De TDSP is een flexibele en iteratieve data science-methodologie die u kunt gebruiken om predictive analytics-oplossingen en AI-toepassingen efficiënt te leveren. De TDSP verbetert de samenwerking van teams en leert door optimale manieren aan te bevelen voor teamrollen om samen te werken. De TDSP bevat best practices en frameworks van Microsoft en andere toonaangevende bedrijven om uw team te helpen gegevenswetenschapsinitiatieven effectief te implementeren. Met de TDSP kunt u de voordelen van uw analyseprogramma volledig realiseren.
Dit artikel bevat een overzicht van de TDSP en de belangrijkste onderdelen. Het bevat richtlijnen over het implementeren van de TDSP met behulp van Microsoft-hulpprogramma's en -infrastructuur. In het artikel vindt u meer gedetailleerde informatiebronnen.
Belangrijke onderdelen van de TDSP
De TDSP heeft de volgende belangrijke onderdelen:
- Definitie van levenscyclus van data science
- Gestandaardiseerde projectstructuur
- Infrastructuur en resources die ideaal zijn voor data science-projecten
- Verantwoorde AI: en een toezegging voor de vooruitgang van AI, gebaseerd op ethische principes
Data science-levenscyclus
De TDSP biedt een levenscyclus die u kunt gebruiken om de ontwikkeling van uw data science-projecten te structuren. De levenscyclus geeft een overzicht van de volledige stappen die voor succesvolle projecten moeten worden gevolgd.
U kunt de op taken gebaseerde TDSP combineren met andere levenscycluss van data science, zoals het standaardproces voor gegevensanalyse (CRISP-DM), het kennisdetectieproces in databases (KDD) of een ander aangepast proces. Deze verschillende methodologieën hebben in de basis veel gemeen.
Gebruik deze levenscyclus als u een data science-project hebt dat deel uitmaakt van een intelligente toepassing. Intelligente toepassingen implementeren machine learning- of AI-modellen voor predictive analytics. U kunt dit proces ook gebruiken voor experimentele data science-projecten en geïmproviseerde analyseprojecten.
De TDSP-levenscyclus bestaat uit vijf belangrijke fasen die uw team iteratief uitvoert. Deze fasen zijn onder andere:
Hier volgt een visuele weergave van de TDSP-levenscyclus:
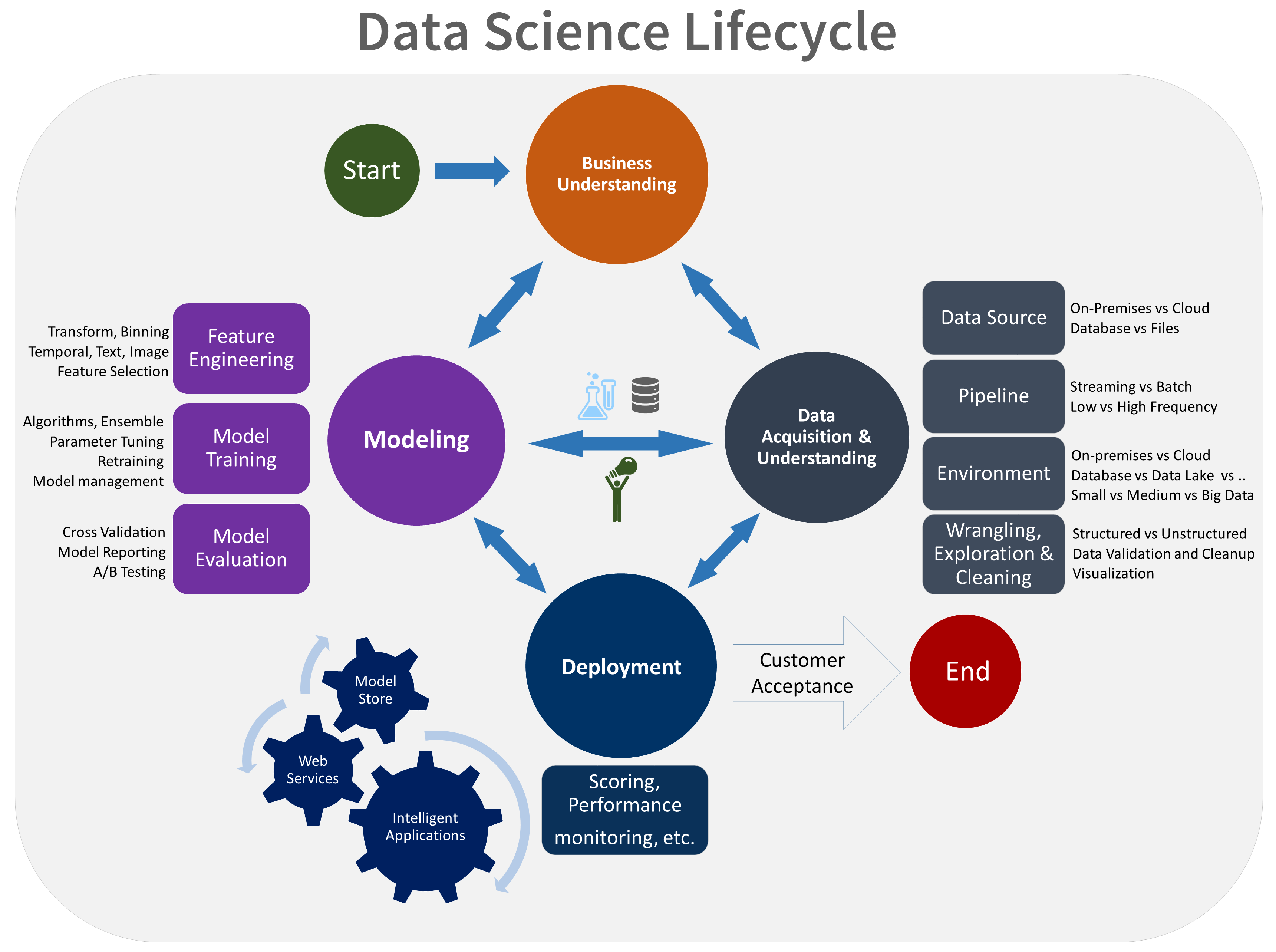
Zie de TDSP-levenscyclus voor meer informatie over de doelen, taken en documentatieartefacten voor elke fase.
Deze taken en artefacten zijn afgestemd op projectrollen, zoals:
