AutoML-training zonder code instellen voor tabelgegevens met de gebruikersinterface van studio
In dit artikel leert u hoe u AutoML-trainingstaken instelt zonder één regel code met behulp van geautomatiseerde ML van Azure Machine Learning in de Azure Machine Learning-studio.
Geautomatiseerde machine learning, AutoML, is een proces waarin het beste machine learning-algoritme voor uw specifieke gegevens voor u wordt geselecteerd. Met dit proces kunt u snel machine learning-modellen genereren. Meer informatie over hoe Azure Machine Learning geautomatiseerde machine learning implementeert.
Probeer voor een end-to-end-voorbeeld de zelfstudie: AutoML- train no-code classificatiemodellen.
Voor een op Code gebaseerde Python-ervaring configureert u uw geautomatiseerde machine learning-experimenten met de Azure Machine Learning SDK.
Vereisten
Een Azure-abonnement. Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint. Probeer vandaag nog de gratis of betaalde versie van Azure Machine Learning.
Een Azure Machine Learning-werkruimte. Zie Werkruimtebronnen maken.
Aan de slag
Meld u aan bij Azure Machine Learning Studio.
Selecteer uw abonnement en werkruimte.
Navigeer naar het linkerdeelvenster. Selecteer Geautomatiseerde ML onder de sectie Ontwerpen .

Als dit de eerste keer is dat u experimenten uitvoert, ziet u een lege lijst en koppelingen naar documentatie.
Anders ziet u een lijst met uw recente geautomatiseerde ML-experimenten, inclusief experimenten die zijn gemaakt met de SDK.
Experiment maken en uitvoeren
Selecteer + Nieuwe geautomatiseerde ML-taak en vul het formulier in.
Selecteer een gegevensasset in uw opslagcontainer of maak een nieuwe gegevensasset. Gegevensasset kan worden gemaakt op basis van lokale bestanden, web-URL's, gegevensarchieven of open Azure-gegevenssets. Meer informatie over het maken van gegevensassets.
Belangrijk
Vereisten voor trainingsgegevens:
- Gegevens moeten in tabelvorm zijn.
- De waarde die u wilt voorspellen (doelkolom) moet aanwezig zijn in de gegevens.
Als u een nieuwe gegevensset wilt maken op basis van een bestand op uw lokale computer, selecteert u +Gegevensset maken en selecteert u vervolgens Van lokaal bestand.
Selecteer Volgende om het formulier Gegevensarchief en bestandsselectie te openen. , selecteert u waar u uw gegevensset wilt uploaden; de standaardopslagcontainer die automatisch wordt gemaakt met uw werkruimte of kies een opslagcontainer die u voor het experiment wilt gebruiken.
- Als uw gegevens zich achter een virtueel netwerk bevinden, moet u de validatiefunctie overslaan om ervoor te zorgen dat de werkruimte toegang heeft tot uw gegevens. Zie Azure Machine Learning-studio gebruiken in een virtueel Azure-netwerk voor meer informatie.
Selecteer Bladeren om het gegevensbestand voor uw gegevensset te uploaden.
Controleer het Instellingen- en voorbeeldformulier op nauwkeurigheid. Het formulier wordt intelligent ingevuld op basis van het bestandstype.
Veld Beschrijving File format Definieert de indeling en het type gegevens dat is opgeslagen in een bestand. Scheidingsteken Een of meer tekens die de grens aangeven tussen afzonderlijke, onafhankelijke regio's in tekst zonder opmaak of andere gegevensstromen. Codering Identificeert welke bit-naar-tekenschematabel er moet gebruikt worden om uw gegevensset te lezen. Kolomkoppen Geeft aan hoe koppen van de gegevensset eventueel worden behandeld. Rijen overslaan Geeft aan hoeveel rijen er eventueel worden overgeslagen in de gegevensset. Selecteer Volgende.
Het schemaformulier wordt intelligent ingevuld op basis van de selecties in het Instellingen- en voorbeeldformulier. Hier configureert u het gegevenstype voor elke kolom, controleert u de kolomnamen en selecteert u welke kolommen u niet wilt opnemen voor uw experiment.
Selecteer Volgende.
Het formulier Details bevestigen is een samenvatting van de informatie die eerder is ingevuld in de basisgegevens en Instellingen en voorbeeldformulieren. U hebt ook de mogelijkheid om een gegevensprofiel voor uw gegevensset te maken met behulp van een rekenproces waarvoor profilering is ingeschakeld.
Selecteer Volgende.
Selecteer de zojuist gemaakte gegevensset zodra deze wordt weergegeven. U kunt ook een voorbeeld van de gegevensset en voorbeeldstatistieken bekijken.
Selecteer in het taakformulier Configureren de optie Nieuwe maken en voer Tutorial-automl-deploy in als naam van het experiment.
Selecteer een doelkolom; dit is de kolom waarop u voorspellingen wilt doen.
Selecteer een rekentype voor de gegevensprofilering en trainingstaak. U kunt een rekencluster of rekenproces selecteren.
Selecteer een berekening in de vervolgkeuzelijst van uw bestaande berekeningen. Volg de instructies in stap 8 om een nieuwe berekening te maken.
Selecteer Een nieuwe berekening maken om uw rekencontext voor dit experiment te configureren.
Veld Beschrijving Naam berekening Voer een unieke naam in waarmee uw rekencontext wordt geïdentificeerd. Prioriteit van virtuele machine Virtuele machines met lage prioriteit zijn goedkoper, maar bieden geen garantie voor de rekenknooppunten. VM-type Selecteer CPU of GPU voor het type virtuele machine. Grootte van de virtuele machine Selecteer de grootte van de virtuele machine voor uw berekening. Min / Max knooppunten Als u gegevens wilt profilen, moet u een of meer knooppunten opgeven. Voer het maximum aantal knooppunten voor uw rekenproces in. De standaardwaarde is zes knooppunten voor een Azure Machine Learning Compute. Geavanceerde instellingen Met deze instellingen kunt u een gebruikersaccount en een bestaand virtueel netwerk voor uw experiment configureren. Selecteer Maken. Het maken van een nieuwe berekening kan enkele minuten duren.
