OutOfMemoryError-uitzonderingen voor Apache Spark in Azure HDInsight
In dit artikel worden stappen voor probleemoplossing en mogelijke oplossingen beschreven voor problemen bij het gebruik van Apache Spark-onderdelen in Azure HDInsight-clusters.
Scenario: OutOfMemoryError-uitzondering voor Apache Spark
Probleem
Uw Apache Spark-toepassing is mislukt met een niet-verwerkte outOfMemoryError-uitzondering. Mogelijk ontvangt u een foutbericht dat vergelijkbaar is met:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Oorzaak
De meest waarschijnlijke oorzaak van deze uitzondering is dat onvoldoende heapgeheugen wordt toegewezen aan de virtuele Java-machines (JVM's). Deze JVM's worden gestart als uitvoerders of stuurprogramma's als onderdeel van de Apache Spark-toepassing.
Oplossing
Bepaal de maximale grootte van de gegevens die de Spark-toepassing verwerkt. Maak een schatting van de grootte op basis van de maximale grootte van de invoergegevens, de tussentijdse gegevens die worden geproduceerd door transformatie van de invoergegevens en de uitvoergegevens die worden geproduceerd door transformatie van de tussentijdse gegevens. Als de eerste schatting niet voldoende is, verhoogt u de grootte iets en gaat u door totdat de geheugenfouten verdwijnen.
Zorg ervoor dat het HDInsight-cluster dat u wilt gebruiken, over voldoende resources (geheugen en kernen) beschikt voor uitvoering van de Spark-toepassing. Dit kan worden bepaald door de sectie Metrische clustergegevens van de YARN-gebruikersinterface van het cluster weer te geven voor de waarden geheugengebruik versus geheugentotaal en VCores Gebruikt versus VCores Total.

Stel de volgende Spark-configuraties in op de juiste waarden. De toepassingsvereisten verdelen met de beschikbare resources in het cluster. Deze waarden mogen niet groter zijn dan 90% van de beschikbare geheugen- en kerngeheugens, zoals weergegeven door YARN, en moeten ook voldoen aan de minimale geheugenvereiste van de Spark-toepassing:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Totaal geheugen dat door alle uitvoerders wordt gebruikt =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Totaal geheugen gebruikt door stuurprogramma =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Scenario: Java-heapruimtefout bij het openen van de Apache Spark-geschiedenisserver
Probleem
U ontvangt de volgende fout bij het openen van gebeurtenissen in de Spark-geschiedenisserver:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Oorzaak
Dit probleem wordt vaak veroorzaakt door een gebrek aan resources bij het openen van grote spark-gebeurtenisbestanden. De grootte van de Spark-heap is standaard ingesteld op 1 GB, maar voor grote Spark-gebeurtenisbestanden is mogelijk meer nodig dan dit.
Als u de grootte wilt controleren van de bestanden die u wilt laden, kunt u de volgende opdrachten uitvoeren:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Oplossing
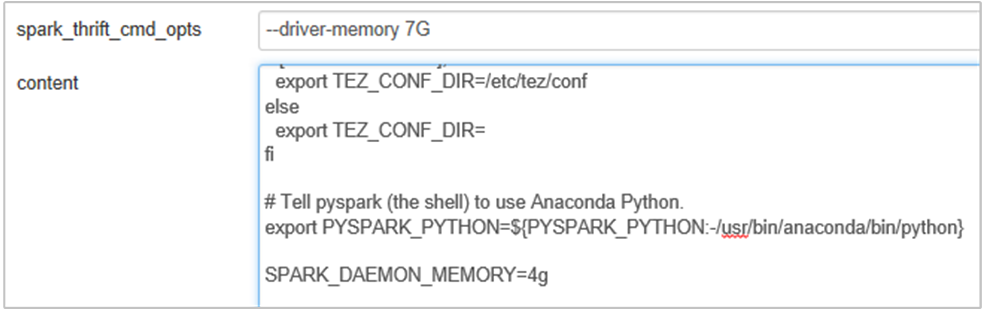
U kunt het geheugen van de Spark History Server vergroten door de eigenschap in de SPARK_DAEMON_MEMORY Spark-configuratie te bewerken en alle services opnieuw te starten.
U kunt dit doen vanuit de gebruikersinterface van de Ambari-browser door de sectie Spark2/Config/Advanced spark2-env te selecteren.
