ML-experimenten en -modellen bijhouden met MLflow
In dit artikel leert u hoe u MLflow gebruikt om uw experimenten bij te houden en uit te voeren in Azure Machine Learning-werkruimten.
Bijhouden is het proces van het opslaan van relevante informatie over experimenten die u uitvoert. De opgeslagen informatie (metagegevens) varieert op basis van uw project en kan het volgende omvatten:
- Code
- Omgevingsgegevens (zoals versie van het besturingssysteem, Python-pakketten)
- Invoergegevens
- Parameterconfiguraties
- Modellen
- Metrische evaluatiegegevens
- Evaluatievisualisaties (zoals verwarringsmatrices, urgentieplots)
- Evaluatieresultaten (inclusief enkele evaluatievoorspellingen)
Wanneer u met taken in Azure Machine Learning werkt, wordt in Azure Machine Learning automatisch informatie bijgehouden over uw experimenten, zoals code, omgeving en invoer- en uitvoergegevens. Voor anderen, zoals modellen, parameters en metrische gegevens, moet de opbouwfunctie voor modellen echter hun tracering configureren, omdat ze specifiek zijn voor het specifieke scenario.
Notitie
Als u experimenten wilt bijhouden die worden uitgevoerd op Azure Databricks, raadpleegt u Azure Databricks ML-experimenten bijhouden met MLflow en Azure Machine Learning. Zie Azure Synapse Analytics ML-experimenten bijhouden met MLflow en Azure Machine Learning voor meer informatie over het bijhouden van experimenten die worden uitgevoerd in Azure Synapse Analytics.
Voordelen van traceringsexperimenten
We raden u ten zeerste aan experimenten bij te houden, ongeacht of u met taken in Azure Machine Learning traint of interactief traint in notebooks. Met het bijhouden van experimenten kunt u het volgende doen:
- Organiseer al uw machine learning-experimenten op één plek. Vervolgens kunt u experimenten doorzoeken en filteren en inzoomen om details te bekijken over de experimenten die u eerder hebt uitgevoerd.
- Vergelijk experimenten, analyseer resultaten en foutopsporingsmodeltraining met weinig extra werk.
- Experimenten reproduceren of opnieuw uitvoeren om resultaten te valideren.
- Verbeter de samenwerking, omdat u kunt zien wat andere teamleden doen, experimentresultaten delen en programmatisch toegang krijgen tot experimentgegevens.
Waarom MLflow gebruiken voor het bijhouden van experimenten?
Azure Machine Learning-werkruimten zijn compatibel met MLflow. Dit betekent dat u MLflow kunt gebruiken om uitvoeringen, metrische gegevens, parameters en artefacten in uw Azure Machine Learning-werkruimten bij te houden. Een groot voordeel van het gebruik van MLflow voor het bijhouden is dat u uw trainingsroutines niet hoeft te wijzigen om met Azure Machine Learning te werken of een cloudspecifieke syntaxis te injecteren.
Beperkingen
Sommige methoden die beschikbaar zijn in de MLflow-API, zijn mogelijk niet beschikbaar wanneer ze zijn verbonden met Azure Machine Learning. Zie ondersteuningsmatrix voor het uitvoeren van query's en experimenten voor meer informatie over ondersteunde en niet-ondersteunde bewerkingen.
Vereisten
- Een Azure-abonnement. Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint. Probeer de gratis of betaalde versie van Azure Machine Learning.
Installeer het MLflow SDK-pakket
mlflowen de Azure Machine Learning-invoegtoepassing voor MLflowazureml-mlflow.pip install mlflow azureml-mlflowTip
U kunt het
mlflow-skinnypakket gebruiken. Dit is een lichtgewicht MLflow-pakket zonder SQL-opslag-, server-, UI- of data science-afhankelijkheden.mlflow-skinnywordt aanbevolen voor gebruikers die voornamelijk de mogelijkheden voor tracering en logboekregistratie van MLflow nodig hebben zonder de volledige suite met functies, waaronder implementaties, te importeren.Een Azure Machine Learning-werkruimte. U kunt er een maken door de zelfstudie Machine Learning-resources maken te volgen.
Als u externe tracering uitvoert (dat wil gezegd, experimenten bijhouden die buiten Azure Machine Learning worden uitgevoerd), configureert u MLflow zodat deze verwijst naar de tracerings-URI van uw Azure Machine Learning-werkruimte. Zie MLflow configureren voor Azure Machine Learning voor meer informatie over het verbinden van MLflow met uw werkruimte.