Selecteer Volgende.
Selecteer in het formulier Taaktype en instellingen het taaktype: classificatie, regressie of prognose. Zie ondersteunde taaktypen voor meer informatie.
Voor classificatie kunt u deep learning ook inschakelen.
Voor prognoses kunt u het volgende doen:
Deep Learning inschakelen.
Tijdkolom selecteren: deze kolom bevat de tijdgegevens die moeten worden gebruikt.
Selecteer de prognoseperiode: Geef aan hoeveel tijdseenheden (minuten/uren/dagen/weken/maanden/jaren) het model in de toekomst kan voorspellen. Hoe verder in de toekomst het model is vereist om te voorspellen, hoe minder nauwkeurig het model wordt. Meer informatie over prognoses en de horizon voor prognoses.
(Optioneel) Aanvullende configuratie-instellingen weergeven: aanvullende instellingen die u kunt gebruiken om de trainingstaak beter te beheren. Anders worden de standaardinstellingen toegepast op basis van de selectie en gegevens van het experiment.
Aanvullende configuraties Beschrijving Primaire metrische gegevens Belangrijkste metrische gegevens die worden gebruikt voor het scoren van uw model. Meer informatie over metrische modelgegevens. Ensemblestacking inschakelen Ensemble learning verbetert machine learning-resultaten en voorspellende prestaties door meerdere modellen te combineren in plaats van één model te gebruiken. Meer informatie over ensemblemodellen. Geblokkeerde modellen Selecteer modellen die u wilt uitsluiten van de trainingstaak.
Het toestaan van modellen is alleen beschikbaar voor SDK-experimenten.
Bekijk de ondersteunde algoritmen voor elk taaktype.Uitleg geven over het beste model Toont automatisch uitleg over het beste model dat is gemaakt door Automated ML. Label van positieve klasse Label dat geautomatiseerde ML gebruikt voor het berekenen van binaire metrische gegevens. (Optioneel) Instellingen voor featurisatie weergeven: als u automatische featurization wilt inschakelen in het formulier Aanvullende configuratie-instellingen, worden standaardmetrisatietechnieken toegepast. In de weergave-instellingen kunt u deze standaardinstellingen wijzigen en dienovereenkomstig aanpassen. Meer informatie over het aanpassen van featurizations.
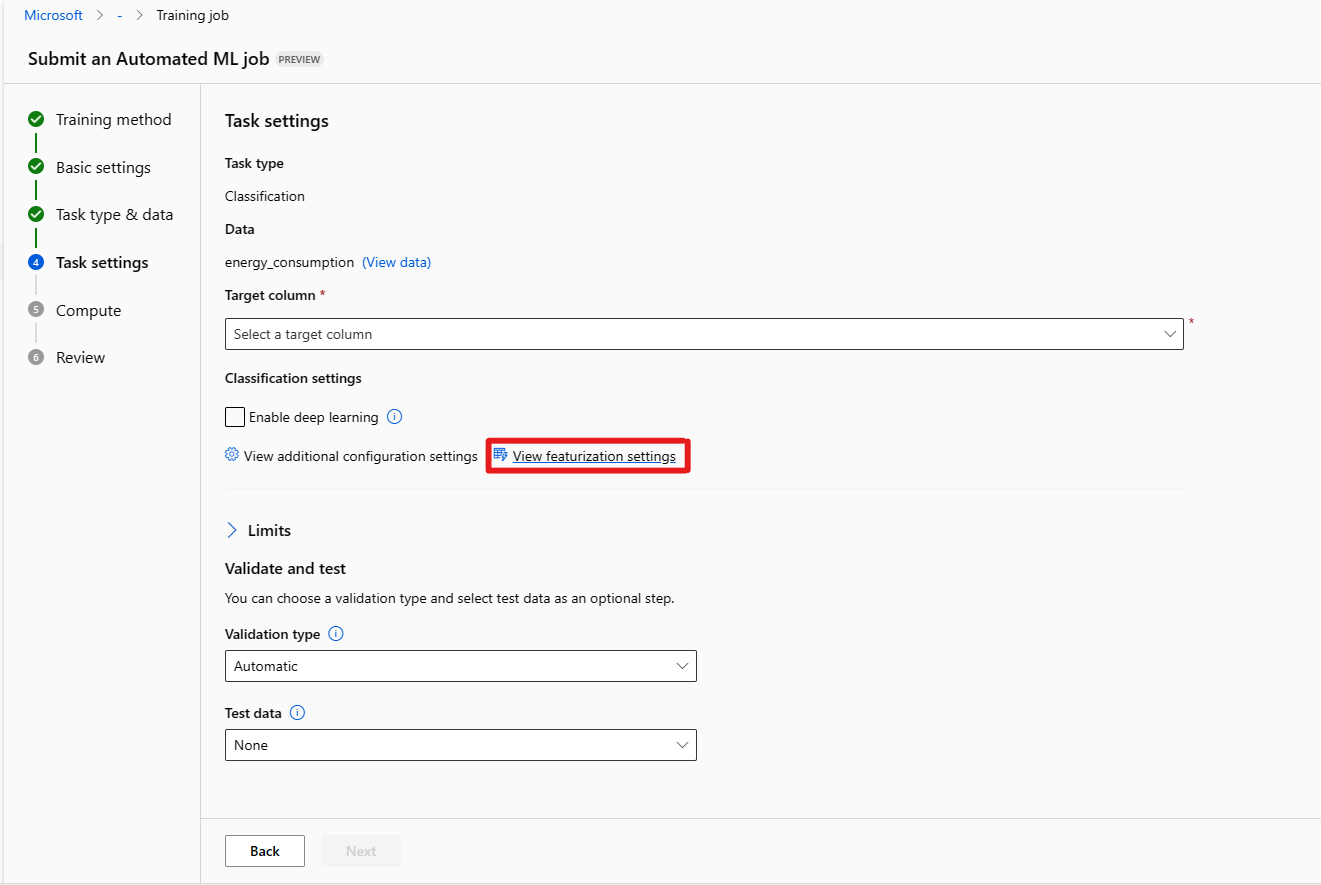
Met het formulier [Optioneel] Limieten kunt u het volgende doen.