- Oplossingsarchitect
- Projectmanager
- Data engineer
- Data scientist
- Toepassingsontwikkelaar
- Projectleider
In het volgende diagram ziet u de taken (blauw) en artefacten (groen) die overeenkomen met elke fase van de levenscyclus die op de horizontale as wordt weergegeven en voor de rollen die op de verticale as worden weergegeven.

Gestandaardiseerde projectstructuur
Uw team kan de Azure-infrastructuur gebruiken om uw data science-assets te organiseren.
Azure Machine Learning ondersteunt de opensource-MLflow. U wordt aangeraden MLflow te gebruiken voor gegevenswetenschap en AI-projectbeheer. MLflow is ontworpen voor het beheren van de volledige levenscyclus van machine learning. Het traint en bedient modellen op verschillende platforms, zodat u een consistente set hulpprogramma's kunt gebruiken, ongeacht waar uw experimenten worden uitgevoerd. U kunt MLflow lokaal op uw computer, op een extern rekendoel, op een virtuele machine of op een machine learning-rekenproces gebruiken.
MLflow bestaat uit verschillende belangrijke functies:
Experimenten bijhouden: U kunt MLflow gebruiken om experimenten bij te houden, waaronder parameters, codeversies, metrische gegevens en uitvoerbestanden. Met deze functie kunt u verschillende uitvoeringen vergelijken en het experimenteerproces efficiënt beheren.
Pakketcode: Het biedt een gestandaardiseerde indeling voor het verpakken van machine learning-code, waaronder afhankelijkheden en configuraties. Deze verpakking maakt het eenvoudiger om uitvoeringen te reproduceren en code met anderen te delen.
Modellen beheren: MLflow biedt functionaliteiten voor het beheren en versiemodellen. Het ondersteunt verschillende machine learning-frameworks, zodat u modellen kunt opslaan, versien en bedienen.
Modellen leveren en implementeren: MLflow integreert modelfuncties en implementatiemogelijkheden, zodat u eenvoudig modellen in diverse omgevingen kunt implementeren.
Modellen registreren: U kunt de levenscyclus van een model beheren, waaronder versiebeheer, faseovergangen en aantekeningen. U kunt MLflow gebruiken om een gecentraliseerd modelarchief te onderhouden in een samenwerkingsomgeving.
Een API en gebruikersinterface gebruiken: In Azure wordt MLflow gebundeld in machine learning-API versie 2, zodat u programmatisch met het systeem kunt werken. U kunt Azure Portal gebruiken om te communiceren met een gebruikersinterface.
