Python-scriptonderdeel uitvoeren
In dit artikel wordt het onderdeel Python-script uitvoeren in Azure Machine Learning Designer beschreven.
Gebruik dit onderdeel om Python-code uit te voeren. Zie Python-code uitvoeren in Azure Machine Learning Designer voor meer informatie over de architectuur en ontwerpprincipes van Python.
Met Python kunt u taken uitvoeren die niet worden ondersteund door bestaande onderdelen, zoals:
- Gegevens visualiseren met behulp van
matplotlib. - Python-bibliotheken gebruiken om gegevenssets en modellen in uw werkruimte op te sommen.
- Het lezen, laden en bewerken van gegevens uit bronnen die niet worden ondersteund door het onderdeel Gegevens importeren .
- Voer uw eigen deep learning-code uit.
Ondersteunde Python-pakketten
Azure Machine Learning maakt gebruik van de Anaconda-distributie van Python, die veel algemene hulpprogramma's voor gegevensverwerking bevat. De Anaconda-versie wordt automatisch bijgewerkt. De huidige versie is:
- Anaconda 4.5+-distributie voor Python 3.6
Zie de sectie Vooraf geïnstalleerde Python-pakketten voor een volledige lijst.
Als u pakketten wilt installeren die niet in de vooraf geïnstalleerde lijst staan (bijvoorbeeld scikit-misc), voegt u de volgende code toe aan uw script:
import os
os.system(f"pip install scikit-misc")
Gebruik de volgende code om pakketten te installeren voor betere prestaties, met name voor deductie:
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
Notitie
Als uw pijplijn meerdere Execute Python Script-onderdelen bevat die pakketten nodig hebben die niet in de vooraf geïnstalleerde lijst staan, installeert u de pakketten in elk onderdeel.
Waarschuwing
Het onderdeel Excute Python Script biedt geen ondersteuning voor het installeren van pakketten die afhankelijk zijn van extra systeemeigen bibliotheken met opdrachten zoals apt-get, zoals Java, PyODBC en enzovoort. Dit komt doordat dit onderdeel wordt uitgevoerd in een eenvoudige omgeving waarin Python alleen vooraf is geïnstalleerd en met niet-beheerdersmachtigingen.
Toegang tot de huidige werkruimte en geregistreerde gegevenssets
U kunt de volgende voorbeeldcode raadplegen voor toegang tot de geregistreerde gegevenssets in uw werkruimte:
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Bestanden uploaden
Het onderdeel Python-script uitvoeren ondersteunt het uploaden van bestanden met behulp van de Azure Machine Learning Python SDK.
