Model opruimen en selecteren voor prognoses in AutoML
Dit artikel is gericht op hoe AutoML prognosemodellen zoekt en selecteert. Raadpleeg het artikel over het overzicht van methoden voor meer algemene informatie over de prognosemethodologie in AutoML. Instructies en voorbeelden voor trainingsprognosemodellen in AutoML vindt u in het artikel AutoML instellen voor tijdreeksprognoses .
Model opruimen
De centrale taak voor AutoML is het trainen en evalueren van verschillende modellen en het kiezen van de beste met betrekking tot de opgegeven primaire metrische gegevens. Het woord 'model' hier verwijst naar zowel de modelklasse, zoals ARIMA of Random Forest, als de specifieke hyperparameterinstellingen waarmee modellen binnen een klasse worden onderscheiden. ARIMA verwijst bijvoorbeeld naar een klasse modellen die een wiskundige sjabloon en een set statistische veronderstellingen delen. Voor het trainen of aanpassen van een ARIMA-model is een lijst met positieve gehele getallen vereist die de precieze wiskundige vorm van het model aangeven; dit zijn de hyperparameters. ARIMA(1, 0, 1) en ARIMA(2, 1, 2) hebben dezelfde klasse, maar verschillende hyperparameters en kunnen dus afzonderlijk worden aangepast aan de trainingsgegevens en ten opzichte van elkaar worden geëvalueerd. AutoML doorzoekt, of veegt, over verschillende modelklassen en binnen klassen op basis van verschillende hyperparameters.
In de volgende tabel ziet u de verschillende methoden voor het opruimen van hyperparameters die AutoML gebruikt voor verschillende modelklassen:
| Modelklassegroep | Modeltype | Methode voor opruimen van hyperparameters |
|---|---|---|
| Naïef, seizoensgebonden naïef, gemiddeld, seizoensgebonden gemiddelde | Tijdreeks | Geen opruimen binnen de klasse vanwege de eenvoud van het model |
| Exponentieel vloeiend maken, ARIMA(X) | Tijdreeks | Rasterzoekactie voor opruimen binnen klasse |
| Profeet | Regressie | Geen opruimen binnen de klasse |
| Lineaire SGD, LARS LASSO, Elastisch net, K dichtstbijzijnde buren, Beslissingsstructuur, Willekeurige forest, Extreem gerandomiseerde bomen, Bomen met kleurovergang, LightGBM, XGBoost | Regressie | De modelaanbevelingsservice van AutoML verkent dynamisch hyperparameterruimten |
| PrognoseTCN | Regressie | Statische lijst met modellen gevolgd door willekeurige zoekopdrachten op netwerkgrootte, vervolgkeuzelijst en leersnelheid. |
Zie de sectie Prognosemodellen van het artikel Overzicht van methoden voor een beschrijving van de verschillende modeltypen.
De hoeveelheid opruimen die AutoML doet, is afhankelijk van de configuratie van de prognosetaak. U kunt de stopcriteria opgeven als een tijdslimiet of een limiet voor het aantal proefversies, of gelijkwaardig aan het aantal modellen. Logica voor vroegtijdige beëindiging kan in beide gevallen worden gebruikt om te stoppen met opruimen als de primaire metrische gegevens niet worden verbeterd.
Modelselectie
Het zoeken en selecteren van autoML-prognosemodellen verloopt in de volgende drie fasen:
- Veeg tijdreeksmodellen door en selecteer het beste model uit elke klasse met behulp van gestrafte waarschijnlijkheidsmethoden.
- Verwijder regressiemodellen en rangschik ze, samen met de beste tijdreeksmodellen uit fase 1, op basis van hun primaire metrische waarden uit validatiesets.
- Bouw een ensemblemodel op basis van de best gerangschikte modellen, bereken de validatiemetriek en rangschik dit met de andere modellen.
Het model met de best gerangschikte metrische waarde aan het einde van fase 3 wordt aangeduid als het beste model.
Belangrijk
In de laatste fase van de modelselectie van AutoML worden altijd metrische gegevens berekend op basis van gegevens buiten de steekproef . Dat wil gezegd, gegevens die niet zijn gebruikt om in de modellen te passen. Dit helpt om te beschermen tegen over-montage.
AutoML heeft twee validatieconfiguraties: kruisvalidatie en expliciete validatiegegevens. In het geval van kruisvalidatie gebruikt AutoML de invoerconfiguratie om gegevens te splitsen in trainings- en validatievouws. De tijdsvolgorde moet behouden blijven in deze splitsingen, dus AutoML maakt gebruik van de zogenaamde Rolling Origin Cross Validation die de reeks verdeelt in trainings- en validatiegegevens met behulp van een begintijdspunt. Het verschuiven van de oorsprong in de tijd genereert de kruisvalidatievouwen. Elke validatievouw bevat de volgende horizon van waarnemingen direct na de positie van de oorsprong van de opgegeven vouw. Deze strategie behoudt de integriteit van tijdreeksgegevens en vermindert het risico op het lekken van informatie.
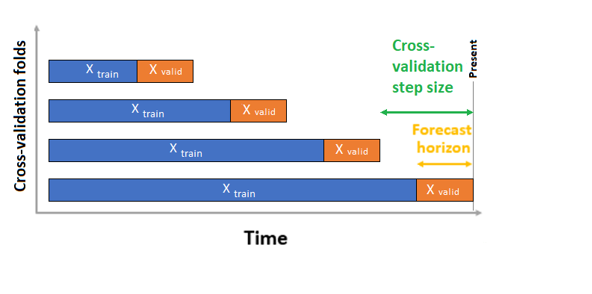
AutoML volgt de gebruikelijke procedure voor kruisvalidatie, waarbij een afzonderlijk model wordt getraind voor elke vouw en gemiddelde validatiegegevens van alle vouwen.
Kruisvalidatie voor prognosetaken wordt geconfigureerd door het aantal kruisvalidatievouwen en optioneel het aantal tijdsperioden tussen twee opeenvolgende kruisvalidatievouwen in te stellen. Zie de aangepaste instellingen voor kruisvalidatie voor meer informatie en een voorbeeld van het configureren van kruisvalidatie voor prognoses.
U kunt ook uw eigen validatiegegevens meenemen. Zie het artikel Gegevenssplitsing en kruisvalidatie configureren in AutoML (SDK v1) voor meer informatie.
Volgende stappen
- Meer informatie over het instellen van AutoML om een tijdreeksprognosemodel te trainen.
- Blader door Veelgestelde vragen over AutoML-prognose.
- Meer informatie over agendafuncties voor het voorspellen van tijdreeksen in AutoML.
- Meer informatie over hoe AutoML machine learning gebruikt om prognosemodellen te bouwen.