MLflow-projecten uitvoeren op Azure Databricks
Een MLflow-project is een indeling voor het verpakken van gegevenswetenschapscode op een herbruikbare en reproduceerbare manier. Het onderdeel MLflow Projects bevat een API en opdrachtregelprogramma's voor het uitvoeren van projecten, die ook kunnen worden geïntegreerd met het onderdeel Tracking om automatisch de parameters en git-doorvoer van uw broncode vast te leggen voor reproduceerbaarheid.
In dit artikel wordt de indeling van een MLflow-project beschreven en wordt beschreven hoe u een MLflow-project op afstand uitvoert op Azure Databricks-clusters met behulp van de MLflow CLI, zodat u uw gegevenswetenschapcode eenvoudig verticaal kunt schalen.
MLflow-projectindeling
Elke lokale map of Git-opslagplaats kan worden behandeld als een MLflow-project. De volgende conventies definiëren een project:
- De naam van het project is de naam van de map.
- De softwareomgeving wordt opgegeven in
python_env.yaml, indien aanwezig. Als er geenpython_env.yamlbestand aanwezig is, gebruikt MLflow een virtualenv-omgeving met alleen Python (met name de nieuwste Python die beschikbaar is voor virtualenv) bij het uitvoeren van het project. - Een
.pybestand in.shhet project kan een toegangspunt zijn, zonder expliciet gedeclareerde parameters. Wanneer u een dergelijke opdracht uitvoert met een set parameters, geeft MLflow elke parameter op de opdrachtregel door met behulp van--key <value>de syntaxis.
U geeft meer opties op door een MLproject-bestand toe te voegen. Dit is een tekstbestand in yamL-syntaxis. Een voorbeeld van een MLproject-bestand ziet er als volgt uit:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
Een MLflow-project uitvoeren
Gebruik de opdracht om een MLflow-project uit te voeren op een Azure Databricks-cluster in de standaardwerkruimte:
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
waar <uri> is een Git-opslagplaats-URI of map met een MLflow-project en <json-new-cluster-spec> is een JSON-document met een new_cluster structuur. De Git-URI moet van de volgende vorm zijn: https://github.com/<repo>#<project-folder>.
Een voorbeeld van een clusterspecificatie is:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
Als u bibliotheken op de werkrol wilt installeren, gebruikt u de indeling 'clusterspecificatie'. Houd er rekening mee dat Python-wielbestanden moeten worden geüpload naar DBFS en moeten worden opgegeven als pypi afhankelijkheden. Voorbeeld:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
Belangrijk
.eggen.jarafhankelijkheden worden niet ondersteund voor MLflow-projecten.- Uitvoering voor MLflow-projecten met Docker-omgevingen wordt niet ondersteund.
- U moet een nieuwe clusterspecificatie gebruiken bij het uitvoeren van een MLflow-project op Databricks. Het uitvoeren van projecten op basis van bestaande clusters wordt niet ondersteund.
SparkR gebruiken
Als u SparkR wilt gebruiken in een MLflow-projectuitvoering, moet uw projectcode eerst SparkR als volgt installeren en importeren:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
Uw project kan vervolgens een SparkR-sessie initialiseren en SparkR als normaal gebruiken:
sparkR.session()
...
Voorbeeld
In dit voorbeeld ziet u hoe u een experiment maakt, het MLflow-zelfstudieproject uitvoert op een Azure Databricks-cluster, de uitvoer van de taakuitvoering bekijkt en de uitvoering in het experiment bekijkt.
Vereisten
- Installeer MLflow met behulp van
pip install mlflow. - Installeer en configureer de Databricks CLI. Het Databricks CLI-verificatiemechanisme is vereist voor het uitvoeren van taken op een Azure Databricks-cluster.
Stap 1: Een experiment maken
Selecteer MLflow Experiment maken > in de werkruimte.
Voer in het veld Naam de naam in
Tutorial.Klik op Create. Noteer de experiment-id. In dit voorbeeld is het
14622565.
Stap 2: Het MLflow-zelfstudieproject uitvoeren
Met de volgende stappen stelt u de MLFLOW_TRACKING_URI omgevingsvariabele in en voert u het project uit, registreert u de trainingsparameters, metrische gegevens en het getrainde model naar het experiment dat u in de vorige stap hebt genoteerd:
Stel de
MLFLOW_TRACKING_URIomgevingsvariabele in op de Azure Databricks-werkruimte.export MLFLOW_TRACKING_URI=databricksVoer het MLflow-zelfstudieproject uit en train een wijnmodel. Vervang
<experiment-id>door de experiment-id die u in de vorige stap hebt genoteerd.mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===Kopieer de URL
https://<databricks-instance>#job/<job-id>/run/1in de laatste regel van de uitvoer van de MLflow-uitvoer.