MLflow vereenvoudigt en standaardiseert het proces van machine learning-ontwikkeling, van experimenten tot implementatie.
Machine Learning kan worden geïntegreerd met Git-opslagplaatsen, zodat u git-compatibele services kunt gebruiken, zoals GitHub, GitLab, Bitbucket, Azure DevOps of een andere met Git compatibele service. Naast de assets die al zijn bijgehouden in Machine Learning, kan uw team hun eigen taxonomie ontwikkelen binnen hun met Git compatibele service om andere projectgegevens op te slaan, zoals:
- Documentatie
- Projectgegevens: zoals het uiteindelijke projectrapport
- Gegevensrapport: zoals de gegevenswoordenlijst of rapporten over gegevenskwaliteit
- Model: zoals modelrapporten
- Code
- Gegevensvoorbereiding
- Modelontwikkeling
- Operationalisatie, waaronder beveiliging en naleving
Infrastructuur en resources
De TDSP biedt aanbevelingen voor het beheren van gedeelde analyses en opslaginfrastructuur in de volgende categorieën:
- Cloudbestandssystemen voor het opslaan van gegevenssets
- Clouddatabases
- Big data-clusters die gebruikmaken van SQL of Spark
- AI- en machine learning-services
Cloudbestandssystemen voor het opslaan van gegevenssets
Cloudbestandssystemen zijn om verschillende redenen van cruciaal belang voor de TDSP:
Gecentraliseerde gegevensopslag: cloudbestandssystemen bieden een centrale locatie voor het opslaan van gegevenssets, wat essentieel is voor samenwerking tussen leden van het data science-team. Centralisatie zorgt ervoor dat alle teamleden toegang hebben tot de meest recente gegevens en vermindert het risico op werken met verouderde of inconsistente gegevenssets.
Schaalbaarheid: cloudbestandssystemen kunnen grote hoeveelheden gegevens verwerken, wat gebruikelijk is in data science-projecten. De bestandssystemen bieden schaalbare opslagoplossingen die groeien met de behoeften van het project. Ze stellen teams in staat om enorme gegevenssets op te slaan en te verwerken zonder dat ze zich zorgen hoeven te maken over hardwarebeperkingen.
Toegankelijkheid: Met cloudbestandssystemen hebt u overal toegang tot gegevens met een internetverbinding. Deze toegang is belangrijk voor gedistribueerde teams of wanneer teamleden op afstand moeten werken. Cloudbestandssystemen vergemakkelijken naadloze samenwerking en zorgen ervoor dat gegevens altijd toegankelijk zijn.
Beveiliging en naleving: cloudproviders implementeren vaak robuuste beveiligingsmaatregelen, waaronder versleuteling, toegangscontroles en naleving van industriestandaarden en regelgeving. Sterke beveiligingsmaatregelen kunnen gevoelige gegevens beschermen en uw team helpen te voldoen aan wettelijke en wettelijke vereisten.
Versiebeheer: cloudbestandssystemen bevatten vaak functies voor versiebeheer, die teams kunnen gebruiken om wijzigingen in gegevenssets in de loop van de tijd bij te houden. Versiebeheer is van cruciaal belang om de integriteit van de gegevens te behouden en de resultaten in data science-projecten te reproduceren. Het helpt u ook bij het controleren en oplossen van eventuele problemen die zich voordoen.
Integratie met hulpprogramma's: Cloudbestandssystemen kunnen naadloos worden geïntegreerd met verschillende data science-hulpprogramma's en -platforms. Integratie van hulpprogramma's ondersteunt eenvoudiger gegevensopname, gegevensverwerking en gegevensanalyse. Azure Storage kan bijvoorbeeld goed worden geïntegreerd met Machine Learning, Azure Databricks en andere hulpprogramma's voor gegevenswetenschap.
Samenwerking en delen: met cloudbestandssystemen kunt u eenvoudig gegevenssets delen met andere teamleden of belanghebbenden. Deze systemen ondersteunen samenwerkingsfuncties, zoals gedeelde mappen en machtigingenbeheer. Samenwerkingsfuncties maken teamwork mogelijk en zorgen ervoor dat de juiste mensen toegang hebben tot de gegevens die ze nodig hebben.
Kostenefficiëntie: cloudbestandssystemen kunnen rendabeler zijn dan het onderhouden van on-premises opslagoplossingen. Cloudproviders hebben flexibele prijsmodellen met opties voor betalen per gebruik, waarmee u kosten kunt beheren op basis van de werkelijke gebruiks- en opslagvereisten van uw data science-project.