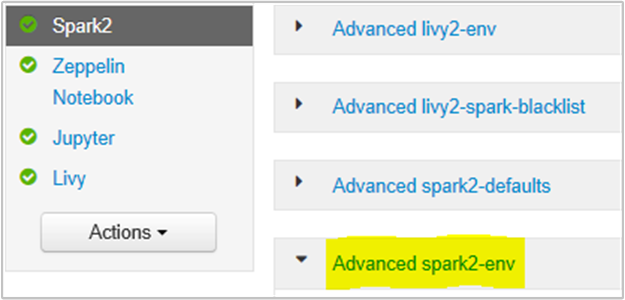
Voeg de volgende eigenschap toe om het geheugen van de Spark History Server te wijzigen van 1g in 4g: SPARK_DAEMON_MEMORY=4g.
Zorg ervoor dat u alle betrokken services opnieuw start vanuit Ambari.
Scenario: Livy Server kan niet worden gestart in een Apache Spark-cluster
Probleem
Livy Server kan niet worden gestart op een Apache Spark [(Spark 2.1 op Linux (HDI 3.6)]. Als u opnieuw wilt opstarten, wordt de volgende foutstack weergegeven vanuit de Livy-logboeken:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Oorzaak
java.lang.OutOfMemoryError: unable to create new native thread markeert dat het besturingssysteem geen systeemeigen threads kan toewijzen aan JVM's. Bevestigd dat deze uitzondering wordt veroorzaakt door de schending van de limiet voor het aantal threads per proces.
Wanneer Livy Server onverwacht wordt beëindigd, worden alle verbindingen met Spark-clusters ook beëindigd, wat betekent dat alle taken en gerelateerde gegevens verloren gaan. In HDP 2.6-sessieherstelmechanisme is geïntroduceerd, slaat Livy de sessiegegevens op in Zookeeper die moeten worden hersteld nadat de Livy Server terug is.
Wanneer er zoveel taken worden verzonden via Livy, worden deze sessiestatussen opgeslagen in ZK (op HDInsight-clusters) en worden deze sessies hersteld wanneer de Livy-service opnieuw wordt opgestart. Bij opnieuw opstarten na onverwachte beëindiging maakt Livy één thread per sessie en verzamelt dit enkele te herstellen sessies waardoor er te veel threads worden gemaakt.
Oplossing
Verwijder alle vermeldingen met behulp van de volgende stappen.
Het IP-adres van de zookeeper-knooppunten ophalen met behulp van
grep -R zk /etc/hadoop/confDe bovenstaande opdracht vermeldt alle zookeepers voor een cluster
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>Haal alle IP-adressen van de zookeeper-knooppunten op met behulp van ping of u kunt ook verbinding maken met zookeeper vanaf headnode met behulp van zookeeper-naam
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181Zodra uw e is verbonden, voert u de volgende opdracht uit om alle sessies weer te geven die zijn geprobeerd opnieuw te starten.
In de meeste gevallen kan dit een lijst zijn van meer dan 8000 sessies ####
ls /livy/v1/batchMet de volgende opdracht verwijdert u alle te herstellen sessies. #####
rmr /livy/v1/batch
Wacht totdat de bovenstaande opdracht is voltooid en de cursor de prompt retourneert en start de Livy-service vervolgens opnieuw vanuit Ambari, wat moet slagen.
Notitie
DELETE de livy-sessie zodra deze is uitgevoerd. De Livy-batchsessies worden niet automatisch verwijderd zodra de Spark-app is voltooid, wat standaard is. Een Livy-sessie is een entiteit die is gemaakt door een POST-aanvraag op de Livy REST-server. Er is een DELETE aanroep nodig om die entiteit te verwijderen. Of we moeten wachten tot de GC begint.
Volgende stappen
Als u uw probleem niet hebt gezien of uw probleem niet kunt oplossen, gaat u naar een van de volgende kanalen voor meer ondersteuning:
Overzicht van Spark-geheugenbeheer.
Krijg antwoorden van Azure-experts via de ondersteuning van De Azure-community.
Verbinding maken met @AzureSupport: het officiële Microsoft Azure-account voor het verbeteren van de klantervaring. Verbinding maken de Azure-community naar de juiste resources: antwoorden, ondersteuning en experts.
Als u meer hulp nodig hebt, kunt u een ondersteuningsaanvraag indienen via Azure Portal. Selecteer Ondersteuning in de menubalk of open de Help + ondersteuningshub . Raadpleeg hoe u een ondersteuning voor Azure aanvraag maakt voor meer informatie. Toegang tot abonnementsbeheer en factuurbeheer is in uw Microsoft Azure-abonnement inbegrepen, en technische ondersteuning wordt verstrekt via een van de Azure-ondersteuningsplannen.