Stap 3: De Azure Databricks-taak weergeven
Open de URL die u in de vorige stap in een browser hebt gekopieerd om de uitvoer van de Azure Databricks-taak weer te geven:
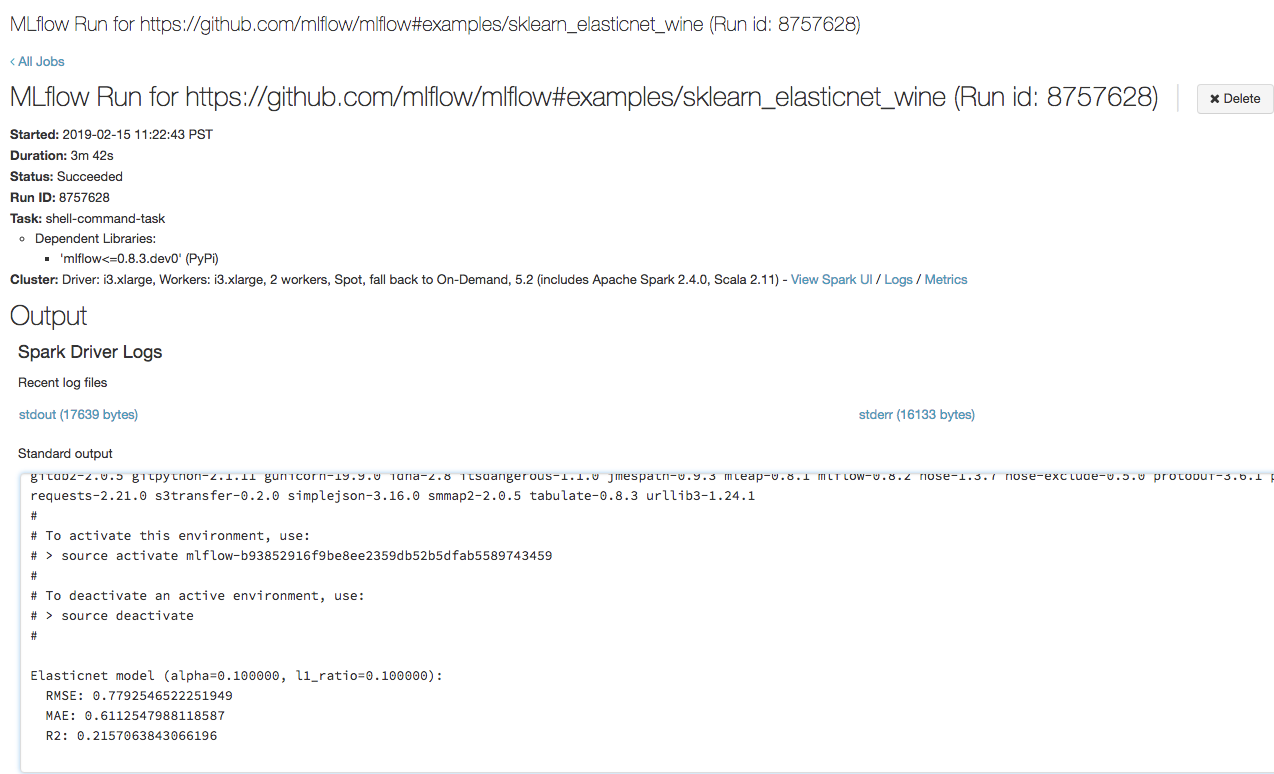
Stap 4: De details van het experiment en de MLflow-uitvoering weergeven
Navigeer naar het experiment in uw Azure Databricks-werkruimte.
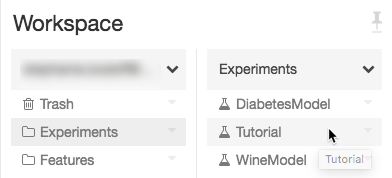
Klik op het experiment.
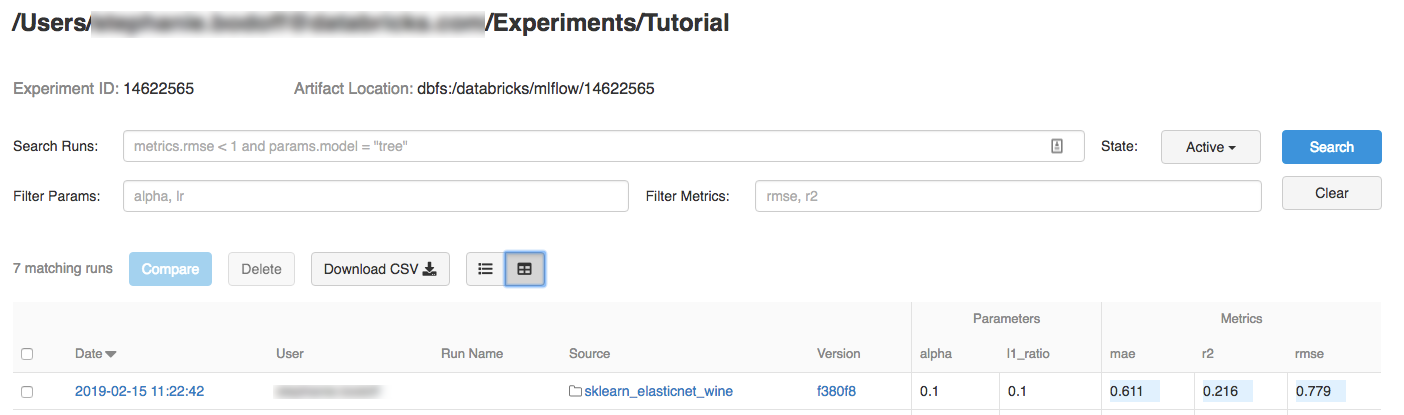
Als u uitvoeringsdetails wilt weergeven, klikt u op een koppeling in de kolom Datum.