In het volgende voorbeeld ziet u hoe u een afbeeldingsbestand uploadt in het onderdeel Python-script uitvoeren:
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Nadat de pijplijn is uitgevoerd, kunt u een voorbeeld van de installatiekopieën bekijken in het rechterdeelvenster van het onderdeel.
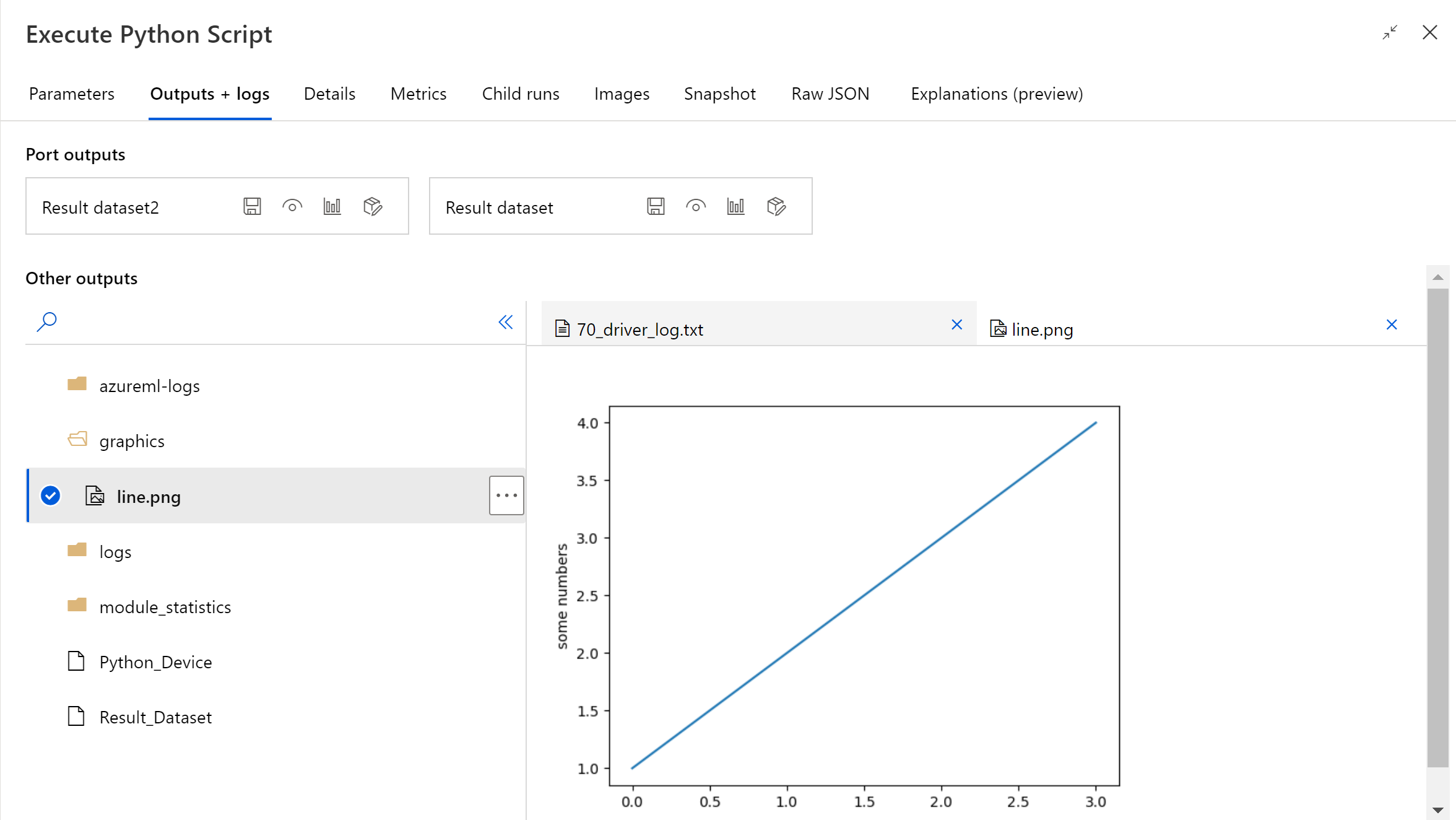
U kunt het bestand ook uploaden naar een willekeurig gegevensarchief met behulp van de volgende code. U kunt alleen een voorbeeld van het bestand bekijken in uw opslagaccount.
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Python-script uitvoeren configureren
Het onderdeel Python-script uitvoeren bevat python-voorbeeldcode die u als uitgangspunt kunt gebruiken. Als u het onderdeel Python-script uitvoeren wilt configureren, geeft u een set invoergegevens en Python-code op die moeten worden uitgevoerd in het tekstvak Python-script .
Voeg het onderdeel Python-script uitvoeren toe aan uw pijplijn.
Voeg alle gegevenssets uit de ontwerpfunctie die u wilt gebruiken voor invoer toe en maak verbinding met Gegevensset1 . Verwijs naar deze gegevensset in uw Python-script als DataFrame1.
Het gebruik van een gegevensset is optioneel. Gebruik dit als u gegevens wilt genereren met behulp van Python, of gebruik Python-code om de gegevens rechtstreeks in het onderdeel te importeren.
Dit onderdeel ondersteunt het toevoegen van een tweede gegevensset op Gegevensset2. Verwijs naar de tweede gegevensset in uw Python-script als DataFrame2.
Gegevenssets die zijn opgeslagen in Azure Machine Learning, worden automatisch geconverteerd naar pandas-gegevensframes wanneer ze met dit onderdeel worden geladen.
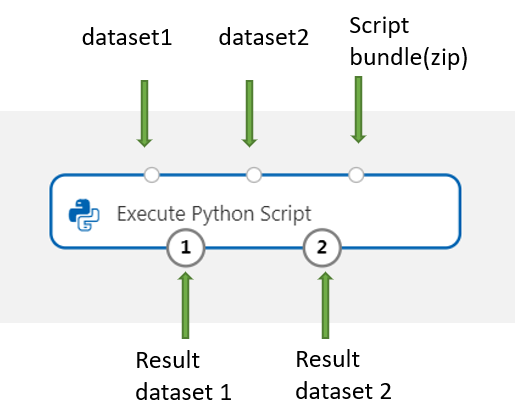
Als u nieuwe Python-pakketten of -code wilt opnemen, verbindt u het zip-bestand met deze aangepaste resources met de scriptbundelpoort . Of als uw script groter is dan 16 kB, gebruikt u de poort scriptbundel om fouten te voorkomen zoals CommandLine overschrijdt de limiet van 16597 tekens.
- Bundel het script en andere aangepaste resources in een zip-bestand.
- Upload het zip-bestand als een bestandsgegevensset naar de studio.
- Sleep het gegevenssetonderdeel vanuit de lijst Gegevenssets in het linkerdeelvenster van de ontwerppagina.
- Verbind het gegevenssetonderdeel met de poort scriptbundel van het onderdeel Python-script uitvoeren .
