Azure Pipelines gebruiken met Azure Machine Learning
Azure DevOps Services | Azure DevOps Server 2022 - Azure DevOps Server 2019
U kunt een Azure DevOps-pijplijn gebruiken om de levenscyclus van machine learning te automatiseren. Enkele van de bewerkingen die u kunt automatiseren zijn:
- Gegevensvoorbereiding (extraheren, transformeren, laden)
- Machine learning-modellen trainen met uitschalen op aanvraag en omhoog schalen
- Implementatie van machine learning-modellen als openbare of persoonlijke webservices
- Geïmplementeerde machine learning-modellen bewaken (zoals voor prestaties of analyse van gegevensdrift)
In dit artikel leert u hoe u een Azure-pijplijn maakt die een machine learning-model bouwt en implementeert in Azure Machine Learning.
In deze zelfstudie wordt gebruikgemaakt van Azure Machine Learning Python SDK v2 en Azure CLI ML-extensie v2.
Vereisten
- Voltooi de resources maken om aan de slag te gaan met:
- Een werkruimte maken
- Een cloud-gebaseerd rekencluster maken dat moet worden gebruikt voor het trainen van uw model
- Azure Machine Learning-extensie voor Azure Pipelines. Deze extensie kan worden geïnstalleerd vanuit de Visual Studio Marketplace op https://marketplace.visualstudio.com/items?itemName=ms-air-aiagility.azureml-v2.
Stap 1: De code ophalen
Fork de volgende opslagplaats op GitHub:
https://github.com/azure/azureml-examples
Stap 2: Aanmelden bij Azure Pipelines
Meld u aan bij Azure Pipelines. Nadat u zich hebt aangemeld, gaat uw browser naar https://dev.azure.com/my-organization-name en geeft u uw Azure DevOps-dashboard weer.
Maak binnen uw geselecteerde organisatie een project. Als u geen projecten in uw organisatie hebt, ziet u het scherm Een project maken om aan de slag te gaan . Selecteer anders de knop Nieuw project in de rechterbovenhoek van het dashboard.
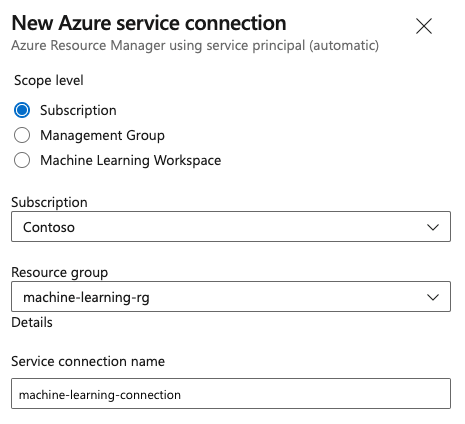
Stap 3: Een serviceverbinding maken
U kunt een bestaande serviceverbinding gebruiken.
U hebt een Azure Resource Manager-verbinding nodig om te verifiëren met Azure Portal.
Selecteer in Azure DevOps Project Instellingen en open de pagina Serviceverbindingen.
Kies + Nieuwe serviceverbinding en selecteer Azure Resource Manager.
Selecteer de standaardverificatiemethode, service-principal (automatisch).
Maak uw serviceverbinding. Stel het bereikniveau van uw voorkeur, abonnement, resourcegroep en verbindingsnaam in.
Stap 4: Een pijplijn maken
Ga naar Pijplijnen en selecteer vervolgens Nieuwe pijplijn.
Voer de stappen van de wizard uit door eerst GitHub te selecteren als de locatie van uw broncode.
U wordt mogelijk omgeleid naar GitHub om u aan te melden. Voer in dat geval uw GitHub-referenties in.
Wanneer u de lijst met opslagplaatsen ziet, selecteert u de opslagplaats.
U wordt mogelijk omgeleid naar GitHub om de Azure Pipelines-app te installeren. Als dat het zo is, selecteert u Goedkeuren en installeren.
Selecteer de Starter-pijplijn. U werkt de sjabloon voor de starterspijplijn bij.
Stap 5: uw YAML-pijplijn bouwen om de Azure Machine Learning-taak te verzenden
Verwijder de starterspijplijn en vervang deze door de volgende YAML-code. In deze pijplijn gaat u het volgende doen:
- Gebruik de Python-versietaak om Python 3.8 in te stellen en de SDK-vereisten te installeren.
- Gebruik de Bash-taak om bash-scripts uit te voeren voor de Azure Machine Learning SDK en CLI.
- Gebruik de Azure CLI-taak om een Azure Machine Learning-taak te verzenden.