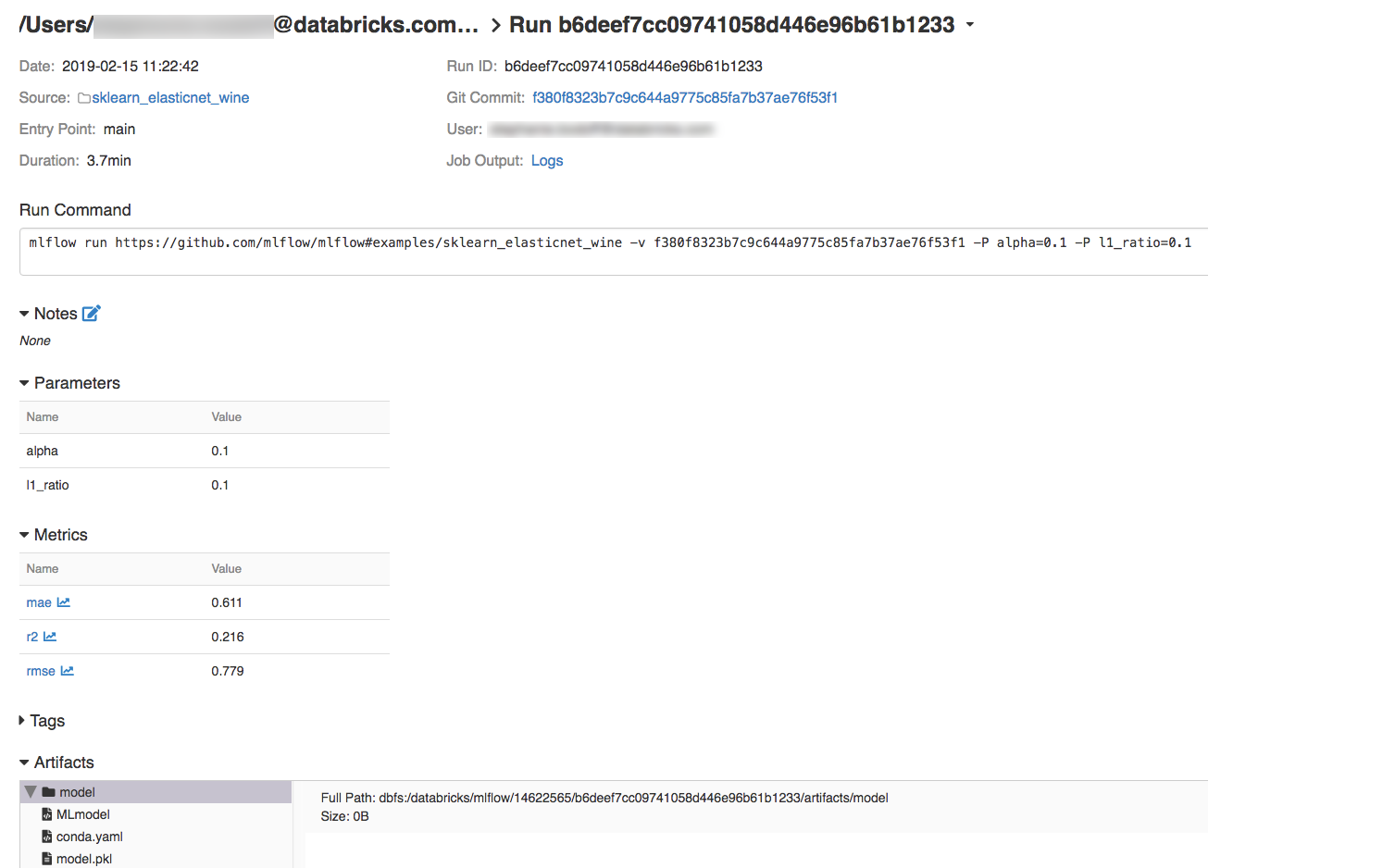
U kunt logboeken van uw uitvoering bekijken door te klikken op de koppeling Logboeken in het veld Taakuitvoer.
Resources
Zie voor enkele voorbeelden van MLflow-projecten de MLflow-appbibliotheek, die een opslagplaats met kant-en-klare projecten bevat die erop gericht zijn ML-functionaliteit eenvoudig in uw code op te nemen.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub Issues geleidelijk uitfaseren als het feedbackmechanisme voor inhoud. Het wordt vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor