Onderdeel Model trainen
In dit artikel wordt een onderdeel in azure Machine Learning Designer beschreven.
Gebruik dit onderdeel om een classificatie- of regressiemodel te trainen. Training vindt plaats nadat u een model hebt gedefinieerd en de parameters ervan hebt ingesteld. Hiervoor zijn getagde gegevens vereist. U kunt Train Model ook gebruiken om een bestaand model opnieuw te trainen met nieuwe gegevens.
Hoe het trainingsproces werkt
In Azure Machine Learning bestaat het maken en gebruiken van een machine learning-model doorgaans uit drie stappen.
U configureert een model door een bepaald type algoritme te kiezen en de bijbehorende parameters of hyperparameters te definiëren. Kies een van de volgende modeltypen:
- Classificatiemodellen , gebaseerd op neurale netwerken, beslissingsstructuren, beslissingsforests en andere algoritmen.
- Regressiemodellen , die standaard lineaire regressie kunnen bevatten of die andere algoritmen gebruiken, waaronder neurale netwerken en Bayesiaanse regressie.
Geef een gegevensset op met een label en gegevens die compatibel zijn met het algoritme. Verbind zowel de gegevens als het model met Train Model.
Wat training produceert, is een specifieke binaire indeling, de iLearner, die de statistische patronen inkapselt die zijn geleerd van de gegevens. U kunt deze indeling niet rechtstreeks wijzigen of lezen; andere onderdelen kunnen echter gebruikmaken van dit getrainde model.
U kunt ook eigenschappen van het model weergeven. Zie de sectie Resultaten voor meer informatie.
Nadat de training is voltooid, gebruikt u het getrainde model met een van de scoreonderdelen om voorspellingen te doen over nieuwe gegevens.
Train Model gebruiken
Voeg het onderdeel Train Model toe aan de pijplijn. U vindt dit onderdeel in de categorie Machine Learning . Vouw Trainen uit en sleep het onderdeel Model trainen naar uw pijplijn.
Koppel aan de linkerkant de niet-getrainde modus. Koppel de trainingsgegevensset aan de rechterinvoer van Train Model.
De trainingsgegevensset moet een labelkolom bevatten. Rijen zonder labels worden genegeerd.
Klik voor Kolom label op Kolom bewerken in het rechterdeelvenster van het onderdeel en kies één kolom met resultaten die het model kan gebruiken voor training.
Voor classificatieproblemen moet de labelkolom categorische waarden of discrete waarden bevatten. Enkele voorbeelden zijn een ja/nee-classificatie, een ziekteclassificatiecode of -naam of een inkomensgroep. Als u een niet-categoriekolom kiest, retourneert het onderdeel een fout tijdens de training.
Voor regressieproblemen moet de labelkolom numerieke gegevens bevatten die de antwoordvariabele vertegenwoordigen. Idealiter vertegenwoordigen de numerieke gegevens een continue schaal.
Voorbeelden hiervan zijn een kredietrisicoscore, de verwachte tijd tot storing voor een harde schijf of het voorspelde aantal oproepen naar een callcenter op een bepaalde dag of tijd. Als u geen numerieke kolom kiest, krijgt u mogelijk een foutmelding.
- Als u niet opgeeft welke labelkolom u wilt gebruiken, probeert Azure Machine Learning aan de hand van de metagegevens van de gegevensset af te maken welke labelkolom de juiste labelkolom is. Als de verkeerde kolom wordt gekozen, gebruikt u de kolomkiezer om deze te corrigeren.
Tip
Als u problemen ondervindt met het gebruik van de kolomkiezer, raadpleegt u het artikel Kolommen in gegevensset selecteren voor tips. Hierin worden enkele veelvoorkomende scenario's en tips beschreven voor het gebruik van de opties WITH RULES en BY NAME .
Verzend de pijplijn. Als u veel gegevens hebt, kan dit even duren.