Herstel na noodgevallen: cloudbestandssystemen bevatten doorgaans functies voor gegevensback-up en herstel na noodgevallen. Deze functies helpen bij het beschermen van gegevens tegen hardwarefouten, onbedoelde verwijderingen en andere rampen. Het biedt gemoedsrust en biedt ondersteuning voor continuïteit in data science-bewerkingen.
Integratie van automatisering en werkstroom: cloudopslagsystemen kunnen worden geïntegreerd in geautomatiseerde werkstromen, waardoor naadloze gegevensoverdracht mogelijk is tussen verschillende fasen van het data science-proces. Automatisering kan helpen de efficiëntie te verbeteren en de vereiste handmatige inspanning voor het beheren van gegevens te verminderen.
Aanbevolen Azure-resources voor cloudbestandssystemen
- Azure Blob Storage : uitgebreide documentatie over Azure Blob Storage, een schaalbare objectopslagservice voor ongestructureerde gegevens.
- Azure Data Lake Storage - Informatie over Azure Data Lake Storage Gen2, ontworpen voor big data-analyses en ondersteunt grootschalige gegevenssets.
- Azure Files : details over Azure Files, die volledig beheerde bestandsshares in de cloud biedt.
Kortom, cloudbestandssystemen zijn van cruciaal belang voor de TDSP, omdat ze schaalbare, veilige en toegankelijke opslagoplossingen bieden die de volledige levenscyclus van gegevens ondersteunen. Cloudbestandssystemen maken naadloze gegevensintegratie mogelijk vanuit verschillende bronnen, die uitgebreide gegevensverwerving en -kennis ondersteunen. Gegevenswetenschappers kunnen cloudbestandssystemen gebruiken om grote gegevenssets efficiënt op te slaan, te beheren en te openen. Deze functionaliteit is essentieel voor het trainen en implementeren van machine learning-modellen. Deze systemen verbeteren ook de samenwerking door teamleden in staat te stellen gegevens tegelijkertijd in een geïntegreerde omgeving te delen en eraan te werken. Cloudbestandssystemen bieden robuuste beveiligingsfuncties waarmee gegevens worden beschermd en voldoen aan wettelijke vereisten, wat essentieel is voor het behouden van gegevensintegriteit en vertrouwen.
Clouddatabases
Clouddatabases spelen om verschillende redenen een belangrijke rol in de TDSP:
Schaalbaarheid: clouddatabases bieden schaalbare oplossingen die eenvoudig kunnen groeien om te voldoen aan de toenemende gegevensbehoeften van een project. Schaalbaarheid is cruciaal voor data science-projecten die vaak grote en ingewikkelde gegevenssets verwerken. Clouddatabases kunnen verschillende workloads verwerken zonder dat handmatige interventie of hardware-upgrades nodig zijn.
Prestatieoptimalisatie: ontwikkelaars optimaliseren clouddatabases voor prestaties met behulp van mogelijkheden zoals automatische indexering, queryoptimalisatie en taakverdeling. Deze functies zorgen ervoor dat het ophalen en verwerken van gegevens snel en efficiënt is. Dit is van cruciaal belang voor data science-taken die realtime of bijna realtime gegevenstoegang vereisen.
Toegankelijkheid en samenwerking: Teams heeft vanaf elke locatie toegang tot opgeslagen gegevens in clouddatabases. Deze toegankelijkheid bevordert de samenwerking tussen teamleden die geografisch verspreid kunnen zijn. Toegankelijkheid en samenwerking zijn belangrijk voor gedistribueerde teams of mensen die op afstand werken. Clouddatabases ondersteunen omgevingen met meerdere gebruikers die gelijktijdige toegang en samenwerking mogelijk maken.
Integratie met data science-hulpprogramma's: Clouddatabases kunnen naadloos worden geïntegreerd met verschillende data science-hulpprogramma's en -platforms. Azure-clouddatabases kunnen bijvoorbeeld goed worden geïntegreerd met Machine Learning, Power BI en andere hulpprogramma's voor gegevensanalyse. Deze integratie stroomlijnt de gegevenspijplijn, van opname en opslag tot analyse en visualisatie.
Beveiliging en naleving: cloudproviders implementeren robuuste beveiligingsmaatregelen die gegevensversleuteling, toegangsbeheer en naleving van industriestandaarden en regelgeving omvatten. Beveiligingsmaatregelen beschermen gevoelige gegevens en helpen uw team te voldoen aan wettelijke en wettelijke vereisten. Beveiligingsfuncties zijn essentieel voor het behouden van gegevensintegriteit en privacy.