Het experiment configureren
MLflow organiseert informatie in experimenten en uitvoeringen (uitvoeringen worden taken genoemd in Azure Machine Learning). Standaard worden uitvoeringen geregistreerd bij een experiment met de naam Standaard dat automatisch voor u wordt gemaakt. U kunt het experiment configureren waar het bijhouden plaatsvindt.
Voor interactieve training, zoals in een Jupyter-notebook, gebruikt u de opdracht mlflow.set_experiment()MLflow. Met het volgende codefragment wordt bijvoorbeeld een experiment geconfigureerd:
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
De uitvoering configureren
Azure Machine Learning houdt elke trainingstaak bij in wat MLflow een uitvoering aanroept. Gebruik uitvoeringen om alle verwerkingen vast te leggen die door uw taak worden uitgevoerd.
Wanneer u interactief werkt, begint MLflow met het bijhouden van uw trainingsroutine zodra u probeert gegevens te registreren waarvoor een actieve uitvoering is vereist. MLflow-tracering wordt bijvoorbeeld gestart wanneer u een metrische gegevens, een parameter of start een trainingscyclus, en de functionaliteit voor automatische logboekregistratie van Mlflow is ingeschakeld. Het is echter meestal handig om de uitvoering expliciet te starten, speciaal als u de totale tijd voor uw experiment in het veld Duur wilt vastleggen. Als u de uitvoering expliciet wilt starten, gebruikt u mlflow.start_run().
Of u nu de uitvoering handmatig start of niet, u moet de uitvoering uiteindelijk stoppen, zodat MLflow weet dat de uitvoering van het experiment is voltooid en de status van de uitvoering kan markeren als Voltooid. Als u een uitvoering wilt stoppen, gebruikt u mlflow.end_run().
We raden u ten zeerste aan om uitvoeringen handmatig te starten, zodat u ze niet vergeet te beëindigen wanneer u in notebooks werkt.
Als u een uitvoering handmatig wilt starten en wilt beëindigen wanneer u klaar bent met het werken in het notebook:
mlflow.start_run() # Your code mlflow.end_run()Het is meestal handig om het contextbeheerparadigma te gebruiken om u te helpen de uitvoering te beëindigen:
with mlflow.start_run() as run: # Your codeWanneer u een nieuwe uitvoering start,
mlflow.start_run()kan het handig zijn om derun_nameparameter op te geven, die later wordt omgezet in de naam van de uitvoering in de Azure Machine Learning-gebruikersinterface en u kunt de uitvoering sneller identificeren:with mlflow.start_run(run_name="hello-world-example") as run: # Your code
Automatische aanmelding van MLflow inschakelen
U kunt metrische gegevens, parameters en bestanden handmatig vastleggen met MLflow . U kunt echter ook vertrouwen op de functie voor automatische logboekregistratie van MLflow. Elk machine learning-framework dat door MLflow wordt ondersteund, bepaalt wat automatisch voor u moet worden bijgehouden.
Als u automatische logboekregistratie wilt inschakelen , voegt u de volgende code in vóór uw trainingscode:
mlflow.autolog()
Metrische gegevens en artefacten weergeven in uw werkruimte
De metrische gegevens en artefacten uit MLflow-logboekregistratie worden bijgehouden in uw werkruimte. U kunt ze op elk gewenst moment in de studio bekijken en openen of ze programmatisch openen via de MLflow SDK.