Belangrijk
Als u een id-kolom hebt die de id van elke rij is, of een tekstkolom die te veel unieke waarden bevat, kan Model trainen een fout krijgen zoals 'Aantal unieke waarden in kolom: {column_name}' is groter dan is toegestaan.
Dit komt doordat de kolom de drempelwaarde van unieke waarden heeft bereikt en mogelijk onvoldoende geheugen heeft. U kunt Metagegevens bewerken gebruiken om die kolom te markeren als wisfunctie en deze wordt niet gebruikt in de training, of N-Gram-functies uit het tekstonderdeel extraheren om de tekstkolom voor te verwerken. Zie Designer foutcode voor meer foutdetails.
Modelinterpretabiliteit
Modelinterpretabiliteit biedt de mogelijkheid om het ML-model te begrijpen en de onderliggende basis voor besluitvorming te presenteren op een manier die begrijpelijk is voor mensen.
Momenteel ondersteunt het onderdeel Model trainenhet gebruik van een pakket voor interpreteerbaarheid om ML-modellen uit te leggen. De volgende ingebouwde algoritmen worden ondersteund:
- Lineaire regressie
- Regressie neuraal netwerk
- Boosted Decistion Tree Regression
- Regressie beslissingsforest
- Regressie Poisson
- Logistieke regressie met twee klassen
- Two-Class Support Vector Machine
- Two-Class versterkte decistion-structuur
- Beslissingsforest met twee klassen
- Beslissingsforest met meerdere klassen
- Logistieke regressie met meerdere klassen
- Multi-class Neural Network
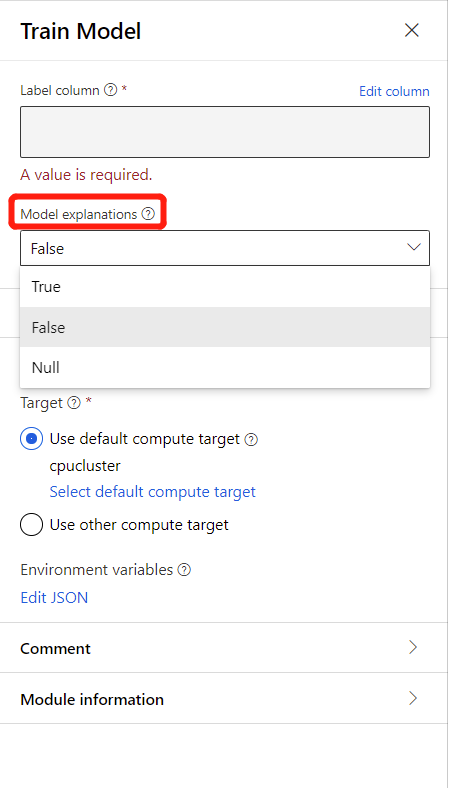
Als u modeluitleg wilt genereren, kunt u Waar selecteren in de vervolgkeuzelijst van Modeluitleg in het onderdeel Model trainen. Deze is standaard ingesteld op False in het onderdeel Train Model . Houd er rekening mee dat voor het genereren van uitleg extra rekenkosten zijn vereist.
Nadat de pijplijnuitvoering is voltooid, kunt u naar het tabblad Uitleg in het rechterdeelvenster van het onderdeel Model trainen gaan en de prestaties, gegevensset en het belang van de functie verkennen.
