar de eigenaren van de gegevens. Zodra ze goedkeuring hebben ontvangen, kan het productteam beginnen met het bouwen van hun gegevenstoepassing.
Gegevens uit de leesgegevensbron worden omgezet in de gegevensproducten voor kredietbewaking. Nieuwe gegevensproducten worden opgeslagen in de gecureerde laag van de data lake. Deze nieuwe gegevensproducten en de nieuwe gegevensherkomst moeten worden geregistreerd als onderdeel van het DevOps-implementatieproces. Een functie kan geregistreerde metagegevens controleren met de fysieke structuur van de gegevensasset. De afhankelijkheid van de gegevensassets en gegevensproducten van de leesgegevensbron moet worden geregistreerd.
Het productteam voor goedkeuringsgegevens voor leningen is afhankelijk van een aantal van de producten voor kredietbewakingsgegevens. Het goedkeuringsteam voor leningen kan leestoegang aanvragen tot de producten voor kredietbewakingsgegevens die ze nodig hebben voor hun gegevensproducten. Zodra ze hun product voor goedkeuring van leningen en de bijbehorende gegevenstoepassing vrijgeven, moeten alle gegevensproductassets, herkomst en modellen worden geregistreerd in de relevante governanceservices.
Voorbeeldgegevenstoepassingen
De volgende secties bevatten voorbeeldgegevenstoepassingen om scenario's voor gegevenstoepassingen verder te illustreren.
Data analytics en data science data application
Een toepassing voor gegevensanalyse en gegevenswetenschap kan de services bevatten die worden weergegeven in de voorbeeldgegevenstoepassing product-analytics-rg.

Notitie
De bovenstaande gegevenstoepassing is beschikbaar als een sjabloon, waarmee een set services wordt geïmplementeerd die u kunt gebruiken voor gegevensanalyse en gegevenswetenschap. Net als al onze sjablonen is deze sjabloon voor gegevensproducttoepassingen een blauwdruk die u kunt gebruiken om snel omgevingen voor functieoverschrijdende teams in te richten. Alle services die u niet nodig hebt, moeten expliciet worden uitgeschakeld.
De sjabloon Data Product Analytics bevat alle sjablonen voor het implementeren van een gegevensproduct voor analyse en gegevenswetenschap binnen een landingszone voor analysescenario's op cloudschaal.
De implementatie- en codeartefacten omvatten de volgende services:
- Machine Learning
- Key Vault
- Application Insights
- Storage
- Container Registry
- Cognitive Services (optioneel)
- Data Factory (kiezen tussen Data Factory en Synapse)
- Synapse-werkruimte (kiezen tussen Data Factory en Synapse)
- Azure Search (optioneel)
- SQL-pool (optioneel)
- BigData-pool (optioneel)
Batch-gegevenstoepassing
De sjabloon Batch-gegevenstoepassing bevat alle sjablonen voor het implementeren van een gegevensproduct voor batchverwerking binnen een landingszone voor analysescenario's op cloudschaal.
De implementatie- en codeartefacten omvatten de volgende services:

- Key Vault
- Data Factory (kiezen tussen Data Factory en Synapse)
- Azure Cosmos DB (optioneel)
- Synapse-werkruimte (kiezen tussen Data Factory en Synapse)
- MySQL-database (optioneel)
- Azure SQL Database (optioneel)
- PostgreSQL-database (optioneel)
- MariaDB-database (optioneel)
- SQL-pool (optioneel)
- SQL Server (optioneel)
- Elastische SQL-pool (optioneel)
- BigData-pool
Toepassing voor streaminggegevens
De toepassingssjabloon voor streaminggegevens bevat alle sjablonen voor het implementeren van een gegevensproduct voor realtime gegevensverwerking binnen een landingszone voor analysescenario's op cloudschaal
De implementatie- en codeartefacten omvatten de volgende services:

- Key Vault
- Event Hubs
- IoT Hub
- Stream Analytics (optioneel)
- Azure Cosmos DB (optioneel)
- Synapse-werkruimte
- Azure SQL Database (optioneel)
- SQL-pool (optioneel)
- SQL Server (optioneel)
- Elastische SQL-pool (optioneel)
- BigData-pool
- Data Explorer (optioneel)
Als u de opslagplaatsen met de eerder genoemde implementatiesjablonen wilt vinden, raadpleegt u Implementatiesjablonen voor analyses op cloudschaal