Optie Omschrijving Maximum aantal proefversies Maximum aantal experimenten, elk met een andere combinatie van algoritme en hyperparameters om te proberen tijdens de AutoML-taak. Moet een geheel getal tussen 1 en 1000 zijn. Maximaal aantal gelijktijdige proefversies Maximum aantal proeftaken dat parallel kan worden uitgevoerd. Moet een geheel getal tussen 1 en 1000 zijn. Maximum aantal knooppunten Het maximum aantal knooppunten dat deze taak kan gebruiken vanuit het geselecteerde rekendoel. Drempelwaarde voor metrische score Wanneer deze drempelwaarde wordt bereikt voor een iteratiemetrie, wordt de trainingstaak beëindigd. Houd er rekening mee dat zinvolle modellen correlatie > 0 hebben, anders zijn ze net zo goed als het raden van de gemiddelde metrische drempel tussen grenzen [0, 10]. Time-out van experiment (minuten) De maximale tijd in minuten dat het hele experiment mag worden uitgevoerd. Zodra deze limiet is bereikt, annuleert het systeem de AutoML-taak, inclusief alle proefversies (kindertaken). Time-out voor iteratie (minuten) De maximale tijd in minuten dat elke proeftaak mag worden uitgevoerd. Zodra deze limiet is bereikt, annuleert het systeem de proefversie. Vroegtijdige beëindiging inschakelen Selecteer deze optie om de taak te beëindigen als de score op korte termijn niet wordt verbeterd. Met het formulier [Optioneel] Valideren en testen kunt u het volgende doen.
a. Geef het type validatie op dat moet worden gebruikt voor uw trainingstaak. Als u een of n_cross_validations meer parameters niet expliciet opgeeftvalidation_data, past geautomatiseerde ML standaardtechnieken toe, afhankelijk van het aantal rijen in de individuele gegevenssettraining_data.
| Grootte van trainingsgegevens | Validatietechniek |
|---|---|
| Groter dan 20.000 rijen | De gegevenssplitsing train/validatie wordt toegepast. De standaardinstelling is om 10% van de initiële trainingsgegevensset als validatieset te gebruiken. Op zijn beurt wordt die validatieset gebruikt voor het berekenen van metrische gegevens. |
| Kleiner dan 20.000 rijen | De benadering voor kruisvalidatie wordt toegepast. Het standaardaantal vouwen is afhankelijk van het aantal rijen. Als de gegevensset kleiner is dan 1000 rijen, worden er 10 vouwen gebruikt. Als de rijen tussen 1.000 en 20.000 liggen, worden er drie vouwen gebruikt. |
b. Geef een testgegevensset (preview) op om het aanbevolen model te evalueren dat geautomatiseerde ML aan het einde van uw experiment voor u genereert. Wanneer u testgegevens opgeeft, wordt aan het einde van uw experiment automatisch een testtaak geactiveerd. Deze testtaak is alleen bedoeld voor het beste model dat wordt aanbevolen door geautomatiseerde ML. Meer informatie over het ophalen van de resultaten van de externe testtaak.
Belangrijk
Het leveren van een testgegevensset voor het evalueren van gegenereerde modellen is een preview-functie. Deze mogelijkheid is een experimentele preview-functie en kan op elk gewenst moment worden gewijzigd.
* Testgegevens worden beschouwd als een afzonderlijk van training en validatie, zodat de resultaten van de testtaak van het aanbevolen model niet worden vooroordelen. Meer informatie over vooroordelen tijdens modelvalidatie.
* U kunt uw eigen testgegevensset opgeven of ervoor kiezen om een percentage van uw trainingsgegevensset te gebruiken. Testgegevens moeten de vorm hebben van een Azure Machine Learning TabularDataset.
* Het schema van de testgegevensset moet overeenkomen met de trainingsgegevensset. De doelkolom is optioneel, maar als er geen doelkolom wordt aangegeven, worden er geen metrische testgegevens berekend.
* De testgegevensset mag niet hetzelfde zijn als de trainingsgegevensset of de validatiegegevensset.
* Prognosetaken ondersteunen geen train-/testsplitsing.
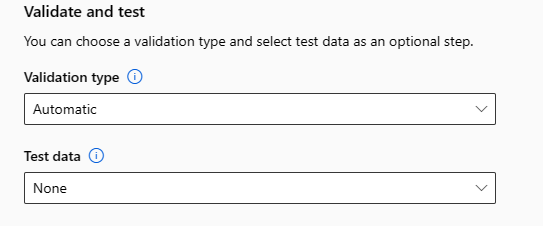
Featurization aanpassen
In het formulier Featurization kunt u automatische featurisatie in- of uitschakelen en de instellingen voor automatische featurisatie voor uw experiment aanpassen. Zie stap 10 in de sectie Experiment maken en uitvoeren om dit formulier te openen.