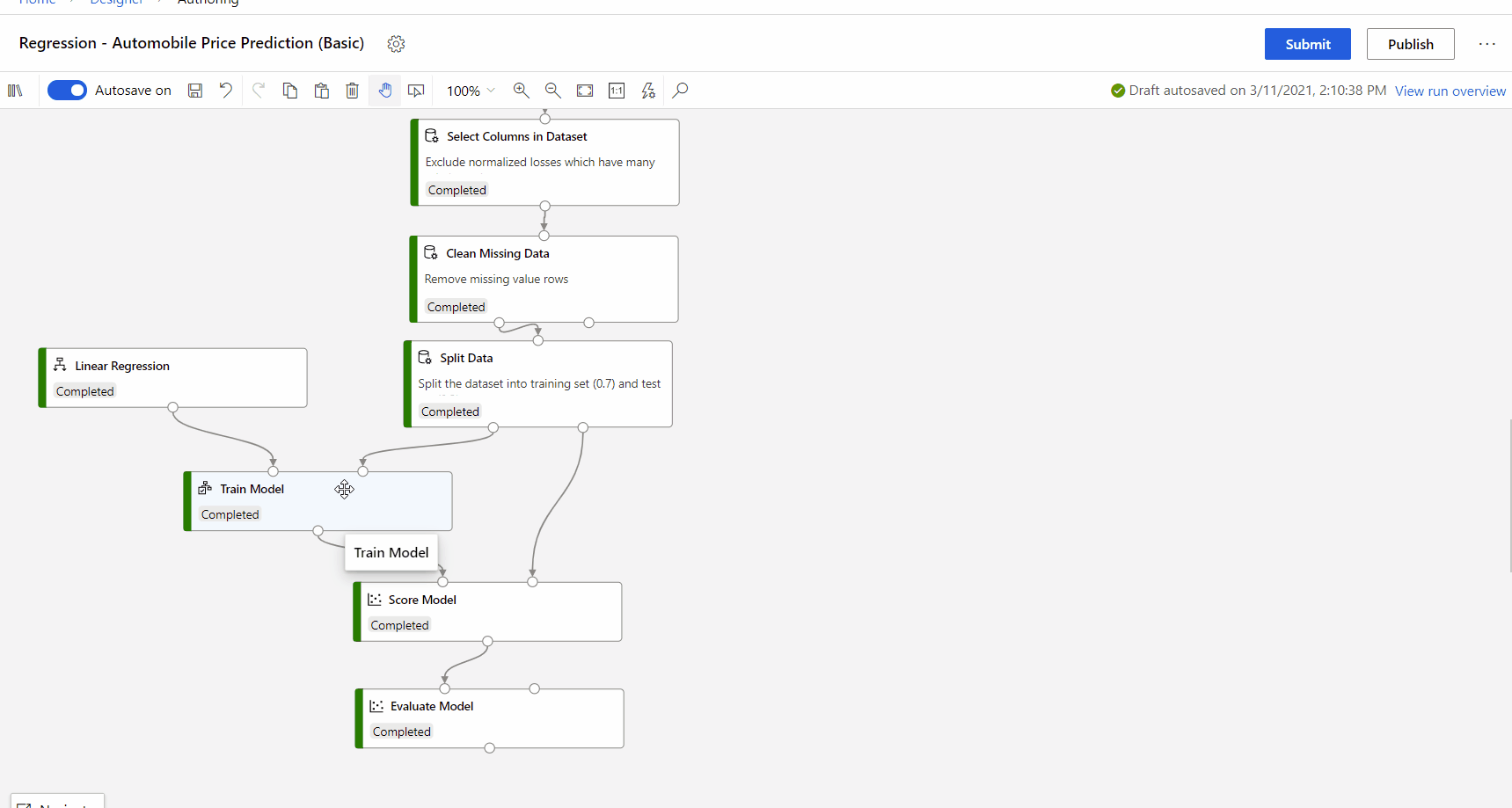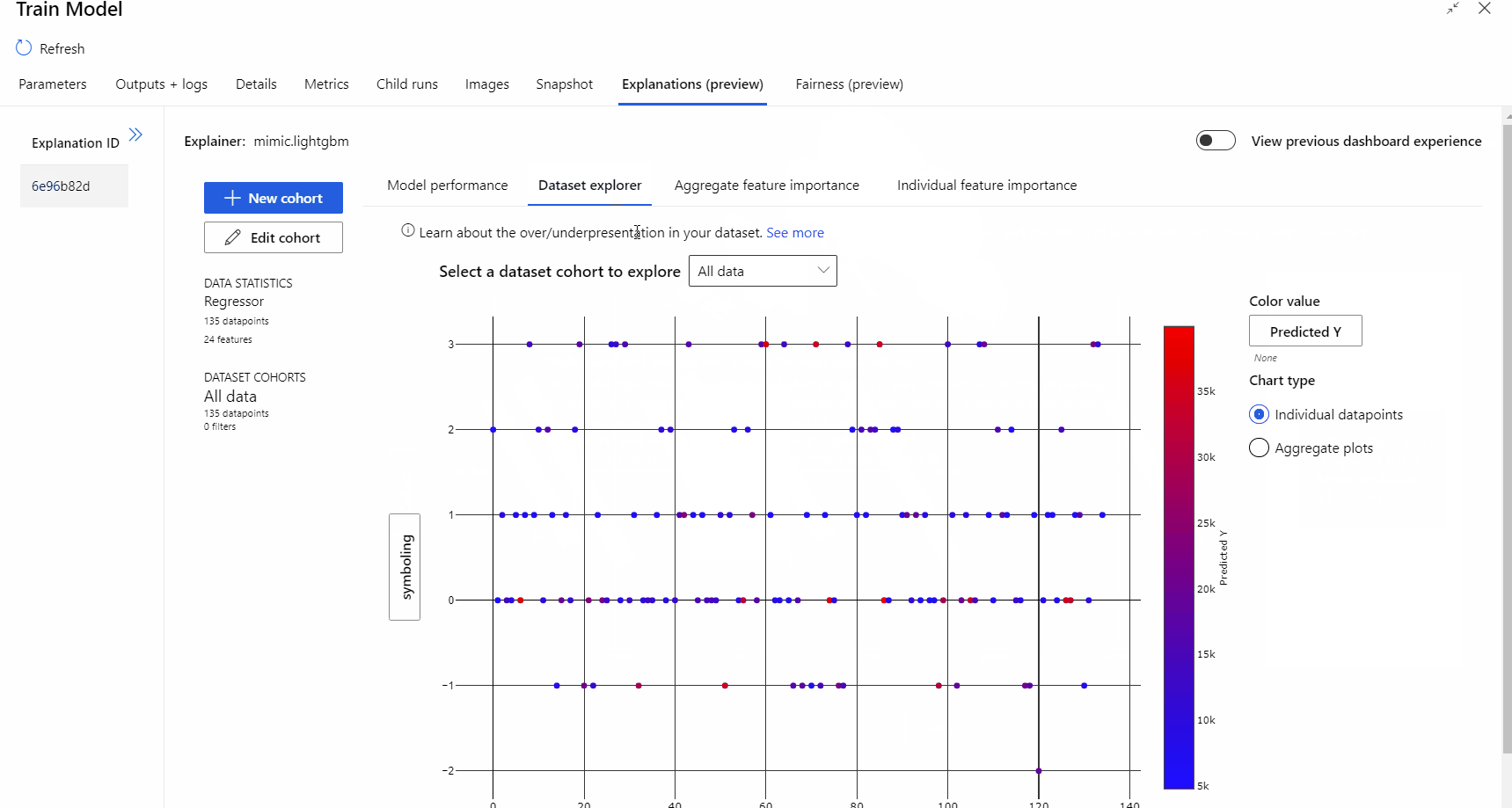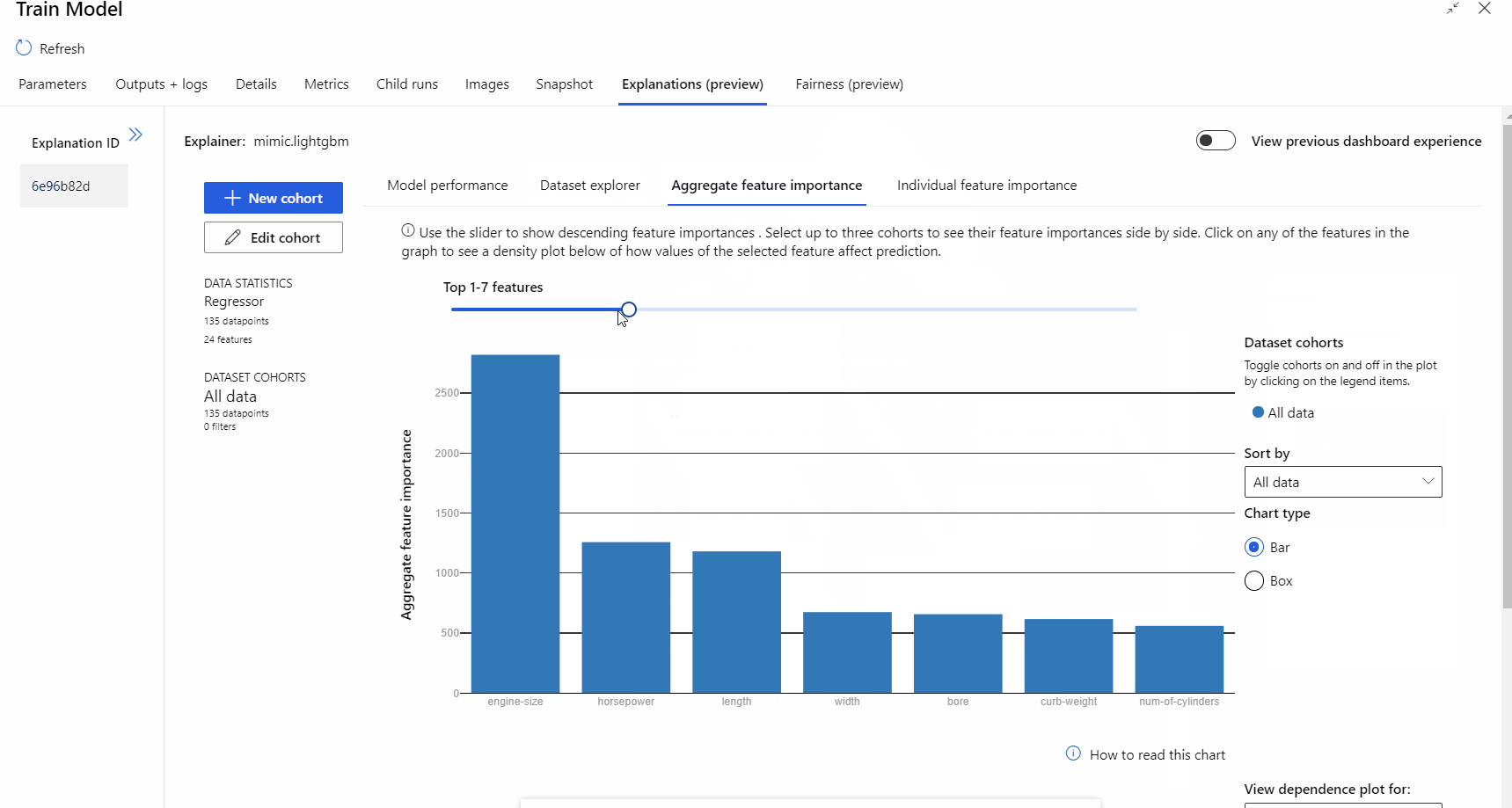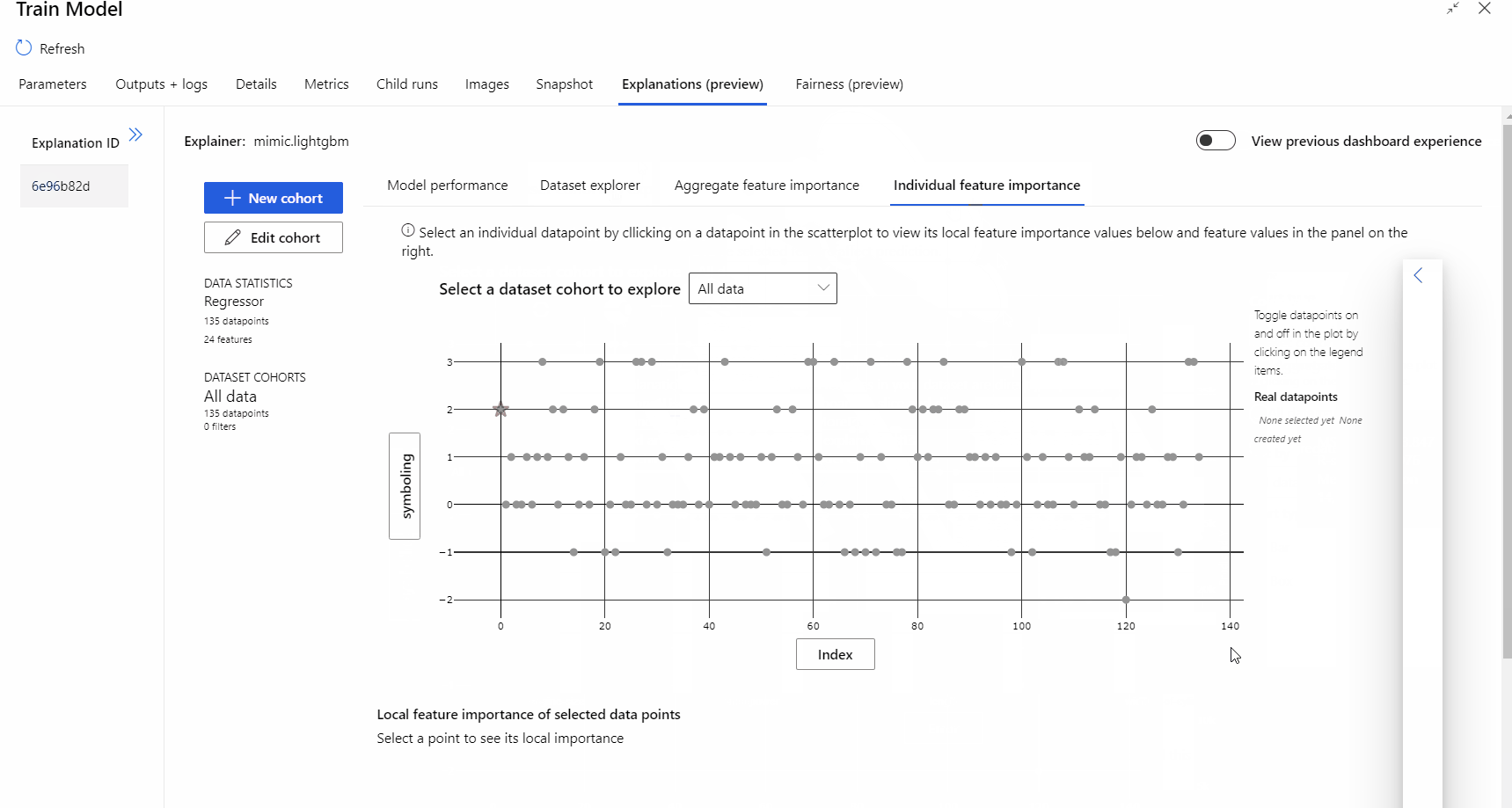
Raadpleeg het instructieartikel over ML-modellen interpreteren voor meer informatie over het gebruik van modeluitleg in Azure Machine Learning.
Resultaten
Nadat het model is getraind:
Als u het model in andere pijplijnen wilt gebruiken, selecteert u het onderdeel en selecteert u het pictogram Gegevensset registreren onder het tabblad Uitvoer in het rechterdeelvenster. U hebt toegang tot opgeslagen modellen in het onderdelenpalet onder Gegevenssets.
Als u het model wilt gebruiken bij het voorspellen van nieuwe waarden, verbindt u het met het onderdeel Score Model , samen met nieuwe invoergegevens.
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.