Kostenefficiëntie: clouddatabases werken vaak op een model voor betalen per gebruik, wat rendabeler kan zijn dan het onderhouden van on-premises databasesystemen. Dankzij deze prijsflexflexiteit kunnen organisaties hun budgetten effectief beheren en alleen betalen voor de opslag- en rekenresources die ze gebruiken.
Automatische back-ups en herstel na noodgevallen: clouddatabases bieden oplossingen voor automatische back-up en herstel na noodgevallen. Deze oplossingen helpen gegevensverlies te voorkomen als er hardwarefouten, onbedoelde verwijderingen of andere rampen zijn. Betrouwbaarheid is van cruciaal belang voor het behouden van gegevenscontinuïteit en integriteit in data science-projecten.
Realtime gegevensverwerking: veel clouddatabases ondersteunen realtime gegevensverwerking en -analyse, wat essentieel is voor data science-taken waarvoor de meest recente informatie is vereist. Met deze mogelijkheid kunnen gegevenswetenschappers tijdig beslissingen nemen op basis van de meest recente beschikbare gegevens.
Gegevensintegratie: clouddatabases kunnen eenvoudig worden geïntegreerd met andere gegevensbronnen, databases, data lakes en externe gegevensfeeds. Dankzij integratie kunnen gegevenswetenschappers gegevens uit meerdere bronnen combineren en een uitgebreidere weergave en geavanceerdere analyse bieden.
Flexibiliteit en verscheidenheid: clouddatabases worden geleverd in verschillende vormen, zoals relationele databases, NoSQL-databases en datawarehouses. Met deze verscheidenheid kunnen data science-teams het beste type database kiezen voor hun specifieke behoeften, ongeacht of ze gestructureerde gegevensopslag, ongestructureerde gegevensverwerking of grootschalige gegevensanalyse vereisen.
Ondersteuning voor geavanceerde analyses: clouddatabases worden vaak geleverd met ingebouwde ondersteuning voor geavanceerde analyses en machine learning. Azure SQL Database biedt bijvoorbeeld ingebouwde machine learning-services. Deze services helpen gegevenswetenschappers geavanceerde analyses rechtstreeks in de databaseomgeving uit te voeren.
Aanbevolen Azure-resources voor clouddatabases
- Azure SQL Database - Documentatie over Azure SQL Database, een volledig beheerde relationele databaseservice.
- Azure Cosmos DB : informatie over Azure Cosmos DB, een wereldwijd gedistribueerde databaseservice met meerdere modellen.
- Azure Database for PostgreSQL - Handleiding voor Azure Database for PostgreSQL, een beheerde databaseservice voor het ontwikkelen en implementeren van apps.
- Azure Database for MySQL - Details over Azure Database for MySQL, een beheerde service voor MySQL-databases.
Kortom, clouddatabases zijn cruciaal voor TDSP, omdat ze schaalbare, betrouwbare en efficiënte oplossingen voor gegevensopslag en -beheer bieden die gegevensgestuurde projecten ondersteunen. Ze faciliteren naadloze gegevensintegratie, waardoor gegevenswetenschappers grote gegevenssets uit verschillende bronnen kunnen opnemen, voorverwerken en analyseren. Clouddatabases maken snelle query's en gegevensverwerking mogelijk. Dit is essentieel voor het ontwikkelen, testen en implementeren van machine learning-modellen. Clouddatabases verbeteren ook de samenwerking door een gecentraliseerd platform te bieden voor teamleden om tegelijkertijd toegang te krijgen tot en te werken met gegevens. Ten slotte bieden clouddatabases geavanceerde beveiligingsfuncties en nalevingsondersteuning om gegevens beveiligd te houden en te voldoen aan wettelijke normen, wat essentieel is voor het onderhouden van gegevensintegriteit en vertrouwen.
Big data-clusters die gebruikmaken van SQL of Spark
Big data-clusters, zoals clusters die GEBRUIKMAKEN van SQL of Spark, zijn om verschillende redenen fundamenteel voor de TDSP:
Grote hoeveelheden gegevens verwerken: Big data-clusters zijn ontworpen om grote hoeveelheden gegevens efficiënt te verwerken. Data science-projecten omvatten vaak enorme gegevenssets die de capaciteit van traditionele databases overschrijden. Op SQL gebaseerde big data-clusters en Spark kunnen deze gegevens op schaal beheren en verwerken.