De volgende tabel bevat een overzicht van de aanpassingen die momenteel beschikbaar zijn via de studio.
| Kolom | Aanpassing |
|---|---|
| Functietype | Wijzig het waardetype voor de geselecteerde kolom. |
| Impute with | Selecteer met welke waarde ontbrekende waarden in uw gegevens moeten worden opgenomen. |
Experiment uitvoeren en resultaten weergeven
Selecteer Voltooien om uw experiment uit te voeren. Het voorbereiden van het experiment kan tot 10 minuten duren. Trainingstaken kunnen nog 2-3 minuten meer kosten voordat het uitvoeren van elke pijplijn is voltooid. Als u hebt opgegeven om RAI-dashboard te genereren voor het beste aanbevolen model, kan het tot 40 minuten duren.
Notitie
De geautomatiseerde ML-algoritmen hebben inherente willekeurigheid die lichte variatie kan veroorzaken in de uiteindelijke score voor metrische gegevens van een aanbevolen model, zoals nauwkeurigheid. Geautomatiseerde ML voert indien nodig ook bewerkingen uit op gegevens zoals splitsing van train-test, train-validation split of kruisvalidatie. Dus als u een experiment met dezelfde configuratie-instellingen en primaire metrische gegevens meerdere keren uitvoert, ziet u waarschijnlijk variatie in de uiteindelijke score voor metrische gegevens van experimenten vanwege deze factoren.
Experimentgegevens bekijken
Het scherm Taakdetails wordt geopend op het tabblad Details . In dit scherm ziet u een samenvatting van de experimenttaak, inclusief een statusbalk bovenaan het taaknummer.
Het tabblad Modellen bevat een lijst met de gemaakte modellen, op volgorde van de metrische score. Standaardstaat het model dat het hoogst scoort op basis van het gekozen metrische gegeven bovenaan de lijst. Naarmate de trainingstaak meer modellen probeert uit te proberen, worden ze toegevoegd aan de lijst. Gebruik dit om een snelle vergelijking te krijgen van de metrische gegevens voor de tot dusver geproduceerde modellen.
Details van trainingstaak weergeven
Zoom in op een van de voltooide modellen om details van trainingstaken te bekijken.
U kunt modelspecifieke grafieken met metrische prestatiegegevens bekijken op het tabblad Metrische gegevens . Meer informatie over grafieken.
Hier vindt u ook details over alle eigenschappen van het model, samen met de bijbehorende code, onderliggende taken en afbeeldingen.
Resultaten van externe testtaken weergeven (preview)
Als u een testgegevensset hebt opgegeven of hebt gekozen voor een train/test split tijdens het instellen van het experiment, test geautomatiseerde ML standaard het aanbevolen model. Als gevolg hiervan berekent geautomatiseerde ML testgegevens om de kwaliteit van het aanbevolen model en de bijbehorende voorspellingen te bepalen.
Belangrijk
Het testen van uw modellen met een testgegevensset om gegenereerde modellen te evalueren, is een preview-functie. Deze mogelijkheid is een experimentele preview-functie en kan op elk gewenst moment worden gewijzigd.
Waarschuwing
Deze functie is niet beschikbaar voor de volgende geautomatiseerde ML-scenario's
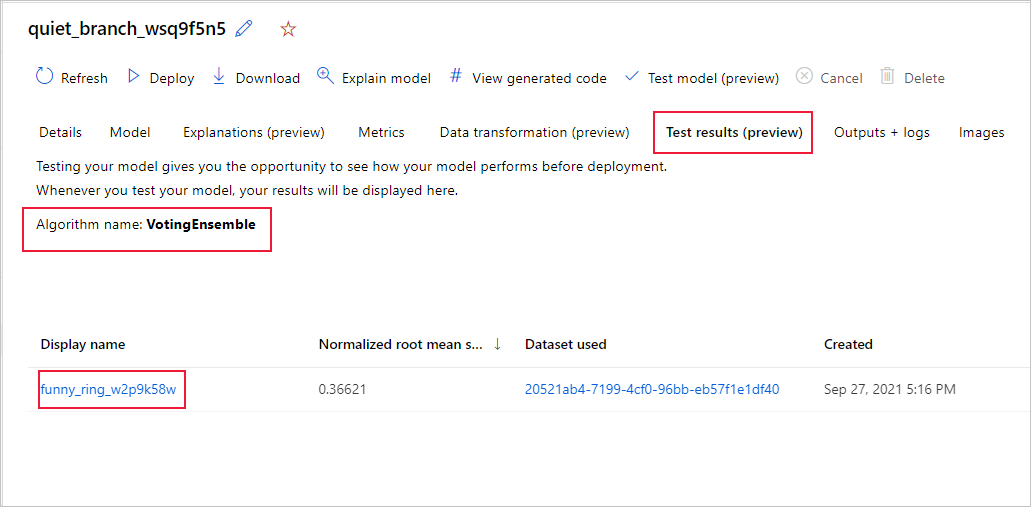
Als u de metrische gegevens van de testtaak van het aanbevolen model wilt weergeven,
- Navigeer naar de pagina Modellen en selecteer het beste model.
- Selecteer het tabblad Testresultaten (preview).
- Selecteer de gewenste taak en bekijk het tabblad Metrische gegevens .
Als u de testvoorspellingen wilt weergeven die worden gebruikt om de metrische testgegevens te berekenen,
- Navigeer naar de onderkant van de pagina en selecteer de koppeling onder Uitvoergegevensset om de gegevensset te openen.
- Selecteer op de pagina Gegevenssets het tabblad Verkennen om de voorspellingen van de testtaak weer te geven.
- U kunt het voorspellingsbestand ook bekijken/downloaden via het tabblad Uitvoer en logboeken , de map Voorspellingen uitvouwen om het
predicted.csvbestand te vinden.
- U kunt het voorspellingsbestand ook bekijken/downloaden via het tabblad Uitvoer en logboeken , de map Voorspellingen uitvouwen om het
U kunt het voorspellingsbestand ook bekijken/downloaden via het tabblad Uitvoer en logboeken, de map Voorspellingen uitvouwen om uw predictions.csv bestand te vinden.
