Opzoektransformaties in toewijzingsgegevensstroom
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Gegevensstromen zijn beschikbaar in Zowel Azure Data Factory als Azure Synapse Pipelines. Dit artikel is van toepassing op toewijzingsgegevensstromen. Als u geen ervaring hebt met transformaties, raadpleegt u het inleidende artikel Gegevens transformeren met behulp van een toewijzingsgegevensstroom.
Gebruik de opzoektransformatie om te verwijzen naar gegevens uit een andere bron in een gegevensstroomstroom. Met de opzoektransformatie worden kolommen van overeenkomende gegevens toegevoegd aan uw brongegevens.
Een opzoektransformatie is vergelijkbaar met een left outer join. Alle rijen van de primaire stroom bestaan in de uitvoerstroom met extra kolommen uit de opzoekstroom.
Configuratie
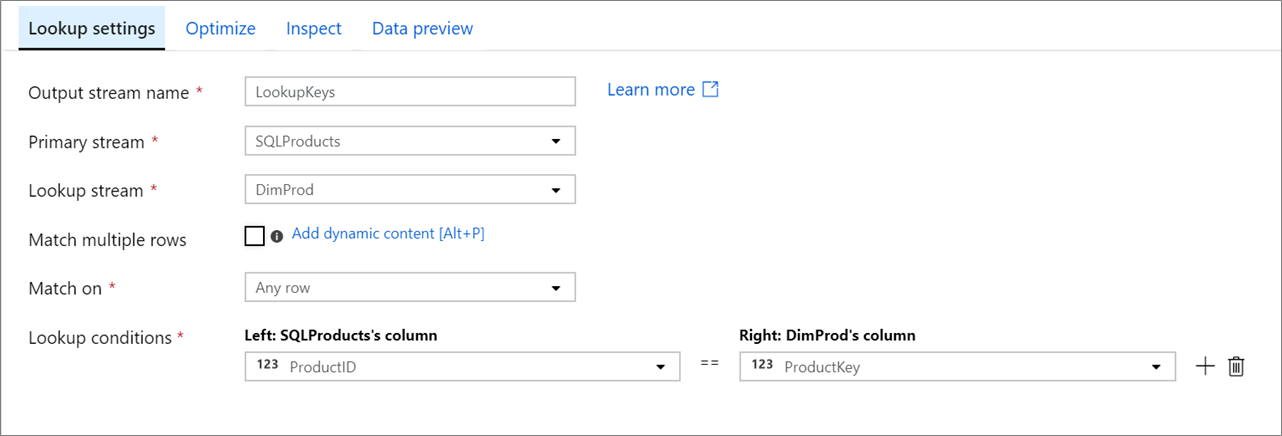
Primaire stroom: de binnenkomende gegevensstroom. Deze stroom is gelijk aan de linkerkant van een join.
Opzoekstroom: de gegevens die worden toegevoegd aan de primaire stroom. Welke gegevens worden toegevoegd, wordt bepaald door de opzoekvoorwaarden. Deze stream is gelijk aan de rechterkant van een join.
Overeenkomen met meerdere rijen: als deze optie is ingeschakeld, retourneert een rij met meerdere overeenkomsten in de primaire stroom meerdere rijen. Anders wordt slechts één rij geretourneerd op basis van de voorwaarde Overeenkomst op.
Overeenkomst ingeschakeld: Alleen zichtbaar als 'Meerdere rijen vergelijken' niet is geselecteerd. Kies of u wilt overeenkomen op een rij, de eerste overeenkomst of de laatste overeenkomst. Elke rij wordt aanbevolen omdat deze het snelst wordt uitgevoerd. Als de eerste rij of laatste rij is geselecteerd, moet u sorteervoorwaarden opgeven.
Opzoekvoorwaarden: kies op welke kolommen u wilt overeenkomen. Als aan de gelijkheidsvoorwaarde wordt voldaan, worden de rijen beschouwd als een overeenkomst. Plaats de muisaanwijzer op Berekende kolom om een waarde te extraheren met behulp van de expressietaal van de gegevensstroom.