Gedistribueerde computing: Big data-clusters maken gebruik van gedistribueerde computing om gegevens en rekentaken over meerdere knooppunten te verdelen. De functie voor parallelle verwerking versnelt de gegevensverwerking en analysetaken aanzienlijk, wat essentieel is om tijdig inzicht te krijgen in data science-projecten.
Schaalbaarheid: Big data-clusters bieden een hoge schaalbaarheid, zowel horizontaal door meer knooppunten en verticaal toe te voegen door de kracht van bestaande knooppunten te vergroten. Schaalbaarheid helpt ervoor te zorgen dat de gegevensinfrastructuur groeit met de behoeften van het project door toenemende gegevensgrootten en complexiteit te verwerken.
Integratie met data science-hulpprogramma's: Big data-clusters kunnen goed worden geïntegreerd met verschillende data science-hulpprogramma's en -platforms. Spark kan bijvoorbeeld naadloos worden geïntegreerd met Hadoop en SQL-clusters werken met verschillende hulpprogramma's voor gegevensanalyse. Integratie vereenvoudigt een soepele werkstroom van gegevensopname tot analyse en visualisatie.
Geavanceerde analyse: Big data-clusters ondersteunen geavanceerde analyses en machine learning. Spark biedt bijvoorbeeld de volgende ingebouwde bibliotheken:
- Machine learning, MLlib
- Grafiekverwerking, GraphX
- Stroomverwerking, Spark Streaming
Deze mogelijkheden helpen gegevenswetenschappers complexe analyses rechtstreeks in het cluster uit te voeren.
Realtime gegevensverwerking: Big data-clusters, met name clusters die gebruikmaken van Spark, ondersteunen realtime gegevensverwerking. Deze mogelijkheid is van cruciaal belang voor projecten waarvoor tot op heden gegevensanalyse en besluitvorming is vereist. Realtime verwerking helpt bij scenario's zoals fraudedetectie, realtime aanbevelingen en dynamische prijzen.
Gegevenstransformatie en extraheren, transformeren, laden (ETL): Big data-clusters zijn ideaal voor gegevenstransformatie en ETL-processen. Ze kunnen efficiënt complexe gegevenstransformaties verwerken, opschonen en aggregatietaken uitvoeren, die vaak nodig zijn voordat gegevens kunnen worden geanalyseerd.
Kostenefficiëntie: Big data-clusters kunnen rendabel zijn, met name wanneer u cloudoplossingen zoals Azure Databricks en andere cloudservices gebruikt. Deze services bieden flexibele prijsmodellen met betalen per gebruik, wat voordeliger kan zijn dan het onderhouden van een on-premises big data-infrastructuur.
Fouttolerantie: Big data-clusters zijn ontworpen met fouttolerantie in gedachten. Ze repliceren gegevens over knooppunten om ervoor te zorgen dat het systeem operationeel blijft, zelfs als sommige knooppunten mislukken. Deze betrouwbaarheid is essentieel voor het onderhouden van gegevensintegriteit en beschikbaarheid in data science-projecten.
Data Lake-integratie: Big data-clusters integreren vaak naadloos met data lakes, waardoor gegevenswetenschappers op een uniforme manier toegang kunnen krijgen tot en analyseren van diverse gegevensbronnen. Integratie bevordert uitgebreidere analyses door een combinatie van gestructureerde en ongestructureerde gegevens te ondersteunen.
Op SQL gebaseerde verwerking: voor gegevenswetenschappers die bekend zijn met SQL, big data-clusters die werken met SQL-query's, zoals Spark SQL of SQL in Hadoop, bieden ze een vertrouwde interface om big data op te vragen en te analyseren. Dit gebruiksgemak kan het analyseproces versnellen en toegankelijker maken voor een breder scala aan gebruikers.
Samenwerking en delen: Big data-clusters ondersteunen samenwerkingsomgevingen waar meerdere gegevenswetenschappers en analisten kunnen samenwerken aan dezelfde gegevenssets. Ze bieden functies voor het delen van code, notebooks en resultaten die teamwerk en kennisdeling bevorderen.
Beveiliging en naleving: Big data-clusters bieden robuuste beveiligingsfuncties, zoals gegevensversleuteling, toegangsbeheer en naleving van industriestandaarden. De beveiligingsfuncties beschermen gevoelige gegevens en helpen uw team te voldoen aan wettelijke vereisten.