Met de modeltesttaak wordt het predictions.csv-bestand gegenereerd dat is opgeslagen in het standaardgegevensarchief dat is gemaakt met de werkruimte. Dit gegevensarchief is zichtbaar voor alle gebruikers met hetzelfde abonnement. Testtaken worden niet aanbevolen voor scenario's als een van de gegevens die worden gebruikt voor of gemaakt door de testtaak privé moet blijven.
Een bestaand geautomatiseerd ML-model testen (preview)
Belangrijk
Het testen van uw modellen met een testgegevensset om gegenereerde modellen te evalueren, is een preview-functie. Deze mogelijkheid is een experimentele preview-functie en kan op elk gewenst moment worden gewijzigd.
Waarschuwing
Deze functie is niet beschikbaar voor de volgende geautomatiseerde ML-scenario's
Nadat uw experiment is voltooid, kunt u de modellen testen die door geautomatiseerde ML voor u worden gegenereerd. Als u een ander geautomatiseerd ml gegenereerd model wilt testen, niet het aanbevolen model, kunt u dit doen met de volgende stappen.
Selecteer een bestaande geautomatiseerde ML-experimenttaak.
Navigeer naar het tabblad Modellen van de taak en selecteer het voltooide model dat u wilt testen.
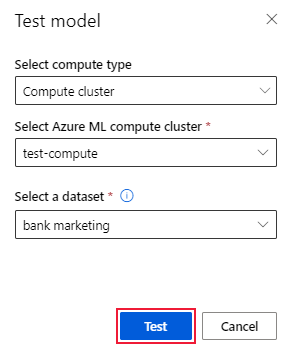
Selecteer op de pagina Modeldetails de knop Model testen (preview) om het deelvenster Testmodel te openen.
Selecteer in het deelvenster Testmodel het rekencluster en een testgegevensset die u wilt gebruiken voor uw testtaak.
Selecteer de knop Testen. Het schema van de testgegevensset moet overeenkomen met de trainingsgegevensset, maar de doelkolom is optioneel.
Wanneer het maken van de modeltesttaak is voltooid, wordt op de pagina Details een bericht weergegeven dat het is gelukt. Selecteer het tabblad Testresultaten om de voortgang van de taak te bekijken.
Als u de resultaten van de testtaak wilt bekijken, opent u de pagina Details en volgt u de stappen in de weergaveresultaten van de sectie externe testtaak .
Verantwoordelijk AI-dashboard (preview)