Alle kolommen van beide streams worden opgenomen in de uitvoergegevens. Als u dubbele of ongewenste kolommen wilt verwijderen, voegt u een selectietransformatie toe na uw opzoektransformatie. Kolommen kunnen ook worden verwijderd of hernoemd in een sinktransformatie.
Niet-equi joins
Als u een voorwaardelijke operator wilt gebruiken, zoals niet gelijk is aan (!=) of groter dan (>) in de opzoekvoorwaarden, wijzigt u de vervolgkeuzelijst van de operator tussen de twee kolommen. Voor niet-equi joins moet ten minste één van de twee streams worden uitgezonden met vaste uitzending op het tabblad Optimaliseren.
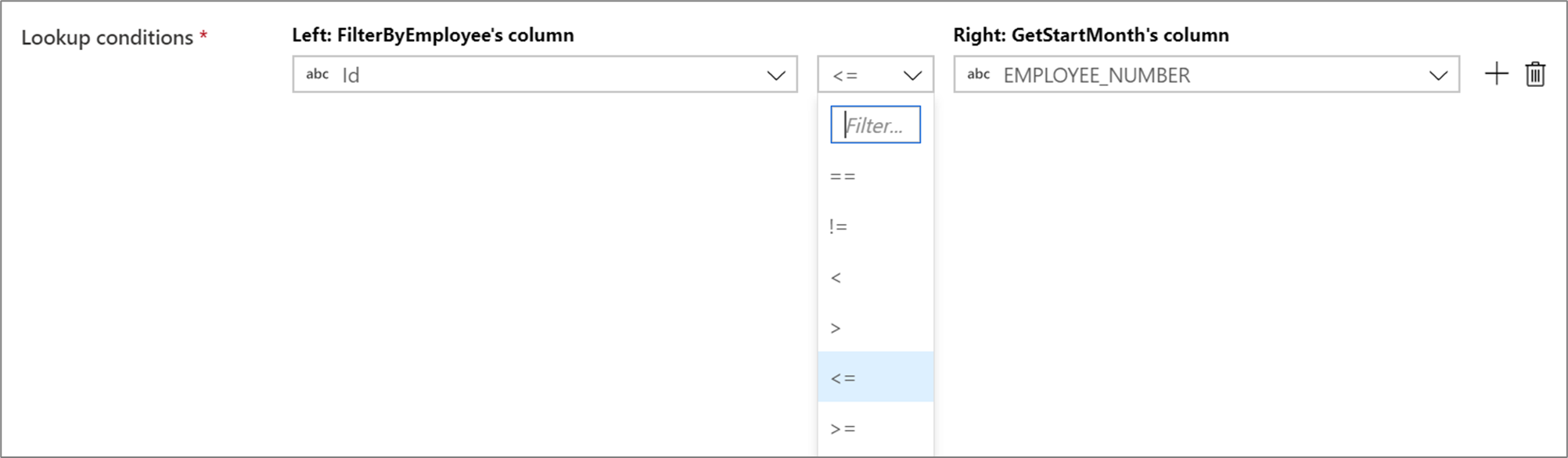
Overeenkomende rijen analyseren
Na de opzoektransformatie kan de functie isMatch() worden gebruikt om te zien of de zoekactie overeenkomt met afzonderlijke rijen.