Elk bestand in het geüploade zip-archief kan worden gebruikt tijdens het uitvoeren van de pijplijn. Als het archief een mapstructuur bevat, blijft de structuur behouden.
Belangrijk
Gebruik een unieke en betekenisvolle naam voor bestanden in de scriptbundel, omdat sommige veelgebruikte woorden (zoals
testenappenzovoort) zijn gereserveerd voor ingebouwde services.Hier volgt een voorbeeld van een scriptbundel, dat een Python-scriptbestand en een txt-bestand bevat:
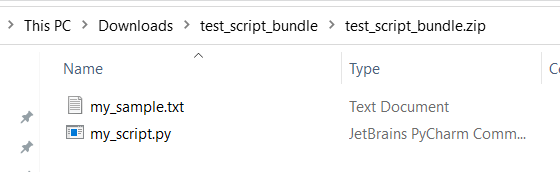
Hieronder volgt de inhoud van
my_script.py:def my_func(dataframe1): return dataframe1Hieronder volgt een voorbeeldcode die laat zien hoe u de bestanden in de scriptbundel kunt gebruiken:
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])Typ of plak een geldig Python-script in het tekstvak Python-script .
Notitie
Wees voorzichtig bij het schrijven van uw script. Zorg ervoor dat er geen syntaxisfouten zijn, zoals het gebruik van niet-opgegeven variabelen of niet-importerende onderdelen of functies. Besteed extra aandacht aan de vooraf geïnstalleerde onderdelenlijst. Als u onderdelen wilt importeren die niet worden vermeld, installeert u de bijbehorende pakketten in uw script, zoals:
import os os.system(f"pip install scikit-misc")Het tekstvak Python-script wordt vooraf ingevuld met enkele instructies in opmerkingen en voorbeeldcode voor toegang tot en uitvoer van gegevens. U moet deze code bewerken of vervangen. Volg de Python-conventies voor inspringing en hoofdletters:
- Het script moet een functie bevatten met de naam
azureml_mainals ingangspunt voor dit onderdeel. - De ingangspuntfunctie moet twee invoerargumenten hebben,
Param<dataframe1>enParam<dataframe2>, zelfs als deze argumenten niet in uw script worden gebruikt. - Gezipte bestanden die zijn verbonden met de derde invoerpoort, worden uitgepakt en opgeslagen in de map
.\Script Bundle, die ook wordt toegevoegd aan de Pythonsys.path.
Als uw .zip-bestand bevat
mymodule.py, importeert u het met behulp vanimport mymodule.Er kunnen twee gegevenssets worden geretourneerd naar de ontwerpfunctie. Dit moet een reeks van het type
pandas.DataFramezijn. U kunt andere uitvoer in uw Python-code maken en deze rechtstreeks naar Azure Storage schrijven.Waarschuwing
Het wordt niet aanbevolen om verbinding te maken met een database of andere externe opslag in het onderdeel Python-script uitvoeren. U kunt het onderdeel Gegevens importeren en het onderdeel Gegevens exporteren gebruiken
- Het script moet een functie bevatten met de naam
Verzend de pijplijn.
Als het onderdeel is voltooid, controleert u de uitvoer als verwacht.
Als het onderdeel is mislukt, moet u problemen oplossen. Selecteer het onderdeel en open Outputs+logs in het rechterdeelvenster. Open 70_driver_log.txt en zoek in azureml_main. Vervolgens kunt u zien welke regel de fout heeft veroorzaakt. Bijvoorbeeld: 'Bestand '/tmp/tmp01_ID/user_script.py', regel 17, in azureml_main' geeft aan dat de fout is opgetreden in de regel 17 van uw Python-script.
Resultaten
De resultaten van berekeningen door de ingesloten Python-code moeten worden opgegeven als pandas.DataFrame, die automatisch wordt geconverteerd naar de indeling van de Azure Machine Learning-gegevensset. Vervolgens kunt u de resultaten gebruiken met andere onderdelen in de pijplijn.
Het onderdeel retourneert twee gegevenssets:
Results Dataset 1, gedefinieerd door het eerste geretourneerde pandas-gegevensframe in een Python-script.
Resultaatgegevensset 2, gedefinieerd door het tweede geretourneerde pandas-gegevensframe in een Python-script.
Vooraf geïnstalleerde Python-pakketten
De vooraf geïnstalleerde pakketten zijn:
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob==1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- klik==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- cryptografie==2.8
- cycler==0.10.0
- dille==0.3.1.1
- distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2.9
- imbalanced-learn==0.4.3
- isodate==0.6.0
- itsdangerous==1.1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0.2
- jsonpickle==1.3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- markupsafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0.16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2.20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- pyopenssl==19.1.0
- pyparsing==2.4.6
- pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1.3.0
- requests==2.23.0
- rsa==4.0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- secretstorage==3.1.2
- setuptools==46.1.1.post20200323
- zes==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- wiel==0.34.2
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.