Als u meer inzicht wilt krijgen in uw model, kunt u verschillende inzichten over uw model zien met behulp van het dashboard Responsible Ai. Hiermee kunt u uw beste geautomatiseerde machine learning-model evalueren en fouten opsporen. Het dashboard Verantwoorde AI evalueert modelfouten en fairness-problemen, diagnosticeert waarom deze fouten optreden door uw train- en/of testgegevens te evalueren en modeluitleg te observeren. Samen kunnen deze inzichten u helpen bij het opbouwen van vertrouwen met uw model en het doorgeven van de auditprocessen. Verantwoordelijke AI-dashboards kunnen niet worden gegenereerd voor een bestaand geautomatiseerd machine learning-model. Het wordt alleen gemaakt voor het beste aanbevolen model wanneer er een nieuwe AutoML-taak wordt gemaakt. Gebruikers moeten modeluitleg blijven gebruiken (preview) totdat ondersteuning wordt geboden voor bestaande modellen.
Een verantwoordelijk AI-dashboard genereren voor een bepaald model,
Ga tijdens het verzenden van een geautomatiseerde ML-taak naar de sectie Taakinstellingen op de linkernavigatiebalk en selecteer de optie Aanvullende configuratie-instellingen weergeven.
Schakel in het nieuwe formulier dat wordt weergegeven na die selectie het selectievakje Beste model uitleggen in.
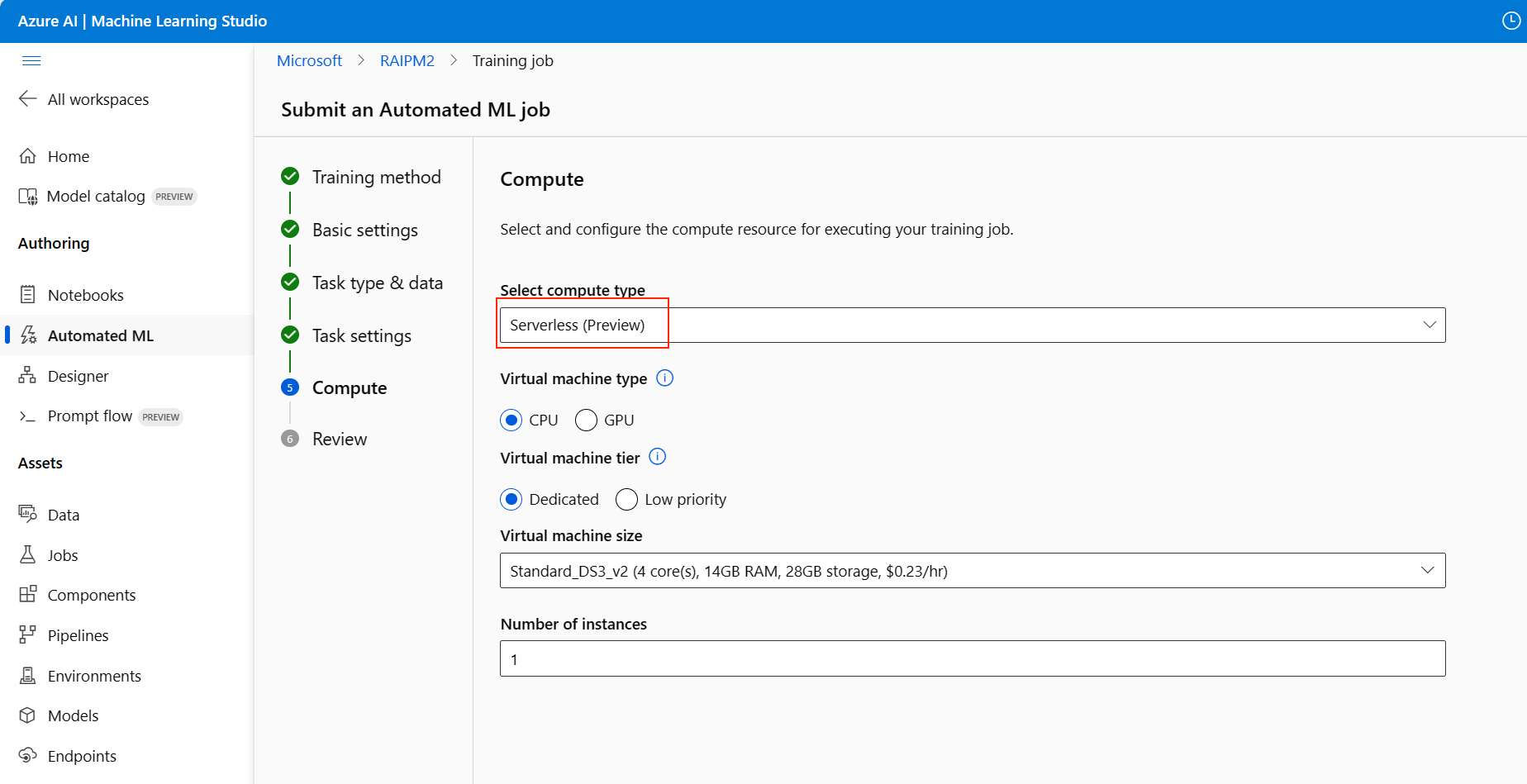
Ga door naar de pagina Compute van het installatieformulier en kies de optie Serverloos voor uw berekening.
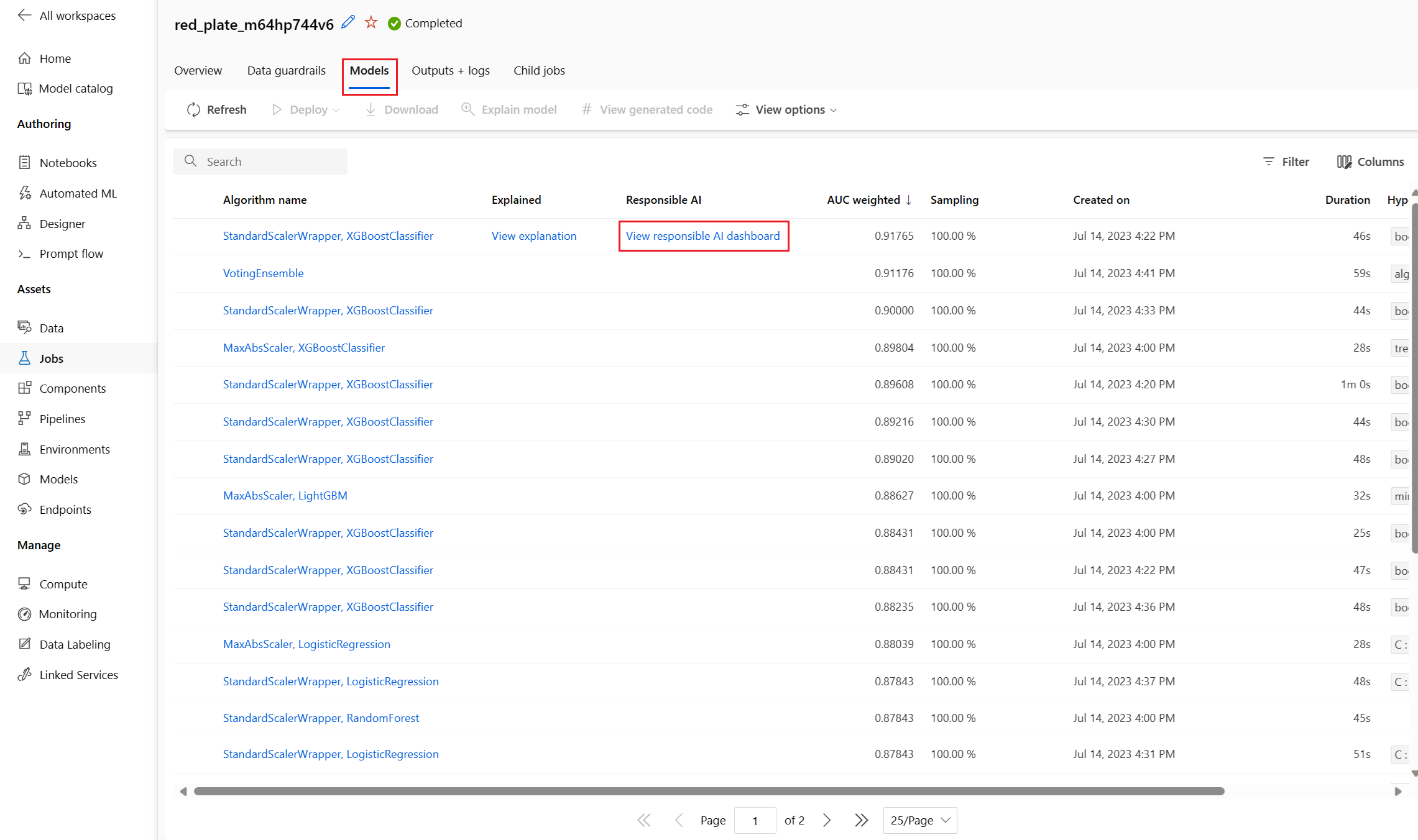
Zodra u klaar bent, gaat u naar de pagina Modellen van uw geautomatiseerde ML-taak, die een lijst met uw getrainde modellen bevat. Selecteer de koppeling Verantwoordelijke AI-dashboard weergeven:
Het verantwoordelijke AI-dashboard wordt weergegeven voor dat model, zoals wordt weergegeven in deze afbeelding:
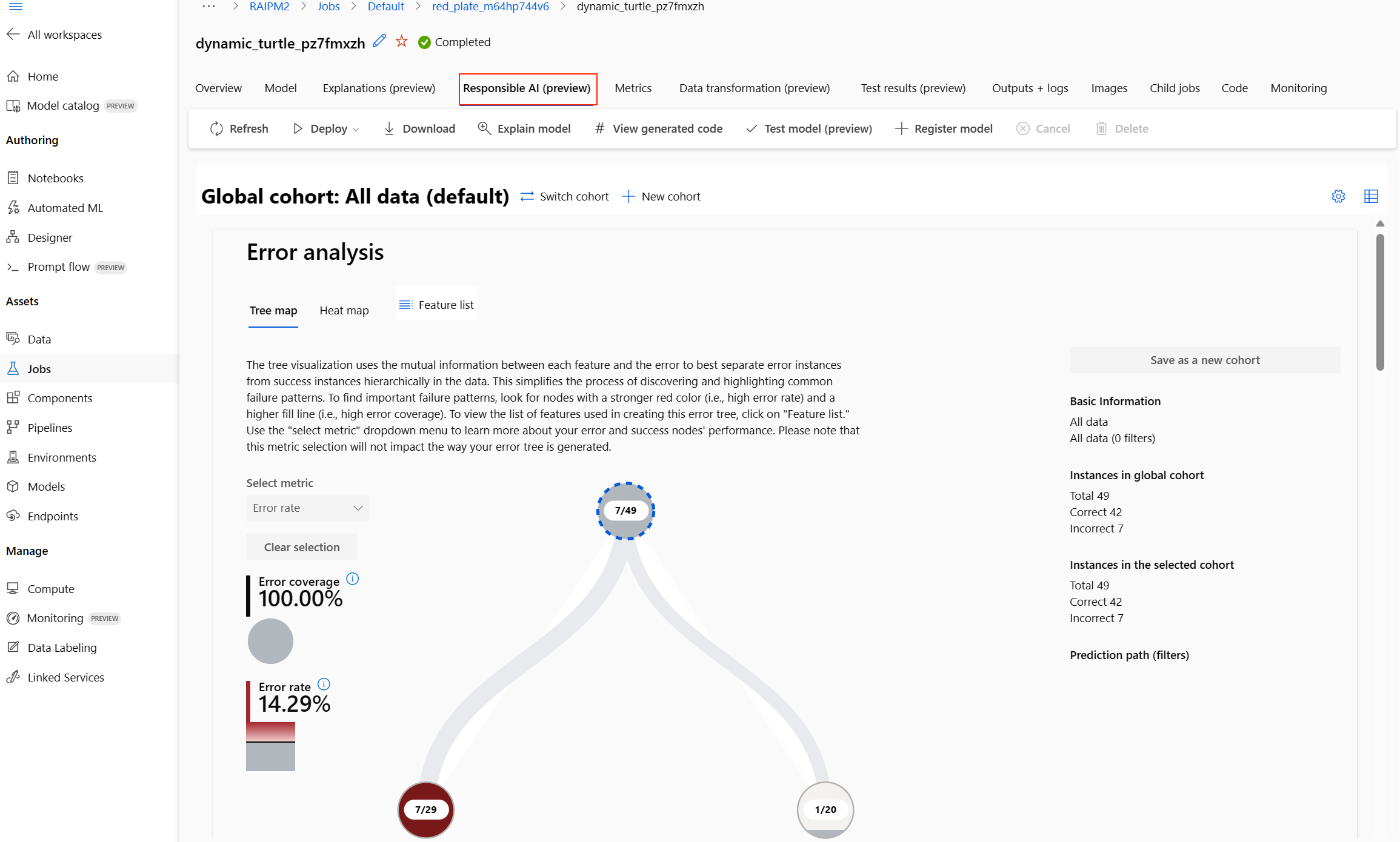
In het dashboard vindt u vier onderdelen die zijn geactiveerd voor het beste model van uw geautomatiseerde ML:
| Onderdeel | Wat wordt in het onderdeel weergegeven? | Hoe kan ik de grafiek lezen? |
|---|---|---|
| Foutanalyse | Gebruik een foutanalyse wanneer u het volgende moet doen: Krijg inzicht in hoe modelfouten worden verdeeld over een gegevensset en over verschillende invoer- en functiedimensies. De metrische statistische prestatiegegevens opsplitsen om automatisch onjuiste cohorten te detecteren om uw gerichte risicobeperkingsstappen te informeren. |