Selecteer de volgende tabbladen, afhankelijk van of u een Azure Resource Manager-serviceverbinding of een algemene serviceverbinding gebruikt. Vervang in de YAML-pijplijn de waarde van variabelen door uw resources.
name: submit-azure-machine-learning-job
trigger:
- none
variables:
service-connection: 'machine-learning-connection' # replace with your service connection name
resource-group: 'machinelearning-rg' # replace with your resource group name
workspace: 'docs-ws' # replace with your workspace name
jobs:
- job: SubmitAzureMLJob
displayName: Submit AzureML Job
timeoutInMinutes: 300
pool:
vmImage: ubuntu-latest
steps:
- task: UsePythonVersion@0
displayName: Use Python >=3.8
inputs:
versionSpec: '>=3.8'
- bash: |
set -ex
az version
az extension add -n ml
displayName: 'Add AzureML Extension'
- task: AzureCLI@2
name: submit_azureml_job_task
displayName: Submit AzureML Job Task
inputs:
azureSubscription: $(service-connection)
workingDirectory: 'cli/jobs/pipelines-with-components/nyc_taxi_data_regression'
scriptLocation: inlineScript
scriptType: bash
inlineScript: |
# submit component job and get the run name
job_name=$(az ml job create --file single-job-pipeline.yml -g $(resource-group) -w $(workspace) --query name --output tsv)
# Set output variable for next task
echo "##vso[task.setvariable variable=JOB_NAME;isOutput=true;]$job_name"
Stap 6: Wacht totdat de Azure Machine Learning-taak is voltooid
In stap 5 hebt u een taak toegevoegd om een Azure Machine Learning-taak te verzenden. In deze stap voegt u een andere taak toe die wacht totdat de Azure Machine Learning-taak is voltooid.
Als u een Azure Resource Manager-serviceverbinding gebruikt, kunt u de extensie Machine Learning gebruiken. U kunt deze extensie doorzoeken in de Marketplace voor Azure DevOps-extensies of rechtstreeks naar de extensie gaan. Installeer de extensie Machine Learning.
Belangrijk
Installeer de Machine Learning-extensie (klassiek) niet per ongeluk. Het is een oudere extensie die niet dezelfde functionaliteit biedt.
Voeg in het venster Pijplijnbeoordeling een servertaak toe. Selecteer in het stappengedeelte van de taak De assistent Weergeven en zoek naar AzureML. Selecteer de azureML-taakwachttaak en vul de gegevens voor de taak in.
De taak heeft vier invoerwaarden: Service Connection, Azure Resource Group Nameen AzureML Job NameAzureML Workspace Name . Vul deze invoer in. De resulterende YAML voor deze stappen is vergelijkbaar met het volgende voorbeeld:
Notitie
- De wachttaak van de Azure Machine Learning-taak wordt uitgevoerd op een servertaak, waarvoor geen dure agentpoolbronnen worden gebruikt en waarvoor geen extra kosten nodig zijn. Servertaken (aangegeven door
pool: server) worden uitgevoerd op dezelfde computer als uw pijplijn. Zie Servertaken voor meer informatie. - Eén azure Machine Learning-taakwachttaak kan slechts op één taak wachten. U moet een afzonderlijke taak instellen voor elke taak waarop u wilt wachten.
- De wachttaak voor de Azure Machine Learning-taak kan maximaal 2 dagen wachten. Dit is een vaste limiet die is ingesteld door Azure DevOps Pipelines.
- job: WaitForAzureMLJobCompletion
displayName: Wait for AzureML Job Completion
pool: server
timeoutInMinutes: 0
dependsOn: SubmitAzureMLJob
variables:
# We are saving the name of azureMl job submitted in previous step to a variable and it will be used as an inut to the AzureML Job Wait task
azureml_job_name_from_submit_job: $[ dependencies.SubmitAzureMLJob.outputs['submit_azureml_job_task.JOB_NAME'] ]
steps:
- task: AzureMLJobWaitTask@1
inputs:
serviceConnection: $(service-connection)
resourceGroupName: $(resource-group)
azureMLWorkspaceName: $(workspace)
azureMLJobName: $(azureml_job_name_from_submit_job)
Stap 7: Pijplijn verzenden en uw pijplijnuitvoering controleren
Selecteer Opslaan en uitvoeren. De pijplijn wacht totdat de Azure Machine Learning-taak is voltooid en beëindigt de taak met WaitForJobCompletion dezelfde status als de Azure Machine Learning-taak. Bijvoorbeeld: Azure Machine Learning-taak == Azure DevOps-taak Succeeded onder SucceededWaitForJobCompletion taak Azure Machine Learning-taak == Azure DevOps-taak Failed onder WaitForJobCompletion taak Failed Azure Machine Learning-taak Cancelled == Azure DevOps-taak onder WaitForJobCompletion taakCancelled
Tip
U kunt de volledige Azure Machine Learning-taak bekijken in Azure Machine Learning-studio.
Resources opschonen
Als u uw pijplijn niet meer gaat gebruiken, verwijdert u uw Azure DevOps-project. Verwijder uw resourcegroep en Azure Machine Learning-exemplaar in Azure Portal.