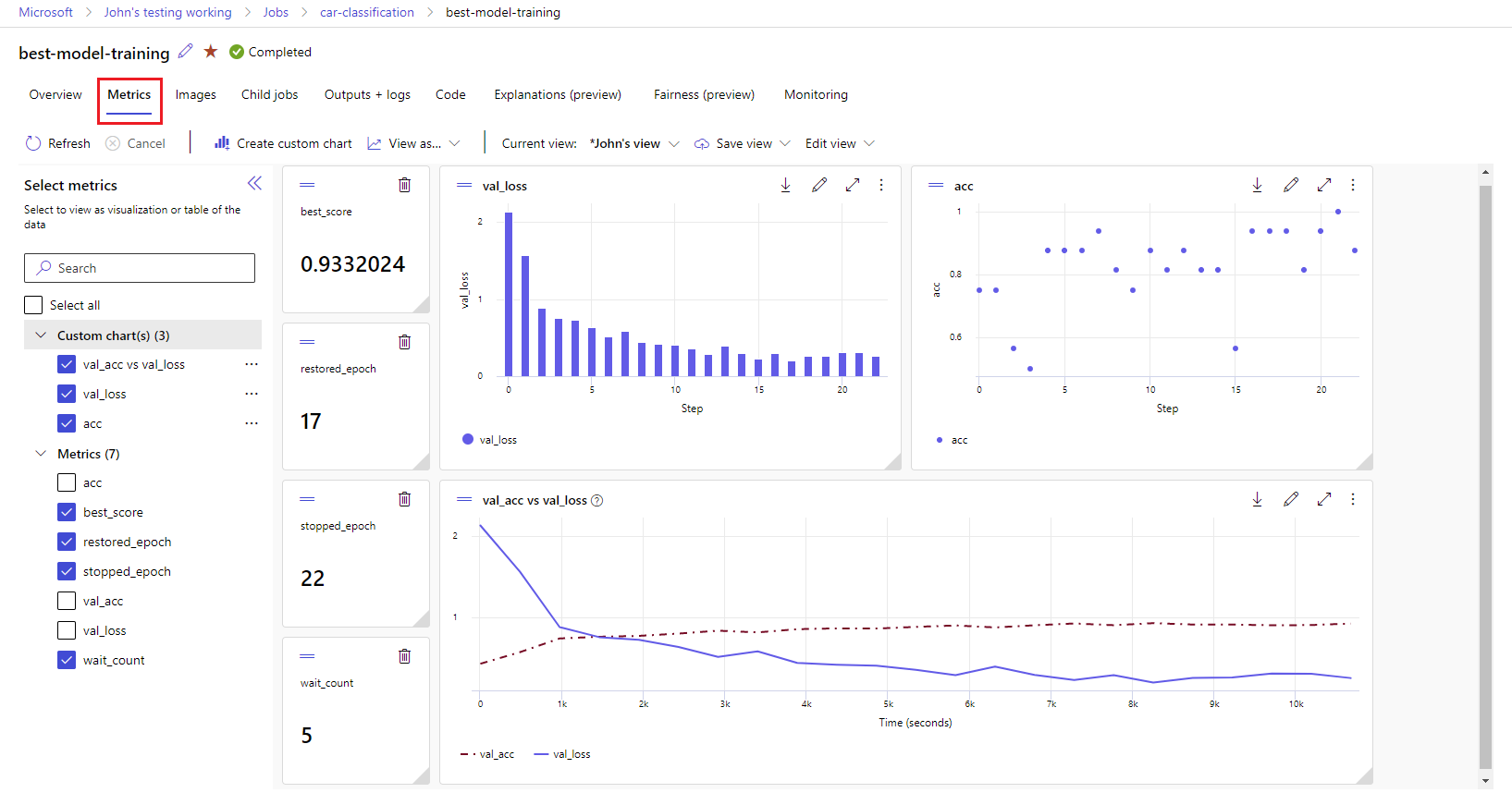
Metrische gegevens en artefacten weergeven in de studio:
Ga naar Azure Machine Learning-studio.
Navigeer naar uw werkruimte.
Zoek het experiment op naam in uw werkruimte.
Selecteer de vastgelegde metrische gegevens om grafieken aan de rechterkant weer te geven. U kunt de grafieken aanpassen door vloeiender te maken, de kleur te wijzigen of meerdere metrische gegevens in één grafiek te tekenen. U kunt ook het formaat van de indeling wijzigen en opnieuw rangschiken zoals u wilt.
Zodra u de gewenste weergave hebt gemaakt, slaat u deze op voor toekomstig gebruik en deelt u deze met uw teamleden, met behulp van een directe koppeling.

Gebruik mlflow.get_run()om programmatisch toegang te krijgen tot metrische gegevens, parameters en artefacten via de MLflow SDK of om query's uit te voeren op metrische gegevens, parameters en artefacten.
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
Tip
Voor metrische gegevens retourneert de vorige voorbeeldcode alleen de laatste waarde van een bepaalde metriek. Als u alle waarden van een bepaalde metrische waarde wilt ophalen, gebruikt u de mlflow.get_metric_history methode. Zie Parameters en metrische gegevens ophalen uit een uitvoering voor meer informatie over het ophalen van waarden van een metrische waarde.
Als u artefacten wilt downloaden die u hebt geregistreerd, zoals bestanden en modellen, gebruikt u mlflow.artifacts.download_artifacts().
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
Zie Query&&compare experimenten en uitvoeringen met MLflow voor meer informatie over het ophalen of vergelijken van gegevens uit experimenten en uitvoeringen in Azure Machine Learning.