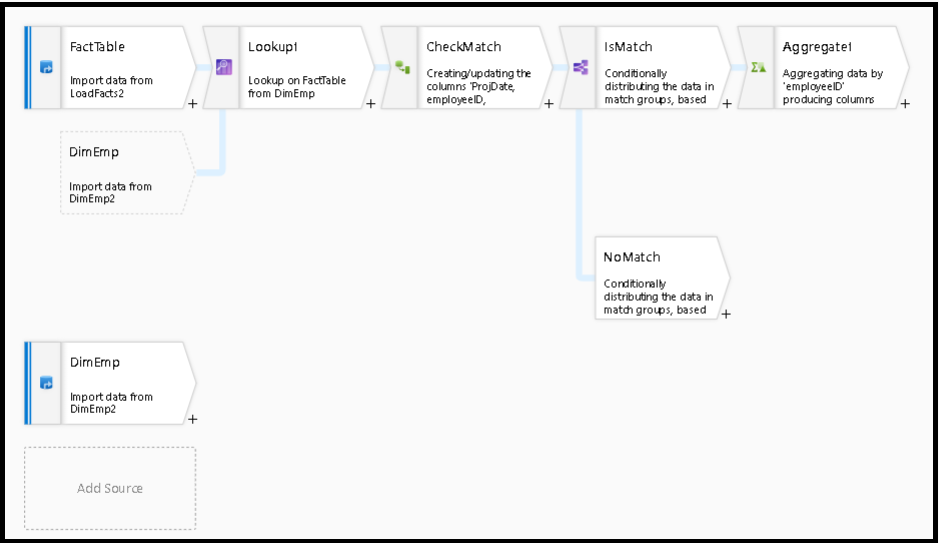
Een voorbeeld van dit patroon is het gebruik van de voorwaardelijke splitsingstransformatie om te splitsen op de isMatch() functie. In het bovenstaande voorbeeld gaan overeenkomende rijen door de bovenste stroom en stromen niet-overeenkomende rijen door de NoMatch stroom.
Opzoekvoorwaarden testen
Wanneer u de opzoektransformatie test met een voorbeeld van gegevens in de foutopsporingsmodus, gebruikt u een kleine set bekende gegevens. Wanneer u rijen uit een grote gegevensset steekt, kunt u niet voorspellen welke rijen en sleutels worden gelezen voor tests. Het resultaat is niet-deterministisch, wat betekent dat uw joinvoorwaarden geen overeenkomsten mogen retourneren.
Optimalisatie van broadcasts
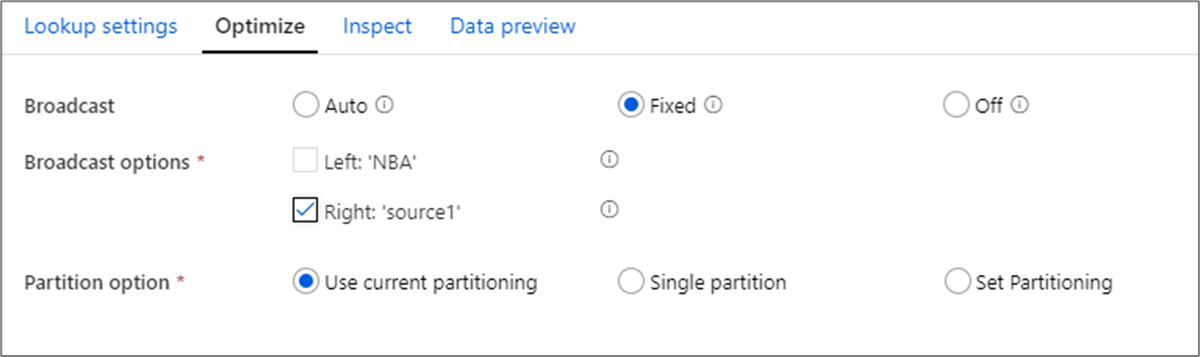
In joins, zoekacties en bestaat transformatie, als een of beide gegevensstromen in het geheugen van het werkknooppunt passen, kunt u de prestaties optimaliseren door Broadcasting in te schakelen. Standaard bepaalt de spark-engine automatisch of er wel of niet één zijde moet worden uitgezonden. Als u handmatig wilt kiezen welke kant u wilt uitzenden, selecteert u Vast.
Het is niet raadzaam om uitzending uit te schakelen via de optie Uit , tenzij uw joins time-outfouten ondervinden.