Aanbevolen Azure-resources voor big data-clusters
- Apache Spark in Machine Learning: Machine Learning-integratie met Azure Synapse Analytics biedt eenvoudige toegang tot gedistribueerde rekenbronnen via het Apache Spark-framework.
- Azure Synapse Analytics: uitgebreide documentatie voor Azure Synapse Analytics, die big data en datawarehousing integreert.
Kortom, big data-clusters, of SQL of Spark, essentieel zijn voor de TDSP, omdat ze de rekenkracht en schaalbaarheid bieden die nodig zijn om grote hoeveelheden gegevens efficiënt te verwerken. Met big data-clusters kunnen gegevenswetenschappers complexe query's en geavanceerde analyses uitvoeren op grote gegevenssets die diepgaande inzichten en nauwkeurige modelontwikkeling mogelijk maken. Wanneer u gedistribueerde computing gebruikt, maken deze clusters snelle gegevensverwerking en -analyse mogelijk, waardoor de algehele werkstroom voor data science wordt versneld. Big data-clusters bieden ook ondersteuning voor naadloze integratie met verschillende gegevensbronnen en hulpprogramma's, waarmee u gegevens uit meerdere omgevingen kunt opnemen, verwerken en analyseren. Big data-clusters bevorderen ook samenwerking en reproduceerbaarheid door een geïntegreerd platform te bieden waar teams effectief resources, werkstromen en resultaten kunnen delen.
AI- en machine learning-services
AI- en machine learning-services (ML) zijn om verschillende redenen integraal voor de TDSP:
Geavanceerde analyse: AI- en ML-services maken geavanceerde analyses mogelijk. Gegevenswetenschappers kunnen geavanceerde analyses gebruiken om complexe patronen te ontdekken, voorspellingen te doen en inzichten te genereren die niet mogelijk zijn met traditionele analytische methoden. Deze geavanceerde mogelijkheden zijn van cruciaal belang voor het maken van data science-oplossingen met hoge impact.
Automatisering van terugkerende taken: AI- en ML-services kunnen terugkerende taken automatiseren, zoals het opschonen van gegevens, functie-engineering en modeltraining. Automatisering bespaart tijd en helpt gegevenswetenschappers zich te concentreren op meer strategische aspecten van het project, waardoor de algehele productiviteit wordt verbeterd.
Verbeterde nauwkeurigheid en prestaties: ML-modellen kunnen de nauwkeurigheid en prestaties van voorspellingen en analyses verbeteren door te leren van gegevens. Deze modellen kunnen continu worden verbeterd naarmate ze worden blootgesteld aan meer gegevens, wat leidt tot betere besluitvorming en betrouwbaardere resultaten.
Schaalbaarheid: AI- en ML-services die worden geleverd door cloudplatforms, zoals Machine Learning, zijn zeer schaalbaar. Ze kunnen grote hoeveelheden gegevens en complexe berekeningen verwerken, waardoor data science-teams hun oplossingen kunnen schalen om te voldoen aan groeiende eisen zonder dat ze zich zorgen hoeven te maken over onderliggende infrastructuurbeperkingen.
Integratie met andere hulpprogramma's: AI- en ML-services kunnen naadloos worden geïntegreerd met andere hulpprogramma's en services binnen het Microsoft-ecosysteem, zoals Azure Data Lake, Azure Databricks en Power BI. Integratie ondersteunt een gestroomlijnde werkstroom van gegevensopname en -verwerking tot modelimplementatie en visualisatie.
Modelimplementatie en -beheer: AI- en ML-services bieden robuuste hulpprogramma's voor het implementeren en beheren van machine learning-modellen in productie. Functies zoals versiebeheer, bewaking en geautomatiseerde hertraining zorgen ervoor dat modellen in de loop van de tijd nauwkeurig en effectief blijven. Deze aanpak vereenvoudigt het onderhoud van ML-oplossingen.
Realtime verwerking: AI- en ML-services ondersteunen realtime gegevensverwerking en besluitvorming. Realtime verwerking is essentieel voor toepassingen die onmiddellijke inzichten en acties vereisen, zoals fraudedetectie, dynamische prijzen en aanbevelingssystemen.
Aanpasbaarheid en flexibiliteit: AI- en ML-services bieden een scala aan aanpasbare opties, van vooraf samengestelde modellen en API's tot frameworks voor het bouwen van aangepaste modellen. Deze flexibiliteit helpt data science-teams om oplossingen aan te passen aan specifieke bedrijfsbehoeften en gebruiksvoorbeelden.