Foutanalysegrafieken |
| Overzicht en billijkheid van modellen | Gebruik dit onderdeel voor het volgende: Krijg een diepgaand inzicht in de prestaties van uw model in verschillende cohorten met gegevens. Inzicht in problemen met de redelijkheid van uw model door te kijken naar de metrische gegevens over verschillen. Deze metrische gegevens kunnen modelgedrag evalueren en vergelijken tussen subgroepen die zijn geïdentificeerd in termen van gevoelige (of niet-gevoelige) functies. |
Modeloverzicht en getrouwheidsgrafieken |
| Modeluitleg | Gebruik het onderdeel voor modeluitleg om begrijpelijke beschrijvingen van de voorspellingen van een machine learning-model te genereren door te kijken naar: Globale uitleg: Welke functies zijn bijvoorbeeld van invloed op het algehele gedrag van een leningtoewijzingsmodel? Lokale uitleg: waarom is de leningsaanvraag van een klant goedgekeurd of geweigerd? |
Model-uitleggrafieken |
| Gegevensanalyse | Gebruik gegevensanalyse wanneer u het volgende moet doen: Verken uw gegevenssetstatistieken door verschillende filters te selecteren om uw gegevens te segmenteren in verschillende dimensies (ook wel cohorten genoemd). Inzicht in de distributie van uw gegevensset in verschillende cohorten en functiegroepen. Bepaal of uw bevindingen met betrekking tot billijkheid, foutanalyse en causaliteit (afgeleid van andere dashboardonderdelen) het resultaat zijn van de distributie van uw gegevensset. Bepaal op welke gebieden meer gegevens moeten worden verzameld om fouten te beperken die afkomstig zijn van weergaveproblemen, labelruis, functieruis, labelvooroordelen en vergelijkbare factoren. |
Data Explorer-grafieken |
- U kunt nog meer cohorten maken (subgroepen van gegevenspunten die opgegeven kenmerken delen) om uw analyse van elk onderdeel op verschillende cohorten te richten. De naam van het cohort dat momenteel op het dashboard wordt toegepast, wordt altijd linksboven in het dashboard weergegeven. De standaardweergave in uw dashboard is uw hele gegevensset met de titel Alle gegevens (standaard). Meer informatie over het globale beheer van uw dashboard vindt u hier.