In de cache opgeslagen zoekopdrachten
Als u meerdere kleinere zoekacties uitvoert op dezelfde bron, is een sink in de cache en zoekactie mogelijk een beter gebruiksvoorbeeld dan de opzoektransformatie. Veelvoorkomende voorbeelden waarbij een cache-sink beter opzoekt naar een maximale waarde in een gegevensarchief en overeenkomende foutcodes voor een database met foutberichten. Meer informatie over cache-sinks en opzoekacties in de cache.
Script voor gegevensstroom
Syntaxis
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
Opmerking
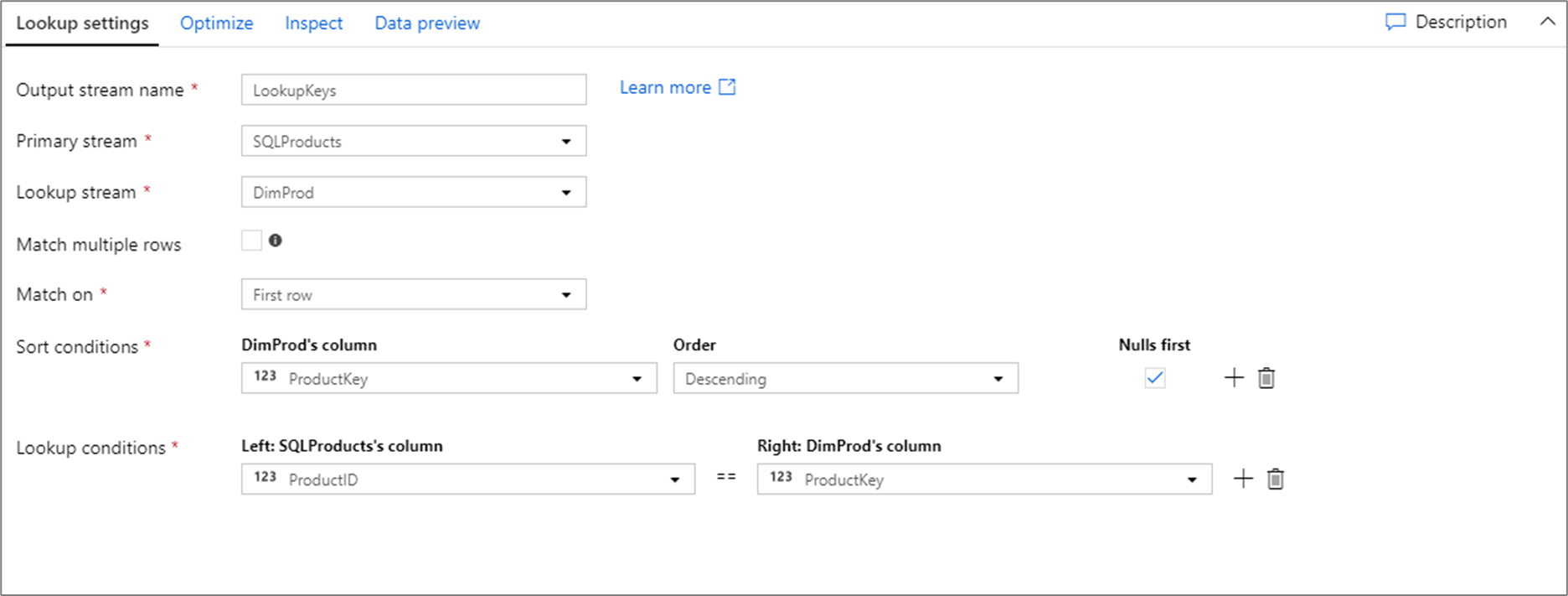
Het gegevensstroomscript voor de bovenstaande opzoekconfiguratie bevindt zich in het onderstaande codefragment.
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys
Gerelateerde inhoud
- De join en bestaat transformaties die beide in meerdere stroominvoer opnemen
- Een voorwaardelijke splitsingstransformatie gebruiken om
isMatch()rijen te splitsen op overeenkomende en niet-overeenkomende waarden