Toegang tot geavanceerde algoritmen: AI- en ML-services bieden gegevenswetenschappers toegang tot geavanceerde algoritmen en technologieën die zijn ontwikkeld door toonaangevende onderzoekers. Access zorgt ervoor dat het team de nieuwste ontwikkelingen in AI en ML voor hun projecten kan gebruiken.
Samenwerking en delen: AI- en ML-platforms ondersteunen samenwerkingsomgevingen voor ontwikkeling, waarbij meerdere teamleden kunnen samenwerken aan hetzelfde project, code kunnen delen en experimenten kunnen reproduceren. Samenwerking verbetert teamwerk en zorgt voor consistentie in modelontwikkeling.
Kostenefficiëntie: AI- en ML-services in de cloud kunnen rendabeler zijn dan het bouwen en onderhouden van on-premises oplossingen. Cloudproviders hebben flexibele prijsmodellen met opties voor betalen per gebruik, waarmee u kosten kunt verlagen en het resourcegebruik kunt optimaliseren.
Verbeterde beveiliging en naleving: AI- en ML-services worden geleverd met robuuste beveiligingsfuncties, waaronder gegevensversleuteling, veilige toegangscontroles en naleving van industriestandaarden en regelgeving. Deze functies helpen uw gegevens en modellen te beschermen en te voldoen aan wettelijke en wettelijke vereisten.
Vooraf gebouwde modellen en API's: veel AI- en ML-services bieden vooraf samengestelde modellen en API's voor algemene taken, zoals verwerking van natuurlijke taal, beeldherkenning en anomaliedetectie. De vooraf gemaakte oplossingen kunnen de ontwikkeling en implementatie versnellen en teams helpen snel AI-mogelijkheden in hun toepassingen te integreren.
Experimenten en prototypen: AI- en ML-platforms bieden omgevingen voor snelle experimenten en prototypen. Gegevenswetenschappers kunnen snel verschillende algoritmen, parameters en gegevenssets testen om de beste oplossing te vinden. Experimenten en prototypen ondersteunen een iteratieve benadering voor modelontwikkeling.
Aanbevolen Azure-resources voor AI- en ML-services
Machine Learning is de belangrijkste resource die we aanbevelen voor data science-toepassingen en TDSP. Azure biedt ook AI-services met kant-en-klare AI-modellen voor specifieke toepassingen.
- Machine Learning: de hoofddocumentatiepagina voor Machine Learning die betrekking heeft op installatie, modeltraining, implementatie, enzovoort.
- Azure AI-services: informatie over AI-services die vooraf samengestelde AI-modellen bieden voor vision-, spraak-, taal- en besluitvormingstaken.
Kortom, AI- en ML-services zijn cruciaal voor de TDSP, omdat ze krachtige hulpprogramma's en frameworks bieden die de ontwikkeling, training en implementatie van machine learning-modellen stroomlijnen. Deze services automatiseren complexe taken, zoals algoritmeselectie en afstemming van hyperparameters, waardoor het ontwikkelingsproces van het model aanzienlijk wordt versneld. Deze services bieden ook een schaalbare infrastructuur waarmee gegevenswetenschappers efficiënt grote gegevenssets en rekenintensieve taken kunnen verwerken. AI- en ML-hulpprogramma's integreren naadloos met andere Azure-services en verbeteren gegevensopname, voorverwerking en modelimplementatie. Integratie zorgt voor een soepele end-to-end werkstroom. Deze services bevorderen ook samenwerking en reproduceerbaarheid. Teams kunnen inzichten delen en effectief experimenteren met resultaten en modellen, terwijl ze hoge normen voor beveiliging en naleving handhaven.
Verantwoorde AI
Met AI- of ML-oplossingen bevordert Microsoft verantwoorde AI-hulpprogramma's binnen de AI- en ML-oplossingen. Deze hulpprogramma's ondersteunen microsoft Responsible AI Standard. Uw workload moet nog steeds afzonderlijk betrekking hebben op AI-gerelateerde schade.
Door peer beoordeeld bronvermeldingen
De TDSP is een goed gevestigde methodologie die teams gebruiken in microsoft-afspraken. De TDSP wordt gedocumenteerd en bestudeerd in peer-review literatuur. De bronvermeldingen bieden een mogelijkheid om de TDSP-functies en -toepassingen te onderzoeken. Zie de TDSP-levenscyclus voor meer informatie en een lijst met bronvermeldingen.