Taken bewerken en verzenden (preview)
Belangrijk
De mogelijkheid om een nieuw experiment te kopiëren, bewerken en verzenden op basis van een bestaand experiment is een preview-functie. Deze mogelijkheid is een experimentele preview-functie en kan op elk gewenst moment worden gewijzigd.
In scenario's waarin u een nieuw experiment wilt maken op basis van de instellingen van een bestaand experiment, biedt geautomatiseerde ML de mogelijkheid om dit te doen met de knop Bewerken en verzenden in de gebruikersinterface van studio.
Deze functionaliteit is beperkt tot experimenten die zijn geïnitieerd vanuit de gebruikersinterface van studio en vereist dat het gegevensschema voor het nieuwe experiment overeenkomt met dat van het oorspronkelijke experiment.
Met de knop Bewerken en verzenden opent u de wizard Een nieuwe geautomatiseerde ML-taak maken met de vooraf ingevulde gegevens, berekenings- en experimentinstellingen. U kunt elk formulier doorlopen en selecties bewerken als dat nodig is voor uw nieuwe experiment.
Uw model implementeren
Zodra u het beste model bij de hand hebt, is het tijd om het te implementeren als een webservice om nieuwe gegevens te voorspellen.
Tip
Als u een model wilt implementeren dat is gegenereerd via het automl pakket met de Python SDK, moet u uw model registreren) in de werkruimte.
Zodra het model is geregistreerd, zoekt u het in de studio door Modellen in het linkerdeelvenster te selecteren. Zodra u het model hebt geopend, kunt u de knop Implementeren boven aan het scherm selecteren en vervolgens de instructies volgen zoals beschreven in stap 2 van de sectie Uw model implementeren.
Geautomatiseerde ML helpt u bij het implementeren van het model zonder code te schrijven:
U hebt een aantal opties voor implementatie.
Optie 1: Implementeer het beste model volgens de metrische criteria die u hebt gedefinieerd.
- Nadat het experiment is voltooid, gaat u naar de bovenliggende taakpagina door Taak 1 boven aan het scherm te selecteren.
- Selecteer het model dat wordt vermeld in de sectie Beste modelsamenvatting .
- Selecteer Implementeren linksboven in het venster.
Optie 2: Een specifieke modeliteratie implementeren vanuit dit experiment.
- Selecteer het gewenste model op het tabblad Modellen
- Selecteer Implementeren linksboven in het venster.
Vul het deelvenster Model implementeren in.
Veld Weergegeven als Naam Voer een unieke naam in voor uw implementatie. Beschrijving Voer een beschrijving in om beter te bepalen waar deze implementatie voor is. Rekentype Selecteer het type eindpunt dat u wilt implementeren: Azure Kubernetes Service (AKS) of Azure Container Instance (ACI). Naam berekening Alleen van toepassing op AKS: selecteer de naam van het AKS-cluster waarnaar u wilt implementeren. Verificatie inschakelen Selecteer deze optie om verificatie op basis van tokens of sleutels toe te staan. Aangepaste implementatie-assets gebruiken Schakel deze functie in als u uw eigen scorescript en omgevingsbestand wilt uploaden. Anders biedt geautomatiseerde ML deze assets standaard voor u. Meer informatie over scorescripts. Belangrijk
Een bestandsnaam mag maximaal 32 tekens bevatten, en moet beginnen en eindigen met een alfanumeriek teken. De rest van de naam mag streepjes, onderstrepingstekens, punten en alfanumerieke tekens bevatten. Spaties zijn niet toegestaan.
Het menu Geavanceerd biedt standaard implementatiefuncties, zoals gegevensverzameling, en instellingen voor het gebruik van resources. Als u deze standaardwaarden wilt overschrijven, kunt u dit doen in dit menu.
Selecteer Implementeren. Implementatie duurt ongeveer 20 minuten. Zodra de implementatie is gestart, wordt het tabblad Overzicht van model weergegeven. U kunt de voortgang van de implementatie bekijken in de sectie Implementatiestatus.
U hebt nu een operationele webservice om voorspellingen te genereren. U kunt de voorspellingen testen door de service te doorzoeken via Ondersteuning voor ingebouwde Azure Machine Learning van Power BI.
Volgende stappen
- Inzicht in geautomatiseerde machine learning-resultaten.
- Meer informatie over geautomatiseerde machine learning en Azure Machine Learning.